 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRELOAD: A Robust and Efficient Learned Query Optimizer for Database Systems
Apr 16, 2026Recent advances in query optimization have shifted from traditional rule-based and cost-based techniques towards machine learning-driven approaches. Among these, reinforcement learning (RL) has attracted significant attention due to its ability to optimize long-term performance by learning policies over query planning. However, existing RL-based query optimizers often exhibit unstable performance at the level of individual queries, including severe performance regressions, and require prolonged training to reach the plan quality of expert, cost-based optimizers. These shortcomings make learned query optimizers difficult to deploy in practice and remain a major barrier to their adoption in production database systems. To address these challenges, we present RELOAD, a robust and efficient learned query optimizer for database systems. RELOAD focuses on (i) robustness, by minimizing query-level performance regressions and ensuring consistent optimization behavior across executions, and (ii) efficiency, by accelerating convergence to expert-level plan quality. Through extensive experiments on standard benchmarks, including Join Order Benchmark, TPC-DS, and Star Schema Benchmark, RELOAD demonstrates up to 2.4x higher robustness and 3.1x greater efficiency compared to state-of-the-art RL-based query optimization techniques.
The Robot's Inner Critic: Self-Refinement of Social Behaviors through VLM-based Replanning
Mar 20, 2026Conventional robot social behavior generation has been limited in flexibility and autonomy, relying on predefined motions or human feedback. This study proposes CRISP (Critique-and-Replan for Interactive Social Presence), an autonomous framework where a robot critiques and replans its own actions by leveraging a Vision-Language Model (VLM) as a `human-like social critic.' CRISP integrates (1) extraction of movable joints and constraints by analyzing the robot's description file (e.g., MJCF), (2) generation of step-by-step behavior plans based on situational context, (3) generation of low-level joint control code by referencing visual information (joint range-of-motion visualizations), (4) VLM-based evaluation of social appropriateness and naturalness, including pinpointing erroneous steps, and (5) iterative refinement of behaviors through reward-based search. This approach is not tied to a specific robot API; it can generate subtly different, human-like motions on various platforms using only the robot's structure file. In a user study involving five different robot types and 20 scenarios, including mobile manipulators and humanoids, our proposed method achieved significantly higher preference and situational appropriateness ratings compared to previous methods. This research presents a general framework that minimizes human intervention while expanding the robot's autonomous interaction capabilities and cross-platform applicability. Detailed result videos and supplementary information regarding this work are available at: https://limjiyu99.github.io/inner-critic/
Spatial Transport Optimization by Repositioning Attention Map for Training-Free Text-to-Image Synthesis
Mar 28, 2025



Diffusion-based text-to-image (T2I) models have recently excelled in high-quality image generation, particularly in a training-free manner, enabling cost-effective adaptability and generalization across diverse tasks. However, while the existing methods have been continuously focusing on several challenges, such as "missing objects" and "mismatched attributes," another critical issue of "mislocated objects" remains where generated spatial positions fail to align with text prompts. Surprisingly, ensuring such seemingly basic functionality remains challenging in popular T2I models due to the inherent difficulty of imposing explicit spatial guidance via text forms. To address this, we propose STORM (Spatial Transport Optimization by Repositioning Attention Map), a novel training-free approach for spatially coherent T2I synthesis. STORM employs Spatial Transport Optimization (STO), rooted in optimal transport theory, to dynamically adjust object attention maps for precise spatial adherence, supported by a Spatial Transport (ST) Cost function that enhances spatial understanding. Our analysis shows that integrating spatial awareness is most effective in the early denoising stages, while later phases refine details. Extensive experiments demonstrate that STORM surpasses existing methods, effectively mitigating mislocated objects while improving missing and mismatched attributes, setting a new benchmark for spatial alignment in T2I synthesis.
