 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-efficient Hindsight Off-policy Option Learning
Jul 30, 2020


Solutions to most complex tasks can be decomposed into simpler, intermediate skills, reusable across wider ranges of problems. We follow this concept and introduce Hindsight Off-policy Options (HO2), a new algorithm for efficient and robust option learning. The algorithm relies on critic-weighted maximum likelihood estimation and an efficient dynamic programming inference procedure over off-policy trajectories. We can backpropagate through the inference procedure through time and the policy components for every time-step, making it possible to train all component's parameters off-policy, independently of the data-generating behavior policy. Experimentally, we demonstrate that HO2 outperforms competitive baselines and solves demanding robot stacking and ball-in-cup tasks from raw pixel inputs in simulation. We further compare autoregressive option policies with simple mixture policies, providing insights into the relative impact of two types of abstractions common in the options framework: action abstraction and temporal abstraction. Finally, we illustrate challenges caused by stale data in off-policy options learning and provide effective solutions.
Attention Privileged Reinforcement Learning For Domain Transfer
Nov 19, 2019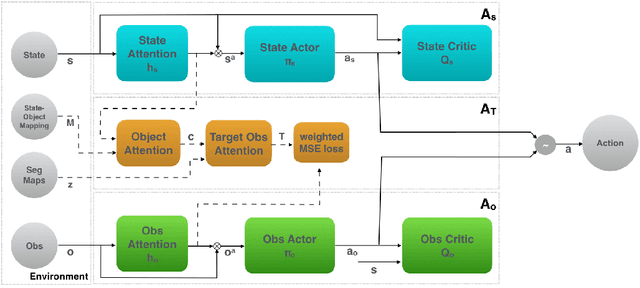
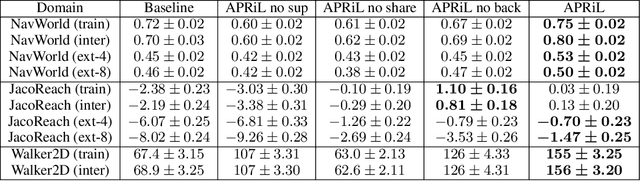
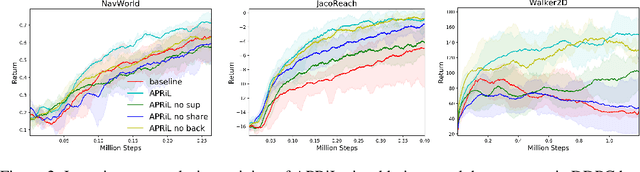
Applying reinforcement learning (RL) to physical systems presents notable challenges, given requirements regarding sample efficiency, safety, and physical constraints compared to simulated environments. To enable transfer of policies trained in simulation, randomising simulation parameters leads to more robust policies, but also significantly extends training time. In this paper, we exploit access to privileged information (such as environment states) often available in simulation, in order to improve and accelerate learning over randomised environments. We introduce Attention Privileged Reinforcement Learning (APRiL), which equips the agent with an attention mechanism and makes use of state information in simulation, learning to align attention between state- and image-based policies while additionally sharing generated data. During deployment we can apply the image-based policy to remove the requirement of access to additional information. We experimentally demonstrate accelerated and more robust learning on a number of diverse domains, leading to improved final performance for environments both within and outside the training distribution.
