 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaw Produce Quality Detection with Shifted Window Self-Attention
Dec 24, 2021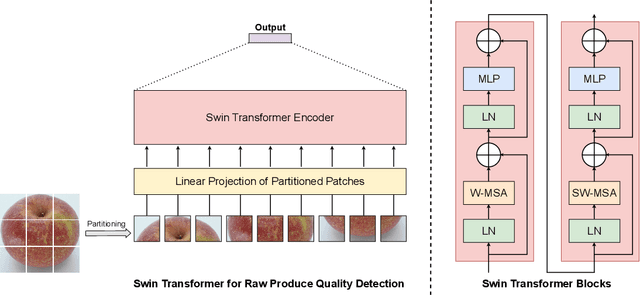
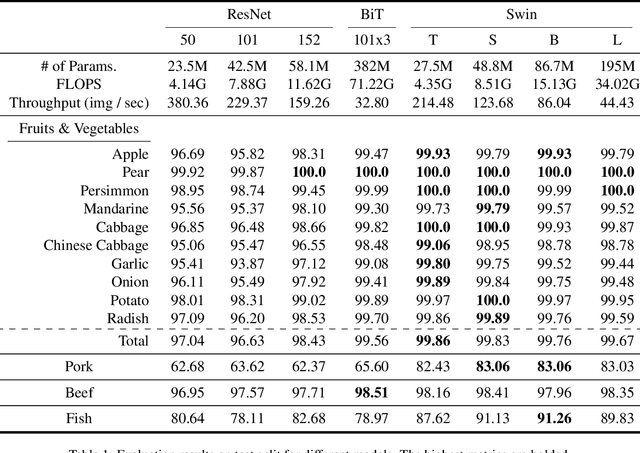
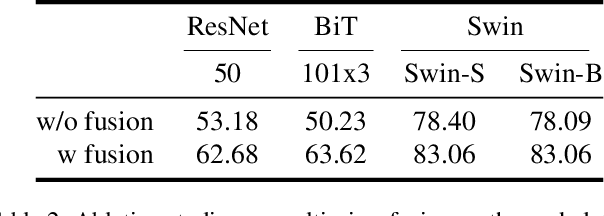
Global food insecurity is expected to worsen in the coming decades with the accelerated rate of climate change and the rapidly increasing population. In this vein, it is important to remove inefficiencies at every level of food production. The recent advances in deep learning can help reduce such inefficiencies, yet their application has not yet become mainstream throughout the industry, inducing economic costs at a massive scale. To this point, modern techniques such as CNNs (Convolutional Neural Networks) have been applied to RPQD (Raw Produce Quality Detection) tasks. On the other hand, Transformer's successful debut in the vision among other modalities led us to expect a better performance with these Transformer-based models in RPQD. In this work, we exclusively investigate the recent state-of-the-art Swin (Shifted Windows) Transformer which computes self-attention in both intra- and inter-window fashion. We compare Swin Transformer against CNN models on four RPQD image datasets, each containing different kinds of raw produce: fruits and vegetables, fish, pork, and beef. We observe that Swin Transformer not only achieves better or competitive performance but also is data- and compute-efficient, making it ideal for actual deployment in real-world setting. To the best of our knowledge, this is the first large-scale empirical study on RPQD task, which we hope will gain more attention in future works.
Knowledge Transfer by Discriminative Pre-training for Academic Performance Prediction
Jul 12, 2021

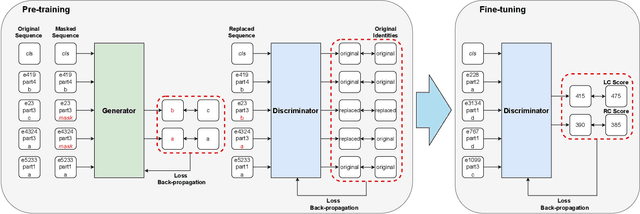

The needs for precisely estimating a student's academic performance have been emphasized with an increasing amount of attention paid to Intelligent Tutoring System (ITS). However, since labels for academic performance, such as test scores, are collected from outside of ITS, obtaining the labels is costly, leading to label-scarcity problem which brings challenge in taking machine learning approaches for academic performance prediction. To this end, inspired by the recent advancement of pre-training method in natural language processing community, we propose DPA, a transfer learning framework with Discriminative Pre-training tasks for Academic performance prediction. DPA pre-trains two models, a generator and a discriminator, and fine-tunes the discriminator on academic performance prediction. In DPA's pre-training phase, a sequence of interactions where some tokens are masked is provided to the generator which is trained to reconstruct the original sequence. Then, the discriminator takes an interaction sequence where the masked tokens are replaced by the generator's outputs, and is trained to predict the originalities of all tokens in the sequence. Compared to the previous state-of-the-art generative pre-training method, DPA is more sample efficient, leading to fast convergence to lower academic performance prediction error. We conduct extensive experimental studies on a real-world dataset obtained from a multi-platform ITS application and show that DPA outperforms the previous state-of-the-art generative pre-training method with a reduction of 4.05% in mean absolute error and more robust to increased label-scarcity.
