 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRissanen Data Analysis: Examining Dataset Characteristics via Description Length
Mar 05, 2021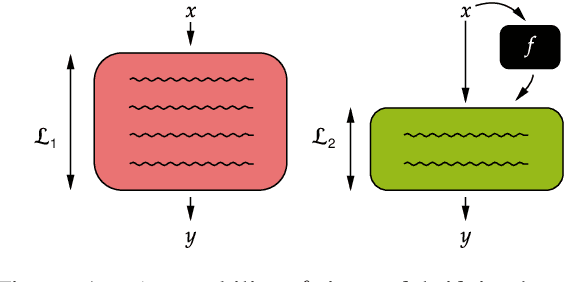

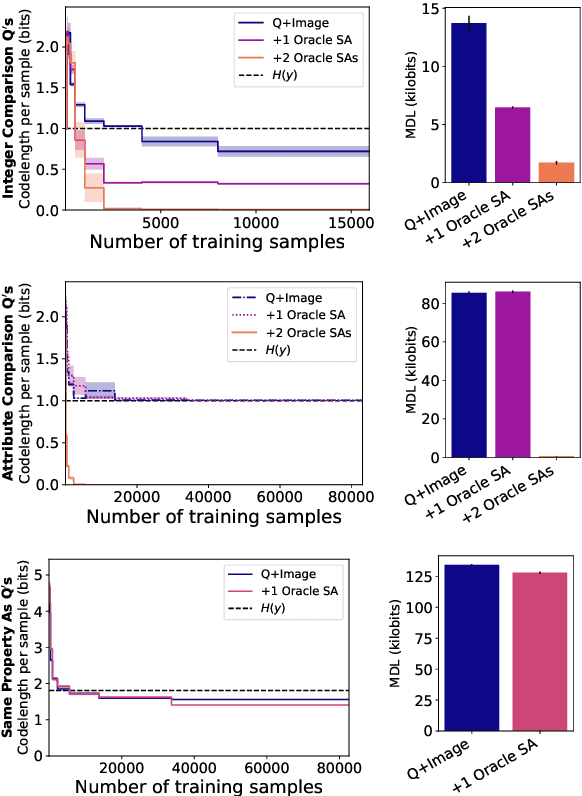
We introduce a method to determine if a certain capability helps to achieve an accurate model of given data. We view labels as being generated from the inputs by a program composed of subroutines with different capabilities, and we posit that a subroutine is useful if and only if the minimal program that invokes it is shorter than the one that does not. Since minimum program length is uncomputable, we instead estimate the labels' minimum description length (MDL) as a proxy, giving us a theoretically-grounded method for analyzing dataset characteristics. We call the method Rissanen Data Analysis (RDA) after the father of MDL, and we showcase its applicability on a wide variety of settings in NLP, ranging from evaluating the utility of generating subquestions before answering a question, to analyzing the value of rationales and explanations, to investigating the importance of different parts of speech, and uncovering dataset gender bias.