Continual Unsupervised Representation Learning
Oct 31, 2019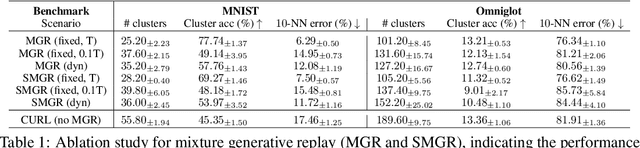
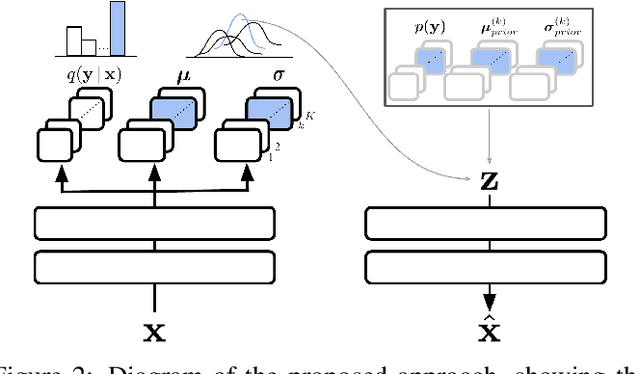

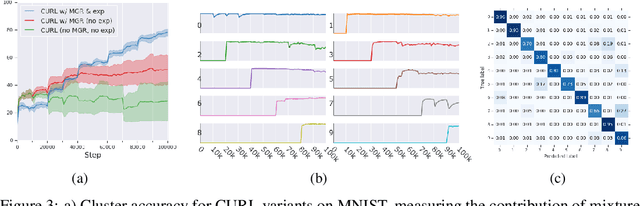
Continual learning aims to improve the ability of modern learning systems to deal with non-stationary distributions, typically by attempting to learn a series of tasks sequentially. Prior art in the field has largely considered supervised or reinforcement learning tasks, and often assumes full knowledge of task labels and boundaries. In this work, we propose an approach (CURL) to tackle a more general problem that we will refer to as unsupervised continual learning. The focus is on learning representations without any knowledge about task identity, and we explore scenarios when there are abrupt changes between tasks, smooth transitions from one task to another, or even when the data is shuffled. The proposed approach performs task inference directly within the model, is able to dynamically expand to capture new concepts over its lifetime, and incorporates additional rehearsal-based techniques to deal with catastrophic forgetting. We demonstrate the efficacy of CURL in an unsupervised learning setting with MNIST and Omniglot, where the lack of labels ensures no information is leaked about the task. Further, we demonstrate strong performance compared to prior art in an i.i.d setting, or when adapting the technique to supervised tasks such as incremental class learning.
Meta-Learning with Latent Embedding Optimization
Sep 28, 2018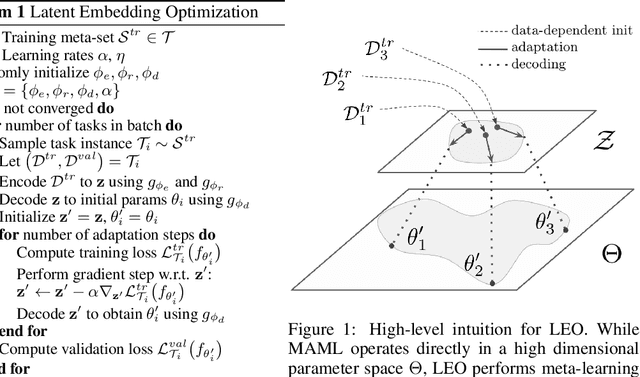
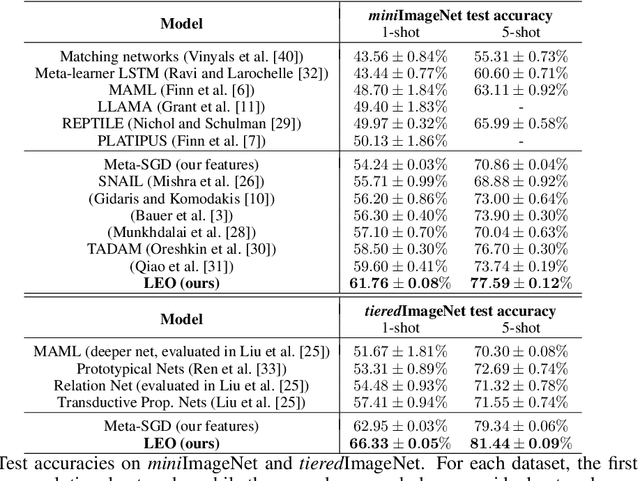
Gradient-based meta-learning techniques are both widely applicable and proficient at solving challenging few-shot learning and fast adaptation problems. However, they have practical difficulties when operating on high-dimensional parameter spaces in extreme low-data regimes. We show that it is possible to bypass these limitations by learning a data-dependent latent generative representation of model parameters, and performing gradient-based meta-learning in this low-dimensional latent space. The resulting approach, latent embedding optimization (LEO), decouples the gradient-based adaptation procedure from the underlying high-dimensional space of model parameters. Our evaluation shows that LEO can achieve state-of-the-art performance on the competitive miniImageNet and tieredImageNet few-shot classification tasks. Further analysis indicates LEO is able to capture uncertainty in the data, and can perform adaptation more effectively by optimizing in latent space.
