 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSQL: A Conversational Text-to-SQL Challenge Towards Cross-Domain Natural Language Interfaces to Databases
Sep 11, 2019
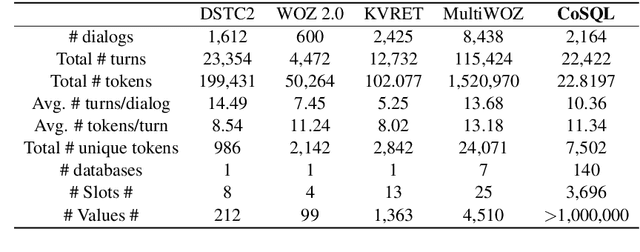
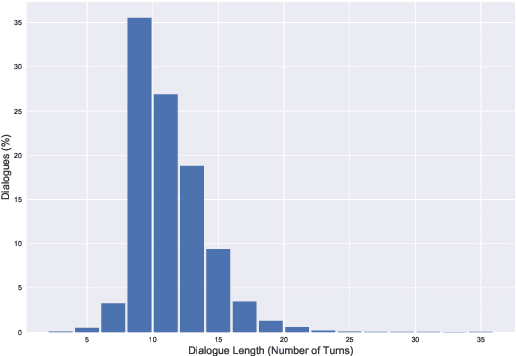
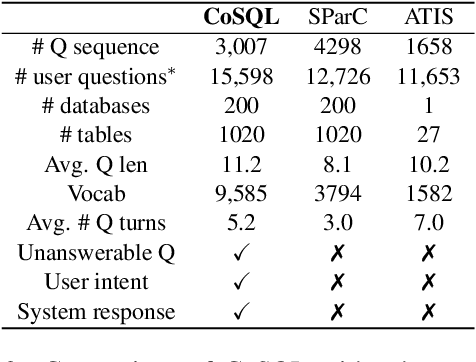
We present CoSQL, a corpus for building cross-domain, general-purpose database (DB) querying dialogue systems. It consists of 30k+ turns plus 10k+ annotated SQL queries, obtained from a Wizard-of-Oz (WOZ) collection of 3k dialogues querying 200 complex DBs spanning 138 domains. Each dialogue simulates a real-world DB query scenario with a crowd worker as a user exploring the DB and a SQL expert retrieving answers with SQL, clarifying ambiguous questions, or otherwise informing of unanswerable questions. When user questions are answerable by SQL, the expert describes the SQL and execution results to the user, hence maintaining a natural interaction flow. CoSQL introduces new challenges compared to existing task-oriented dialogue datasets:(1) the dialogue states are grounded in SQL, a domain-independent executable representation, instead of domain-specific slot-value pairs, and (2) because testing is done on unseen databases, success requires generalizing to new domains. CoSQL includes three tasks: SQL-grounded dialogue state tracking, response generation from query results, and user dialogue act prediction. We evaluate a set of strong baselines for each task and show that CoSQL presents significant challenges for future research. The dataset, baselines, and leaderboard will be released at https://yale-lily.github.io/cosql.
Editing-Based SQL Query Generation for Cross-Domain Context-Dependent Questions
Sep 10, 2019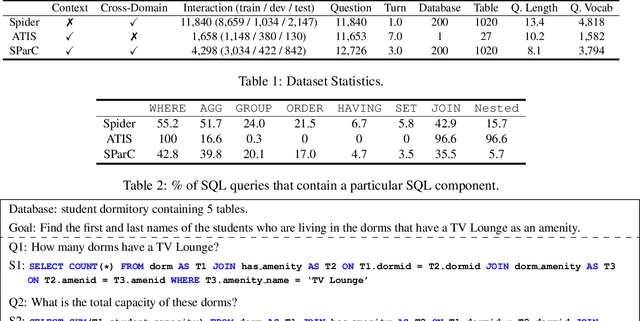
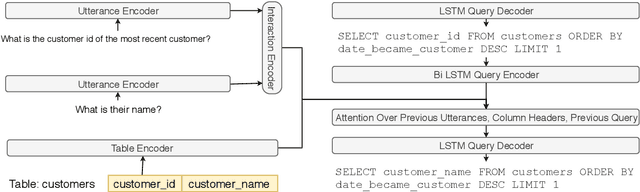
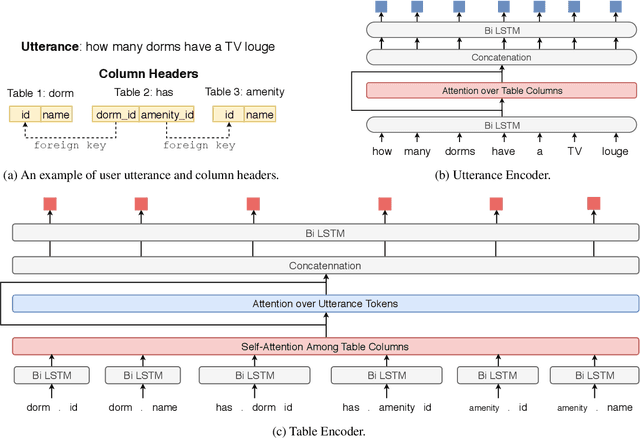