Learning from the Worst: Dynamically Generated Datasets to Improve Online Hate Detection
Dec 31, 2020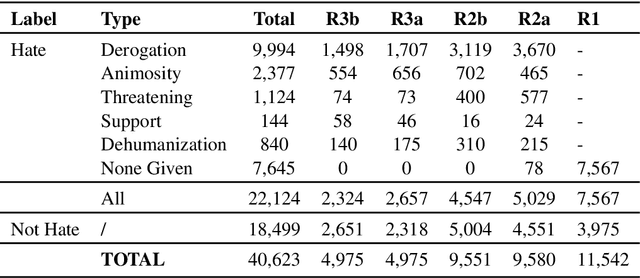
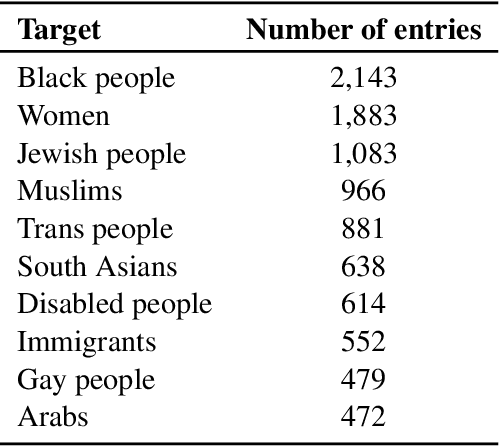
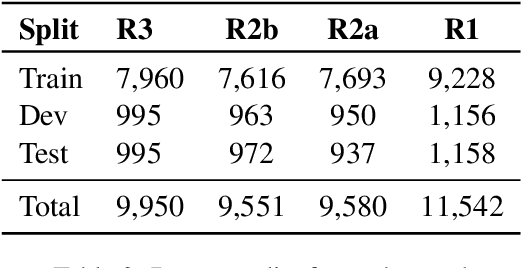
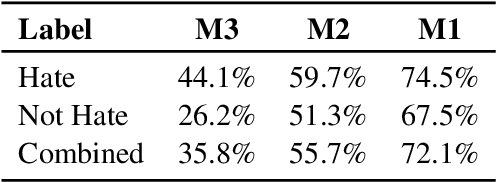
We present a first-of-its-kind large synthetic training dataset for online hate classification, created from scratch with trained annotators over multiple rounds of dynamic data collection. We provide a 40,623 example dataset with annotations for fine-grained labels, including a large number of challenging contrastive perturbation examples. Unusually for an abusive content dataset, it comprises 54% hateful and 46% not hateful entries. We show that model performance and robustness can be greatly improved using the dynamic data collection paradigm. The model error rate decreased across rounds, from 72.1% in the first round to 35.8% in the last round, showing that models became increasingly harder to trick -- even though content become progressively more adversarial as annotators became more experienced. Hate speech detection is an important and subtle problem that is still very challenging for existing AI methods. We hope that the models, dataset and dynamic system that we present here will help improve current approaches, having a positive social impact.
DynaSent: A Dynamic Benchmark for Sentiment Analysis
Dec 30, 2020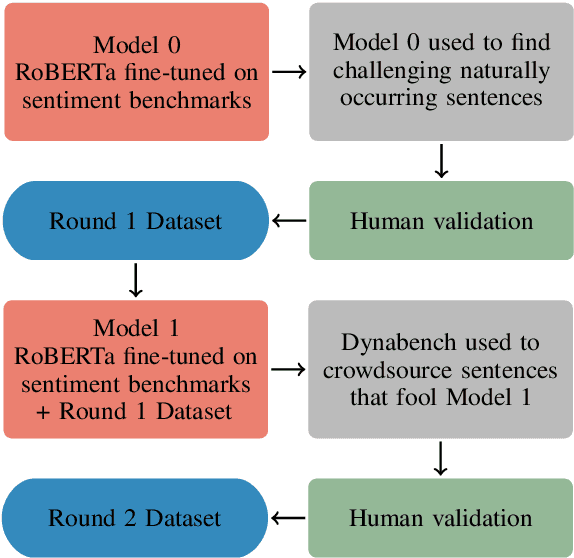
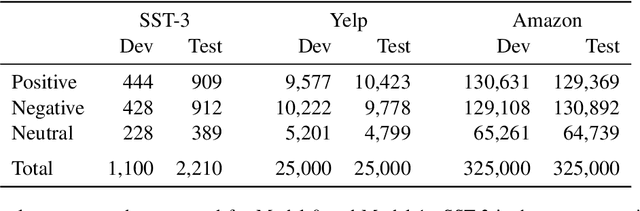
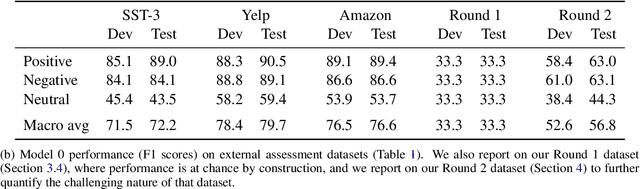
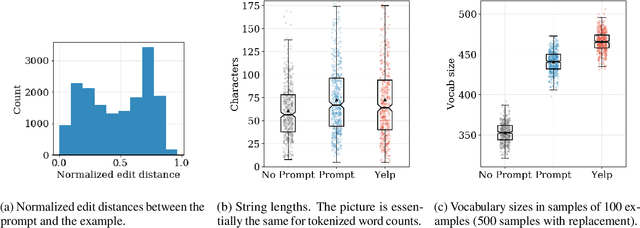
We introduce DynaSent ('Dynamic Sentiment'), a new English-language benchmark task for ternary (positive/negative/neutral) sentiment analysis. DynaSent combines naturally occurring sentences with sentences created using the open-source Dynabench Platform, which facilities human-and-model-in-the-loop dataset creation. DynaSent has a total of 121,634 sentences, each validated by five crowdworkers, and its development and test splits are designed to produce chance performance for even the best models we have been able to develop; when future models solve this task, we will use them to create DynaSent version 2, continuing the dynamic evolution of this benchmark. Here, we report on the dataset creation effort, focusing on the steps we took to increase quality and reduce artifacts. We also present evidence that DynaSent's Neutral category is more coherent than the comparable category in other benchmarks, and we motivate training models from scratch for each round over successive fine-tuning.
