 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDongmei Zhang
Homophily-oriented Heterogeneous Graph Rewiring
Feb 24, 2023
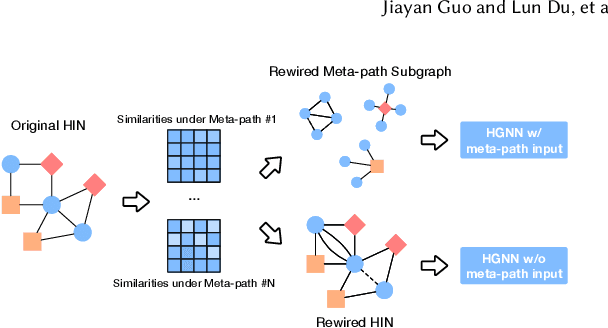
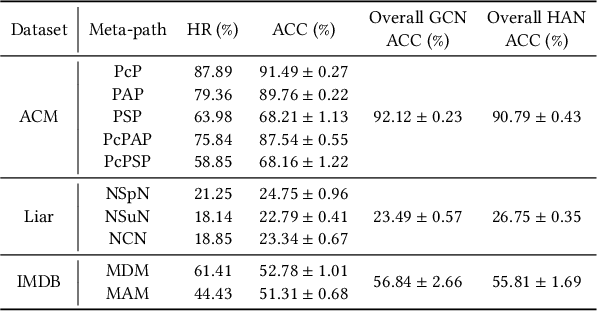
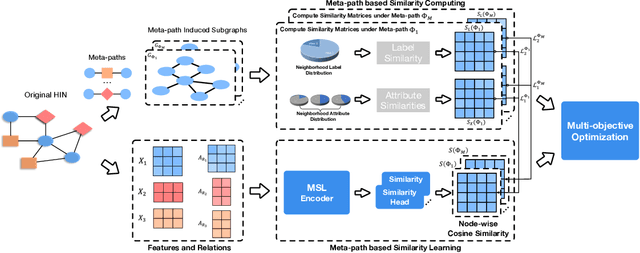
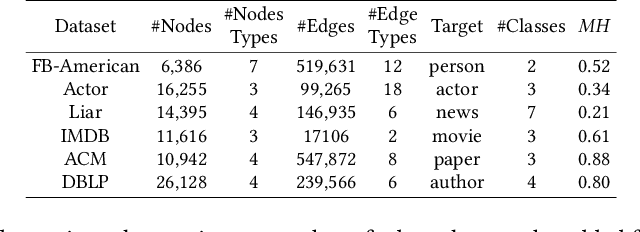
With the rapid development of the World Wide Web (WWW), heterogeneous graphs (HG) have explosive growth. Recently, heterogeneous graph neural network (HGNN) has shown great potential in learning on HG. Current studies of HGNN mainly focus on some HGs with strong homophily properties (nodes connected by meta-path tend to have the same labels), while few discussions are made in those that are less homophilous. Recently, there have been many works on homogeneous graphs with heterophily. However, due to heterogeneity, it is non-trivial to extend their approach to deal with HGs with heterophily. In this work, based on empirical observations, we propose a meta-path-induced metric to measure the homophily degree of a HG. We also find that current HGNNs may have degenerated performance when handling HGs with less homophilous properties. Thus it is essential to increase the generalization ability of HGNNs on non-homophilous HGs. To this end, we propose HDHGR, a homophily-oriented deep heterogeneous graph rewiring approach that modifies the HG structure to increase the performance of HGNN. We theoretically verify HDHGR. In addition, experiments on real-world HGs demonstrate the effectiveness of HDHGR, which brings at most more than 10% relative gain.
