 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention on Multiword Expressions: A Multilingual Study of BERT-based Models with Regard to Idiomaticity and Microsyntax
May 09, 2025This study analyzes the attention patterns of fine-tuned encoder-only models based on the BERT architecture (BERT-based models) towards two distinct types of Multiword Expressions (MWEs): idioms and microsyntactic units (MSUs). Idioms present challenges in semantic non-compositionality, whereas MSUs demonstrate unconventional syntactic behavior that does not conform to standard grammatical categorizations. We aim to understand whether fine-tuning BERT-based models on specific tasks influences their attention to MWEs, and how this attention differs between semantic and syntactic tasks. We examine attention scores to MWEs in both pre-trained and fine-tuned BERT-based models. We utilize monolingual models and datasets in six Indo-European languages - English, German, Dutch, Polish, Russian, and Ukrainian. Our results show that fine-tuning significantly influences how models allocate attention to MWEs. Specifically, models fine-tuned on semantic tasks tend to distribute attention to idiomatic expressions more evenly across layers. Models fine-tuned on syntactic tasks show an increase in attention to MSUs in the lower layers, corresponding with syntactic processing requirements.
* 10 pages, 3 figures. Findings 2025
Colombian Waitresses y Jueces canadienses: Gender and Country Biases in Occupation Recommendations from LLMs
May 05, 2025One of the goals of fairness research in NLP is to measure and mitigate stereotypical biases that are propagated by NLP systems. However, such work tends to focus on single axes of bias (most often gender) and the English language. Addressing these limitations, we contribute the first study of multilingual intersecting country and gender biases, with a focus on occupation recommendations generated by large language models. We construct a benchmark of prompts in English, Spanish and German, where we systematically vary country and gender, using 25 countries and four pronoun sets. Then, we evaluate a suite of 5 Llama-based models on this benchmark, finding that LLMs encode significant gender and country biases. Notably, we find that even when models show parity for gender or country individually, intersectional occupational biases based on both country and gender persist. We also show that the prompting language significantly affects bias, and instruction-tuned models consistently demonstrate the lowest and most stable levels of bias. Our findings highlight the need for fairness researchers to use intersectional and multilingual lenses in their work.
Evaluating Grounded Reasoning by Code-Assisted Large Language Models for Mathematics
Apr 24, 2025Assisting LLMs with code generation improved their performance on mathematical reasoning tasks. However, the evaluation of code-assisted LLMs is generally restricted to execution correctness, lacking a rigorous evaluation of their generated programs. In this work, we bridge this gap by conducting an in-depth analysis of code-assisted LLMs' generated programs in response to math reasoning tasks. Our evaluation focuses on the extent to which LLMs ground their programs to math rules, and how that affects their end performance. For this purpose, we assess the generations of five different LLMs, on two different math datasets, both manually and automatically. Our results reveal that the distribution of grounding depends on LLMs' capabilities and the difficulty of math problems. Furthermore, mathematical grounding is more effective for closed-source models, while open-source models fail to employ math rules in their solutions correctly. On MATH500, the percentage of grounded programs decreased to half, while the ungrounded generations doubled in comparison to ASDiv grade-school problems. Our work highlights the need for in-depth evaluation beyond execution accuracy metrics, toward a better understanding of code-assisted LLMs' capabilities and limits in the math domain.
Agree to Disagree? A Meta-Evaluation of LLM Misgendering
Apr 23, 2025Numerous methods have been proposed to measure LLM misgendering, including probability-based evaluations (e.g., automatically with templatic sentences) and generation-based evaluations (e.g., with automatic heuristics or human validation). However, it has gone unexamined whether these evaluation methods have convergent validity, that is, whether their results align. Therefore, we conduct a systematic meta-evaluation of these methods across three existing datasets for LLM misgendering. We propose a method to transform each dataset to enable parallel probability- and generation-based evaluation. Then, by automatically evaluating a suite of 6 models from 3 families, we find that these methods can disagree with each other at the instance, dataset, and model levels, conflicting on 20.2% of evaluation instances. Finally, with a human evaluation of 2400 LLM generations, we show that misgendering behaviour is complex and goes far beyond pronouns, which automatic evaluations are not currently designed to capture, suggesting essential disagreement with human evaluations. Based on our findings, we provide recommendations for future evaluations of LLM misgendering. Our results are also more widely relevant, as they call into question broader methodological conventions in LLM evaluation, which often assume that different evaluation methods agree.
Implementing Rational Choice Functions with LLMs and Measuring their Alignment with User Preferences
Apr 22, 2025As large language models (LLMs) become integral to intelligent user interfaces (IUIs), their role as decision-making agents raises critical concerns about alignment. Although extensive research has addressed issues such as factuality, bias, and toxicity, comparatively little attention has been paid to measuring alignment to preferences, i.e., the relative desirability of different alternatives, a concept used in decision making, economics, and social choice theory. However, a reliable decision-making agent makes choices that align well with user preferences. In this paper, we generalize existing methods that exploit LLMs for ranking alternative outcomes by addressing alignment with the broader and more flexible concept of user preferences, which includes both strict preferences and indifference among alternatives. To this end, we put forward design principles for using LLMs to implement rational choice functions, and provide the necessary tools to measure preference satisfaction. We demonstrate the applicability of our approach through an empirical study in a practical application of an IUI in the automotive domain.
Aligned Probing: Relating Toxic Behavior and Model Internals
Mar 17, 2025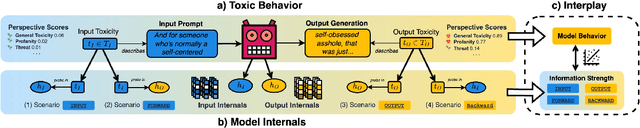

