 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Behavior evolution-inspired approach to walking gait reinforcement training for quadruped robots
Sep 25, 2024



Reinforcement learning method is extremely competitive in gait generation techniques for quadrupedal robot, which is mainly due to the fact that stochastic exploration in reinforcement training is beneficial to achieve an autonomous gait. Nevertheless, although incremental reinforcement learning is employed to improve training success and movement smoothness by relying on the continuity inherent during limb movements, challenges remain in adapting gait policy to diverse terrain and external disturbance. Inspired by the association between reinforcement learning and the evolution of animal motion behavior, a self-improvement mechanism for reference gait is introduced in this paper to enable incremental learning of action and self-improvement of reference action together to imitate the evolution of animal motion behavior. Further, a new framework for reinforcement training of quadruped gait is proposed. In this framework, genetic algorithm is specifically adopted to perform global probabilistic search for the initial value of the arbitrary foot trajectory to update the reference trajectory with better fitness. Subsequently, the improved reference gait is used for incremental reinforcement learning of gait. The above process is repeatedly and alternatively executed to finally train the gait policy. The analysis considering terrain, model dimensions, and locomotion condition is presented in detail based on simulation, and the results show that the framework is significantly more adaptive to terrain compared to regular incremental reinforcement learning.
Task Me Anything
Jun 17, 2024



Benchmarks for large multimodal language models (MLMs) now serve to simultaneously assess the general capabilities of models instead of evaluating for a specific capability. As a result, when a developer wants to identify which models to use for their application, they are overwhelmed by the number of benchmarks and remain uncertain about which benchmark's results are most reflective of their specific use case. This paper introduces Task-Me-Anything, a benchmark generation engine which produces a benchmark tailored to a user's needs. Task-Me-Anything maintains an extendable taxonomy of visual assets and can programmatically generate a vast number of task instances. Additionally, it algorithmically addresses user queries regarding MLM performance efficiently within a computational budget. It contains 113K images, 10K videos, 2K 3D object assets, over 365 object categories, 655 attributes, and 335 relationships. It can generate 750M image/video question-answering pairs, which focus on evaluating MLM perceptual capabilities. Task-Me-Anything reveals critical insights: open-source MLMs excel in object and attribute recognition but lack spatial and temporal understanding; each model exhibits unique strengths and weaknesses; larger models generally perform better, though exceptions exist; and GPT4o demonstrates challenges in recognizing rotating/moving objects and distinguishing colors.
Demonstration of MaskSearch: Efficiently Querying Image Masks for Machine Learning Workflows
Apr 09, 2024



We demonstrate MaskSearch, a system designed to accelerate queries over databases of image masks generated by machine learning models. MaskSearch formalizes and accelerates a new category of queries for retrieving images and their corresponding masks based on mask properties, which support various applications, from identifying spurious correlations learned by models to exploring discrepancies between model saliency and human attention. This demonstration makes the following contributions:(1) the introduction of MaskSearch's graphical user interface (GUI), which enables interactive exploration of image databases through mask properties, (2) hands-on opportunities for users to explore MaskSearch's capabilities and constraints within machine learning workflows, and (3) an opportunity for conference attendees to understand how MaskSearch accelerates queries over image masks.
MaskSearch: Querying Image Masks at Scale
May 03, 2023



Machine learning tasks over image databases often generate masks that annotate image content (e.g., saliency maps, segmentation maps) and enable a variety of applications (e.g., determine if a model is learning spurious correlations or if an image was maliciously modified to mislead a model). While queries that retrieve examples based on mask properties are valuable to practitioners, existing systems do not support such queries efficiently. In this paper, we formalize the problem and propose a system, MaskSearch, that focuses on accelerating queries over databases of image masks. MaskSearch leverages a novel indexing technique and an efficient filter-verification query execution framework. Experiments on real-world datasets with our prototype show that MaskSearch, using indexes approximately 5% the size of the data, accelerates individual queries by up to two orders of magnitude and consistently outperforms existing methods on various multi-query workloads that simulate dataset exploration and analysis processes.
VOCALExplore: Pay-as-You-Go Video Data Exploration and Model Building
Mar 07, 2023



We introduce VOCALExplore, a system designed to support users in building domain-specific models over video datasets. VOCALExplore supports interactive labeling sessions and trains models using user-supplied labels. VOCALExplore maximizes model quality by automatically deciding how to select samples based on observed skew in the collected labels. It also selects the optimal video representations to use when training models by casting feature selection as a rising bandit problem. Finally, VOCALExplore implements optimizations to achieve low latency without sacrificing model performance. We demonstrate that VOCALExplore achieves close to the best possible model quality given candidate acquisition functions and feature extractors, and it does so with low visible latency (~1 second per iteration) and no expensive preprocessing.
Query Processing on Tensor Computation Runtimes
Mar 03, 2022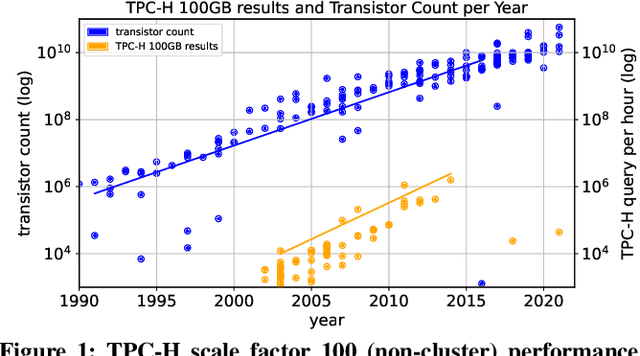