Consistency and Monotonicity Regularization for Neural Knowledge Tracing
May 03, 2021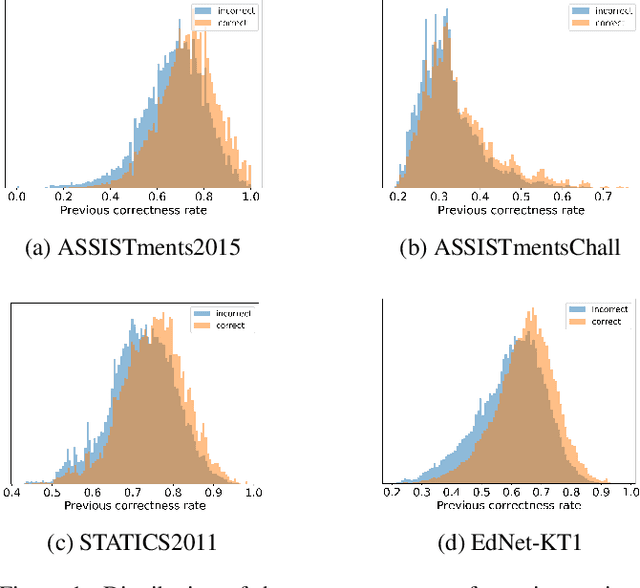
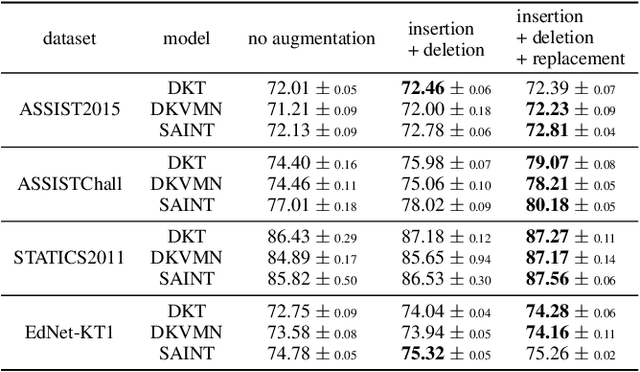

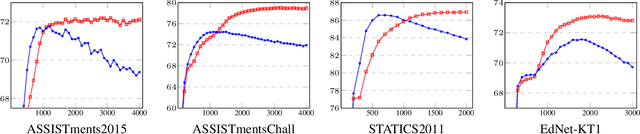
Knowledge Tracing (KT), tracking a human's knowledge acquisition, is a central component in online learning and AI in Education. In this paper, we present a simple, yet effective strategy to improve the generalization ability of KT models: we propose three types of novel data augmentation, coined replacement, insertion, and deletion, along with corresponding regularization losses that impose certain consistency or monotonicity biases on the model's predictions for the original and augmented sequence. Extensive experiments on various KT benchmarks show that our regularization scheme consistently improves the model performances, under 3 widely-used neural networks and 4 public benchmarks, e.g., it yields 6.3% improvement in AUC under the DKT model and the ASSISTmentsChall dataset.