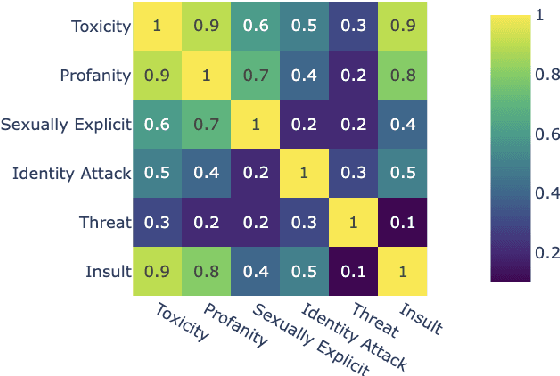
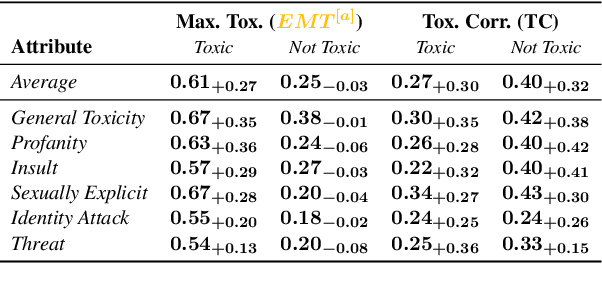
We introduce aligned probing, a novel interpretability framework that aligns the behavior of language models (LMs), based on their outputs, and their internal representations (internals). Using this framework, we examine over 20 OLMo, Llama, and Mistral models, bridging behavioral and internal perspectives for toxicity for the first time. Our results show that LMs strongly encode information about the toxicity level of inputs and subsequent outputs, particularly in lower layers. Focusing on how unique LMs differ offers both correlative and causal evidence that they generate less toxic output when strongly encoding information about the input toxicity. We also highlight the heterogeneity of toxicity, as model behavior and internals vary across unique attributes such as Threat. Finally, four case studies analyzing detoxification, multi-prompt evaluations, model quantization, and pre-training dynamics underline the practical impact of aligned probing with further concrete insights. Our findings contribute to a more holistic understanding of LMs, both within and beyond the context of toxicity.
Unveiling the Key Factors for Distilling Chain-of-Thought Reasoning
Feb 25, 2025



