 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Global Large Language Models in Medicine
Jan 05, 2026Despite continuous advances in medical technology, the global distribution of health care resources remains uneven. The development of large language models (LLMs) has transformed the landscape of medicine and holds promise for improving health care quality and expanding access to medical information globally. However, existing LLMs are primarily trained on high-resource languages, limiting their applicability in global medical scenarios. To address this gap, we constructed GlobMed, a large multilingual medical dataset, containing over 500,000 entries spanning 12 languages, including four low-resource languages. Building on this, we established GlobMed-Bench, which systematically assesses 56 state-of-the-art proprietary and open-weight LLMs across multiple multilingual medical tasks, revealing significant performance disparities across languages, particularly for low-resource languages. Additionally, we introduced GlobMed-LLMs, a suite of multilingual medical LLMs trained on GlobMed, with parameters ranging from 1.7B to 8B. GlobMed-LLMs achieved an average performance improvement of over 40% relative to baseline models, with a more than threefold increase in performance on low-resource languages. Together, these resources provide an important foundation for advancing the equitable development and application of LLMs globally, enabling broader language communities to benefit from technological advances.
Investigating the Multilingual Calibration Effects of Language Model Instruction-Tuning
Jan 04, 2026Ensuring that deep learning models are well-calibrated in terms of their predictive uncertainty is essential in maintaining their trustworthiness and reliability, yet despite increasing advances in foundation model research, the relationship between such large language models (LLMs) and their calibration remains an open area of research. In this work, we look at a critical gap in the calibration of LLMs within multilingual settings, in an attempt to better understand how the data scarcity can potentially lead to different calibration effects and how commonly used techniques can apply in these settings. Our analysis on two multilingual benchmarks, over 29 and 42 languages respectively, reveals that even in low-resource languages, model confidence can increase significantly after instruction-tuning on high-resource language SFT datasets. However, improvements in accuracy are marginal or non-existent, resulting in mis-calibration, highlighting a critical shortcoming of standard SFT for multilingual languages. Furthermore, we observe that the use of label smoothing to be a reasonable method alleviate this concern, again without any need for low-resource SFT data, maintaining better calibration across all languages. Overall, this highlights the importance of multilingual considerations for both training and tuning LLMs in order to improve their reliability and fairness in downstream use.
On the Role of Unobserved Sequences on Sample-based Uncertainty Quantification for LLMs
Oct 06, 2025Quantifying uncertainty in large language models (LLMs) is important for safety-critical applications because it helps spot incorrect answers, known as hallucinations. One major trend of uncertainty quantification methods is based on estimating the entropy of the distribution of the LLM's potential output sequences. This estimation is based on a set of output sequences and associated probabilities obtained by querying the LLM several times. In this paper, we advocate and experimentally show that the probability of unobserved sequences plays a crucial role, and we recommend future research to integrate it to enhance such LLM uncertainty quantification methods.
Image-Text Relation Prediction for Multilingual Tweets
May 08, 2025Various social networks have been allowing media uploads for over a decade now. Still, it has not always been clear what is their relation with the posted text or even if there is any at all. In this work, we explore how multilingual vision-language models tackle the task of image-text relation prediction in different languages, and construct a dedicated balanced benchmark data set from Twitter posts in Latvian along with their manual translations into English. We compare our results to previous work and show that the more recently released vision-language model checkpoints are becoming increasingly capable at this task, but there is still much room for further improvement.
MMLU-ProX: A Multilingual Benchmark for Advanced Large Language Model Evaluation
Mar 13, 2025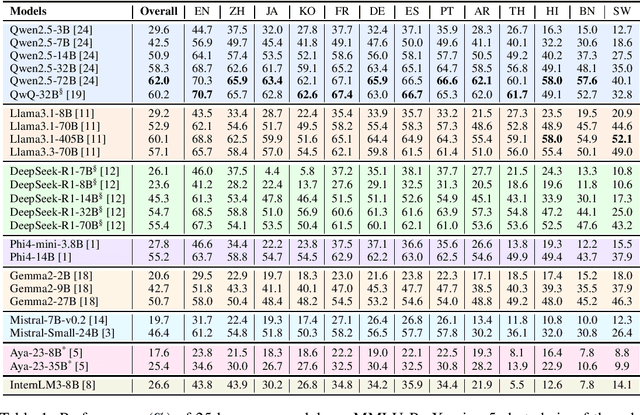
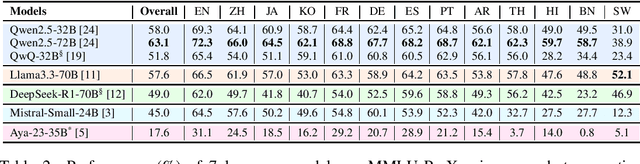
Traditional benchmarks struggle to evaluate increasingly sophisticated language models in multilingual and culturally diverse contexts. To address this gap, we introduce MMLU-ProX, a comprehensive multilingual benchmark covering 13 typologically diverse languages with approximately 11,829 questions per language. Building on the challenging reasoning-focused design of MMLU-Pro, our framework employs a semi-automatic translation process: translations generated by state-of-the-art large language models (LLMs) are rigorously evaluated by expert annotators to ensure conceptual accuracy, terminological consistency, and cultural relevance. We comprehensively evaluate 25 state-of-the-art LLMs using 5-shot chain-of-thought (CoT) and zero-shot prompting strategies, analyzing their performance across linguistic and cultural boundaries. Our experiments reveal consistent performance degradation from high-resource languages to lower-resource ones, with the best models achieving over 70% accuracy on English but dropping to around 40% for languages like Swahili, highlighting persistent gaps in multilingual capabilities despite recent advances. MMLU-ProX is an ongoing project; we are expanding our benchmark by incorporating additional languages and evaluating more language models to provide a more comprehensive assessment of multilingual capabilities.
Annotations for Exploring Food Tweets From Multiple Aspects
Dec 09, 2024