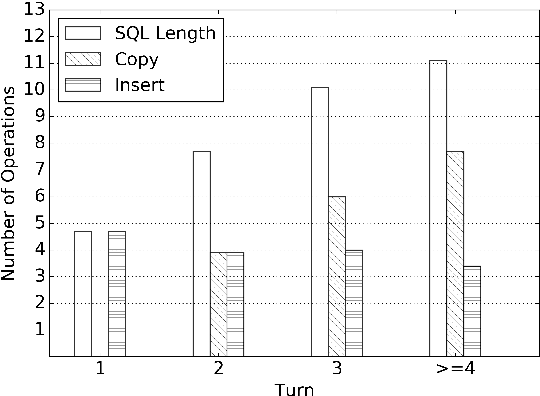
We focus on the cross-domain context-dependent text-to-SQL generation task. Based on the observation that adjacent natural language questions are often linguistically dependent and their corresponding SQL queries tend to overlap, we utilize the interaction history by editing the previous predicted query to improve the generation quality. Our editing mechanism views SQL as sequences and reuses generation results at the token level in a simple manner. It is flexible to change individual tokens and robust to error propagation. Furthermore, to deal with complex table structures in different domains, we employ an utterance-table encoder and a table-aware decoder to incorporate the context of the user utterance and the table schema. We evaluate our approach on the SParC dataset and demonstrate the benefit of editing compared with the state-of-the-art baselines which generate SQL from scratch. Our code is available at https://github.com/ryanzhumich/sparc_atis_pytorch.
The CL-SciSumm Shared Task 2018: Results and Key Insights
Sep 02, 2019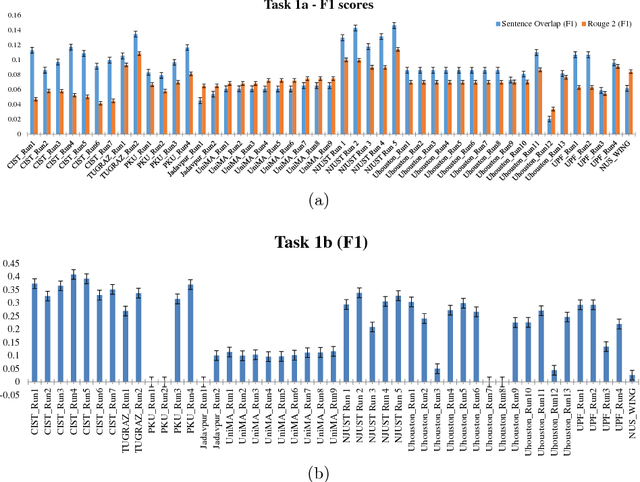
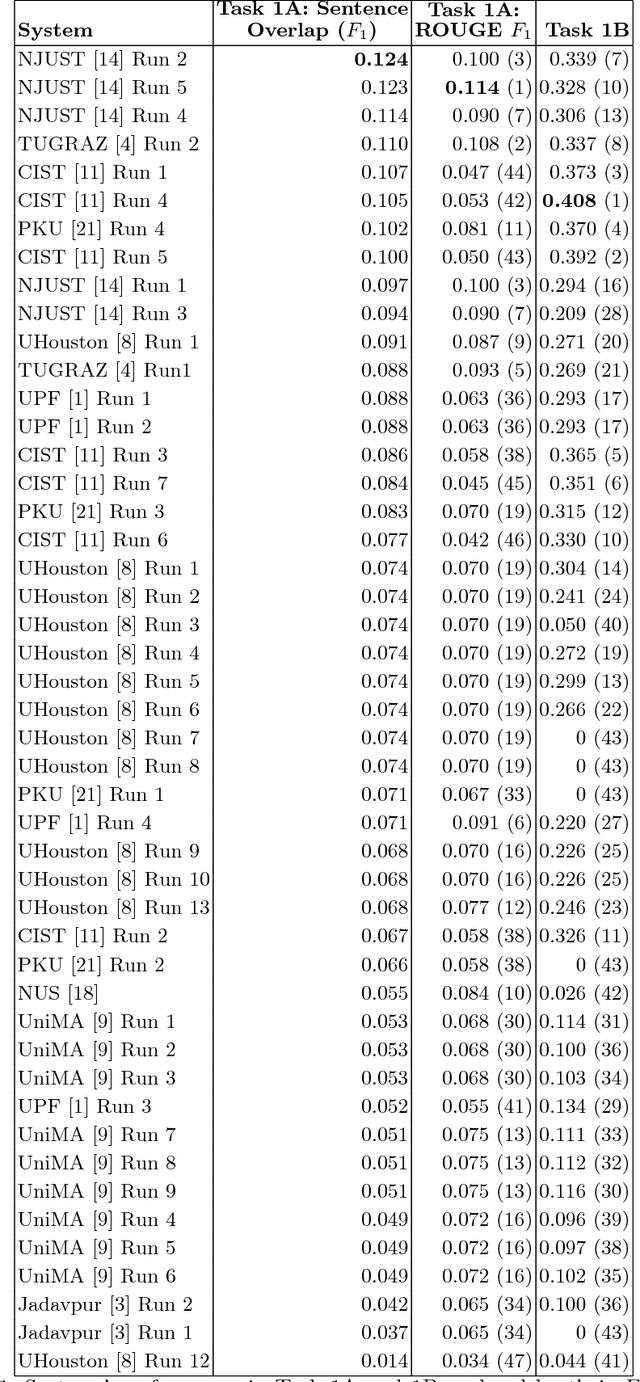

This overview describes the official results of the CL-SciSumm Shared Task 2018 -- the first medium-scale shared task on scientific document summarization in the computational linguistics (CL) domain. This year, the dataset comprised 60 annotated sets of citing and reference papers from the open access research papers in the CL domain. The Shared Task was organized as a part of the 41st Annual Conference of the Special Interest Group in Information Retrieval (SIGIR), held in Ann Arbor, USA in July 2018. We compare the participating systems in terms of two evaluation metrics. The annotated dataset and evaluation scripts can be accessed and used by the community from: \url{https://github.com/WING-NUS/scisumm-corpus}.
