 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Backward: Streaming Video-to-Video Translation with Feature Banks
May 24, 2024



This paper introduces StreamV2V, a diffusion model that achieves real-time streaming video-to-video (V2V) translation with user prompts. Unlike prior V2V methods using batches to process limited frames, we opt to process frames in a streaming fashion, to support unlimited frames. At the heart of StreamV2V lies a backward-looking principle that relates the present to the past. This is realized by maintaining a feature bank, which archives information from past frames. For incoming frames, StreamV2V extends self-attention to include banked keys and values and directly fuses similar past features into the output. The feature bank is continually updated by merging stored and new features, making it compact but informative. StreamV2V stands out for its adaptability and efficiency, seamlessly integrating with image diffusion models without fine-tuning. It can run 20 FPS on one A100 GPU, being 15x, 46x, 108x, and 158x faster than FlowVid, CoDeF, Rerender, and TokenFlow, respectively. Quantitative metrics and user studies confirm StreamV2V's exceptional ability to maintain temporal consistency.
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Apr 02, 2024



Visual sound source localization poses a significant challenge in identifying the semantic region of each sounding source within a video. Existing self-supervised and weakly supervised source localization methods struggle to accurately distinguish the semantic regions of each sounding object, particularly in multi-source mixtures. These methods often rely on audio-visual correspondence as guidance, which can lead to substantial performance drops in complex multi-source localization scenarios. The lack of access to individual source sounds in multi-source mixtures during training exacerbates the difficulty of learning effective audio-visual correspondence for localization. To address this limitation, in this paper, we propose incorporating the text modality as an intermediate feature guide using tri-modal joint embedding models (e.g., AudioCLIP) to disentangle the semantic audio-visual source correspondence in multi-source mixtures. Our framework, dubbed T-VSL, begins by predicting the class of sounding entities in mixtures. Subsequently, the textual representation of each sounding source is employed as guidance to disentangle fine-grained audio-visual source correspondence from multi-source mixtures, leveraging the tri-modal AudioCLIP embedding. This approach enables our framework to handle a flexible number of sources and exhibits promising zero-shot transferability to unseen classes during test time. Extensive experiments conducted on the MUSIC, VGGSound, and VGGSound-Instruments datasets demonstrate significant performance improvements over state-of-the-art methods.
Weakly-supervised Audio Separation via Bi-modal Semantic Similarity
Apr 02, 2024



Conditional sound separation in multi-source audio mixtures without having access to single source sound data during training is a long standing challenge. Existing mix-and-separate based methods suffer from significant performance drop with multi-source training mixtures due to the lack of supervision signal for single source separation cases during training. However, in the case of language-conditional audio separation, we do have access to corresponding text descriptions for each audio mixture in our training data, which can be seen as (rough) representations of the audio samples in the language modality. To this end, in this paper, we propose a generic bi-modal separation framework which can enhance the existing unsupervised frameworks to separate single-source signals in a target modality (i.e., audio) using the easily separable corresponding signals in the conditioning modality (i.e., language), without having access to single-source samples in the target modality during training. We empirically show that this is well within reach if we have access to a pretrained joint embedding model between the two modalities (i.e., CLAP). Furthermore, we propose to incorporate our framework into two fundamental scenarios to enhance separation performance. First, we show that our proposed methodology significantly improves the performance of purely unsupervised baselines by reducing the distribution shift between training and test samples. In particular, we show that our framework can achieve 71% boost in terms of Signal-to-Distortion Ratio (SDR) over the baseline, reaching 97.5% of the supervised learning performance. Second, we show that we can further improve the performance of the supervised learning itself by 17% if we augment it by our proposed weakly-supervised framework, that enables a powerful semi-supervised framework for audio separation.
PaPr: Training-Free One-Step Patch Pruning with Lightweight ConvNets for Faster Inference
Mar 24, 2024



As deep neural networks evolve from convolutional neural networks (ConvNets) to advanced vision transformers (ViTs), there is an increased need to eliminate redundant data for faster processing without compromising accuracy. Previous methods are often architecture-specific or necessitate re-training, restricting their applicability with frequent model updates. To solve this, we first introduce a novel property of lightweight ConvNets: their ability to identify key discriminative patch regions in images, irrespective of model's final accuracy or size. We demonstrate that fully-connected layers are the primary bottleneck for ConvNets performance, and their suppression with simple weight recalibration markedly enhances discriminative patch localization performance. Using this insight, we introduce PaPr, a method for substantially pruning redundant patches with minimal accuracy loss using lightweight ConvNets across a variety of deep learning architectures, including ViTs, ConvNets, and hybrid transformers, without any re-training. Moreover, the simple early-stage one-step patch pruning with PaPr enhances existing patch reduction methods. Through extensive testing on diverse architectures, PaPr achieves significantly higher accuracy over state-of-the-art patch reduction methods with similar FLOP count reduction. More specifically, PaPr reduces about 70% of redundant patches in videos with less than 0.8% drop in accuracy, and up to 3.7x FLOPs reduction, which is a 15% more reduction with 2.5% higher accuracy.
FlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis
Dec 29, 2023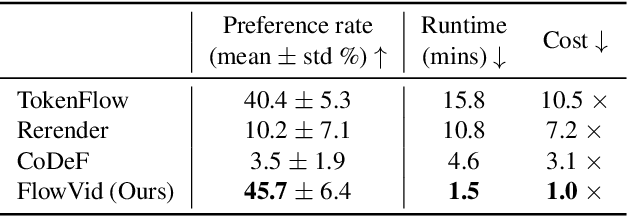

