 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFor SALE: State-Action Representation Learning for Deep Reinforcement Learning
Jun 04, 2023



In the field of reinforcement learning (RL), representation learning is a proven tool for complex image-based tasks, but is often overlooked for environments with low-level states, such as physical control problems. This paper introduces SALE, a novel approach for learning embeddings that model the nuanced interaction between state and action, enabling effective representation learning from low-level states. We extensively study the design space of these embeddings and highlight important design considerations. We integrate SALE and an adaptation of checkpoints for RL into TD3 to form the TD7 algorithm, which significantly outperforms existing continuous control algorithms. On OpenAI gym benchmark tasks, TD7 has an average performance gain of 276.7% and 50.7% over TD3 at 300k and 5M time steps, respectively, and works in both the online and offline settings.
Uncertainty-Driven Active Vision for Implicit Scene Reconstruction
Oct 03, 2022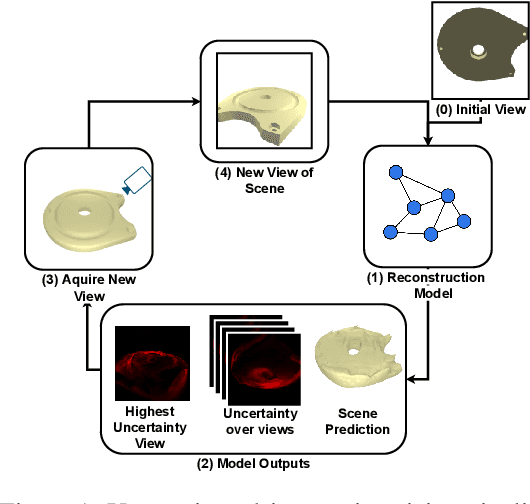
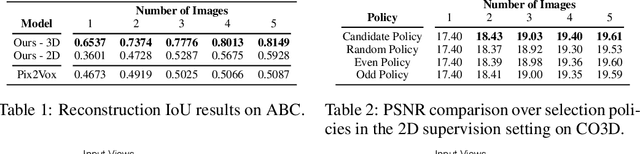
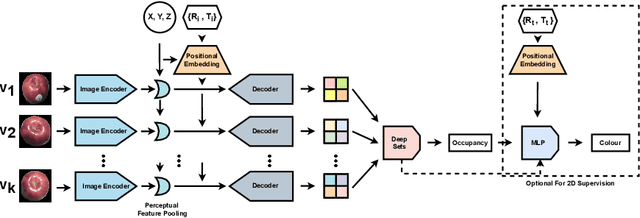

Multi-view implicit scene reconstruction methods have become increasingly popular due to their ability to represent complex scene details. Recent efforts have been devoted to improving the representation of input information and to reducing the number of views required to obtain high quality reconstructions. Yet, perhaps surprisingly, the study of which views to select to maximally improve scene understanding remains largely unexplored. We propose an uncertainty-driven active vision approach for implicit scene reconstruction, which leverages occupancy uncertainty accumulated across the scene using volume rendering to select the next view to acquire. To this end, we develop an occupancy-based reconstruction method which accurately represents scenes using either 2D or 3D supervision. We evaluate our proposed approach on the ABC dataset and the in the wild CO3D dataset, and show that: (1) we are able to obtain high quality state-of-the-art occupancy reconstructions; (2) our perspective conditioned uncertainty definition is effective to drive improvements in next best view selection and outperforms strong baseline approaches; and (3) we can further improve shape understanding by performing a gradient-based search on the view selection candidates. Overall, our results highlight the importance of view selection for implicit scene reconstruction, making it a promising avenue to explore further.
