 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtractBench: A Benchmark and Evaluation Methodology for Complex Structured Extraction
Feb 13, 2026Unstructured documents like PDFs contain valuable structured information, but downstream systems require this data in reliable, standardized formats. LLMs are increasingly deployed to automate this extraction, making accuracy and reliability paramount. However, progress is bottlenecked by two gaps. First, no end-to-end benchmark evaluates PDF-to-JSON extraction under enterprise-scale schema breadth. Second, no principled methodology captures the semantics of nested extraction, where fields demand different notions of correctness (exact match for identifiers, tolerance for quantities, semantic equivalence for names), arrays require alignment, and omission must be distinguished from hallucination. We address both gaps with ExtractBench, an open-source benchmark and evaluation framework for PDF-to-JSON structured extraction. The benchmark pairs 35 PDF documents with JSON Schemas and human-annotated gold labels across economically valuable domains, yielding 12,867 evaluatable fields spanning schema complexities from tens to hundreds of fields. The evaluation framework treats the schema as an executable specification: each field declares its scoring metric. Baseline evaluations reveal that frontier models (GPT-5/5.2, Gemini-3 Flash/Pro, Claude 4.5 Opus/Sonnet) remain unreliable on realistic schemas. Performance degrades sharply with schema breadth, culminating in 0% valid output on a 369-field financial reporting schema across all tested models. We release ExtractBench at https://github.com/ContextualAI/extract-bench.
Classification is a RAG problem: A case study on hate speech detection
Aug 08, 2025Robust content moderation requires classification systems that can quickly adapt to evolving policies without costly retraining. We present classification using Retrieval-Augmented Generation (RAG), which shifts traditional classification tasks from determining the correct category in accordance with pre-trained parameters to evaluating content in relation to contextual knowledge retrieved at inference. In hate speech detection, this transforms the task from "is this hate speech?" to "does this violate the hate speech policy?" Our Contextual Policy Engine (CPE) - an agentic RAG system - demonstrates this approach and offers three key advantages: (1) robust classification accuracy comparable to leading commercial systems, (2) inherent explainability via retrieved policy segments, and (3) dynamic policy updates without model retraining. Through three experiments, we demonstrate strong baseline performance and show that the system can apply fine-grained policy control by correctly adjusting protection for specific identity groups without requiring retraining or compromising overall performance. These findings establish that RAG can transform classification into a more flexible, transparent, and adaptable process for content moderation and wider classification problems.
The Hateful Memes Challenge: Detecting Hate Speech in Multimodal Memes
Jun 08, 2020
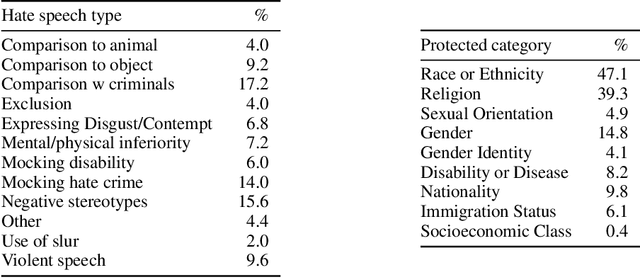
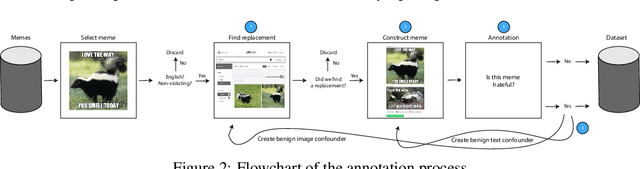

This work proposes a new challenge set for multimodal classification, focusing on detecting hate speech in multimodal memes. It is constructed such that unimodal models struggle and only multimodal models can succeed: difficult examples ("benign confounders") are added to the dataset to make it hard to rely on unimodal signals. The task requires subtle reasoning, yet is straightforward to evaluate as a binary classification problem. We provide baseline performance numbers for unimodal models, as well as for multimodal models with various degrees of sophistication. We find that state-of-the-art methods perform poorly compared to humans (64.73% vs. 84.7% accuracy), illustrating the difficulty of the task and highlighting the challenge that this important problem poses to the community.