Reservoir Transformer
Dec 30, 2020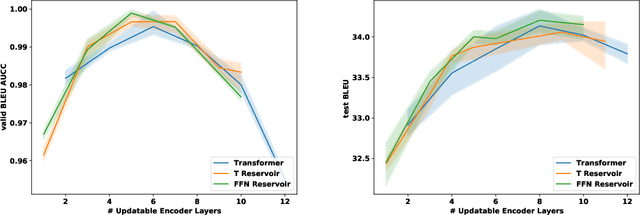
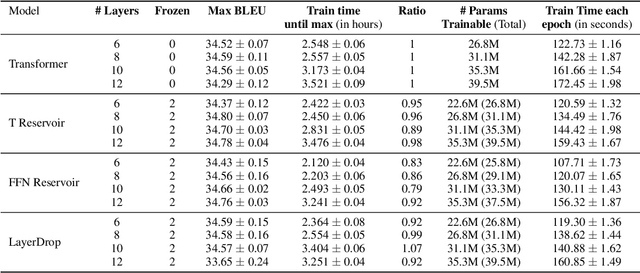
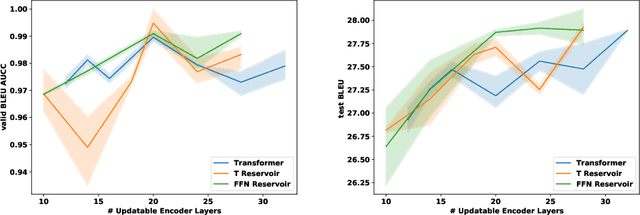
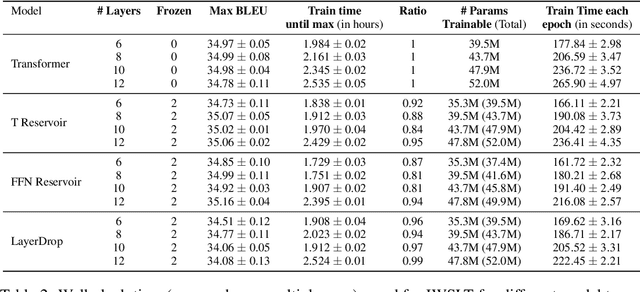
We demonstrate that transformers obtain impressive performance even when some of the layers are randomly initialized and never updated. Inspired by old and well-established ideas in machine learning, we explore a variety of non-linear "reservoir" layers interspersed with regular transformer layers, and show improvements in wall-clock compute time until convergence, as well as overall performance, on various machine translation and (masked) language modelling tasks.