Overview and Results: CL-SciSumm Shared Task 2019
Jul 23, 2019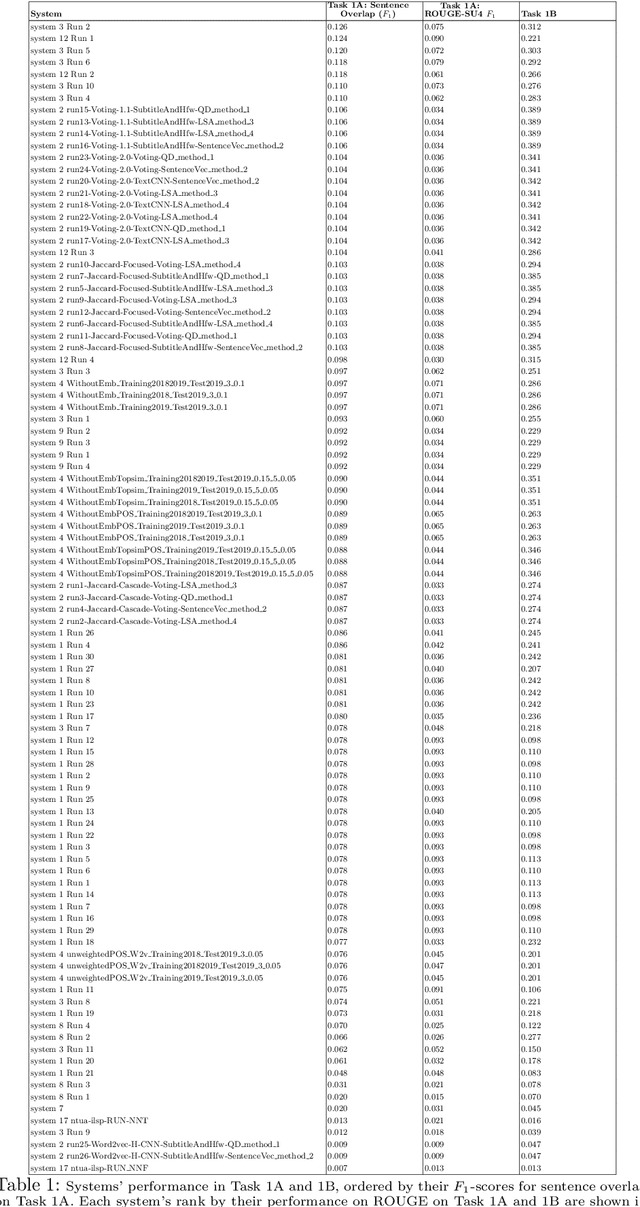
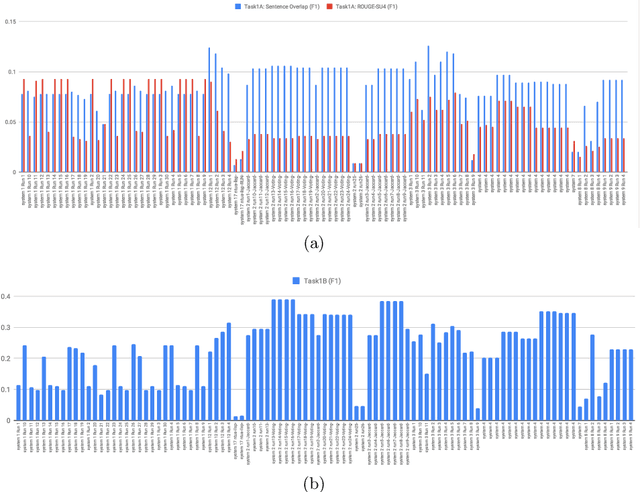
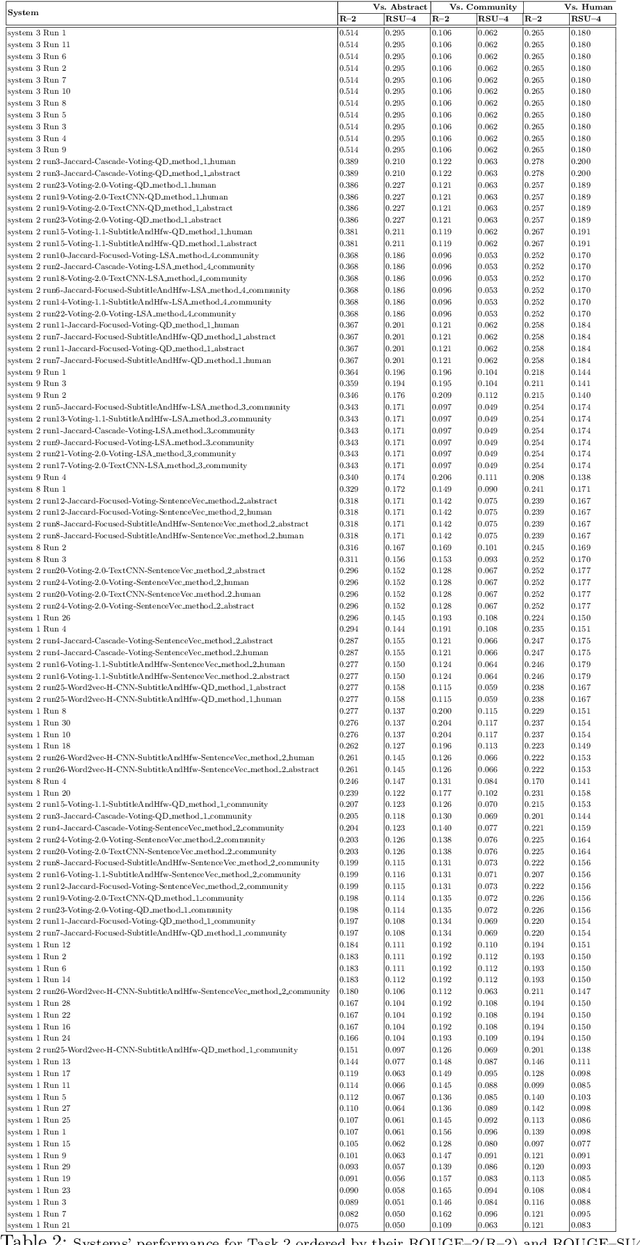
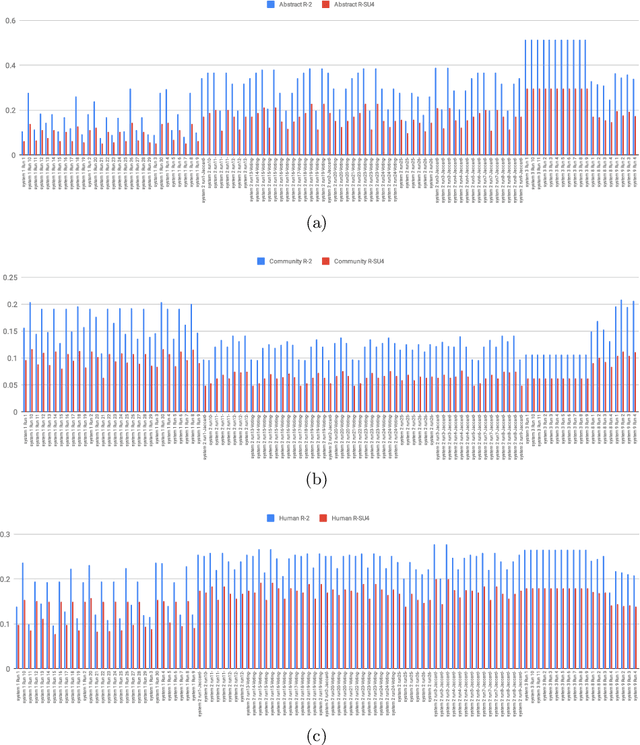
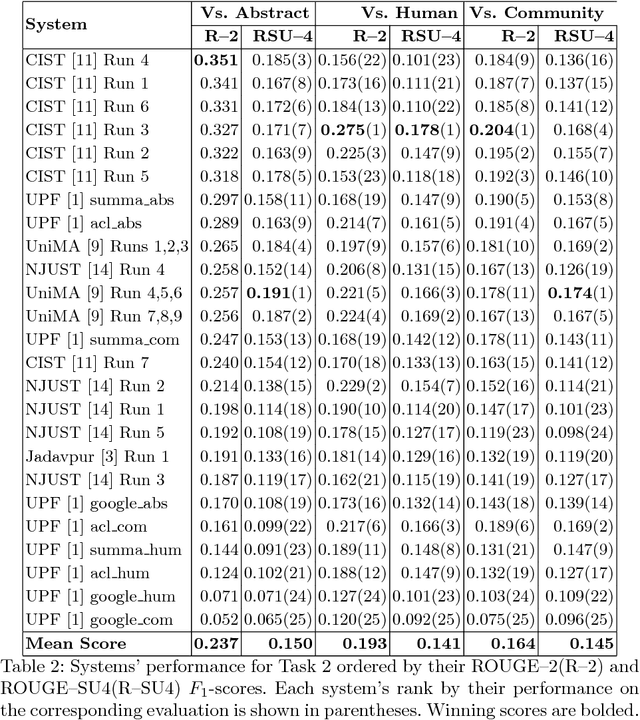
The CL-SciSumm Shared Task is the first medium-scale shared task on scientific document summarization in the computational linguistics~(CL) domain. In 2019, it comprised three tasks: (1A) identifying relationships between citing documents and the referred document, (1B) classifying the discourse facets, and (2) generating the abstractive summary. The dataset comprised 40 annotated sets of citing and reference papers of the CL-SciSumm 2018 corpus and 1000 more from the SciSummNet dataset. All papers are from the open access research papers in the CL domain. This overview describes the participation and the official results of the CL-SciSumm 2019 Shared Task, organized as a part of the 42nd Annual Conference of the Special Interest Group in Information Retrieval (SIGIR), held in Paris, France in July 2019. We compare the participating systems in terms of two evaluation