Resource-Performance Trade-off Analysis for Mobile Robot Design
Sep 11, 2017



The design of mobile autonomous robots is challenging due to the limited on-board resources such as processing power and energy. A promising approach is to generate intelligent schedules that reduce the resource consumption while maintaining best performance, or more interestingly, to trade off reduced resource consumption for a slightly lower but still acceptable level of performance. In this paper, we provide a framework to aid designers in exploring such resource-performance trade-offs and finding schedules for mobile robots, guided by questions such as "what is the minimum resource budget required to achieve a given level of performance?" The framework is based on a quantitative multi-objective verification technique which, for a collection of possibly conflicting objectives, produces the Pareto front that contains all the optimal trade-offs that are achievable. The designer then selects a specific Pareto point based on the resource constraints and desired performance level, and a correct-by-construction schedule that meets those constraints is automatically generated. We demonstrate the efficacy of this framework on several robotic scenarios in both simulations and experiments with encouraging results.
Deep Tracking on the Move: Learning to Track the World from a Moving Vehicle using Recurrent Neural Networks
Apr 19, 2017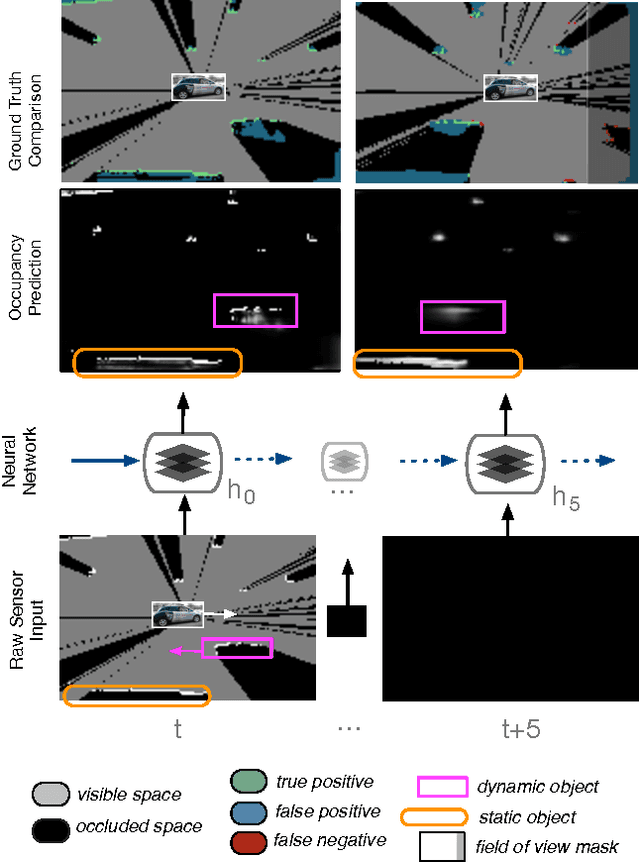
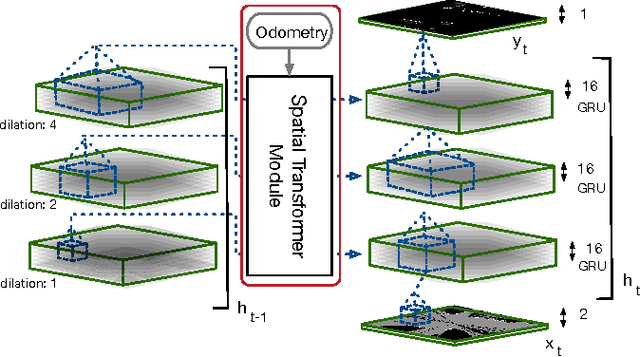
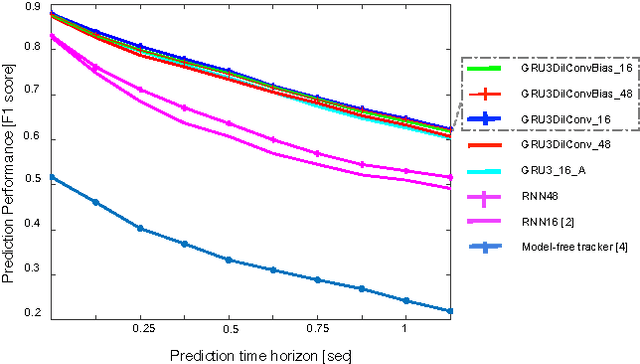
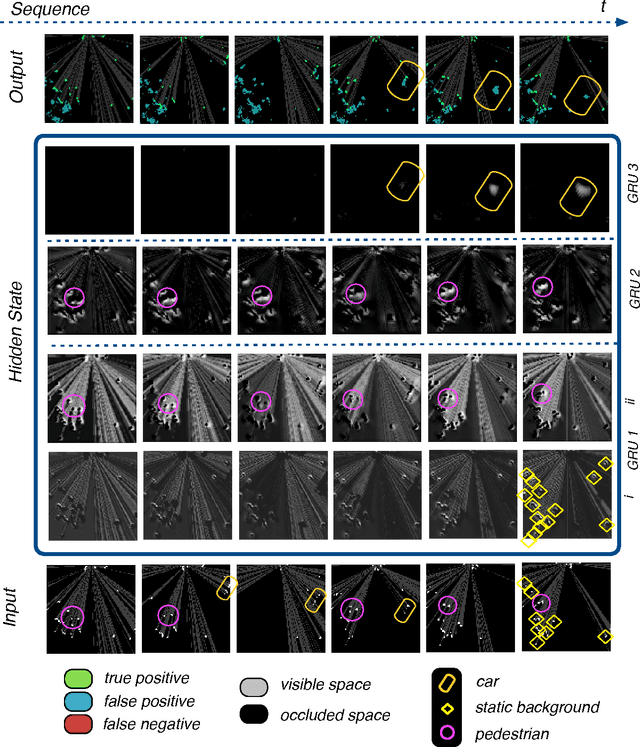
This paper presents an end-to-end approach for tracking static and dynamic objects for an autonomous vehicle driving through crowded urban environments. Unlike traditional approaches to tracking, this method is learned end-to-end, and is able to directly predict a full unoccluded occupancy grid map from raw laser input data. Inspired by the recently presented DeepTracking approach [Ondruska, 2016], we employ a recurrent neural network (RNN) to capture the temporal evolution of the state of the environment, and propose to use Spatial Transformer modules to exploit estimates of the egomotion of the vehicle. Our results demonstrate the ability to track a range of objects, including cars, buses, pedestrians, and cyclists through occlusion, from both moving and stationary platforms, using a single learned model. Experimental results demonstrate that the model can also predict the future states of objects from current inputs, with greater accuracy than previous work.