I like fish, especially dolphins: Addressing Contradictions in Dialogue Modeling
Dec 28, 2020
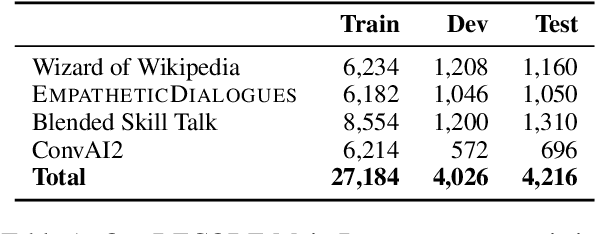

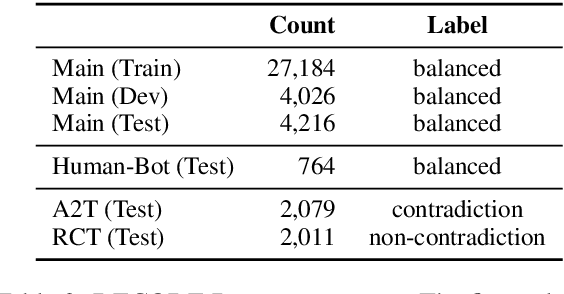
To quantify how well natural language understanding models can capture consistency in a general conversation, we introduce the DialoguE COntradiction DEtection task (DECODE) and a new conversational dataset containing both human-human and human-bot contradictory dialogues. We then compare a structured utterance-based approach of using pre-trained Transformer models for contradiction detection with the typical unstructured approach. Results reveal that: (i) our newly collected dataset is notably more effective at providing supervision for the dialogue contradiction detection task than existing NLI data including those aimed to cover the dialogue domain; (ii) the structured utterance-based approach is more robust and transferable on both analysis and out-of-distribution dialogues than its unstructured counterpart. We also show that our best contradiction detection model correlates well with human judgments and further provide evidence for its usage in both automatically evaluating and improving the consistency of state-of-the-art generative chatbots.
To what extent do human explanations of model behavior align with actual model behavior?
Dec 24, 2020
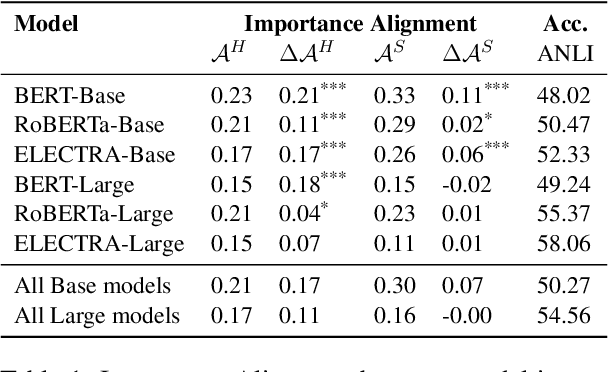
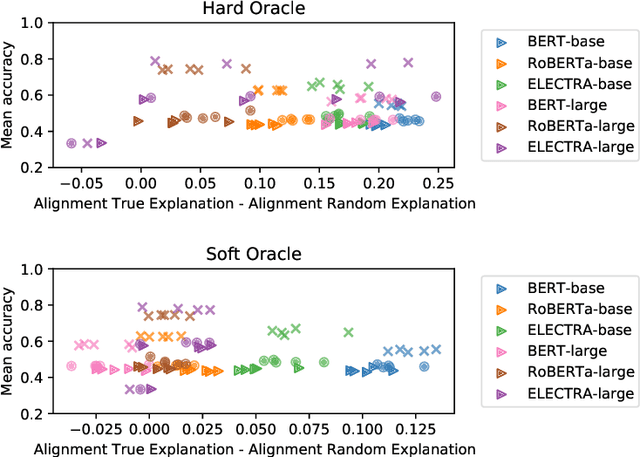
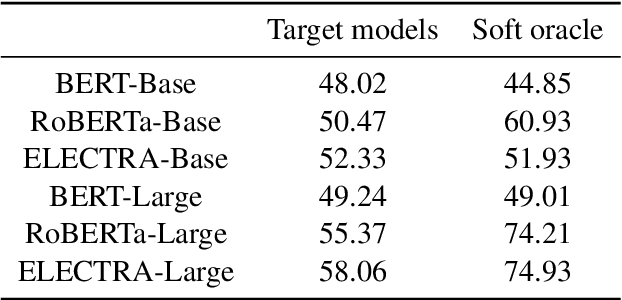
Given the increasingly prominent role NLP models (will) play in our lives, it is important to evaluate models on their alignment with human expectations of how models behave. Using Natural Language Inference (NLI) as a case study, we investigated the extent to which human-generated explanations of models' inference decisions align with how models actually make these decisions. More specifically, we defined two alignment metrics that quantify how well natural language human explanations align with model sensitivity to input words, as measured by integrated gradients. Then, we evaluated six different transformer models (the base and large versions of BERT, RoBERTa and ELECTRA), and found that the BERT-base model has the highest alignment with human-generated explanations, for both alignment metrics. Additionally, the base versions of the models we surveyed tended to have higher alignment with human-generated explanations than their larger counterparts, suggesting that increasing the number model parameters could result in worse alignment with human explanations. Finally, we find that a model's alignment with human explanations is not predicted by the model's accuracy on NLI, suggesting that accuracy and alignment are orthogonal, and both are important ways to evaluate models.
