 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-Adaptive Meta-Learning for Cold-Start Medication Recommendation with Uncertainty Filtering
Jan 30, 2026Large-scale Electronic Health Record (EHR) databases have become indispensable in supporting clinical decision-making through data-driven treatment recommendations. However, existing medication recommender methods often struggle with a user (i.e., patient) cold-start problem, where recommendations for new patients are usually unreliable due to the lack of sufficient prescription history for patient profiling. While prior studies have utilized medical knowledge graphs to connect medication concepts through pharmacological or chemical relationships, these methods primarily focus on mitigating the item cold-start issue and fall short in providing personalized recommendations that adapt to individual patient characteristics. Meta-learning has shown promise in handling new users with sparse interactions in recommender systems. However, its application to EHRs remains underexplored due to the unique sequential structure of EHR data. To tackle these challenges, we propose MetaDrug, a multi-level, uncertainty-aware meta-learning framework designed to address the patient cold-start problem in medication recommendation. MetaDrug proposes a novel two-level meta-adaptation mechanism, including self-adaptation, which adapts the model to new patients using their own medical events as support sets to capture temporal dependencies; and peer-adaptation, which adapts the model using similar visits from peer patients to enrich new patient representations. Meanwhile, to further improve meta-adaptation outcomes, we introduce an uncertainty quantification module that ranks the support visits and filters out the unrelated information for adaptation consistency. We evaluate our approach on the MIMIC-III and Acute Kidney Injury (AKI) datasets. Experimental results on both datasets demonstrate that MetaDrug consistently outperforms state-of-the-art medication recommendation methods on cold-start patients.
Kernel Alignment-based Multi-view Unsupervised Feature Selection with Sample-level Adaptive Graph Learning
Jan 12, 2026Although multi-view unsupervised feature selection (MUFS) has demonstrated success in dimensionality reduction for unlabeled multi-view data, most existing methods reduce feature redundancy by focusing on linear correlations among features but often overlook complex nonlinear dependencies. This limits the effectiveness of feature selection. In addition, existing methods fuse similarity graphs from multiple views by employing sample-invariant weights to preserve local structure. However, this process fails to account for differences in local neighborhood clarity among samples within each view, thereby hindering accurate characterization of the intrinsic local structure of the data. In this paper, we propose a Kernel Alignment-based multi-view unsupervised FeatUre selection with Sample-level adaptive graph lEarning method (KAFUSE) to address these issues. Specifically, we first employ kernel alignment with an orthogonal constraint to reduce feature redundancy in both linear and nonlinear relationships. Then, a cross-view consistent similarity graph is learned by applying sample-level fusion to each slice of a tensor formed by stacking similarity graphs from different views, which automatically adjusts the view weights for each sample during fusion. These two steps are integrated into a unified model for feature selection, enabling mutual enhancement between them. Extensive experiments on real multi-view datasets demonstrate the superiority of KAFUSE over state-of-the-art methods.
Joint Learning of Unsupervised Multi-view Feature and Instance Co-selection with Cross-view Imputation
Dec 17, 2025



Feature and instance co-selection, which aims to reduce both feature dimensionality and sample size by identifying the most informative features and instances, has attracted considerable attention in recent years. However, when dealing with unlabeled incomplete multi-view data, where some samples are missing in certain views, existing methods typically first impute the missing data and then concatenate all views into a single dataset for subsequent co-selection. Such a strategy treats co-selection and missing data imputation as two independent processes, overlooking potential interactions between them. The inter-sample relationships gleaned from co-selection can aid imputation, which in turn enhances co-selection performance. Additionally, simply merging multi-view data fails to capture the complementary information among views, ultimately limiting co-selection effectiveness. To address these issues, we propose a novel co-selection method, termed Joint learning of Unsupervised multI-view feature and instance Co-selection with cross-viEw imputation (JUICE). JUICE first reconstructs incomplete multi-view data using available observations, bringing missing data recovery and feature and instance co-selection together in a unified framework. Then, JUICE leverages cross-view neighborhood information to learn inter-sample relationships and further refine the imputation of missing values during reconstruction. This enables the selection of more representative features and instances. Extensive experiments demonstrate that JUICE outperforms state-of-the-art methods.
Cross-view Joint Learning for Mixed-Missing Multi-view Unsupervised Feature Selection
Nov 15, 2025