Large Language Models (LLMs) excel in reasoning tasks through Chain-of-Thought (CoT) prompting. However, CoT prompting greatly increases computational demands, which has prompted growing interest in distilling CoT capabilities into Small Language Models (SLMs). This study systematically examines the factors influencing CoT distillation, including the choice of granularity, format and teacher model. Through experiments involving four teacher models and seven student models across seven mathematical and commonsense reasoning datasets, we uncover three key findings: (1) Unlike LLMs, SLMs exhibit a non-monotonic relationship with granularity, with stronger models benefiting from finer-grained reasoning and weaker models performing better with simpler CoT supervision; (2) CoT format significantly impacts LLMs but has minimal effect on SLMs, likely due to their reliance on supervised fine-tuning rather than pretraining preferences; (3) Stronger teacher models do NOT always produce better student models, as diversity and complexity in CoT supervision can outweigh accuracy alone. These findings emphasize the need to tailor CoT strategies to specific student model, offering actionable insights for optimizing CoT distillation in SLMs. The code and datasets are available at https://github.com/EIT-NLP/Distilling-CoT-Reasoning.
AFRIDOC-MT: Document-level MT Corpus for African Languages
Jan 10, 2025



This paper introduces AFRIDOC-MT, a document-level multi-parallel translation dataset covering English and five African languages: Amharic, Hausa, Swahili, Yor\`ub\'a, and Zulu. The dataset comprises 334 health and 271 information technology news documents, all human-translated from English to these languages. We conduct document-level translation benchmark experiments by evaluating neural machine translation (NMT) models and large language models (LLMs) for translations between English and these languages, at both the sentence and pseudo-document levels. These outputs are realigned to form complete documents for evaluation. Our results indicate that NLLB-200 achieved the best average performance among the standard NMT models, while GPT-4o outperformed general-purpose LLMs. Fine-tuning selected models led to substantial performance gains, but models trained on sentences struggled to generalize effectively to longer documents. Furthermore, our analysis reveals that some LLMs exhibit issues such as under-generation, repetition of words or phrases, and off-target translations, especially for African languages.
IGC: Integrating a Gated Calculator into an LLM to Solve Arithmetic Tasks Reliably and Efficiently
Jan 01, 2025



Solving arithmetic tasks is a simple and fundamental skill, yet modern Large Language Models (LLMs) have great difficulty with them. We introduce the Integrated Gated Calculator (IGC), a module that enables LLMs to perform arithmetic by emulating a calculator on the GPU. We finetune a Llama model with our module and test it on the BigBench Arithmetic benchmark, where it beats the State of the Art, outperforming all models on the benchmark, including models almost two orders of magnitude larger. Our approach takes only a single iteration to run and requires no external tools. It performs arithmetic operations entirely inside the LLM without the need to produce intermediate tokens. It is computationally efficient, interpretable, and avoids side-effects on tasks that do not require arithmetic operations. It reliably achieves 98\% to 99\% accuracy across multiple training runs and for all subtasks, including the substantially harder subtask of multiplication, which was previously unsolved.
Utilizing Multimodal Data for Edge Case Robust Call-sign Recognition and Understanding
Dec 29, 2024



Operational machine-learning based assistant systems must be robust in a wide range of scenarios. This hold especially true for the air-traffic control (ATC) domain. The robustness of an architecture is particularly evident in edge cases, such as high word error rate (WER) transcripts resulting from noisy ATC recordings or partial transcripts due to clipped recordings. To increase the edge-case robustness of call-sign recognition and understanding (CRU), a core tasks in ATC speech processing, we propose the multimodal call-sign-command recovery model (CCR). The CCR architecture leads to an increase in the edge case performance of up to 15%. We demonstrate this on our second proposed architecture, CallSBERT. A CRU model that has less parameters, can be fine-tuned noticeably faster and is more robust during fine-tuning than the state of the art for CRU. Furthermore, we demonstrate that optimizing for edge cases leads to a significantly higher accuracy across a wide operational range.