SAINT+: Integrating Temporal Features for EdNet Correctness Prediction
Oct 19, 2020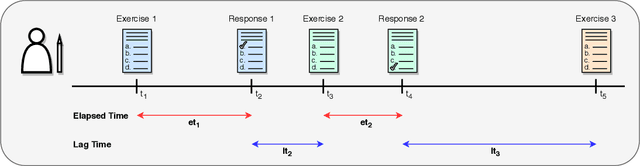

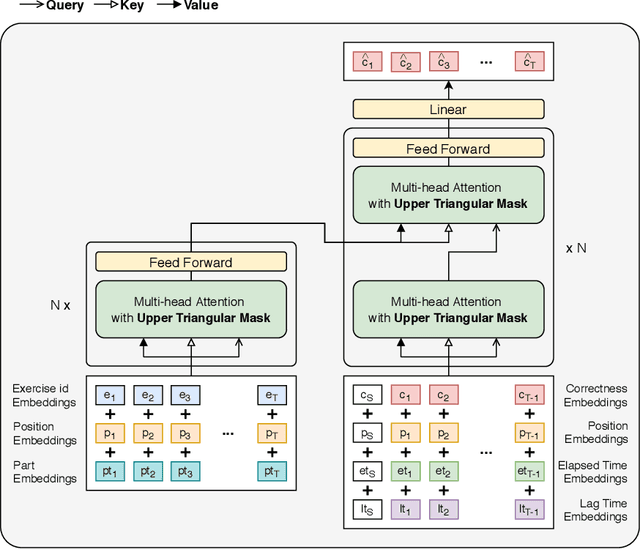
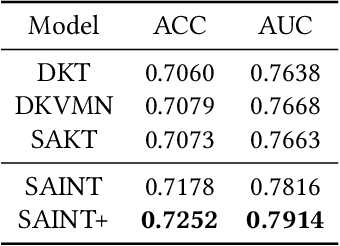
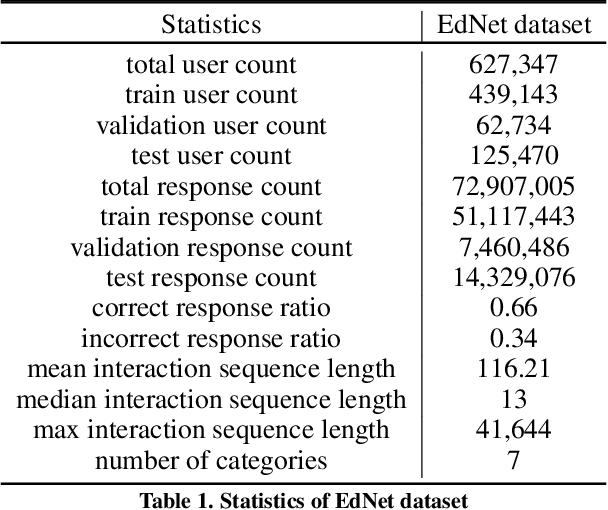
We propose SAINT+, a successor of SAINT which is a Transformer based knowledge tracing model that separately processes exercise information and student response information. Following the architecture of SAINT, SAINT+ has an encoder-decoder structure where the encoder applies self-attention layers to a stream of exercise embeddings, and the decoder alternately applies self-attention layers and encoder-decoder attention layers to streams of response embeddings and encoder output. Moreover, SAINT+ incorporates two temporal feature embeddings into the response embeddings: elapsed time, the time taken for a student to answer, and lag time, the time interval between adjacent learning activities. We empirically evaluate the effectiveness of SAINT+ on EdNet, the largest publicly available benchmark dataset in the education domain. Experimental results show that SAINT+ achieves state-of-the-art performance in knowledge tracing with an improvement of 1.25% in area under receiver operating characteristic curve compared to SAINT, the current state-of-the-art model in EdNet dataset.