Vote3Deep: Fast Object Detection in 3D Point Clouds Using Efficient Convolutional Neural Networks
Mar 05, 2017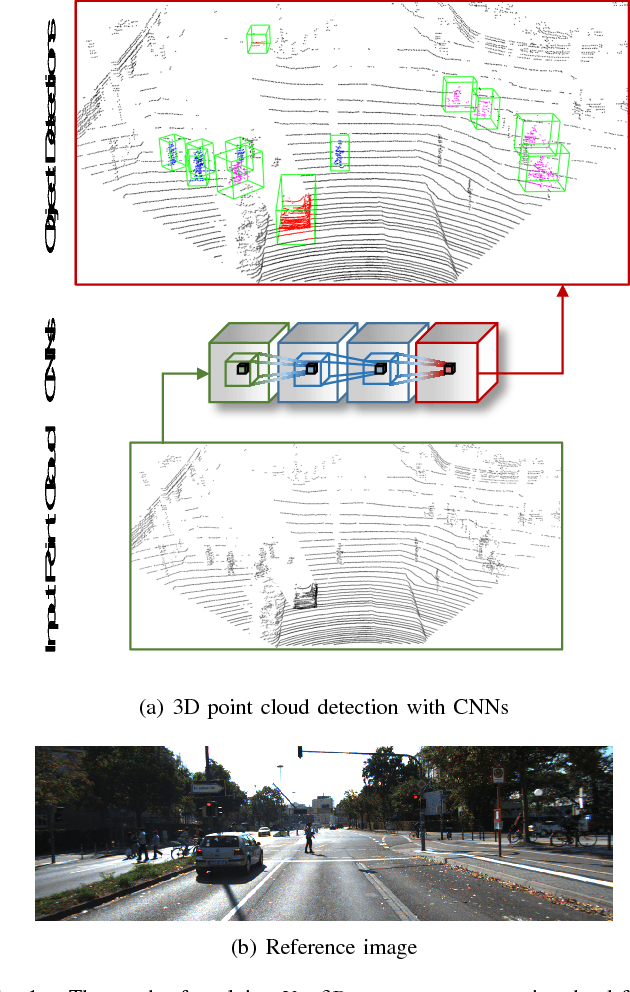
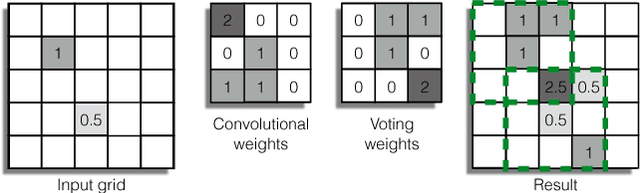
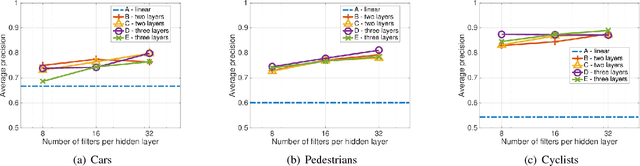
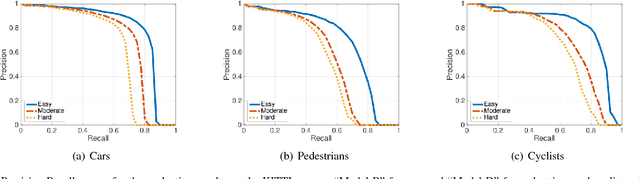
This paper proposes a computationally efficient approach to detecting objects natively in 3D point clouds using convolutional neural networks (CNNs). In particular, this is achieved by leveraging a feature-centric voting scheme to implement novel convolutional layers which explicitly exploit the sparsity encountered in the input. To this end, we examine the trade-off between accuracy and speed for different architectures and additionally propose to use an L1 penalty on the filter activations to further encourage sparsity in the intermediate representations. To the best of our knowledge, this is the first work to propose sparse convolutional layers and L1 regularisation for efficient large-scale processing of 3D data. We demonstrate the efficacy of our approach on the KITTI object detection benchmark and show that Vote3Deep models with as few as three layers outperform the previous state of the art in both laser and laser-vision based approaches by margins of up to 40% while remaining highly competitive in terms of processing time.