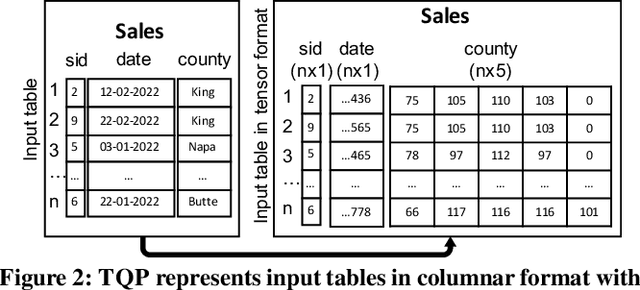
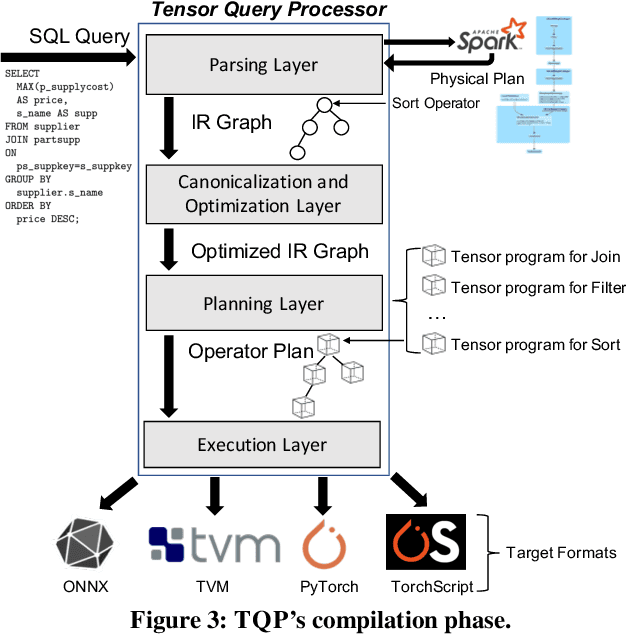
The huge demand for computation in artificial intelligence (AI) is driving unparalleled investments in new hardware and software systems for AI. This leads to an explosion in the number of specialized hardware devices, which are now part of the offerings of major cloud providers. Meanwhile, by hiding the low-level complexity through a tensor-based interface, tensor computation runtimes (TCRs) such as PyTorch allow data scientists to efficiently exploit the exciting capabilities offered by the new hardware. In this paper, we explore how databases can ride the wave of innovation happening in the AI space. Specifically, we present Tensor Query Processor (TQP): a SQL query processor leveraging the tensor interface of TCRs. TQP is able to efficiently run the full TPC-H benchmark by implementing novel algorithms for executing relational operators on the specialized tensor routines provided by TCRs. Meanwhile, TQP can target various hardware while only requiring a fraction of the usual development effort. Experiments show that TQP can improve query execution time by up to 20x over CPU-only systems, and up to 5x over specialized GPU solutions. Finally, TQP can accelerate queries mixing ML predictions and SQL end-to-end, and deliver up to 5x speedup over CPU baselines.
GSECnet: Ground Segmentation of Point Clouds for Edge Computing
Apr 05, 2021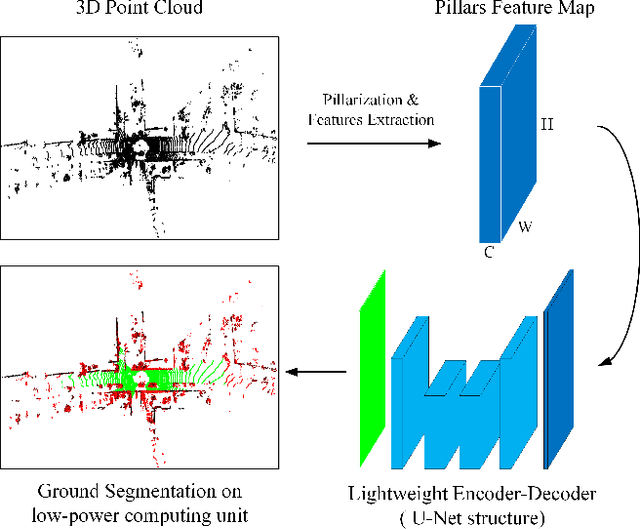
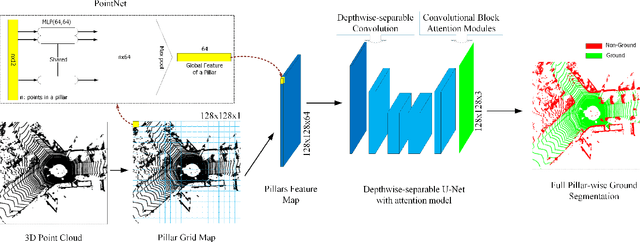