Robust Mid-Pass Filtering Graph Convolutional Networks
Feb 16, 2023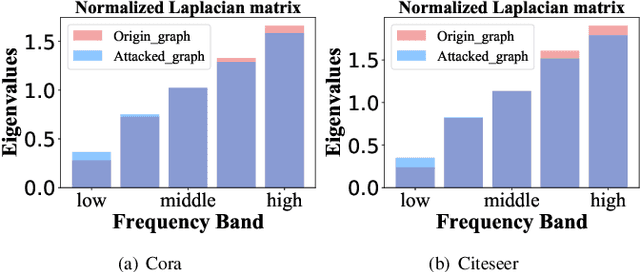
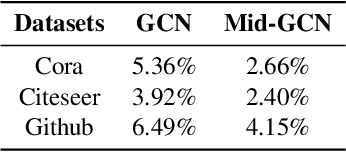
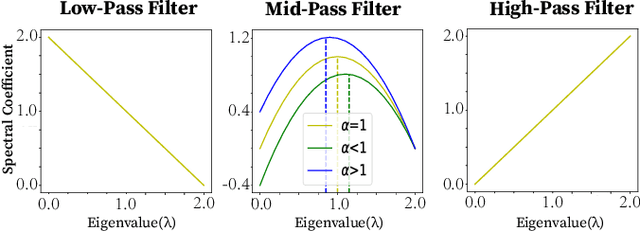
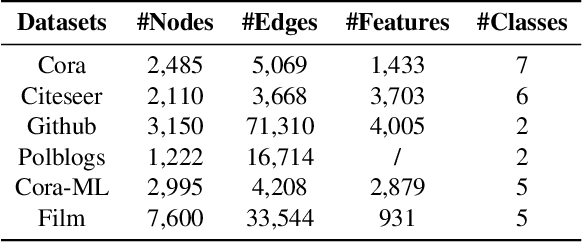
Graph convolutional networks (GCNs) are currently the most promising paradigm for dealing with graph-structure data, while recent studies have also shown that GCNs are vulnerable to adversarial attacks. Thus developing GCN models that are robust to such attacks become a hot research topic. However, the structural purification learning-based or robustness constraints-based defense GCN methods are usually designed for specific data or attacks, and introduce additional objective that is not for classification. Extra training overhead is also required in their design. To address these challenges, we conduct in-depth explorations on mid-frequency signals on graphs and propose a simple yet effective Mid-pass filter GCN (Mid-GCN). Theoretical analyses guarantee the robustness of signals through the mid-pass filter, and we also shed light on the properties of different frequency signals under adversarial attacks. Extensive experiments on six benchmark graph data further verify the effectiveness of our designed Mid-GCN in node classification accuracy compared to state-of-the-art GCNs under various adversarial attack strategies.
Conservative State Value Estimation for Offline Reinforcement Learning
Feb 14, 2023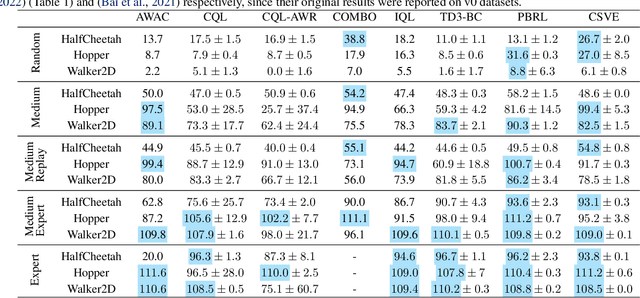
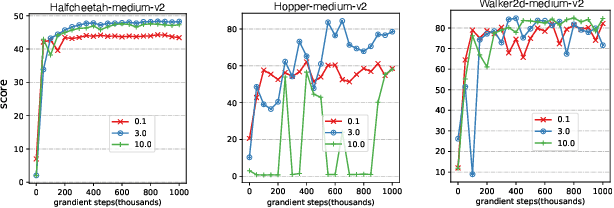
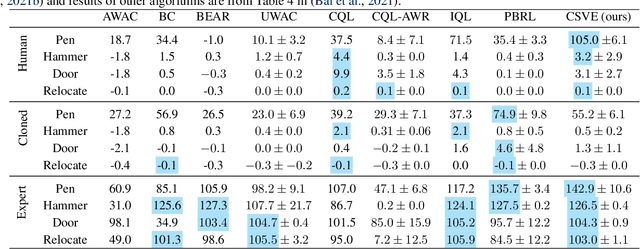
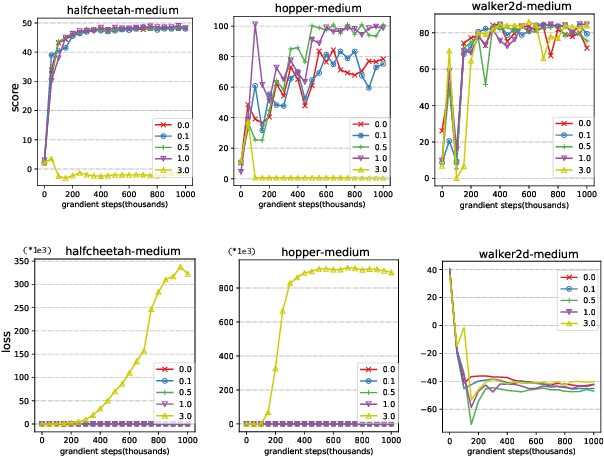
Offline reinforcement learning faces a significant challenge of value over-estimation due to the distributional drift between the dataset and the current learned policy, leading to learning failure in practice. The common approach is to incorporate a penalty term to reward or value estimation in the Bellman iterations. Meanwhile, to avoid extrapolation on out-of-distribution (OOD) states and actions, existing methods focus on conservative Q-function estimation. In this paper, we propose Conservative State Value Estimation (CSVE), a new approach that learns conservative V-function via directly imposing penalty on OOD states. Compared to prior work, CSVE allows more effective in-data policy optimization with conservative value guarantees. Further, we apply CSVE and develop a practical actor-critic algorithm in which the critic does the conservative value estimation by additionally sampling and penalizing the states \emph{around} the dataset, and the actor applies advantage weighted updates extended with state exploration to improve the policy. We evaluate in classic continual control tasks of D4RL, showing that our method performs better than the conservative Q-function learning methods and is strongly competitive among recent SOTA methods.