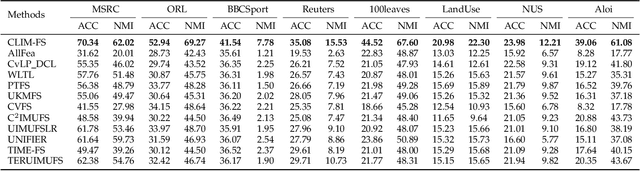
Incomplete multi-view unsupervised feature selection (IMUFS), which aims to identify representative features from unlabeled multi-view data containing missing values, has received growing attention in recent years. Despite their promising performance, existing methods face three key challenges: 1) by focusing solely on the view-missing problem, they are not well-suited to the more prevalent mixed-missing scenario in practice, where some samples lack entire views or only partial features within views; 2) insufficient utilization of consistency and diversity across views limits the effectiveness of feature selection; and 3) the lack of theoretical analysis makes it unclear how feature selection and data imputation interact during the joint learning process. Being aware of these, we propose CLIM-FS, a novel IMUFS method designed to address the mixed-missing problem. Specifically, we integrate the imputation of both missing views and variables into a feature selection model based on nonnegative orthogonal matrix factorization, enabling the joint learning of feature selection and adaptive data imputation. Furthermore, we fully leverage consensus cluster structure and cross-view local geometrical structure to enhance the synergistic learning process. We also provide a theoretical analysis to clarify the underlying collaborative mechanism of CLIM-FS. Experimental results on eight real-world multi-view datasets demonstrate that CLIM-FS outperforms state-of-the-art methods.
From Queries to Insights: Agentic LLM Pipelines for Spatio-Temporal Text-to-SQL
Oct 29, 2025Natural-language-to-SQL (NL-to-SQL) systems hold promise for democratizing access to structured data, allowing users to query databases without learning SQL. Yet existing systems struggle with realistic spatio-temporal queries, where success requires aligning vague user phrasing with schema-specific categories, handling temporal reasoning, and choosing appropriate outputs. We present an agentic pipeline that extends a naive text-to-SQL baseline (llama-3-sqlcoder-8b) with orchestration by a Mistral-based ReAct agent. The agent can plan, decompose, and adapt queries through schema inspection, SQL generation, execution, and visualization tools. We evaluate on 35 natural-language queries over the NYC and Tokyo check-in dataset, covering spatial, temporal, and multi-dataset reasoning. The agent achieves substantially higher accuracy than the naive baseline 91.4% vs. 28.6% and enhances usability through maps, plots, and structured natural-language summaries. Crucially, our design enables more natural human-database interaction, supporting users who lack SQL expertise, detailed schema knowledge, or prompting skill. We conclude that agentic orchestration, rather than stronger SQL generators alone, is a promising foundation for interactive geospatial assistants.
TRUST-FS: Tensorized Reliable Unsupervised Multi-View Feature Selection for Incomplete Data
Sep 16, 2025Multi-view unsupervised feature selection (MUFS), which selects informative features from multi-view unlabeled data, has attracted increasing research interest in recent years. Although great efforts have been devoted to MUFS, several challenges remain: 1) existing methods for incomplete multi-view data are limited to handling missing views and are unable to address the more general scenario of missing variables, where some features have missing values in certain views; 2) most methods address incomplete data by first imputing missing values and then performing feature selection, treating these two processes independently and overlooking their interactions; 3) missing data can result in an inaccurate similarity graph, which reduces the performance of feature selection. To solve this dilemma, we propose a novel MUFS method for incomplete multi-view data with missing variables, termed Tensorized Reliable UnSupervised mulTi-view Feature Selection (TRUST-FS). TRUST-FS introduces a new adaptive-weighted CP decomposition that simultaneously performs feature selection, missing-variable imputation, and view weight learning within a unified tensor factorization framework. By utilizing Subjective Logic to acquire trustworthy cross-view similarity information, TRUST-FS facilitates learning a reliable similarity graph, which subsequently guides feature selection and imputation. Comprehensive experimental results demonstrate the effectiveness and superiority of our method over state-of-the-art methods.
GPT-FT: An Efficient Automated Feature Transformation Using GPT for Sequence Reconstruction and Performance Enhancement
Aug 28, 2025



Feature transformation plays a critical role in enhancing machine learning model performance by optimizing data representations. Recent state-of-the-art approaches address this task as a continuous embedding optimization problem, converting discrete search into a learnable process. Although effective, these methods often rely on sequential encoder-decoder structures that cause high computational costs and parameter requirements, limiting scalability and efficiency. To address these limitations, we propose a novel framework that accomplishes automated feature transformation through four steps: transformation records collection, embedding space construction with a revised Generative Pre-trained Transformer (GPT) model, gradient-ascent search, and autoregressive reconstruction. In our approach, the revised GPT model serves two primary functions: (a) feature transformation sequence reconstruction and (b) model performance estimation and enhancement for downstream tasks by constructing the embedding space. Such a multi-objective optimization framework reduces parameter size and accelerates transformation processes. Experimental results on benchmark datasets show that the proposed framework matches or exceeds baseline performance, with significant gains in computational efficiency. This work highlights the potential of transformer-based architectures for scalable, high-performance automated feature transformation.
Distribution Shift Aware Neural Tabular Learning
Aug 27, 2025