End-to-end Optimization of Machine Learning Prediction Queries
May 31, 2022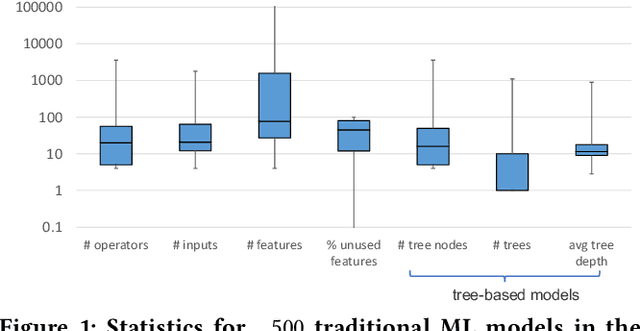
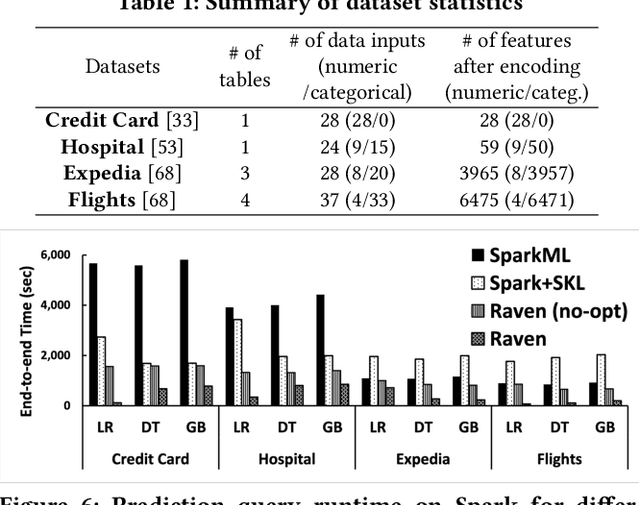
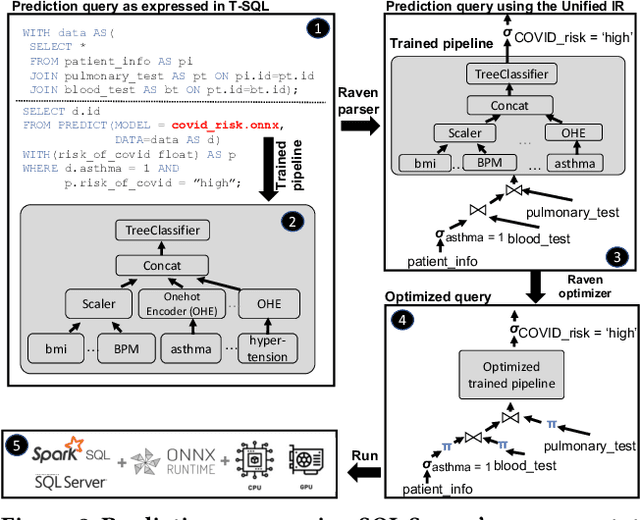
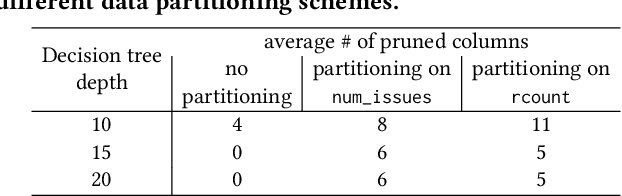
Prediction queries are widely used across industries to perform advanced analytics and draw insights from data. They include a data processing part (e.g., for joining, filtering, cleaning, featurizing the datasets) and a machine learning (ML) part invoking one or more trained models to perform predictions. These parts have so far been optimized in isolation, leaving significant opportunities for optimization unexplored. We present Raven, a production-ready system for optimizing prediction queries. Raven follows the enterprise architectural trend of collocating data and ML runtimes. It relies on a unified intermediate representation that captures both data and ML operators in a single graph structure to unlock two families of optimizations. First, it employs logical optimizations that pass information between the data part (and the properties of the underlying data) and the ML part to optimize each other. Second, it introduces logical-to-physical transformations that allow operators to be executed on different runtimes (relational, ML, and DNN) and hardware (CPU, GPU). Novel data-driven optimizations determine the runtime to be used for each part of the query to achieve optimal performance. Our evaluation shows that Raven improves performance of prediction queries on Apache Spark and SQL Server by up to 13.1x and 330x, respectively. For complex models where GPU acceleration is beneficial, Raven provides up to 8x speedup compared to state-of-the-art systems.