This research builds upon the Latvian Twitter Eater Corpus (LTEC), which is focused on the narrow domain of tweets related to food, drinks, eating and drinking. LTEC has been collected for more than 12 years and reaching almost 3 million tweets with the basic information as well as extended automatically and manually annotated metadata. In this paper we supplement the LTEC with manually annotated subsets of evaluation data for machine translation, named entity recognition, timeline-balanced sentiment analysis, and text-image relation classification. We experiment with each of the data sets using baseline models and highlight future challenges for various modelling approaches.
Synergy and Diversity in CLIP: Enhancing Performance Through Adaptive Backbone Ensembling
May 27, 2024



Contrastive Language-Image Pretraining (CLIP) stands out as a prominent method for image representation learning. Various architectures, from vision transformers (ViTs) to convolutional networks (ResNets) have been trained with CLIP to serve as general solutions to diverse vision tasks. This paper explores the differences across various CLIP-trained vision backbones. Despite using the same data and training objective, we find that these architectures have notably different representations, different classification performance across datasets, and different robustness properties to certain types of image perturbations. Our findings indicate a remarkable possible synergy across backbones by leveraging their respective strengths. In principle, classification accuracy could be improved by over 40 percentage with an informed selection of the optimal backbone per test example.Using this insight, we develop a straightforward yet powerful approach to adaptively ensemble multiple backbones. The approach uses as few as one labeled example per class to tune the adaptive combination of backbones. On a large collection of datasets, the method achieves a remarkable increase in accuracy of up to 39.1% over the best single backbone, well beyond traditional ensembles
Unveiling Backbone Effects in CLIP: Exploring Representational Synergies and Variances
Dec 22, 2023Contrastive Language-Image Pretraining (CLIP) stands out as a prominent method for image representation learning. Various neural architectures, spanning Transformer-based models like Vision Transformers (ViTs) to Convolutional Networks (ConvNets) like ResNets, are trained with CLIP and serve as universal backbones across diverse vision tasks. Despite utilizing the same data and training objectives, the effectiveness of representations learned by these architectures raises a critical question. Our investigation explores the differences in CLIP performance among these backbone architectures, revealing significant disparities in their classifications. Notably, normalizing these representations results in substantial performance variations. Our findings showcase a remarkable possible synergy between backbone predictions that could reach an improvement of over 20% through informed selection of the appropriate backbone. Moreover, we propose a simple, yet effective approach to combine predictions from multiple backbones, leading to a notable performance boost of up to 6.34\%. We will release the code for reproducing the results.
Perceptual Structure in the Absence of Grounding for LLMs: The Impact of Abstractedness and Subjectivity in Color Language
Nov 22, 2023



The need for grounding in language understanding is an active research topic. Previous work has suggested that color perception and color language appear as a suitable test bed to empirically study the problem, given its cognitive significance and showing that there is considerable alignment between a defined color space and the feature space defined by a language model. To further study this issue, we collect a large scale source of colors and their descriptions, containing almost a 1 million examples , and perform an empirical analysis to compare two kinds of alignments: (i) inter-space, by learning a mapping between embedding space and color space, and (ii) intra-space, by means of prompting comparatives between color descriptions. Our results show that while color space alignment holds for monolexemic, highly pragmatic color descriptions, this alignment drops considerably in the presence of examples that exhibit elements of real linguistic usage such as subjectivity and abstractedness, suggesting that grounding may be required in such cases.
Integrating UMLS Knowledge into Large Language Models for Medical Question Answering
Oct 13, 2023



Large language models (LLMs) have demonstrated powerful text generation capabilities, bringing unprecedented innovation to the healthcare field. While LLMs hold immense promise for applications in healthcare, applying them to real clinical scenarios presents significant challenges, as these models may generate content that deviates from established medical facts and even exhibit potential biases. In our research, we develop an augmented LLM framework based on the Unified Medical Language System (UMLS), aiming to better serve the healthcare community. We employ LLaMa2-13b-chat and ChatGPT-3.5 as our benchmark models, and conduct automatic evaluations using the ROUGE Score and BERTScore on 104 questions from the LiveQA test set. Additionally, we establish criteria for physician-evaluation based on four dimensions: Factuality, Completeness, Readability and Relevancy. ChatGPT-3.5 is used for physician evaluation with 20 questions on the LiveQA test set. Multiple resident physicians conducted blind reviews to evaluate the generated content, and the results indicate that this framework effectively enhances the factuality, completeness, and relevance of generated content. Our research demonstrates the effectiveness of using UMLS-augmented LLMs and highlights the potential application value of LLMs in in medical question-answering.