LUNA: Language Understanding with Number Augmentations on Transformers via Number Plugins and Pre-training
Dec 06, 2022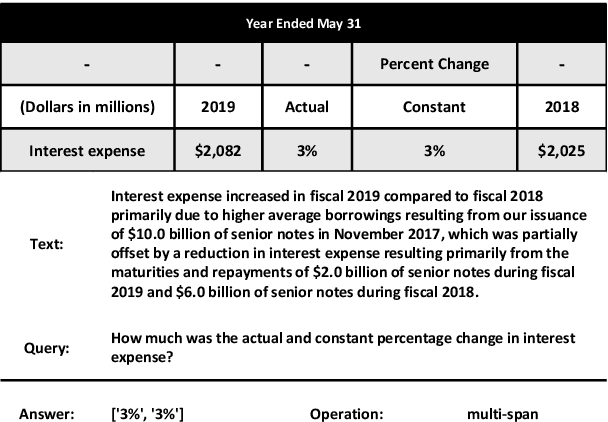
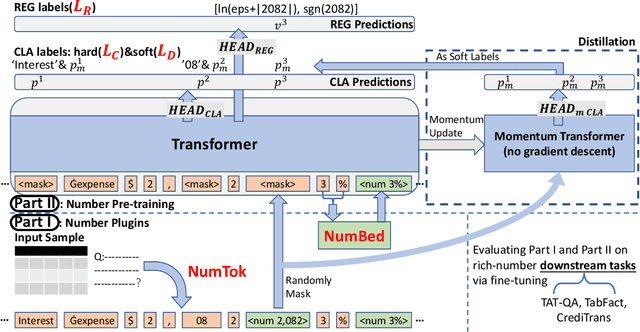

Transformers are widely used in NLP tasks. However, current approaches to leveraging transformers to understand language expose one weak spot: Number understanding. In some scenarios, numbers frequently occur, especially in semi-structured data like tables. But current approaches to rich-number tasks with transformer-based language models abandon or lose some of the numeracy information - e.g., breaking numbers into sub-word tokens - which leads to many number-related errors. In this paper, we propose the LUNA framework which improves the numerical reasoning and calculation capabilities of transformer-based language models. With the number plugin of NumTok and NumBed, LUNA represents each number as a whole to model input. With number pre-training, including regression loss and model distillation, LUNA bridges the gap between number and vocabulary embeddings. To the best of our knowledge, this is the first work that explicitly injects numeracy capability into language models using Number Plugins. Besides evaluating toy models on toy tasks, we evaluate LUNA on three large-scale transformer models (RoBERTa, BERT, TabBERT) over three different downstream tasks (TATQA, TabFact, CrediTrans), and observe the performances of language models are constantly improved by LUNA. The augmented models also improve the official baseline of TAT-QA (EM: 50.15 -> 59.58) and achieve SOTA performance on CrediTrans (F1 = 86.17).
