 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWST: Weakly Supervised Transducer for Automatic Speech Recognition
Nov 06, 2025The Recurrent Neural Network-Transducer (RNN-T) is widely adopted in end-to-end (E2E) automatic speech recognition (ASR) tasks but depends heavily on large-scale, high-quality annotated data, which are often costly and difficult to obtain. To mitigate this reliance, we propose a Weakly Supervised Transducer (WST), which integrates a flexible training graph designed to robustly handle errors in the transcripts without requiring additional confidence estimation or auxiliary pre-trained models. Empirical evaluations on synthetic and industrial datasets reveal that WST effectively maintains performance even with transcription error rates of up to 70%, consistently outperforming existing Connectionist Temporal Classification (CTC)-based weakly supervised approaches, such as Bypass Temporal Classification (BTC) and Omni-Temporal Classification (OTC). These results demonstrate the practical utility and robustness of WST in realistic ASR settings. The implementation will be publicly available.
Learning from Flawed Data: Weakly Supervised Automatic Speech Recognition
Sep 26, 2023



Training automatic speech recognition (ASR) systems requires large amounts of well-curated paired data. However, human annotators usually perform "non-verbatim" transcription, which can result in poorly trained models. In this paper, we propose Omni-temporal Classification (OTC), a novel training criterion that explicitly incorporates label uncertainties originating from such weak supervision. This allows the model to effectively learn speech-text alignments while accommodating errors present in the training transcripts. OTC extends the conventional CTC objective for imperfect transcripts by leveraging weighted finite state transducers. Through experiments conducted on the LibriSpeech and LibriVox datasets, we demonstrate that training ASR models with OTC avoids performance degradation even with transcripts containing up to 70% errors, a scenario where CTC models fail completely. Our implementation is available at https://github.com/k2-fsa/icefall.
Alternative Pseudo-Labeling for Semi-Supervised Automatic Speech Recognition
Aug 12, 2023



When labeled data is insufficient, semi-supervised learning with the pseudo-labeling technique can significantly improve the performance of automatic speech recognition. However, pseudo-labels are often noisy, containing numerous incorrect tokens. Taking noisy labels as ground-truth in the loss function results in suboptimal performance. Previous works attempted to mitigate this issue by either filtering out the nosiest pseudo-labels or improving the overall quality of pseudo-labels. While these methods are effective to some extent, it is unrealistic to entirely eliminate incorrect tokens in pseudo-labels. In this work, we propose a novel framework named alternative pseudo-labeling to tackle the issue of noisy pseudo-labels from the perspective of the training objective. The framework comprises several components. Firstly, a generalized CTC loss function is introduced to handle noisy pseudo-labels by accepting alternative tokens in the positions of incorrect tokens. Applying this loss function in pseudo-labeling requires detecting incorrect tokens in the predicted pseudo-labels. In this work, we adopt a confidence-based error detection method that identifies the incorrect tokens by comparing their confidence scores with a given threshold, thus necessitating the confidence score to be discriminative. Hence, the second proposed technique is the contrastive CTC loss function that widens the confidence gap between the correctly and incorrectly predicted tokens, thereby improving the error detection ability. Additionally, obtaining satisfactory performance with confidence-based error detection typically requires extensive threshold tuning. Instead, we propose an automatic thresholding method that uses labeled data as a proxy for determining the threshold, thus saving the pain of manual tuning.
HK-LegiCoST: Leveraging Non-Verbatim Transcripts for Speech Translation
Jun 20, 2023We introduce HK-LegiCoST, a new three-way parallel corpus of Cantonese-English translations, containing 600+ hours of Cantonese audio, its standard traditional Chinese transcript, and English translation, segmented and aligned at the sentence level. We describe the notable challenges in corpus preparation: segmentation, alignment of long audio recordings, and sentence-level alignment with non-verbatim transcripts. Such transcripts make the corpus suitable for speech translation research when there are significant differences between the spoken and written forms of the source language. Due to its large size, we are able to demonstrate competitive speech translation baselines on HK-LegiCoST and extend them to promising cross-corpus results on the FLEURS Cantonese subset. These results deliver insights into speech recognition and translation research in languages for which non-verbatim or ``noisy'' transcription is common due to various factors, including vernacular and dialectal speech.
Bypass Temporal Classification: Weakly Supervised Automatic Speech Recognition with Imperfect Transcripts
Jun 01, 2023



This paper presents a novel algorithm for building an automatic speech recognition (ASR) model with imperfect training data. Imperfectly transcribed speech is a prevalent issue in human-annotated speech corpora, which degrades the performance of ASR models. To address this problem, we propose Bypass Temporal Classification (BTC) as an expansion of the Connectionist Temporal Classification (CTC) criterion. BTC explicitly encodes the uncertainties associated with transcripts during training. This is accomplished by enhancing the flexibility of the training graph, which is implemented as a weighted finite-state transducer (WFST) composition. The proposed algorithm improves the robustness and accuracy of ASR systems, particularly when working with imprecisely transcribed speech corpora. Our implementation will be open-sourced.
PHONEix: Acoustic Feature Processing Strategy for Enhanced Singing Pronunciation with Phoneme Distribution Predictor
Mar 15, 2023