metrics and discuss the use of ROUGE as an evaluation metric. The annotated dataset used for this shared task and the scripts used for evaluation can be accessed and used by the community at: https://github.com/WING-NUS/scisumm-corpus.
Creating A Neural Pedagogical Agent by Jointly Learning to Review and Assess
Jul 01, 2019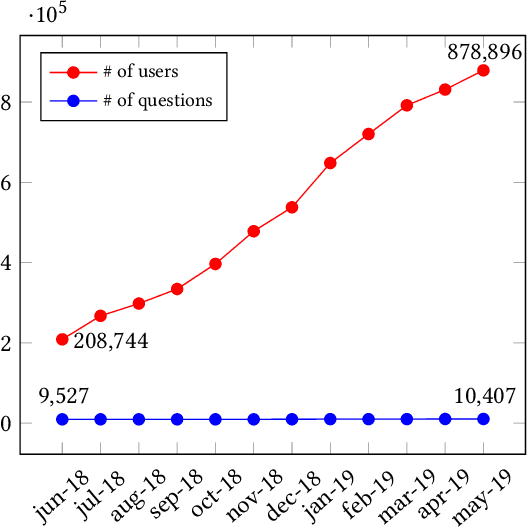
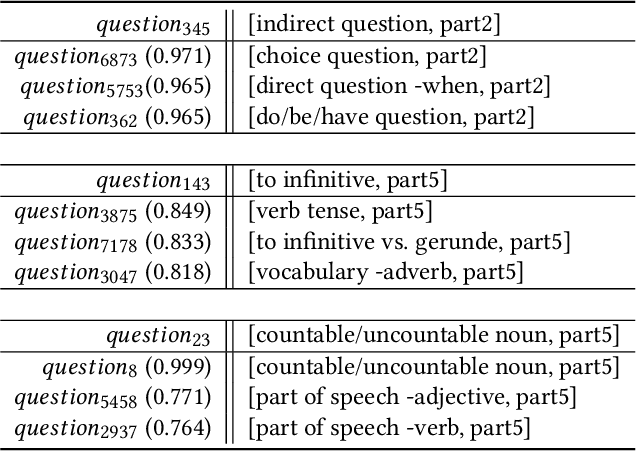

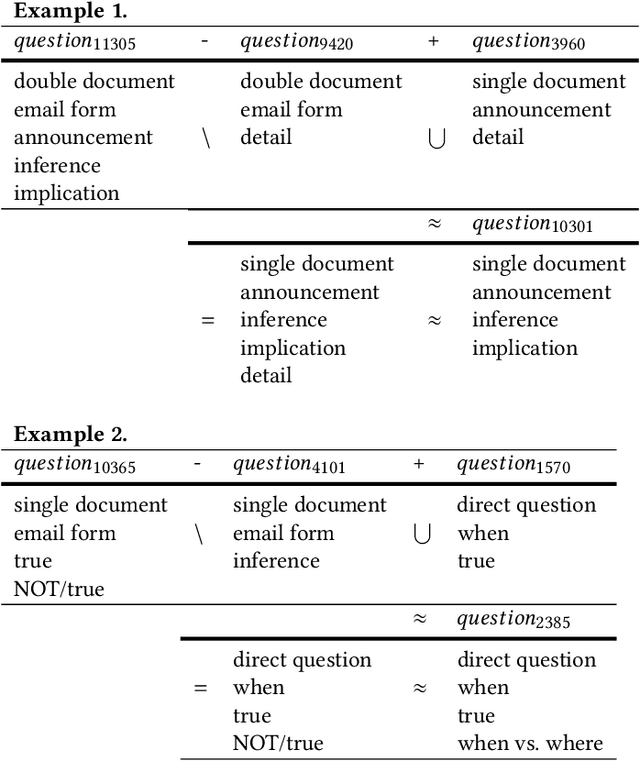
Machine learning plays an increasing role in intelligent tutoring systems as both the amount of data available and specialization among students grow. Nowadays, these systems are frequently deployed on mobile applications. Users on such mobile education platforms are dynamic, frequently being added, accessing the application with varying levels of focus, and changing while using the service. The education material itself, on the other hand, is often static and is an exhaustible resource whose use in tasks such as problem recommendation must be optimized. The ability to update user models with respect to educational material in real-time is thus essential; however, existing approaches require time-consuming re-training of user features whenever new data is added. In this paper, we introduce a neural pedagogical agent for real-time user modeling in the task of predicting user response correctness, a central task for mobile education applications. Our model, inspired by work in natural language processing on sequence modeling and machine translation, updates user features in real-time via bidirectional recurrent neural networks with an attention mechanism over embedded question-response pairs. We experiment on the mobile education application SantaTOEIC, which has 559k users, 66M response data points as well as a set of 10k study problems each expert-annotated with topic tags and gathered since 2016. Our model outperforms existing approaches over several metrics in predicting user response correctness, notably out-performing other methods on new users without large question-response histories. Additionally, our attention mechanism and annotated tag set allow us to create an interpretable education platform, with a smart review system that addresses the aforementioned issue of varied user attention and problem exhaustion.