Learning Cooperative Oversubscription for Cloud by Chance-Constrained Multi-Agent Reinforcement Learning
Nov 21, 2022
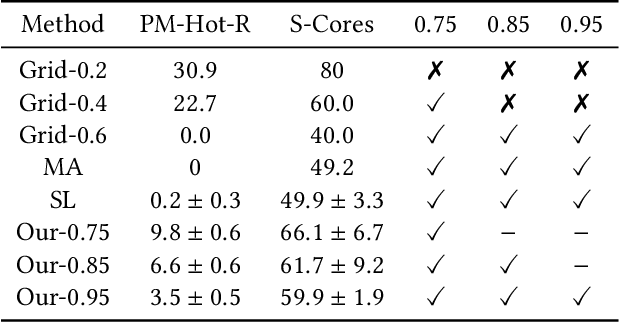
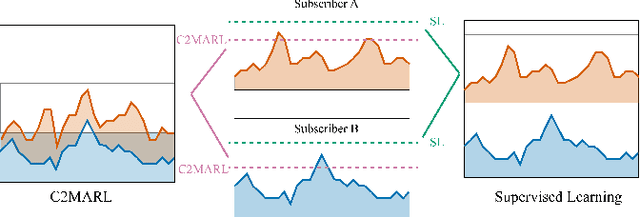
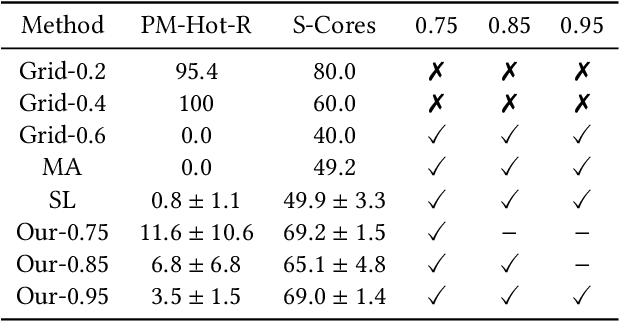
Oversubscription is a common practice for improving cloud resource utilization. It allows the cloud service provider to sell more resources than the physical limit, assuming not all users would fully utilize the resources simultaneously. However, how to design an oversubscription policy that improves utilization while satisfying the some safety constraints remains an open problem. Existing methods and industrial practices are over-conservative, ignoring the coordination of diverse resource usage patterns and probabilistic constraints. To address these two limitations, this paper formulates the oversubscription for cloud as a chance-constrained optimization problem and propose an effective Chance Constrained Multi-Agent Reinforcement Learning (C2MARL) method to solve this problem. Specifically, C2MARL reduces the number of constraints by considering their upper bounds and leverages a multi-agent reinforcement learning paradigm to learn a safe and optimal coordination policy. We evaluate our C2MARL on an internal cloud platform and public cloud datasets. Experiments show that our C2MARL outperforms existing methods in improving utilization ($20\%\sim 86\%$) under different levels of safety constraints.
Towards Robust Numerical Question Answering: Diagnosing Numerical Capabilities of NLP Systems
Nov 14, 2022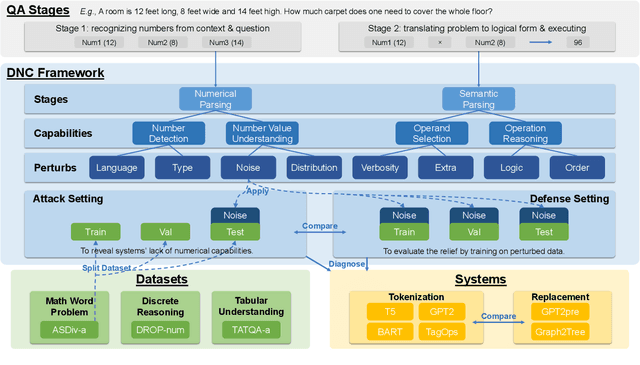
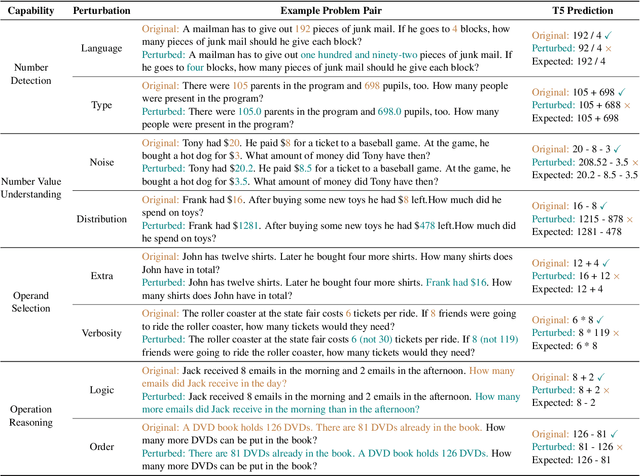
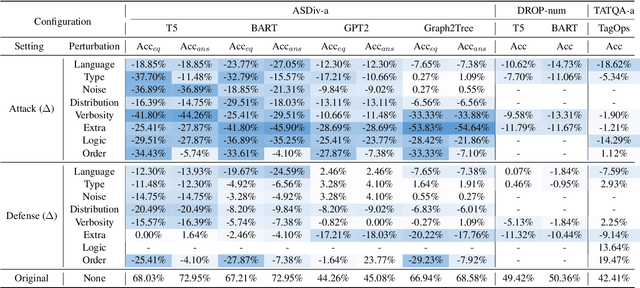
Numerical Question Answering is the task of answering questions that require numerical capabilities. Previous works introduce general adversarial attacks to Numerical Question Answering, while not systematically exploring numerical capabilities specific to the topic. In this paper, we propose to conduct numerical capability diagnosis on a series of Numerical Question Answering systems and datasets. A series of numerical