Incorporating Human Domain Knowledge into Large Scale Cost Function Learning
Dec 13, 2016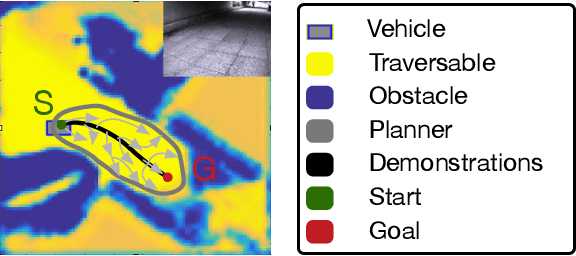
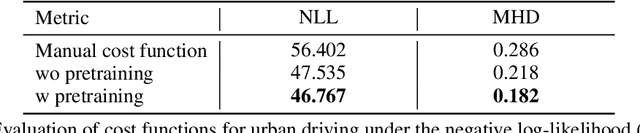
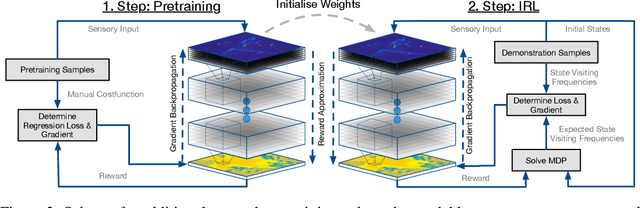
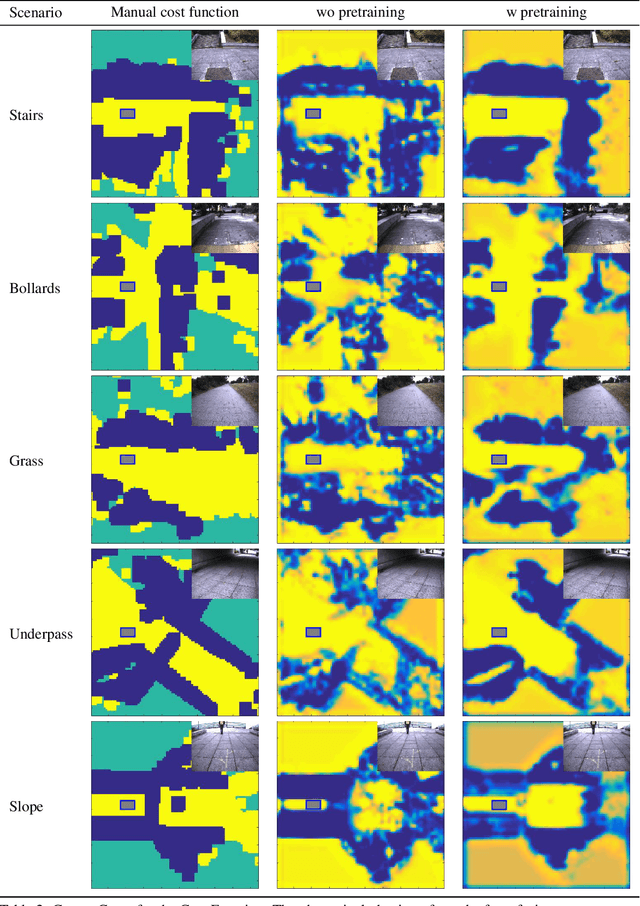
Recent advances have shown the capability of Fully Convolutional Neural Networks (FCN) to model cost functions for motion planning in the context of learning driving preferences purely based on demonstration data from human drivers. While pure learning from demonstrations in the framework of Inverse Reinforcement Learning (IRL) is a promising approach, we can benefit from well informed human priors and incorporate them into the learning process. Our work achieves this by pretraining a model to regress to a manual cost function and refining it based on Maximum Entropy Deep Inverse Reinforcement Learning. When injecting prior knowledge as pretraining for the network, we achieve higher robustness, more visually distinct obstacle boundaries, and the ability to capture instances of obstacles that elude models that purely learn from demonstration data. Furthermore, by exploiting these human priors, the resulting model can more accurately handle corner cases that are scarcely seen in the demonstration data, such as stairs, slopes, and underpasses.