Frame Averaging for Invariant and Equivariant Network Design
Oct 07, 2021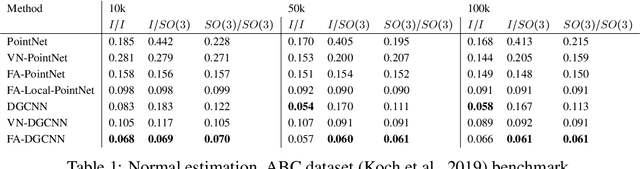
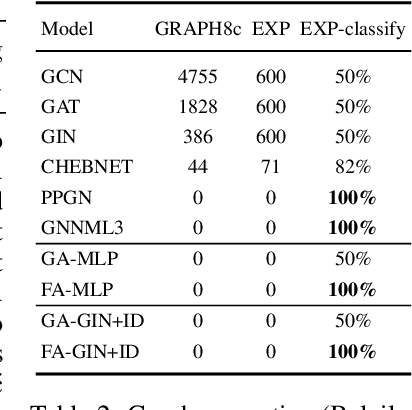
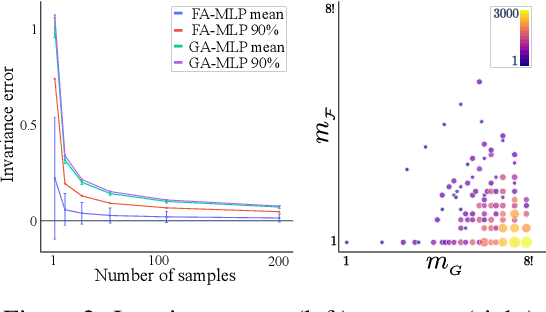
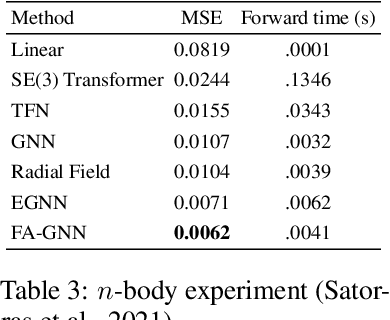
Many machine learning tasks involve learning functions that are known to be invariant or equivariant to certain symmetries of the input data. However, it is often challenging to design neural network architectures that respect these symmetries while being expressive and computationally efficient. For example, Euclidean motion invariant/equivariant graph or point cloud neural networks. We introduce Frame Averaging (FA), a general purpose and systematic framework for adapting known (backbone) architectures to become invariant or equivariant to new symmetry types. Our framework builds on the well known group averaging operator that guarantees invariance or equivariance but is intractable. In contrast, we observe that for many important classes of symmetries, this operator can be replaced with an averaging operator over a small subset of the group elements, called a frame. We show that averaging over a frame guarantees exact invariance or equivariance while often being much simpler to compute than averaging over the entire group. Furthermore, we prove that FA-based models have maximal expressive power in a broad setting and in general preserve the expressive power of their backbone architectures. Using frame averaging, we propose a new class of universal Graph Neural Networks (GNNs), universal Euclidean motion invariant point cloud networks, and Euclidean motion invariant Message Passing (MP) GNNs. We demonstrate the practical effectiveness of FA on several applications including point cloud normal estimation, beyond $2$-WL graph separation, and $n$-body dynamics prediction, achieving state-of-the-art results in all of these benchmarks.