capabilities are highlighted, and corresponding dataset perturbations are designed. Empirical results indicate that existing systems are severely challenged by these perturbations. E.g., Graph2Tree experienced a 53.83% absolute accuracy drop against the ``Extra'' perturbation on ASDiv-a, and BART experienced 13.80% accuracy drop against the ``Language'' perturbation on the numerical subset of DROP. As a counteracting approach, we also investigate the effectiveness of applying perturbations as data augmentation to relieve systems' lack of robust numerical capabilities. With experiment analysis and empirical studies, it is demonstrated that Numerical Question Answering with robust numerical capabilities is still to a large extent an open question. We discuss future directions of Numerical Question Answering and summarize guidelines on future dataset collection and system design.
FormLM: Recommending Creation Ideas for Online Forms by Modelling Semantic and Structural Information
Nov 10, 2022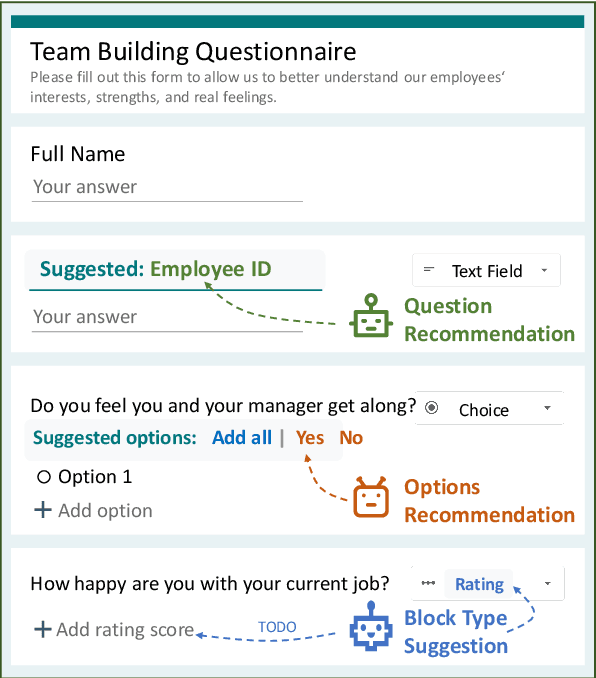
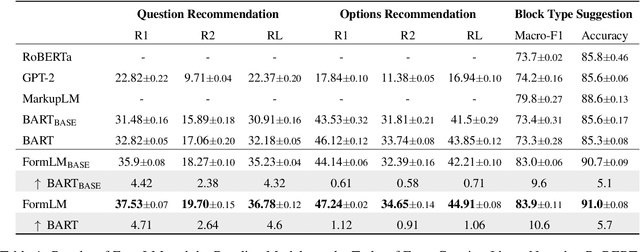
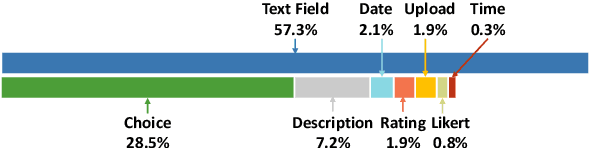
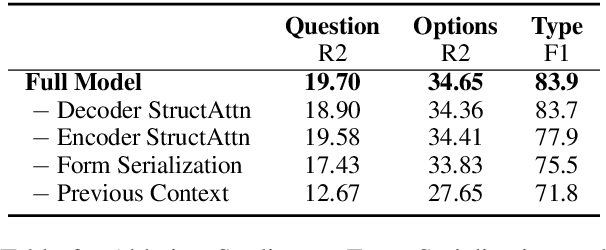
Online forms are widely used to collect data from human and have a multi-billion market. Many software products provide online services for creating semi-structured forms where questions and descriptions are organized by pre-defined structures. However, the design and creation process of forms is still tedious and requires expert knowledge. To assist form designers, in this work we present FormLM to model online forms (by enhancing pre-trained language model with form structural information) and recommend form creation ideas (including question / options recommendations and block type suggestion). For model training and evaluation, we collect the first public online form dataset with 62K online forms. Experiment results show that FormLM significantly outperforms general-purpose language models on all tasks, with an improvement by 4.71 on Question Recommendation and 10.6 on Block Type Suggestion in terms of ROUGE-1 and Macro-F1, respectively.