Exploring Zero-Shot Emergent Communication in Embodied Multi-Agent Populations
Oct 29, 2020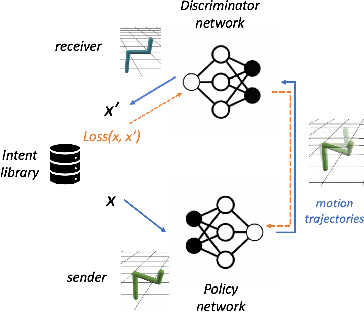

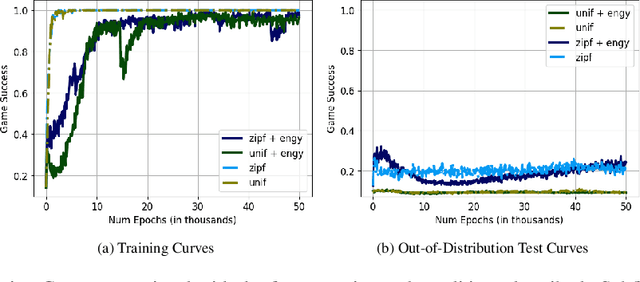

Effective communication is an important skill for enabling information exchange and cooperation in multi-agent settings. Indeed, emergent communication is now a vibrant field of research, with common settings involving discrete cheap-talk channels. One limitation of this setting is that it does not allow for the emergent protocols to generalize beyond the training partners. Furthermore, so far emergent communication has primarily focused on the use of symbolic channels. In this work, we extend this line of work to a new modality, by studying agents that learn to communicate via actuating their joints in a 3D environment. We show that under realistic assumptions, a non-uniform distribution of intents and a common-knowledge energy cost, these agents can find protocols that generalize to novel partners. We also explore and analyze specific difficulties associated with finding these solutions in practice. Finally, we propose and evaluate initial training improvements to address these challenges, involving both specific training curricula and providing the latent feature that can be coordinated on during training.