Tabular learning transforms raw features into optimized spaces for downstream tasks, but its effectiveness deteriorates under distribution shifts between training and testing data. We formalize this challenge as the Distribution Shift Tabular Learning (DSTL) problem and propose a novel Shift-Aware Feature Transformation (SAFT) framework to address it. SAFT reframes tabular learning from a discrete search task into a continuous representation-generation paradigm, enabling differentiable optimization over transformed feature sets. SAFT integrates three mechanisms to ensure robustness: (i) shift-resistant representation via embedding decorrelation and sample reweighting, (ii) flatness-aware generation through suboptimal embedding averaging, and (iii) normalization-based alignment between training and test distributions. Extensive experiments show that SAFT consistently outperforms prior tabular learning methods in terms of robustness, effectiveness, and generalization ability under diverse real-world distribution shifts.
Efficient Post-Training Refinement of Latent Reasoning in Large Language Models
Jun 10, 2025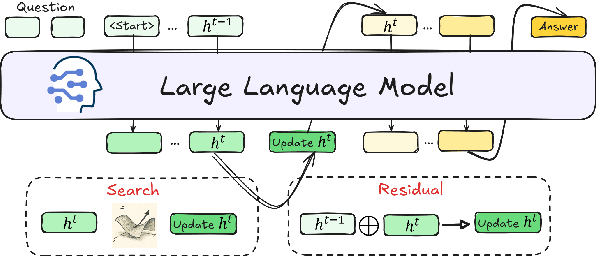
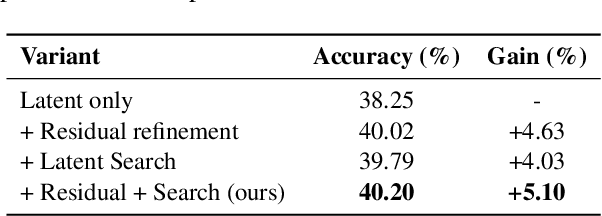
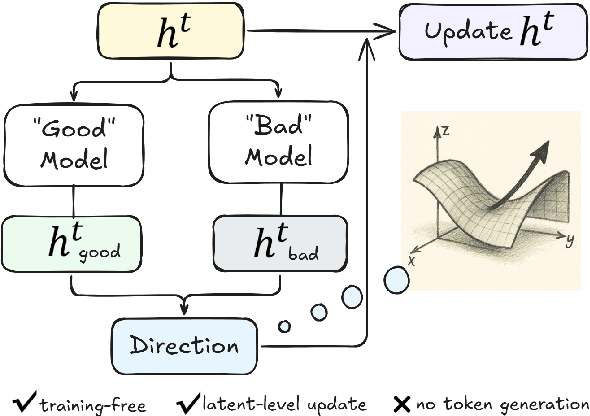
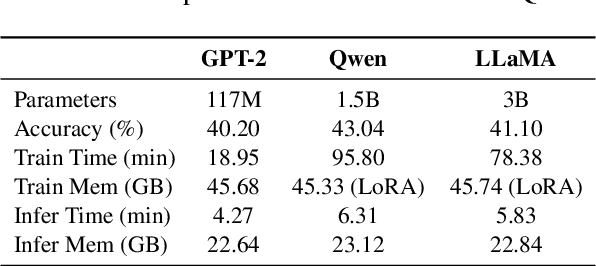
Reasoning is a key component of language understanding in Large Language Models. While Chain-of-Thought prompting enhances performance via explicit intermediate steps, it suffers from sufficient token overhead and a fixed reasoning trajectory, preventing step-wise refinement. Recent advances in latent reasoning address these limitations by refining internal reasoning processes directly in the model's latent space, without producing explicit outputs. However, a key challenge remains: how to effectively update reasoning embeddings during post-training to guide the model toward more accurate solutions. To overcome this challenge, we propose a lightweight post-training framework that refines latent reasoning trajectories using two novel strategies: 1) Contrastive reasoning feedback, which compares reasoning embeddings against strong and weak baselines to infer effective update directions via embedding enhancement; 2) Residual embedding refinement, which stabilizes updates by progressively integrating current and historical gradients, enabling fast yet controlled convergence. Extensive experiments and case studies are conducted on five reasoning benchmarks to demonstrate the effectiveness of the proposed framework. Notably, a 5\% accuracy gain on MathQA without additional training.
Biological Pathway Guided Gene Selection Through Collaborative Reinforcement Learning
May 30, 2025



Gene selection in high-dimensional genomic data is essential for understanding disease mechanisms and improving therapeutic outcomes. Traditional feature selection methods effectively identify predictive genes but often ignore complex biological pathways and regulatory networks, leading to unstable and biologically irrelevant signatures. Prior approaches, such as Lasso-based methods and statistical filtering, either focus solely on individual gene-outcome associations or fail to capture pathway-level interactions, presenting a key challenge: how to integrate biological pathway knowledge while maintaining statistical rigor in gene selection? To address this gap, we propose a novel two-stage framework that integrates statistical selection with biological pathway knowledge using multi-agent reinforcement learning (MARL). First, we introduce a pathway-guided pre-filtering strategy that leverages multiple statistical methods alongside KEGG pathway information for initial dimensionality reduction. Next, for refined selection, we model genes as collaborative agents in a MARL framework, where each agent optimizes both predictive power and biological relevance. Our framework incorporates pathway knowledge through Graph Neural Network-based state representations, a reward mechanism combining prediction performance with gene centrality and pathway coverage, and collaborative learning strategies using shared memory and a centralized critic component. Extensive experiments on multiple gene expression datasets demonstrate that our approach significantly improves both prediction accuracy and biological interpretability compared to traditional methods.