Singing voice synthesis (SVS), as a specific task for generating the vocal singing voice from a music score, has drawn much attention in recent years. SVS faces the challenge that the singing has various pronunciation flexibility conditioned on the same music score. Most of the previous works of SVS can not well handle the misalignment between the music score and actual singing. In this paper, we propose an acoustic feature processing strategy, named PHONEix, with a phoneme distribution predictor, to alleviate the gap between the music score and the singing voice, which can be easily adopted in different SVS systems. Extensive experiments in various settings demonstrate the effectiveness of our PHONEix in both objective and subjective evaluations.
EURO: ESPnet Unsupervised ASR Open-source Toolkit
Dec 01, 2022



This paper describes the ESPnet Unsupervised ASR Open-source Toolkit (EURO), an end-to-end open-source toolkit for unsupervised automatic speech recognition (UASR). EURO adopts the state-of-the-art UASR learning method introduced by the Wav2vec-U, originally implemented at FAIRSEQ, which leverages self-supervised speech representations and adversarial training. In addition to wav2vec2, EURO extends the functionality and promotes reproducibility for UASR tasks by integrating S3PRL and k2, resulting in flexible frontends from 27 self-supervised models and various graph-based decoding strategies. EURO is implemented in ESPnet and follows its unified pipeline to provide UASR recipes with a complete setup. This improves the pipeline's efficiency and allows EURO to be easily applied to existing datasets in ESPnet. Extensive experiments on three mainstream self-supervised models demonstrate the toolkit's effectiveness and achieve state-of-the-art UASR performance on TIMIT and LibriSpeech datasets. EURO will be publicly available at https://github.com/espnet/espnet, aiming to promote this exciting and emerging research area based on UASR through open-source activity.
Bridging Speech and Textual Pre-trained Models with Unsupervised ASR
Nov 06, 2022Spoken language understanding (SLU) is a task aiming to extract high-level semantics from spoken utterances. Previous works have investigated the use of speech self-supervised models and textual pre-trained models, which have shown reasonable improvements to various SLU tasks. However, because of the mismatched modalities between speech signals and text tokens, previous methods usually need complex designs of the frameworks. This work proposes a simple yet efficient unsupervised paradigm that connects speech and textual pre-trained models, resulting in an unsupervised speech-to-semantic pre-trained model for various tasks in SLU. To be specific, we propose to use unsupervised automatic speech recognition (ASR) as a connector that bridges different modalities used in speech and textual pre-trained models. Our experiments show that unsupervised ASR itself can improve the representations from speech self-supervised models. More importantly, it is shown as an efficient connector between speech and textual pre-trained models, improving the performances of five different SLU tasks. Notably, on spoken question answering, we reach the state-of-the-art result over the challenging NMSQA benchmark.
Decoupling recognition and transcription in Mandarin ASR
Aug 02, 2021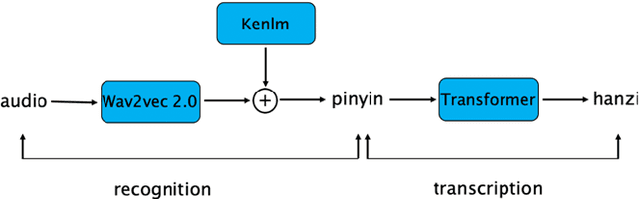
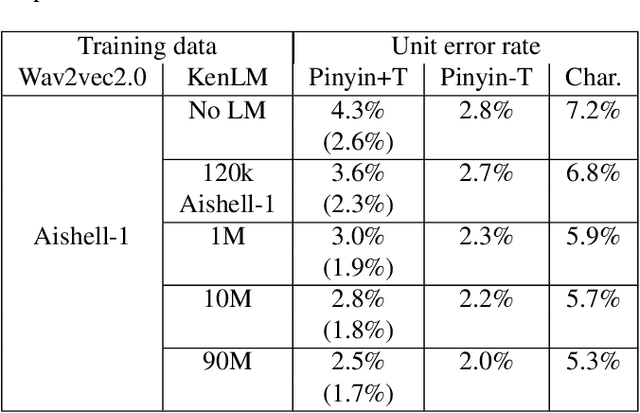
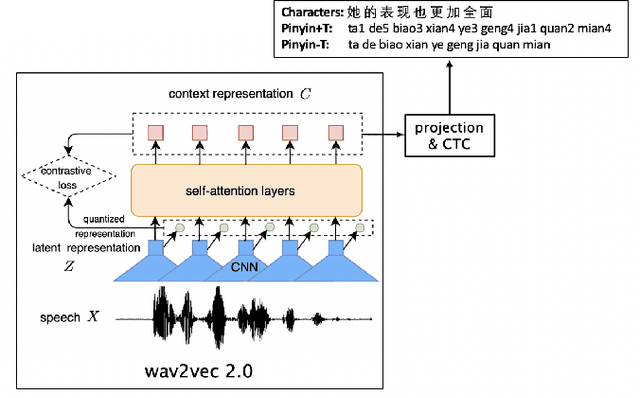
Much of the recent literature on automatic speech recognition (ASR) is taking an end-to-end approach. Unlike English where the writing system is closely related to sound, Chinese characters (Hanzi) represent meaning, not sound. We propose factoring audio -> Hanzi into two sub-tasks: (1) audio -> Pinyin and (2) Pinyin -> Hanzi, where Pinyin is a system of phonetic transcription of standard Chinese. Factoring the audio -> Hanzi task in this way achieves 3.9% CER (character error rate) on the Aishell-1 corpus, the best result reported on this dataset so far.