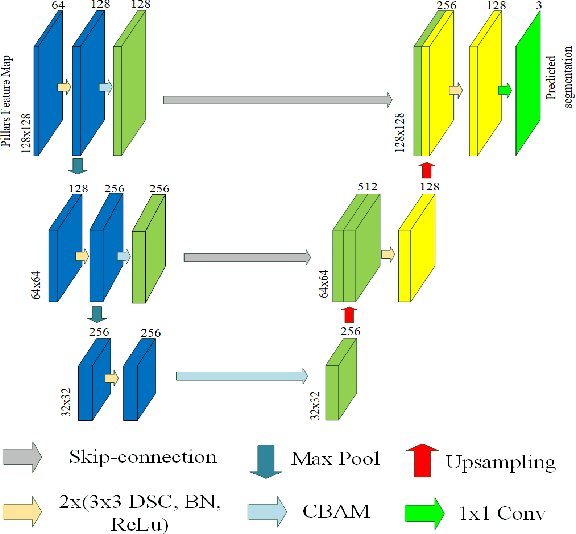
Ground segmentation of point clouds remains challenging because of the sparse and unordered data structure. This paper proposes the GSECnet - Ground Segmentation network for Edge Computing, an efficient ground segmentation framework of point clouds specifically designed to be deployable on a low-power edge computing unit. First, raw point clouds are converted into a discretization representation by pillarization. Afterward, features of points within pillars are fed into PointNet to get the corresponding pillars feature map. Then, a depthwise-separable U-Net with the attention module learns the classification from the pillars feature map with an enormously diminished model parameter size. Our proposed framework is evaluated on SemanticKITTI against both point-based and discretization-based state-of-the-art learning approaches, and achieves an excellent balance between high accuracy and low computing complexity. Remarkably, our framework achieves the inference runtime of 135.2 Hz on a desktop platform. Moreover, experiments verify that it is deployable on a low-power edge computing unit powered 10 watts only.
Measuring Mother-Infant Emotions By Audio Sensing
Dec 10, 2019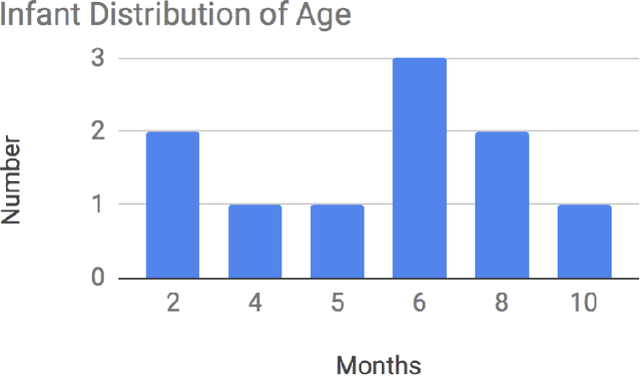
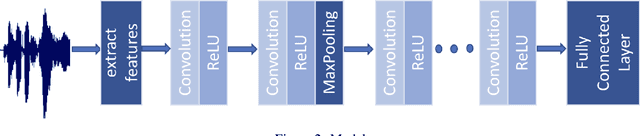
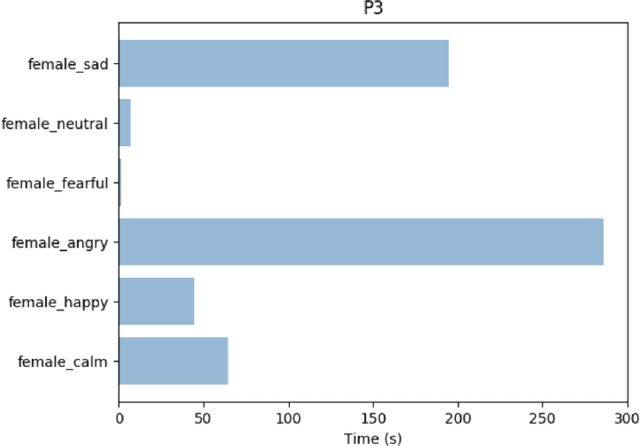
It has been suggested in developmental psychology literature that the communication of affect between mothers and their infants correlates with the socioemotional and cognitive development of infants. In this study, we obtained day-long audio recordings of 10 mother-infant pairs in order to study their affect communication in speech with a focus on mother's speech. In order to build a model for speech emotion detection, we used the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) and trained a Convolutional Neural Nets model which is able to classify 6 different emotions at 70% accuracy. We applied our model to mother's speech and found the dominant emotions were angry and sad, which were not true. Based on our own observations, we concluded that emotional speech databases made with the help of actors cannot generalize well to real-life settings, suggesting an active learning or unsupervised approach in the future.