Improving Low-Resource Cross-lingual Document Retrieval by Reranking with Deep Bilingual Representations
Jun 08, 2019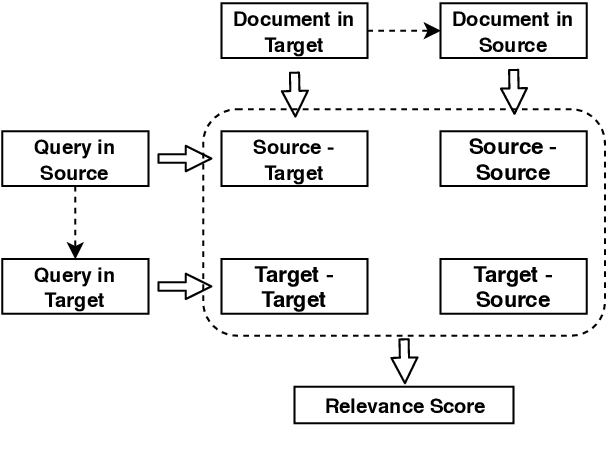
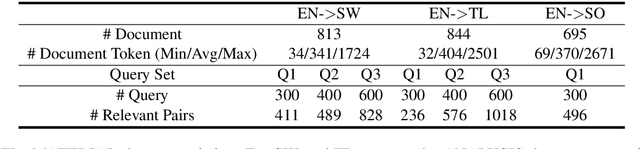

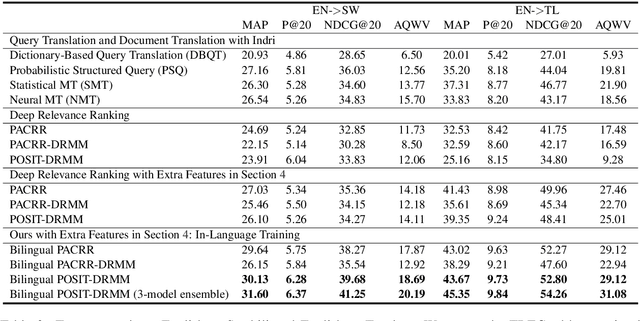
In this paper, we propose to boost low-resource cross-lingual document retrieval performance with deep bilingual query-document representations. We match queries and documents in both source and target languages with four components, each of which is implemented as a term interaction-based deep neural network with cross-lingual word embeddings as input. By including query likelihood scores as extra features, our model effectively learns to rerank the retrieved documents by using a small number of relevance labels for low-resource language pairs. Due to the shared cross-lingual word embedding space, the model can also be directly applied to another language pair without any training label. Experimental results on the MATERIAL dataset show that our model outperforms the competitive translation-based baselines on English-Swahili, English-Tagalog, and English-Somali cross-lingual information retrieval tasks.