Active 3D Shape Reconstruction from Vision and Touch
Jul 20, 2021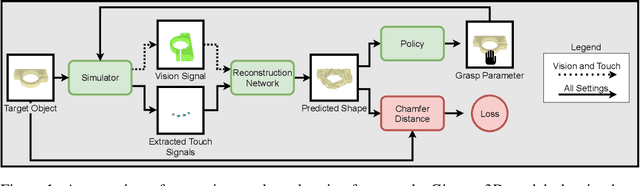
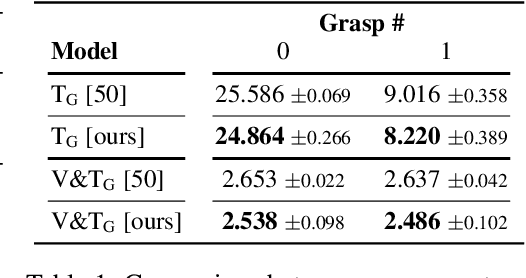
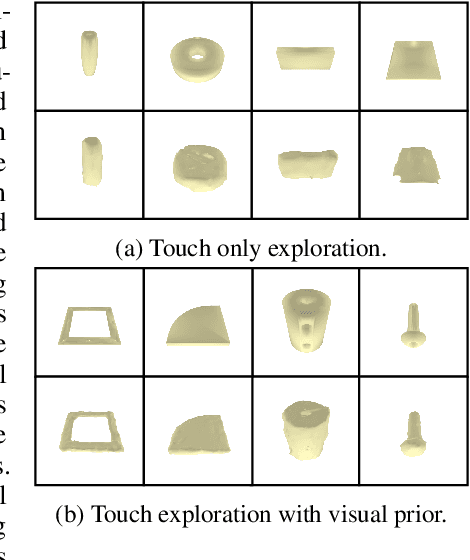
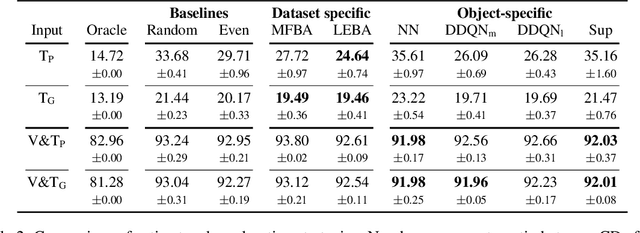
Humans build 3D understandings of the world through active object exploration, using jointly their senses of vision and touch. However, in 3D shape reconstruction, most recent progress has relied on static datasets of limited sensory data such as RGB images, depth maps or haptic readings, leaving the active exploration of the shape largely unexplored. In active touch sensing for 3D reconstruction, the goal is to actively select the tactile readings that maximize the improvement in shape reconstruction accuracy. However, the development of deep learning-based active touch models is largely limited by the lack of frameworks for shape exploration. In this paper, we focus on this problem and introduce a system composed of: 1) a haptic simulator leveraging high spatial resolution vision-based tactile sensors for active touching of 3D objects; 2) a mesh-based 3D shape reconstruction model that relies on tactile or visuotactile signals; and 3) a set of data-driven solutions with either tactile or visuotactile priors to guide the shape exploration. Our framework enables the development of the first fully data-driven solutions to active touch on top of learned models for object understanding. Our experiments show the benefits of such solutions in the task of 3D shape understanding where our models consistently outperform natural baselines. We provide our framework as a tool to foster future research in this direction.
3D Shape Reconstruction from Vision and Touch
Jul 07, 2020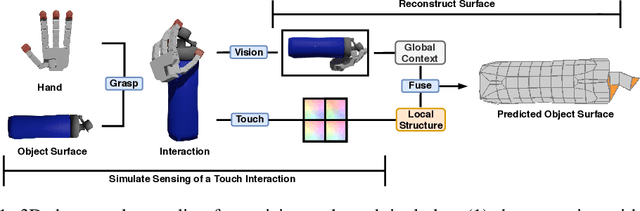
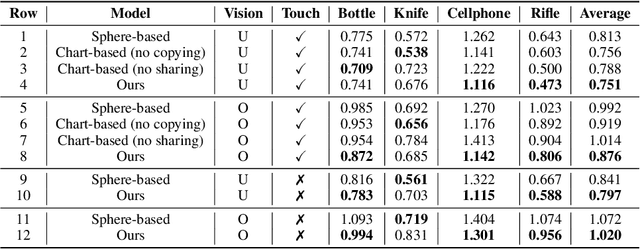
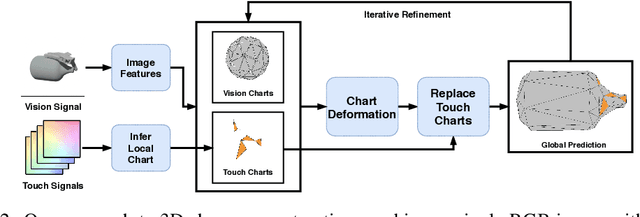

When a toddler is presented a new toy, their instinctual behaviour is to pick it up and inspect it with their hand and eyes in tandem, clearly searching over its surface to properly understand what they are playing with. Here, touch provides high fidelity localized information while vision provides complementary global context. However, in 3D shape reconstruction, the complementary fusion of visual and haptic modalities remains largely unexplored. In this paper, we study this problem and present an effective chart-based approach to fusing vision and touch, which leverages advances in graph convolutional networks. To do so, we introduce a dataset of simulated touch and vision signals from the interaction between a robotic hand and a large array of 3D objects. Our results show that (1) leveraging both vision and touch signals consistently improves single-modality baselines; (2) our approach outperforms alternative modality fusion methods and strongly benefits from the proposed chart-based structure; (3) the reconstruction quality increases with the number of grasps provided; and (4) the touch information not only enhances the reconstruction at the touch site but also extrapolates to its local neighborhood.