Prescribing Deep Attentive Score Prediction Attracts Improved Student Engagement
May 19, 2020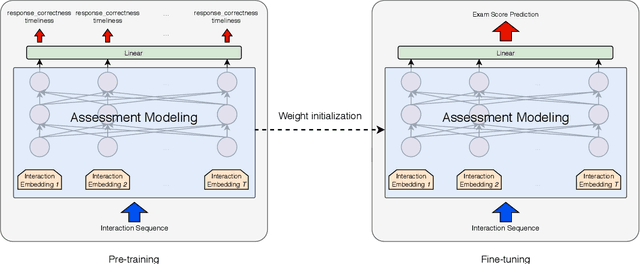
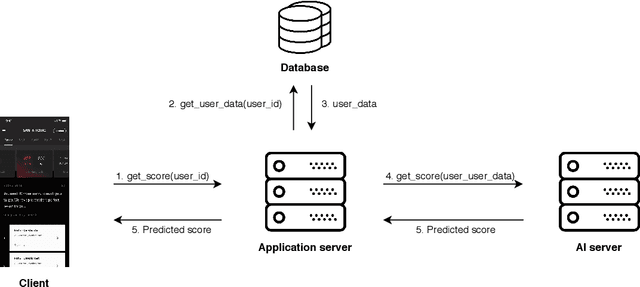
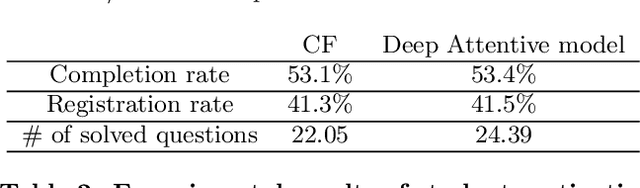
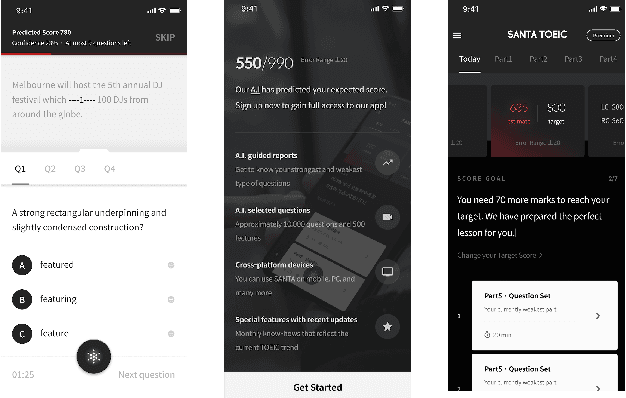
Intelligent Tutoring Systems (ITSs) have been developed to provide students with personalized learning experiences by adaptively generating learning paths optimized for each individual. Within the vast scope of ITS, score prediction stands out as an area of study that enables students to construct individually realistic goals based on their current position. Via the expected score provided by the ITS, a student can instantaneously compare one's expected score to one's actual score, which directly corresponds to the reliability that the ITS can instill. In other words, refining the precision of predicted scores strictly correlates to the level of confidence that a student may have with an ITS, which will evidently ensue improved student engagement. However, previous studies have solely concentrated on improving the performance of a prediction model, largely lacking focus on the benefits generated by its practical application. In this paper, we demonstrate that the accuracy of the score prediction model deployed in a real-world setting significantly impacts user engagement by providing empirical evidence. To that end, we apply a state-of-the-art deep attentive neural network-based score prediction model to Santa, a multi-platform English ITS with approximately 780K users in South Korea that exclusively focuses on the TOEIC (Test of English for International Communications) standardized examinations. We run a controlled A/B test on the ITS with two models, respectively based on collaborative filtering and deep attentive neural networks, to verify whether the more accurate model engenders any student engagement. The results conclude that the attentive model not only induces high student morale (e.g. higher diagnostic test completion ratio, number of questions answered, etc.) but also encourages active engagement (e.g. higher purchase rate, improved total profit, etc.) on Santa.