ANLIzing the Adversarial Natural Language Inference Dataset
Oct 24, 2020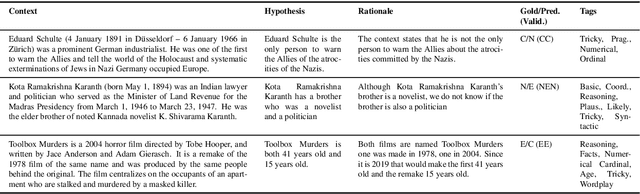
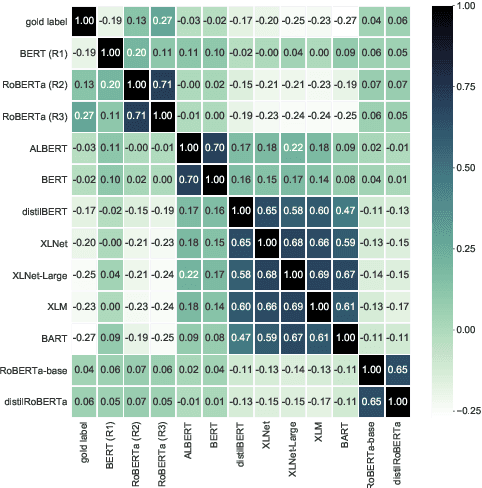
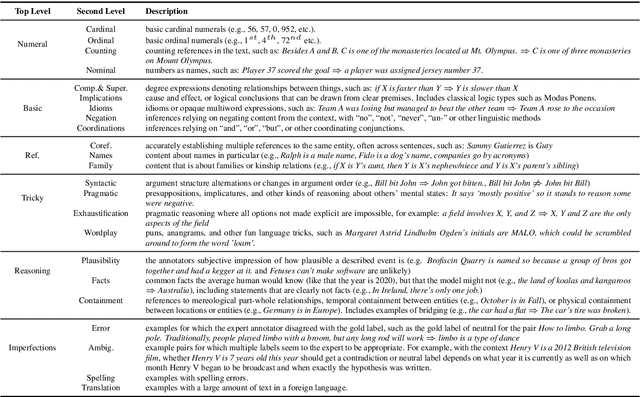
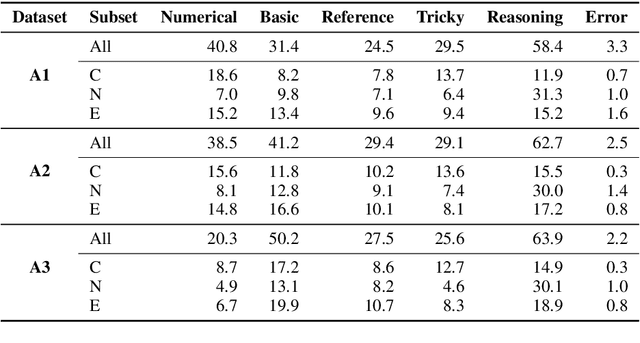
We perform an in-depth error analysis of Adversarial NLI (ANLI), a recently introduced large-scale human-and-model-in-the-loop natural language inference dataset collected over multiple rounds. We propose a fine-grained annotation scheme of the different aspects of inference that are responsible for the gold classification labels, and use it to hand-code all three of the ANLI development sets. We use these annotations to answer a variety of interesting questions: which inference types are most common, which models have the highest performance on each reasoning type, and which types are the most challenging for state of-the-art models? We hope that our annotations will enable more fine-grained evaluation of models trained on ANLI, provide us with a deeper understanding of where models fail and succeed, and help us determine how to train better models in future.
Learning Optimal Representations with the Decodable Information Bottleneck
Sep 27, 2020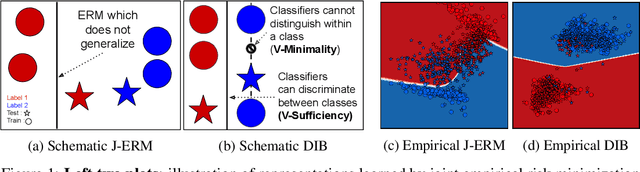
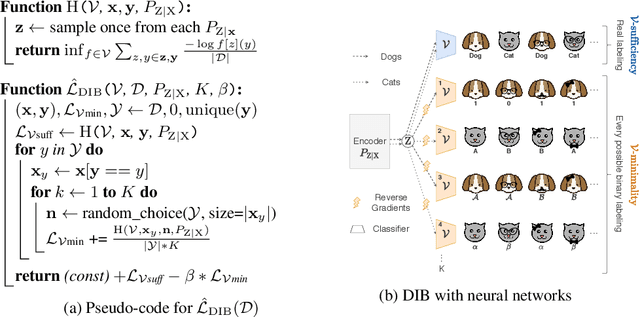

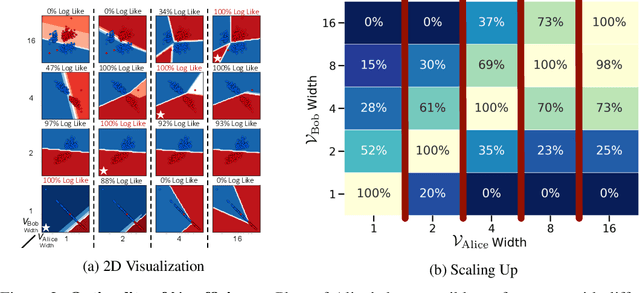
We address the question of characterizing and finding optimal representations for supervised learning. Traditionally, this question has been tackled using the Information Bottleneck, which compresses the inputs while retaining information about the targets, in a decoder-agnostic fashion. In machine learning, however, our goal is not compression but rather generalization, which is intimately linked to the predictive family or decoder of interest (e.g. linear classifier). We propose the Decodable Information Bottleneck (DIB) that considers information retention and compression from the perspective of the desired predictive family. As a result, DIB gives rise to representations that are optimal in terms of expected test performance and can be estimated with guarantees. Empirically, we show that the framework can be used to enforce a small generalization gap on downstream classifiers and to predict the generalization ability of neural networks.