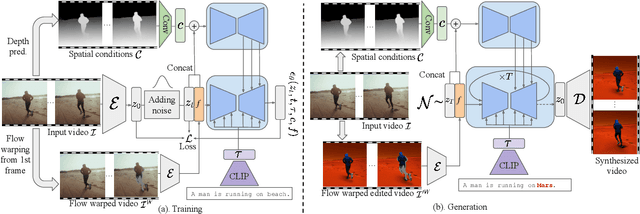

Diffusion models have transformed the image-to-image (I2I) synthesis and are now permeating into videos. However, the advancement of video-to-video (V2V) synthesis has been hampered by the challenge of maintaining temporal consistency across video frames. This paper proposes a consistent V2V synthesis framework by jointly leveraging spatial conditions and temporal optical flow clues within the source video. Contrary to prior methods that strictly adhere to optical flow, our approach harnesses its benefits while handling the imperfection in flow estimation. We encode the optical flow via warping from the first frame and serve it as a supplementary reference in the diffusion model. This enables our model for video synthesis by editing the first frame with any prevalent I2I models and then propagating edits to successive frames. Our V2V model, FlowVid, demonstrates remarkable properties: (1) Flexibility: FlowVid works seamlessly with existing I2I models, facilitating various modifications, including stylization, object swaps, and local edits. (2) Efficiency: Generation of a 4-second video with 30 FPS and 512x512 resolution takes only 1.5 minutes, which is 3.1x, 7.2x, and 10.5x faster than CoDeF, Rerender, and TokenFlow, respectively. (3) High-quality: In user studies, our FlowVid is preferred 45.7% of the time, outperforming CoDeF (3.5%), Rerender (10.2%), and TokenFlow (40.4%).
FLORA: Fine-grained Low-Rank Architecture Search for Vision Transformer
Nov 07, 2023



Vision Transformers (ViT) have recently demonstrated success across a myriad of computer vision tasks. However, their elevated computational demands pose significant challenges for real-world deployment. While low-rank approximation stands out as a renowned method to reduce computational loads, efficiently automating the target rank selection in ViT remains a challenge. Drawing from the notable similarity and alignment between the processes of rank selection and One-Shot NAS, we introduce FLORA, an end-to-end automatic framework based on NAS. To overcome the design challenge of supernet posed by vast search space, FLORA employs a low-rank aware candidate filtering strategy. This method adeptly identifies and eliminates underperforming candidates, effectively alleviating potential undertraining and interference among subnetworks. To further enhance the quality of low-rank supernets, we design a low-rank specific training paradigm. First, we propose weight inheritance to construct supernet and enable gradient sharing among low-rank modules. Secondly, we adopt low-rank aware sampling to strategically allocate training resources, taking into account inherited information from pre-trained models. Empirical results underscore FLORA's efficacy. With our method, a more fine-grained rank configuration can be generated automatically and yield up to 33% extra FLOPs reduction compared to a simple uniform configuration. More specific, FLORA-DeiT-B/FLORA-Swin-B can save up to 55%/42% FLOPs almost without performance degradtion. Importantly, FLORA boasts both versatility and orthogonality, offering an extra 21%-26% FLOPs reduction when integrated with leading compression techniques or compact hybrid structures. Our code is publicly available at https://github.com/shadowpa0327/FLORA.
Efficient Low-rank Backpropagation for Vision Transformer Adaptation
Sep 26, 2023