Choose Your Own Question: Encouraging Self-Personalization in Learning Path Construction
May 08, 2020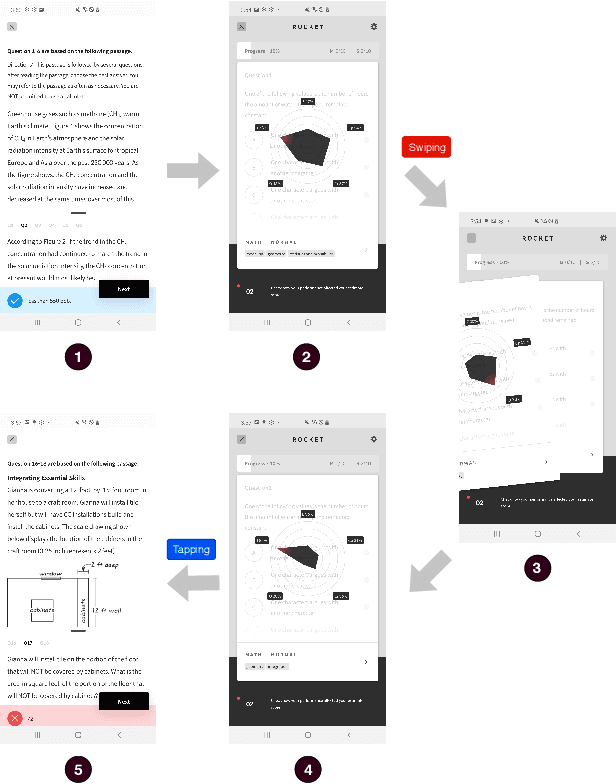
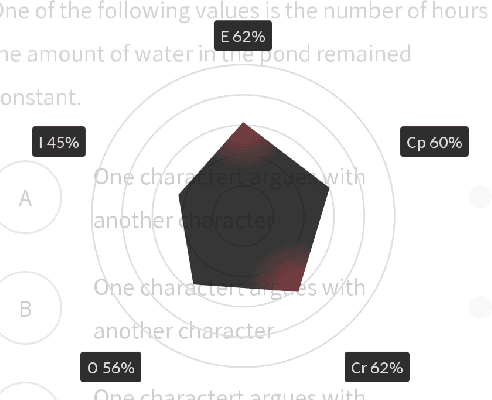
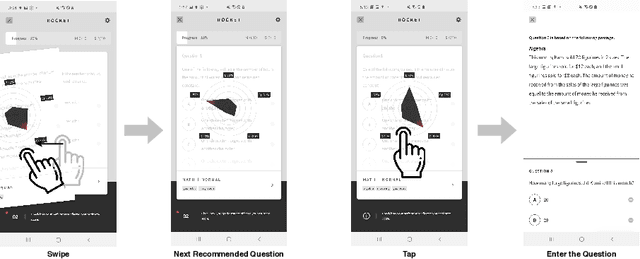
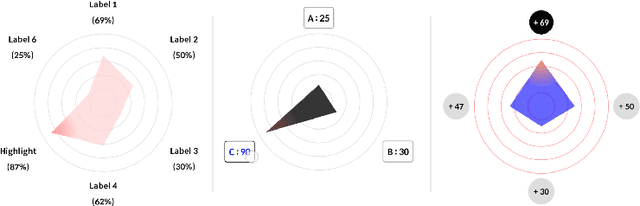
Learning Path Recommendation is the heart of adaptive learning, the educational paradigm of an Interactive Educational System (IES) providing a personalized learning experience based on the student's history of learning activities. In typical existing IESs, the student must fully consume a recommended learning item to be provided a new recommendation. This workflow comes with several limitations. For example, there is no opportunity for the student to give feedback on the choice of learning items made by the IES. Furthermore, the mechanism by which the choice is made is opaque to the student, limiting the student's ability to track their learning. To this end, we introduce Rocket, a Tinder-like User Interface for a general class of IESs. Rocket provides a visual representation of Artificial Intelligence (AI)-extracted features of learning materials, allowing the student to quickly decide whether the material meets their needs. The student can choose between engaging with the material and receiving a new recommendation by swiping or tapping. Rocket offers the following potential improvements for IES User Interfaces: First, Rocket enhances the explainability of IES recommendations by showing students a visual summary of the meaningful AI-extracted features used in the decision-making process. Second, Rocket enables self-personalization of the learning experience by leveraging the students' knowledge of their own abilities and needs. Finally, Rocket provides students with fine-grained information on their learning path, giving them an avenue to assess their own skills and track their learning progress. We present the source code of Rocket, in which we emphasize the independence and extensibility of each component, and make it publicly available for all purposes.
