 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Agnostic Low-Rank Adapters for Unseen English Dialects
Nov 02, 2023



Large Language Models (LLMs) are trained on corpora disproportionally weighted in favor of Standard American English. As a result, speakers of other dialects experience significantly more failures when interacting with these technologies. In practice, these speakers often accommodate their speech to be better understood. Our work shares the belief that language technologies should be designed to accommodate the diversity in English dialects and not the other way around. However, prior works on dialect struggle with generalizing to evolving and emerging dialects in a scalable manner. To fill this gap, our method, HyperLoRA, leverages expert linguistic knowledge to enable resource-efficient adaptation via hypernetworks. By disentangling dialect-specific and cross-dialectal information, HyperLoRA improves generalization to unseen dialects in a task-agnostic fashion. Not only is HyperLoRA more scalable in the number of parameters, but it also achieves the best or most competitive performance across 5 dialects in a zero-shot setting. In this way, our approach facilitates access to language technology for billions of English dialect speakers who are traditionally underrepresented.
Unlearn What You Want to Forget: Efficient Unlearning for LLMs
Oct 31, 2023Large language models (LLMs) have achieved significant progress from pre-training on and memorizing a wide range of textual data, however, this process might suffer from privacy issues and violations of data protection regulations. As a result, the ability to easily remove data related to individual users from such models while not deteriorating their predictive quality after the removal becomes increasingly important. To address these issues, in this work, we propose an efficient unlearning framework that could efficiently update LLMs without having to retrain the whole model after data removals, by introducing lightweight unlearning layers learned with a selective teacher-student objective into the transformers. In addition, we introduce a fusion mechanism to effectively combine different unlearning layers that learns to forget different sets of data to handle a sequence of forgetting operations. Experiments on classification and generation tasks demonstrate the effectiveness of our proposed methods compared to the state-of-the-art baselines.
Impressions: Understanding Visual Semiotics and Aesthetic Impact
Oct 27, 2023



Is aesthetic impact different from beauty? Is visual salience a reflection of its capacity for effective communication? We present Impressions, a novel dataset through which to investigate the semiotics of images, and how specific visual features and design choices can elicit specific emotions, thoughts and beliefs. We posit that the impactfulness of an image extends beyond formal definitions of aesthetics, to its success as a communicative act, where style contributes as much to meaning formation as the subject matter. However, prior image captioning datasets are not designed to empower state-of-the-art architectures to model potential human impressions or interpretations of images. To fill this gap, we design an annotation task heavily inspired by image analysis techniques in the Visual Arts to collect 1,440 image-caption pairs and 4,320 unique annotations exploring impact, pragmatic image description, impressions, and aesthetic design choices. We show that existing multimodal image captioning and conditional generation models struggle to simulate plausible human responses to images. However, this dataset significantly improves their ability to model impressions and aesthetic evaluations of images through fine-tuning and few-shot adaptation.
CoAnnotating: Uncertainty-Guided Work Allocation between Human and Large Language Models for Data Annotation
Oct 24, 2023



Annotated data plays a critical role in Natural Language Processing (NLP) in training models and evaluating their performance. Given recent developments in Large Language Models (LLMs), models such as ChatGPT demonstrate zero-shot capability on many text-annotation tasks, comparable with or even exceeding human annotators. Such LLMs can serve as alternatives for manual annotation, due to lower costs and higher scalability. However, limited work has leveraged LLMs as complementary annotators, nor explored how annotation work is best allocated among humans and LLMs to achieve both quality and cost objectives. We propose CoAnnotating, a novel paradigm for Human-LLM co-annotation of unstructured texts at scale. Under this framework, we utilize uncertainty to estimate LLMs' annotation capability. Our empirical study shows CoAnnotating to be an effective means to allocate work from results on different datasets, with up to 21% performance improvement over random baseline. For code implementation, see https://github.com/SALT-NLP/CoAnnotating.
CoMPosT: Characterizing and Evaluating Caricature in LLM Simulations
Oct 17, 2023
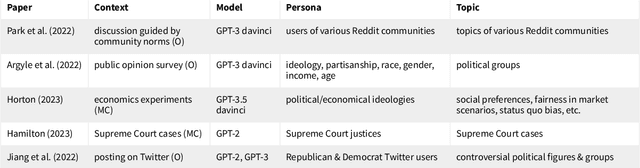