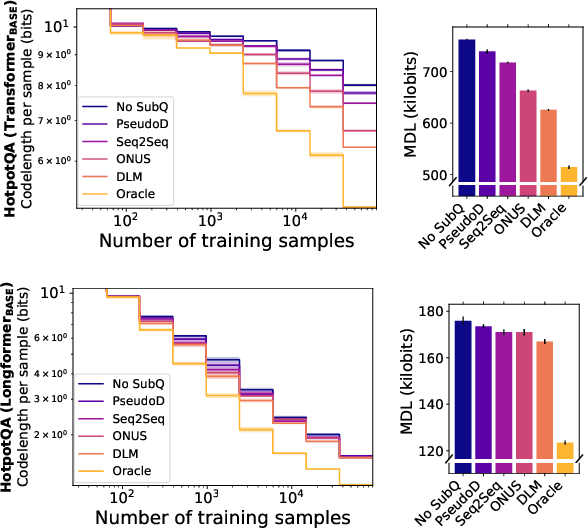
Answering Complex Open-Domain Questions with Multi-Hop Dense Retrieval
Sep 27, 2020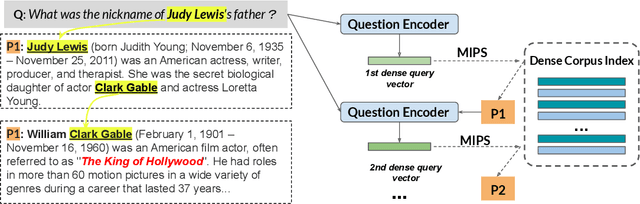
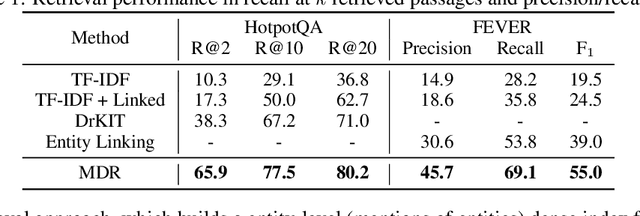
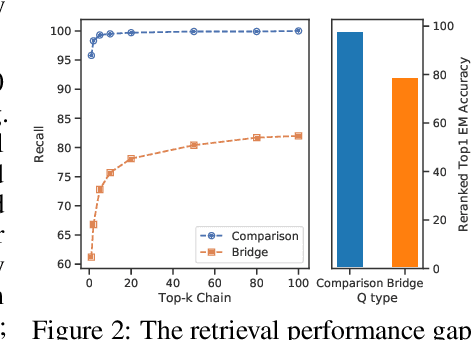

We propose a simple and efficient multi-hop dense retrieval approach for answering complex open-domain questions, which achieves state-of-the-art performance on two multi-hop datasets, HotpotQA and multi-evidence FEVER. Contrary to previous work, our method does not require access to any corpus-specific information, such as inter-document hyperlinks or human-annotated entity markers, and can be applied to any unstructured text corpus. Our system also yields a much better efficiency-accuracy trade-off, matching the best published accuracy on HotpotQA while being 10 times faster at inference time.