Learning to Predict 3D Objects with an Interpolation-based Differentiable Renderer
Aug 03, 2019

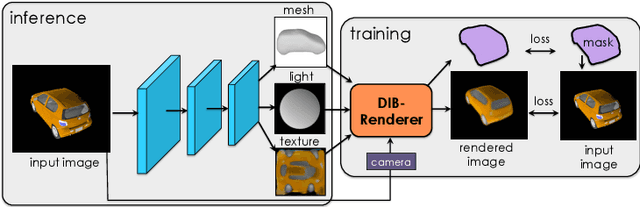

Many machine learning models operate on images, but ignore the fact that images are 2D projections formed by 3D geometry interacting with light, in a process called rendering. Enabling ML models to understand image formation might be key for generalization. However, due to an essential rasterization step involving discrete assignment operations, rendering pipelines are non-differentiable and thus largely inaccessible to gradient-based ML techniques. In this paper, we present DIB-R, a differentiable rendering framework which allows gradients to be analytically computed for all pixels in an image. Key to our approach is to view foreground rasterization as a weighted interpolation of local properties and background rasterization as an distance-based aggregation of global geometry. Our approach allows for accurate optimization over vertex positions, colors, normals, light directions and texture coordinates through a variety of lighting models. We showcase our approach in two ML applications: single-image 3D object prediction, and 3D textured object generation, both trained using exclusively using 2D supervision. Our project website is: https://nv-tlabs.github.io/DIB-R/
GEOMetrics: Exploiting Geometric Structure for Graph-Encoded Objects
Jan 31, 2019
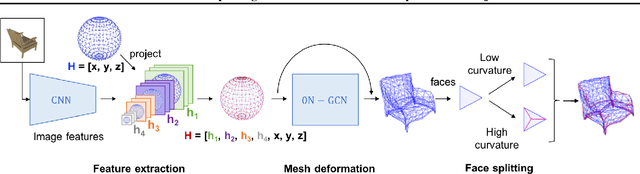

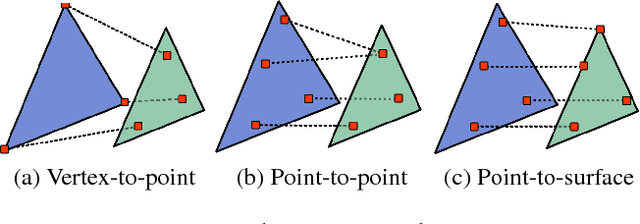
Mesh models are a promising approach for encoding the structure of 3D objects. Current mesh reconstruction systems predict uniformly distributed vertex locations of a predetermined graph through a series of graph convolutions, leading to compromises with respect to performance or resolution. In this paper, we argue that the graph representation of geometric objects allows for additional structure, which should be leveraged for enhanced reconstruction. Thus, we propose a system which properly benefits from the advantages of the geometric structure of graph encoded objects by introducing (1) a graph convolutional update preserving vertex information; (2) an adaptive splitting heuristic allowing detail to emerge; and (3) a training objective operating both on the local surfaces defined by vertices as well as the global structure defined by the mesh. Our proposed method is evaluated on the task of 3D object reconstruction from images with the ShapeNet dataset, where we demonstrate state of the art performance, both visually and numerically, while having far smaller space requirements by generating adaptive meshes