Reflection of Thought: Inversely Eliciting Numerical Reasoning in Language Models via Solving Linear Systems
Oct 11, 2022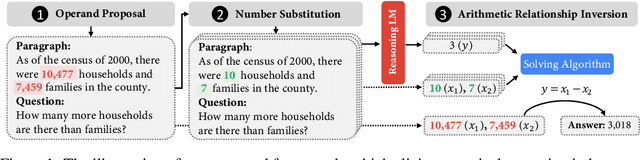

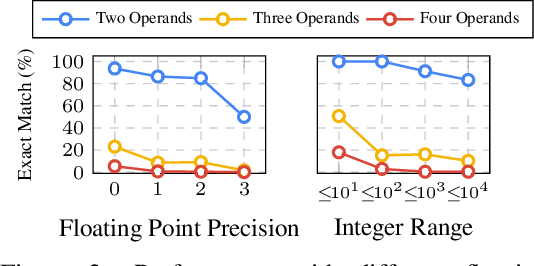

Numerical reasoning over natural language has been a long-standing goal for the research community. However, cutting-edge language models have proven difficult to reliably generalize to a broad range of numbers, although they have shown proficiency in reasoning over common and simple numbers. In this paper, we propose a novel method to elicit and exploit the numerical reasoning knowledge hidden in pre-trained language models using simple anchor numbers. Concretely, we first leverage simple numbers as anchors to probe the implicitly inferred arithmetic expressions from language models, and then explicitly apply the expressions on complex numbers to get corresponding answers. To inversely elicit arithmetic expressions, we transform and formulate the task as an analytically solvable linear system. Experimental results on several numerical reasoning benchmarks demonstrate that our approach significantly improves numerical reasoning capabilities of existing LMs. More importantly, our approach is training-free and simply works in the inference phase, making it highly portable and achieving consistent performance benefits across a variety of language models (GPT-3, T5, BART, etc) in all zero-shot, few-shot, and fine-tuning scenarios.