Towards an Appropriate Query, Key, and Value Computation for Knowledge Tracing
Feb 14, 2020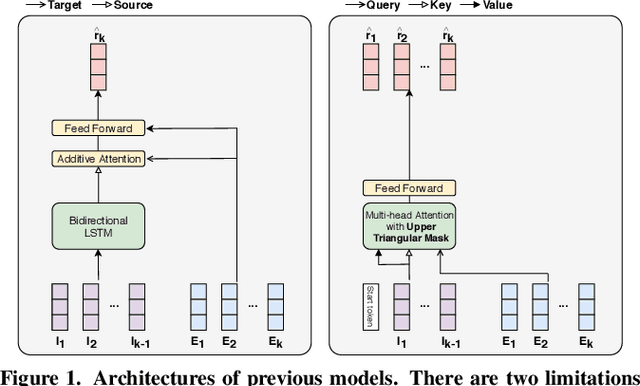
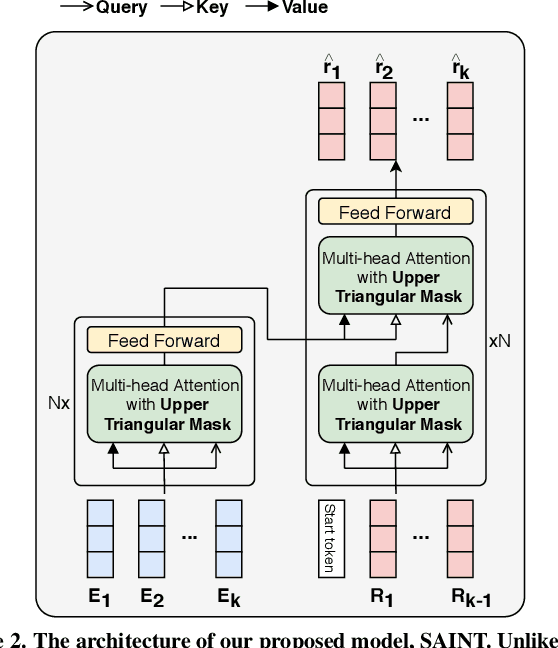

Knowledge tracing, the act of modeling a student's knowledge through learning activities, is an extensively studied problem in the field of computer-aided education. Although models with attention mechanism have outperformed traditional approaches such as Bayesian knowledge tracing and collaborative filtering, they share two limitations. Firstly, the models rely on shallow attention layers and fail to capture complex relations among exercises and responses over time. Secondly, different combinations of queries, keys and values for the self-attention layer for knowledge tracing were not extensively explored. Usual practice of using exercises and interactions (exercise-response pairs) as queries and keys/values respectively lacks empirical support. In this paper, we propose a novel Transformer based model for knowledge tracing, SAINT: Separated Self-AttentIve Neural Knowledge Tracing. SAINT has an encoder-decoder structure where exercise and response embedding sequence separately enter the encoder and the decoder respectively, which allows to stack attention layers multiple times. To the best of our knowledge, this is the first work to suggest an encoder-decoder model for knowledge tracing that applies deep self-attentive layers to exercises and responses separately. The empirical evaluations on a large-scale knowledge tracing dataset show that SAINT achieves the state-of-the-art performance in knowledge tracing with the improvement of AUC by 1.8% compared to the current state-of-the-art models.
Deep Attentive Study Session Dropout Prediction in Mobile Learning Environment
Feb 14, 2020
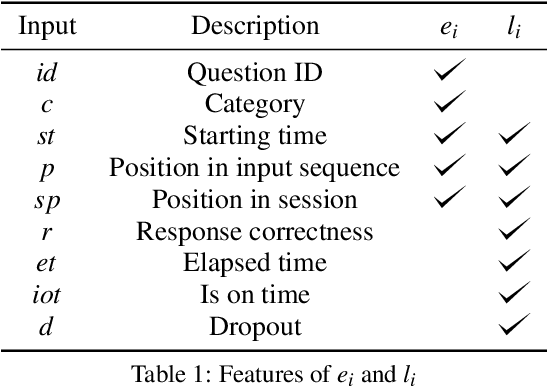
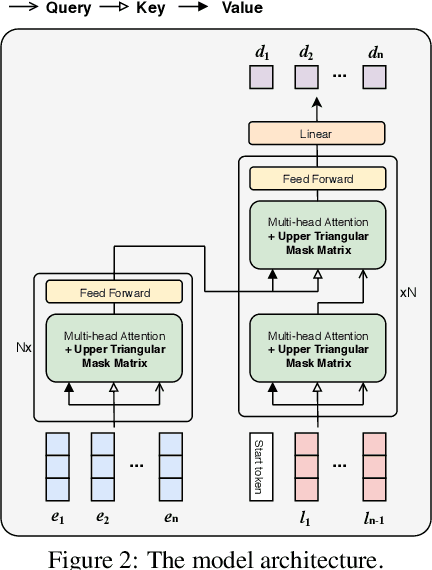

Student dropout prediction provides an opportunity to improve student engagement, which maximizes the overall effectiveness of learning experiences. However, researches on student dropout were mainly conducted on school dropout or course dropout, and study session dropout in a mobile learning environment has not been considered thoroughly. In this paper, we investigate the study session dropout prediction problem in a mobile learning environment. First, we define the concept of the study session, study session dropout and study session dropout prediction task in a mobile learning environment. Based on the definitions, we propose a novel Transformer based model for predicting study session dropout, DAS: Deep Attentive Study Session Dropout Prediction in Mobile Learning Environment. DAS has an encoder-decoder structure which is composed of stacked multi-head attention and point-wise feed-forward networks. The deep attentive computations in DAS are capable of capturing complex relations among dynamic student interactions. To the best of our knowledge, this is the first attempt to investigate study session dropout in a mobile learning environment. Empirical evaluations on a large-scale dataset show that DAS achieves the best performance with a significant improvement in area under the receiver operating characteristic curve compared to baseline models.