The increasing scale of vision transformers (ViT) has made the efficient fine-tuning of these large models for specific needs a significant challenge in various applications. This issue originates from the computationally demanding matrix multiplications required during the backpropagation process through linear layers in ViT. In this paper, we tackle this problem by proposing a new Low-rank BackPropagation via Walsh-Hadamard Transformation (LBP-WHT) method. Intuitively, LBP-WHT projects the gradient into a low-rank space and carries out backpropagation. This approach substantially reduces the computation needed for adapting ViT, as matrix multiplication in the low-rank space is far less resource-intensive. We conduct extensive experiments with different models (ViT, hybrid convolution-ViT model) on multiple datasets to demonstrate the effectiveness of our method. For instance, when adapting an EfficientFormer-L1 model on CIFAR100, our LBP-WHT achieves 10.4% higher accuracy than the state-of-the-art baseline, while requiring 9 MFLOPs less computation. As the first work to accelerate ViT adaptation with low-rank backpropagation, our LBP-WHT method is complementary to many prior efforts and can be combined with them for better performance.
SSVOD: Semi-Supervised Video Object Detection with Sparse Annotations
Sep 04, 2023



Despite significant progress in semi-supervised learning for image object detection, several key issues are yet to be addressed for video object detection: (1) Achieving good performance for supervised video object detection greatly depends on the availability of annotated frames. (2) Despite having large inter-frame correlations in a video, collecting annotations for a large number of frames per video is expensive, time-consuming, and often redundant. (3) Existing semi-supervised techniques on static images can hardly exploit the temporal motion dynamics inherently present in videos. In this paper, we introduce SSVOD, an end-to-end semi-supervised video object detection framework that exploits motion dynamics of videos to utilize large-scale unlabeled frames with sparse annotations. To selectively assemble robust pseudo-labels across groups of frames, we introduce \textit{flow-warped predictions} from nearby frames for temporal-consistency estimation. In particular, we introduce cross-IoU and cross-divergence based selection methods over a set of estimated predictions to include robust pseudo-labels for bounding boxes and class labels, respectively. To strike a balance between confirmation bias and uncertainty noise in pseudo-labels, we propose confidence threshold based combination of hard and soft pseudo-labels. Our method achieves significant performance improvements over existing methods on ImageNet-VID, Epic-KITCHENS, and YouTube-VIS datasets. Code and pre-trained models will be released.
Jumping through Local Minima: Quantization in the Loss Landscape of Vision Transformers
Aug 21, 2023Quantization scale and bit-width are the most important parameters when considering how to quantize a neural network. Prior work focuses on optimizing quantization scales in a global manner through gradient methods (gradient descent \& Hessian analysis). Yet, when applying perturbations to quantization scales, we observe a very jagged, highly non-smooth test loss landscape. In fact, small perturbations in quantization scale can greatly affect accuracy, yielding a $0.5-0.8\%$ accuracy boost in 4-bit quantized vision transformers (ViTs). In this regime, gradient methods break down, since they cannot reliably reach local minima. In our work, dubbed Evol-Q, we use evolutionary search to effectively traverse the non-smooth landscape. Additionally, we propose using an infoNCE loss, which not only helps combat overfitting on the small calibration dataset ($1,000$ images) but also makes traversing such a highly non-smooth surface easier. Evol-Q improves the top-1 accuracy of a fully quantized ViT-Base by $10.30\%$, $0.78\%$, and $0.15\%$ for $3$-bit, $4$-bit, and $8$-bit weight quantization levels. Extensive experiments on a variety of CNN and ViT architectures further demonstrate its robustness in extreme quantization scenarios. Our code is available at https://github.com/enyac-group/evol-q
MobileTL: On-device Transfer Learning with Inverted Residual Blocks
Dec 05, 2022



Transfer learning on edge is challenging due to on-device limited resources. Existing work addresses this issue by training a subset of parameters or adding model patches. Developed with inference in mind, Inverted Residual Blocks (IRBs) split a convolutional layer into depthwise and pointwise convolutions, leading to more stacking layers, e.g., convolution, normalization, and activation layers. Though they are efficient for inference, IRBs require that additional activation maps are stored in memory for training weights for convolution layers and scales for normalization layers. As a result, their high memory cost prohibits training IRBs on resource-limited edge devices, and making them unsuitable in the context of transfer learning. To address this issue, we present MobileTL, a memory and computationally efficient on-device transfer learning method for models built with IRBs. MobileTL trains the shifts for internal normalization layers to avoid storing activation maps for the backward pass. Also, MobileTL approximates the backward computation of the activation layer (e.g., Hard-Swish and ReLU6) as a signed function which enables storing a binary mask instead of activation maps for the backward pass. MobileTL fine-tunes a few top blocks (close to output) rather than propagating the gradient through the whole network to reduce the computation cost. Our method reduces memory usage by 46% and 53% for MobileNetV2 and V3 IRBs, respectively. For MobileNetV3, we observe a 36% reduction in floating-point operations (FLOPs) when fine-tuning 5 blocks, while only incurring a 0.6% accuracy reduction on CIFAR10. Extensive experiments on multiple datasets demonstrate that our method is Pareto-optimal (best accuracy under given hardware constraints) compared to prior work in transfer learning for edge devices.