Query Processing on Tensor Computation Runtimes
Mar 03, 2022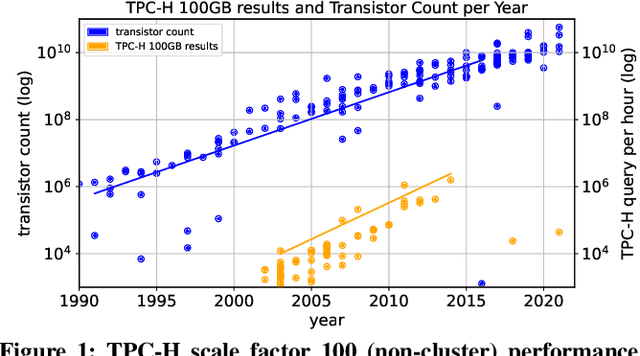

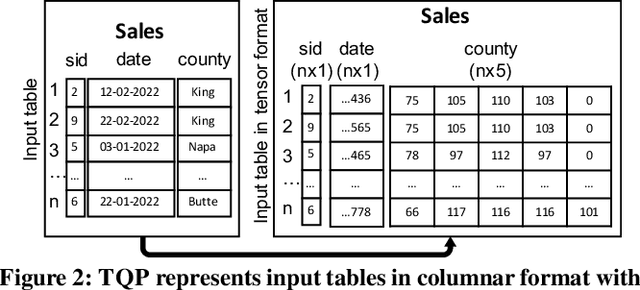
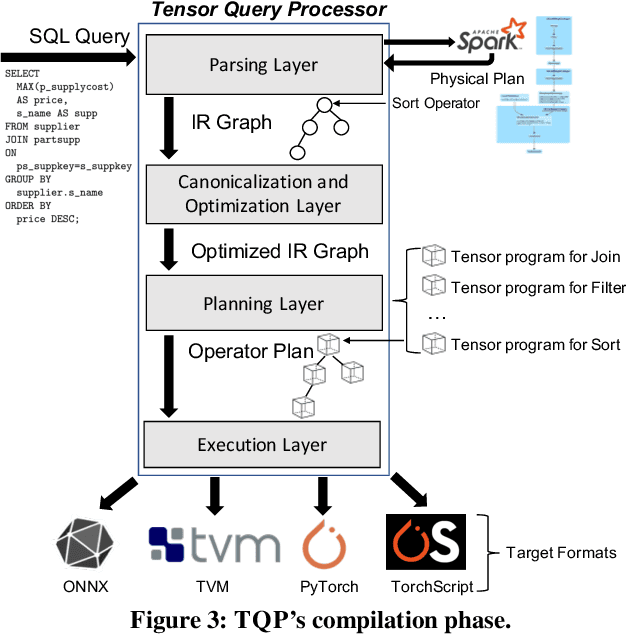
The huge demand for computation in artificial intelligence (AI) is driving unparalleled investments in new hardware and software systems for AI. This leads to an explosion in the number of specialized hardware devices, which are now part of the offerings of major cloud providers. Meanwhile, by hiding the low-level complexity through a tensor-based interface, tensor computation runtimes (TCRs) such as PyTorch allow data scientists to efficiently exploit the exciting capabilities offered by the new hardware. In this paper, we explore how databases can ride the wave of innovation happening in the AI space. Specifically, we present Tensor Query Processor (TQP): a SQL query processor leveraging the tensor interface of TCRs. TQP is able to efficiently run the full TPC-H benchmark by implementing novel algorithms for executing relational operators on the specialized tensor routines provided by TCRs. Meanwhile, TQP can target various hardware while only requiring a fraction of the usual development effort. Experiments show that TQP can improve query execution time by up to 20x over CPU-only systems, and up to 5x over specialized GPU solutions. Finally, TQP can accelerate queries mixing ML predictions and SQL end-to-end, and deliver up to 5x speedup over CPU baselines.