Assessment Modeling: Fundamental Pre-training Tasks for Interactive Educational Systems
Jan 01, 2020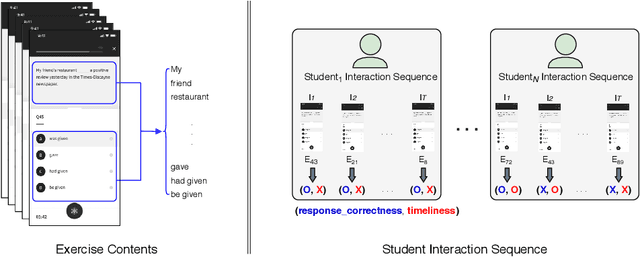

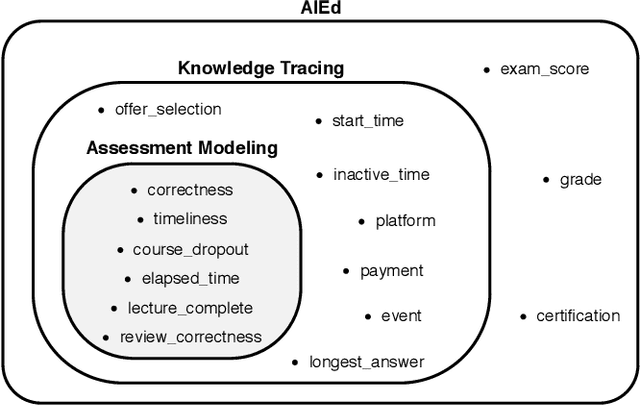
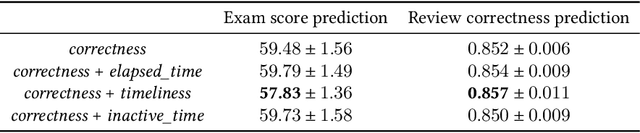
Interactive Educational Systems (IESs) have developed rapidly in recent years to address the issue of quality and affordability of education. Analogous to other domains in AI, there are specific tasks of AIEd for which labels are scarce. For instance, labels like exam score and grade are considered important in educational and social context. However, obtaining the labels is costly as they require student actions taken outside the system. Likewise, while student events like course dropout and review correctness are automatically recorded by IESs, they are few in number as the events occur sporadically in practice. A common way of circumventing the label-scarcity problem is the pre-train/fine-tine method. Accordingly, existing works pre-train a model to learn representations of contents in learning items. However, such methods fail to utilize the student interaction data available and model student learning behavior. To this end, we propose assessment modeling, fundamental pre-training tasks for IESs. An assessment is a feature of student-system interactions which can act as pedagogical evaluation, such as student response correctness or timeliness. Assessment modeling is the prediction of assessments conditioned on the surrounding context of interactions. Although it is natural to pre-train interactive features available in large amount, narrowing down the prediction targets to assessments holds relevance to the label-scarce educational problems while reducing irrelevant noises. To the best of our knowledge, this is the first work investigating appropriate pre-training method of predicting educational features from student-system interactions. While the effectiveness of different combinations of assessments is open for exploration, we suggest assessment modeling as a guiding principle for selecting proper pre-training tasks for the label-scarce educational problems.