SParC: Cross-Domain Semantic Parsing in Context
Jun 05, 2019
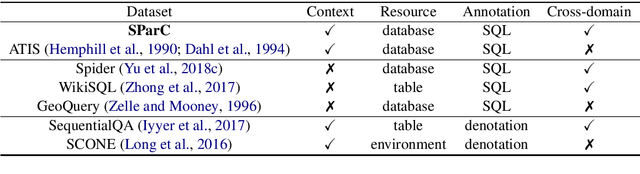

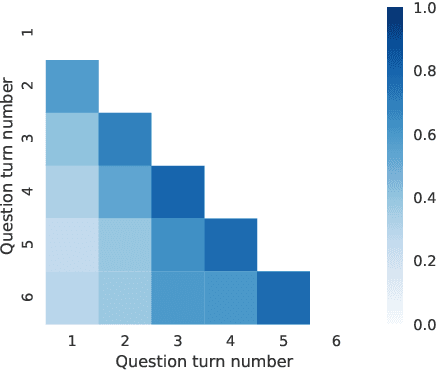
We present SParC, a dataset for cross-domainSemanticParsing inContext that consists of 4,298 coherent question sequences (12k+ individual questions annotated with SQL queries). It is obtained from controlled user interactions with 200 complex databases over 138 domains. We provide an in-depth analysis of SParC and show that it introduces new challenges compared to existing datasets. SParC demonstrates complex contextual dependencies, (2) has greater semantic diversity, and (3) requires generalization to unseen domains due to its cross-domain nature and the unseen databases at test time. We experiment with two state-of-the-art text-to-SQL models adapted to the context-dependent, cross-domain setup. The best model obtains an exact match accuracy of 20.2% over all questions and less than10% over all interaction sequences, indicating that the cross-domain setting and the con-textual phenomena of the dataset present significant challenges for future research. The dataset, baselines, and leaderboard are released at https://yale-lily.github.io/sparc.
Syntax-aware Neural Semantic Role Labeling with Supertags
Apr 03, 2019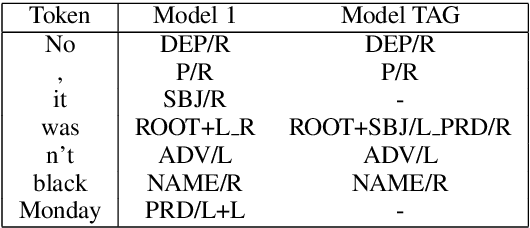
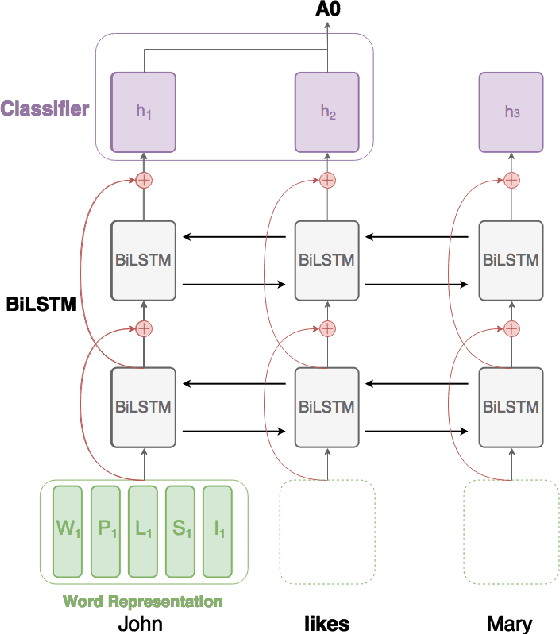
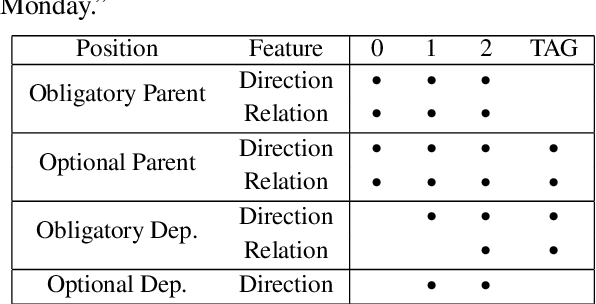
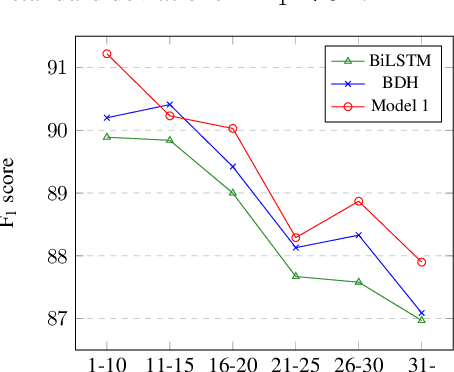
We introduce a new syntax-aware model for dependency-based semantic role labeling that outperforms syntax-agnostic models for English and Spanish. We use a BiLSTM to tag the text with supertags extracted from dependency parses, and we feed these supertags, along with words and parts of speech, into a deep highway BiLSTM for semantic role labeling. Our model combines the strengths of earlier models that performed SRL on the basis of a full dependency parse with more recent models that use no syntactic information at all. Our local and non-ensemble model achieves state-of-the-art performance on the CoNLL 09 English and Spanish datasets. SRL models benefit from syntactic information, and we show that supertagging is a simple, powerful, and robust way to incorporate syntax into a neural SRL system.
Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task
Oct 25, 2018
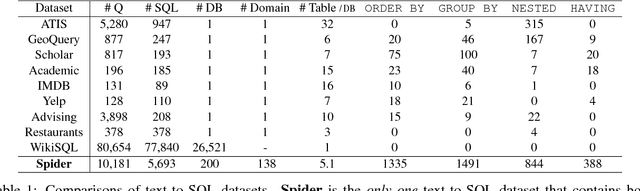
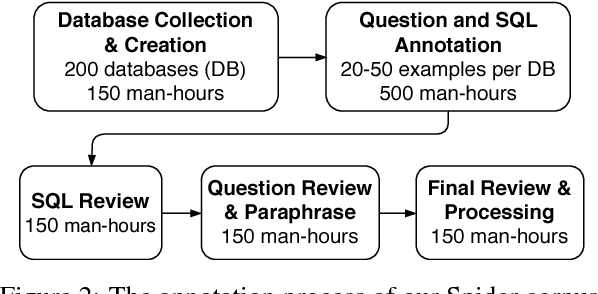
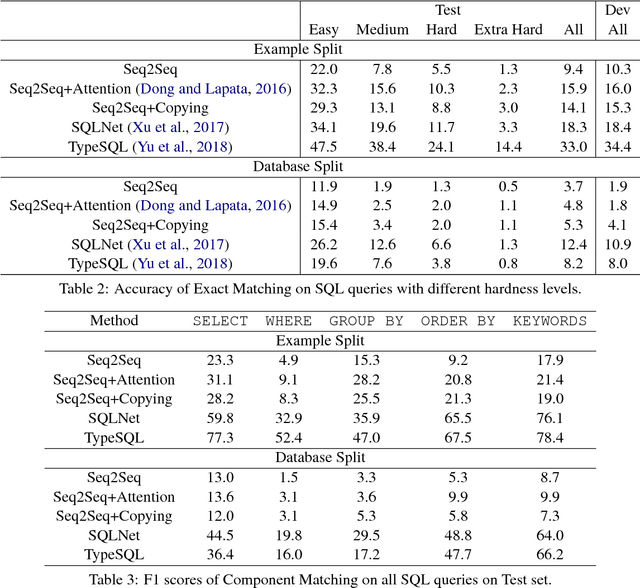
We present Spider, a large-scale, complex and cross-domain semantic parsing and text-to-SQL dataset annotated by 11 college students. It consists of 10,181 questions and 5,693 unique complex SQL queries on 200 databases with multiple tables, covering 138 different domains. We define a new complex and cross-domain semantic parsing and text-to-SQL task where different complex SQL queries and databases appear in train and test sets. In this way, the task requires the model to generalize well to both new SQL queries and new database schemas. Spider is distinct from most of the previous semantic parsing tasks because they all use a single database and the exact same programs in the train set and the test set. We experiment with various state-of-the-art models and the best model achieves only 12.4% exact matching accuracy on a database split setting. This shows that Spider presents a strong challenge for future research. Our dataset and task are publicly available at https://yale-lily.github.io/spider
SyntaxSQLNet: Syntax Tree Networks for Complex and Cross-DomainText-to-SQL Task
Oct 25, 2018
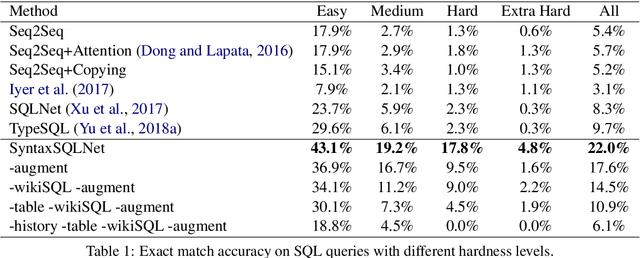

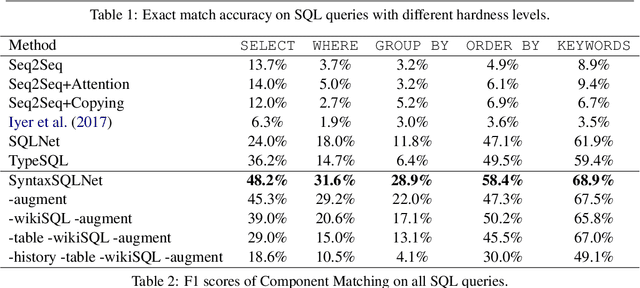
Most existing studies in text-to-SQL tasks do not require generating complex SQL queries with multiple clauses or sub-queries, and generalizing to new, unseen databases. In this paper we propose SyntaxSQLNet, a syntax tree network to address the complex and cross-domain text-to-SQL generation task. SyntaxSQLNet employs a SQL specific syntax tree-based decoder with SQL generation path history and table-aware column attention encoders. We evaluate SyntaxSQLNet on the Spider text-to-SQL task, which contains databases with multiple tables and complex SQL queries with multiple SQL clauses and nested queries. We use a database split setting where databases in the test set are unseen during training. Experimental results show that SyntaxSQLNet can handle a significantly greater number of complex SQL examples than prior work, outperforming the previous state-of-the-art model by 7.3% in exact matching accuracy. We also show that SyntaxSQLNet can further improve the performance by an additional 7.5% using a cross-domain augmentation method, resulting in a 14.8% improvement in total. To our knowledge, we are the first to study this complex and cross-domain text-to-SQL task.