Guiding the PLMs with Semantic Anchors as Intermediate Supervision: Towards Interpretable Semantic Parsing
Oct 04, 2022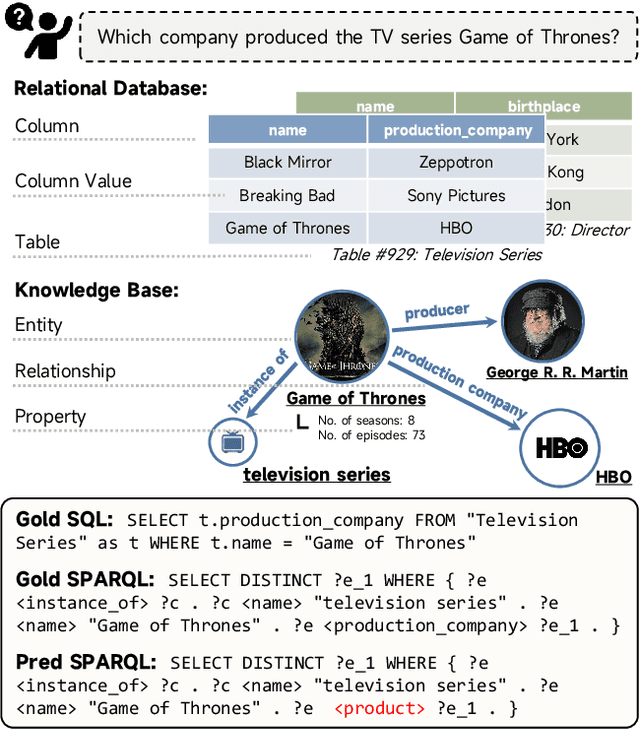
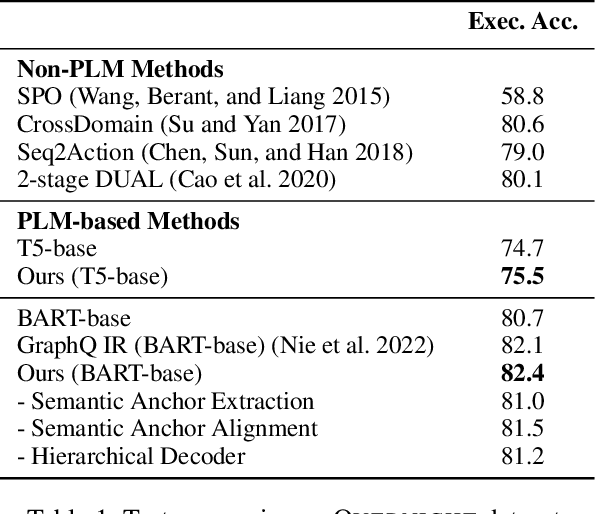
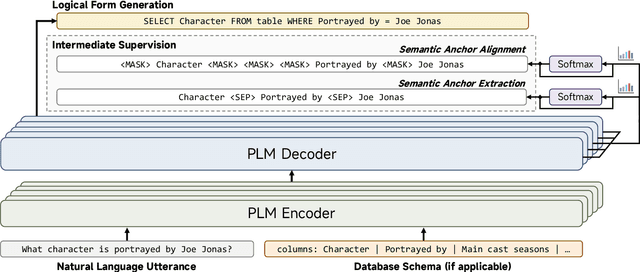
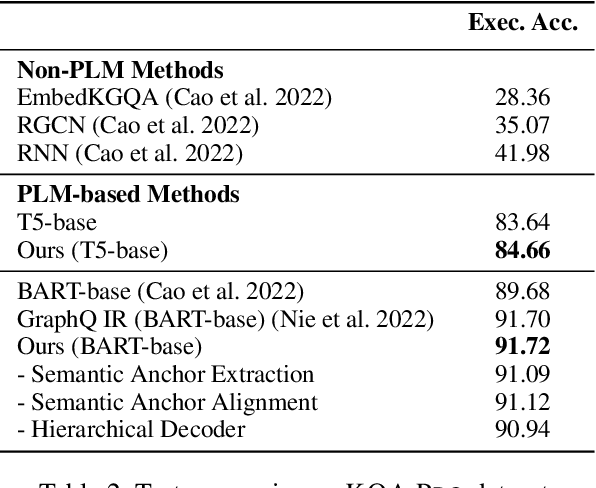
The recent prevalence of pretrained language models (PLMs) has dramatically shifted the paradigm of semantic parsing, where the mapping from natural language utterances to structured logical forms is now formulated as a Seq2Seq task. Despite the promising performance, previous PLM-based approaches often suffer from hallucination problems due to their negligence of the structural information contained in the sentence, which essentially constitutes the key semantics of the logical forms. Furthermore, most works treat PLM as a black box in which the generation process of the target logical form is hidden beneath the decoder modules, which greatly hinders the model's intrinsic interpretability. To address these two issues, we propose to incorporate the current PLMs with a hierarchical decoder network. By taking the first-principle structures as the semantic anchors, we propose two novel intermediate supervision tasks, namely Semantic Anchor Extraction and Semantic Anchor Alignment, for training the hierarchical decoders and probing the model intermediate representations in a self-adaptive manner alongside the fine-tuning process. We conduct intensive experiments on several semantic parsing benchmarks and demonstrate that our approach can consistently outperform the baselines. More importantly, by analyzing the intermediate representations of the hierarchical decoders, our approach also makes a huge step toward the intrinsic interpretability of PLMs in the domain of semantic parsing.