EdNet: A Large-Scale Hierarchical Dataset in Education
Dec 06, 2019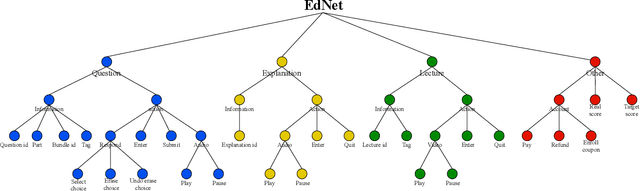
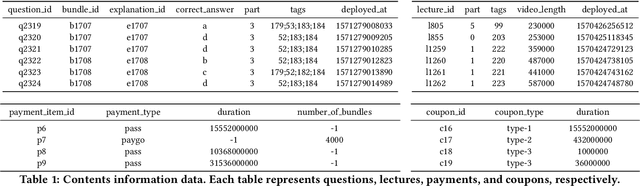
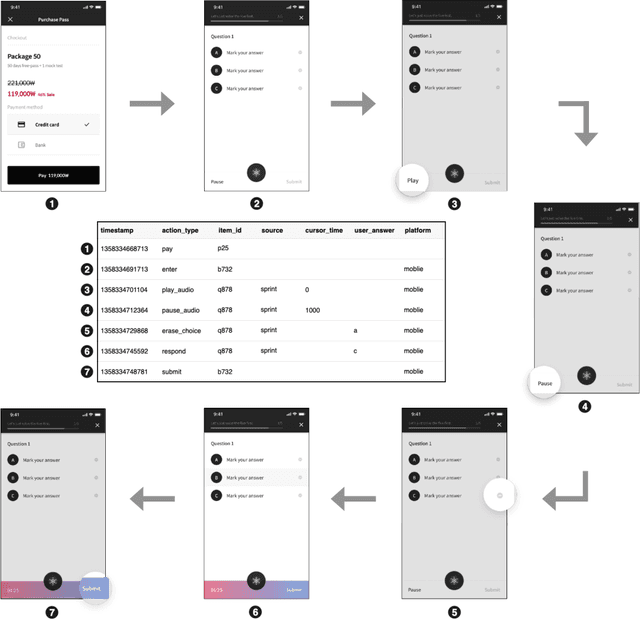
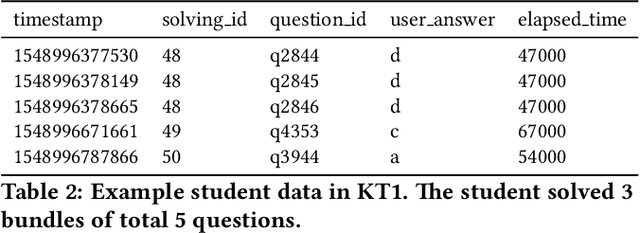
With advances in Artificial Intelligence in Education (AIEd) and the ever-growing scale of Interactive Educational Systems (IESs), data-driven approach has become a common recipe for various tasks such as knowledge tracing and learning path recommendation. Unfortunately, collecting real students' interaction data is often challenging, which results in the lack of public large-scale benchmark dataset reflecting a wide variety of student behaviors in modern IESs. Although several datasets, such as ASSISTments, Junyi Academy, Synthetic and STATICS, are publicly available and widely used, they are not large enough to leverage the full potential of state-of-the-art data-driven models and limits the recorded behaviors to question-solving activities. To this end, we introduce EdNet, a large-scale hierarchical dataset of diverse student activities collected by Santa, a multi-platform self-study solution equipped with artificial intelligence tutoring system. EdNet contains 131,441,538 interactions from 784,309 students collected over more than 2 years, which is the largest among the ITS datasets released to the public so far. Unlike existing datasets, EdNet provides a wide variety of student actions ranging from question-solving to lecture consumption and item purchasing. Also, EdNet has a hierarchical structure where the student actions are divided into 4 different levels of abstractions. The features of EdNet are domain-agnostic, allowing EdNet to be extended to different domains easily. The dataset is publicly released under Creative Commons Attribution-NonCommercial 4.0 International license for research purposes. We plan to host challenges in multiple AIEd tasks with EdNet to provide a common ground for the fair comparison between different state of the art models and encourage the development of practical and effective methods.