Extending Relational Query Processing with ML Inference
Nov 01, 2019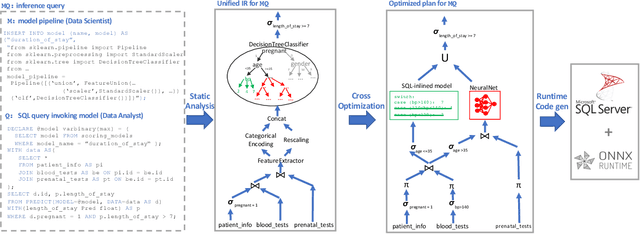

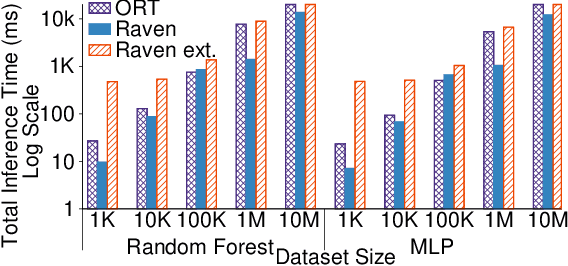
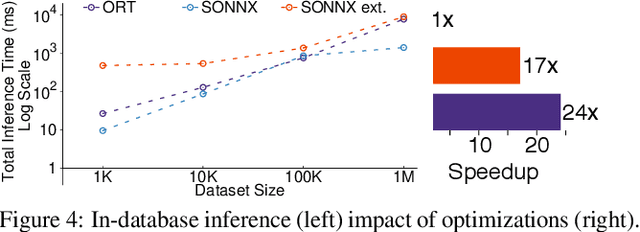
The broadening adoption of machine learning in the enterprise is increasing the pressure for strict governance and cost-effective performance, in particular for the common and consequential steps of model storage and inference. The RDBMS provides a natural starting point, given its mature infrastructure for fast data access and processing, along with support for enterprise features (e.g., encryption, auditing, high-availability). To take advantage of all of the above, we need to address a key concern: Can in-RDBMS scoring of ML models match (outperform?) the performance of dedicated frameworks? We answer the above positively by building Raven, a system that leverages native integration of ML runtimes (i.e., ONNX Runtime) deep within SQL Server, and a unified intermediate representation (IR) to enable advanced cross-optimizations between ML and DB operators. In this optimization space, we discover the most exciting research opportunities that combine DB/Compiler/ML thinking. Our initial evaluation on real data demonstrates performance gains of up to 5.5x from the native integration of ML in SQL Server, and up to 24x from cross-optimizations--we will demonstrate Raven live during the conference talk.
Cloudy with high chance of DBMS: A 10-year prediction for Enterprise-Grade ML
Aug 30, 2019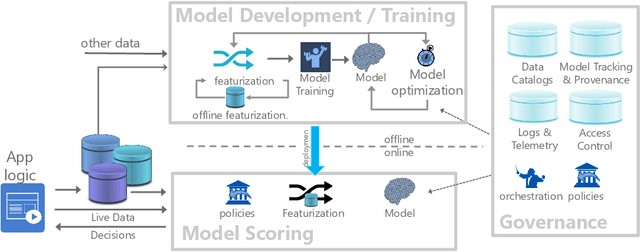
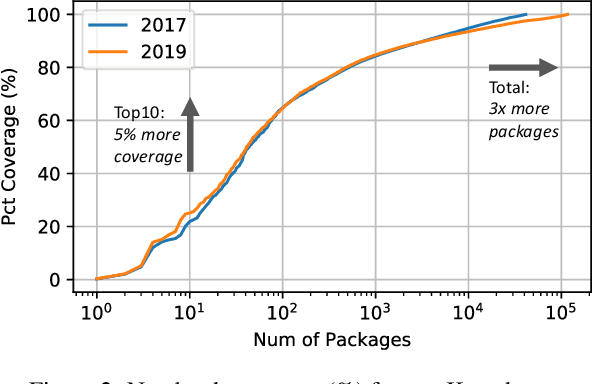
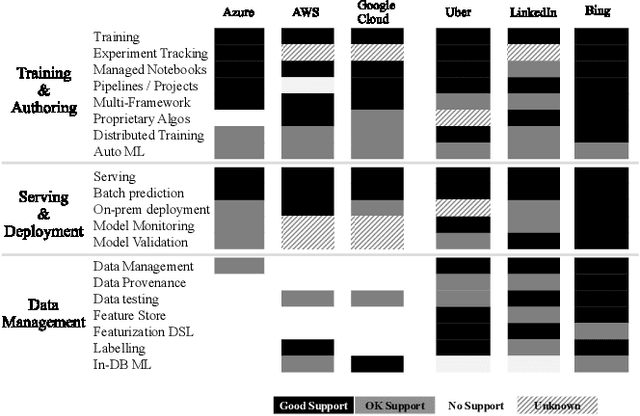
Machine learning (ML) has proven itself in high-value web applications such as search ranking and is emerging as a powerful tool in a much broader range of enterprise scenarios including voice recognition and conversational understanding for customer support, autotuning for videoconferencing, inteligent feedback loops in largescale sysops, manufacturing and autonomous vehicle management, complex financial predictions, just to name a few. Meanwhile, as the value of data is increasingly recognized and monetized, concerns about securing valuable data and risks to individual privacy have been growing. Consequently, rigorous data management has emerged as a key requirement in enterprise settings. How will these trends (ML growing popularity, and stricter data governance) intersect? What are the unmet requirements for applying ML in enterprise settings? What are the technical challenges for the DB community to solve? In this paper, we present our vision of how ML and database systems are likely to come together, and early steps we take towards making this vision a reality.