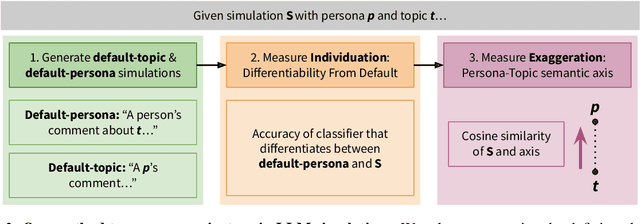
Recent work has aimed to capture nuances of human behavior by using LLMs to simulate responses from particular demographics in settings like social science experiments and public opinion surveys. However, there are currently no established ways to discuss or evaluate the quality of such LLM simulations. Moreover, there is growing concern that these LLM simulations are flattened caricatures of the personas that they aim to simulate, failing to capture the multidimensionality of people and perpetuating stereotypes. To bridge these gaps, we present CoMPosT, a framework to characterize LLM simulations using four dimensions: Context, Model, Persona, and Topic. We use this framework to measure open-ended LLM simulations' susceptibility to caricature, defined via two criteria: individuation and exaggeration. We evaluate the level of caricature in scenarios from existing work on LLM simulations. We find that for GPT-4, simulations of certain demographics (political and marginalized groups) and topics (general, uncontroversial) are highly susceptible to caricature.
"Mistakes Help Us Grow": Facilitating and Evaluating Growth Mindset Supportive Language in Classrooms
Oct 16, 2023Teachers' growth mindset supportive language (GMSL)--rhetoric emphasizing that one's skills can be improved over time--has been shown to significantly reduce disparities in academic achievement and enhance students' learning outcomes. Although teachers espouse growth mindset principles, most find it difficult to adopt GMSL in their practice due the lack of effective coaching in this area. We explore whether large language models (LLMs) can provide automated, personalized coaching to support teachers' use of GMSL. We establish an effective coaching tool to reframe unsupportive utterances to GMSL by developing (i) a parallel dataset containing GMSL-trained teacher reframings of unsupportive statements with an accompanying annotation guide, (ii) a GMSL prompt framework to revise teachers' unsupportive language, and (iii) an evaluation framework grounded in psychological theory for evaluating GMSL with the help of students and teachers. We conduct a large-scale evaluation involving 174 teachers and 1,006 students, finding that both teachers and students perceive GMSL-trained teacher and model reframings as more effective in fostering a growth mindset and promoting challenge-seeking behavior, among other benefits. We also find that model-generated reframings outperform those from the GMSL-trained teachers. These results show promise for harnessing LLMs to provide automated GMSL feedback for teachers and, more broadly, LLMs' potentiality for supporting students' learning in the classroom. Our findings also demonstrate the benefit of large-scale human evaluations when applying LLMs in educational domains.
Generating and Evaluating Tests for K-12 Students with Language Model Simulations: A Case Study on Sentence Reading Efficiency
Oct 10, 2023Developing an educational test can be expensive and time-consuming, as each item must be written by experts and then evaluated by collecting hundreds of student responses. Moreover, many tests require multiple distinct sets of questions administered throughout the school year to closely monitor students' progress, known as parallel tests. In this study, we focus on tests of silent sentence reading efficiency, used to assess students' reading ability over time. To generate high-quality parallel tests, we propose to fine-tune large language models (LLMs) to simulate how previous students would have responded to unseen items. With these simulated responses, we can estimate each item's difficulty and ambiguity. We first use GPT-4 to generate new test items following a list of expert-developed rules and then apply a fine-tuned LLM to filter the items based on criteria from psychological measurements. We also propose an optimal-transport-inspired technique for generating parallel tests and show the generated tests closely correspond to the original test's difficulty and reliability based on crowdworker responses. Our evaluation of a generated test with 234 students from grades 2 to 8 produces test scores highly correlated (r=0.93) to those of a standard test form written by human experts and evaluated across thousands of K-12 students.
DyVal: Graph-informed Dynamic Evaluation of Large Language Models
Oct 05, 2023



Large language models (LLMs) have achieved remarkable performance in various evaluation benchmarks. However, concerns about their performance are raised on potential data contamination in their considerable volume of training corpus. Moreover, the static nature and fixed complexity of current benchmarks may inadequately gauge the advancing capabilities of LLMs. In this paper, we introduce DyVal, a novel, general, and flexible evaluation protocol for dynamic evaluation of LLMs. Based on our proposed dynamic evaluation framework, we build graph-informed DyVal by leveraging the structural advantage of directed acyclic graphs to dynamically generate evaluation samples with controllable complexities. DyVal generates challenging evaluation sets on reasoning tasks including mathematics, logical reasoning, and algorithm problems. We evaluate various LLMs ranging from Flan-T5-large to ChatGPT and GPT4. Experiments demonstrate that LLMs perform worse in DyVal-generated evaluation samples with different complexities, emphasizing the significance of dynamic evaluation. We also analyze the failure cases and results of different prompting methods. Moreover, DyVal-generated samples are not only evaluation sets, but also helpful data for fine-tuning to improve the performance of LLMs on existing benchmarks. We hope that DyVal can shed light on the future evaluation research of LLMs.
MIDDAG: Where Does Our News Go? Investigating Information Diffusion via Community-Level Information Pathways
Oct 04, 2023We present MIDDAG, an intuitive, interactive system that visualizes the information propagation paths on social media triggered by COVID-19-related news articles accompanied by comprehensive insights including user/community susceptibility level, as well as events and popular opinions raised by the crowd while propagating the information. Besides discovering information flow patterns among users, we construct communities among users and develop the propagation forecasting capability, enabling tracing and understanding of how information is disseminated at a higher level.
Dynamic LLM-Agent Network: An LLM-agent Collaboration Framework with Agent Team Optimization
Oct 03, 2023



Large language model (LLM) agents have been shown effective on a wide range of tasks, and by ensembling multiple LLM agents, their performances could be further improved. Existing approaches employ a fixed set of agents to interact with each other in a static architecture, which limits their generalizability to various tasks and requires strong human prior in designing these agents. In this work, we propose to construct a strategic team of agents communicating in a dynamic interaction architecture based on the task query. Specifically, we build a framework named Dynamic LLM-Agent Network ($\textbf{DyLAN}$) for LLM-agent collaboration on complicated tasks like reasoning and code generation. DyLAN enables agents to interact for multiple rounds in a dynamic architecture with inference-time agent selection and an early-stopping mechanism to improve performance and efficiency. We further design an automatic agent team optimization algorithm based on an unsupervised metric termed $\textit{Agent Importance Score}$, enabling the selection of best agents based on the contribution each agent makes. Empirically, we demonstrate that DyLAN performs well in both reasoning and code generation tasks with reasonable computational cost. DyLAN achieves 13.0% and 13.3% improvement on MATH and HumanEval, respectively, compared to a single execution on GPT-35-turbo. On specific subjects of MMLU, agent team optimization in DyLAN increases accuracy by up to 25.0%.