 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSep: Leveraging Large Language Models with Textual Inversion for Open World Audio Separation
Sep 28, 2024



Audio separation in real-world scenarios, where mixtures contain a variable number of sources, presents significant challenges due to limitations of existing models, such as over-separation, under-separation, and dependence on predefined training sources. We propose OpenSep, a novel framework that leverages large language models (LLMs) for automated audio separation, eliminating the need for manual intervention and overcoming source limitations. OpenSep uses textual inversion to generate captions from audio mixtures with off-the-shelf audio captioning models, effectively parsing the sound sources present. It then employs few-shot LLM prompting to extract detailed audio properties of each parsed source, facilitating separation in unseen mixtures. Additionally, we introduce a multi-level extension of the mix-and-separate training framework to enhance modality alignment by separating single source sounds and mixtures simultaneously. Extensive experiments demonstrate OpenSep's superiority in precisely separating new, unseen, and variable sources in challenging mixtures, outperforming SOTA baseline methods. Code is released at https://github.com/tanvir-utexas/OpenSep.git
Ada-VE: Training-Free Consistent Video Editing Using Adaptive Motion Prior
Jun 07, 2024



Video-to-video synthesis models face significant challenges, such as ensuring consistent character generation across frames, maintaining smooth temporal transitions, and preserving quality during fast motion. The introduction of joint fully cross-frame self-attention mechanisms has improved character consistency, but this comes at the cost of increased computational complexity. This full cross-frame self-attention mechanism also incorporates redundant details and limits the number of frames that can be jointly edited due to its computational cost. Moreover, the lack of frames in cross-frame attention adversely affects temporal consistency and visual quality. To address these limitations, we propose a new adaptive motion-guided cross-frame attention mechanism that drastically reduces complexity while preserving semantic details and temporal consistency. Specifically, we selectively incorporate the moving regions of successive frames in cross-frame attention and sparsely include stationary regions based on optical flow sampling. This technique allows for an increased number of jointly edited frames without additional computational overhead. For longer duration of video editing, existing methods primarily focus on frame interpolation or flow-warping from jointly edited keyframes, which often results in blurry frames or reduced temporal consistency. To improve this, we introduce KV-caching of jointly edited frames and reuse the same KV across all intermediate frames, significantly enhancing both intermediate frame quality and temporal consistency. Overall, our motion-sampling method enables the use of around three times more keyframes than existing joint editing methods while maintaining superior prediction quality. Ada-VE achieves up to 4x speed-up when using fully-extended self-attention across 40 frames for joint editing, without compromising visual quality or temporal consistency.
MA-AVT: Modality Alignment for Parameter-Efficient Audio-Visual Transformers
Jun 07, 2024



Recent advances in pre-trained vision transformers have shown promise in parameter-efficient audio-visual learning without audio pre-training. However, few studies have investigated effective methods for aligning multimodal features in parameter-efficient audio-visual transformers. In this paper, we propose MA-AVT, a new parameter-efficient audio-visual transformer employing deep modality alignment for corresponding multimodal semantic features. Specifically, we introduce joint unimodal and multimodal token learning for aligning the two modalities with a frozen modality-shared transformer. This allows the model to learn separate representations for each modality, while also attending to the cross-modal relationships between them. In addition, unlike prior work that only aligns coarse features from the output of unimodal encoders, we introduce blockwise contrastive learning to align coarse-to-fine-grain hierarchical features throughout the encoding phase. Furthermore, to suppress the background features in each modality from foreground matched audio-visual features, we introduce a robust discriminative foreground mining scheme. Through extensive experiments on benchmark AVE, VGGSound, and CREMA-D datasets, we achieve considerable performance improvements over SOTA methods.
Weakly-supervised Audio Separation via Bi-modal Semantic Similarity
Apr 02, 2024



Conditional sound separation in multi-source audio mixtures without having access to single source sound data during training is a long standing challenge. Existing mix-and-separate based methods suffer from significant performance drop with multi-source training mixtures due to the lack of supervision signal for single source separation cases during training. However, in the case of language-conditional audio separation, we do have access to corresponding text descriptions for each audio mixture in our training data, which can be seen as (rough) representations of the audio samples in the language modality. To this end, in this paper, we propose a generic bi-modal separation framework which can enhance the existing unsupervised frameworks to separate single-source signals in a target modality (i.e., audio) using the easily separable corresponding signals in the conditioning modality (i.e., language), without having access to single-source samples in the target modality during training. We empirically show that this is well within reach if we have access to a pretrained joint embedding model between the two modalities (i.e., CLAP). Furthermore, we propose to incorporate our framework into two fundamental scenarios to enhance separation performance. First, we show that our proposed methodology significantly improves the performance of purely unsupervised baselines by reducing the distribution shift between training and test samples. In particular, we show that our framework can achieve 71% boost in terms of Signal-to-Distortion Ratio (SDR) over the baseline, reaching 97.5% of the supervised learning performance. Second, we show that we can further improve the performance of the supervised learning itself by 17% if we augment it by our proposed weakly-supervised framework, that enables a powerful semi-supervised framework for audio separation.
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Apr 02, 2024



Visual sound source localization poses a significant challenge in identifying the semantic region of each sounding source within a video. Existing self-supervised and weakly supervised source localization methods struggle to accurately distinguish the semantic regions of each sounding object, particularly in multi-source mixtures. These methods often rely on audio-visual correspondence as guidance, which can lead to substantial performance drops in complex multi-source localization scenarios. The lack of access to individual source sounds in multi-source mixtures during training exacerbates the difficulty of learning effective audio-visual correspondence for localization. To address this limitation, in this paper, we propose incorporating the text modality as an intermediate feature guide using tri-modal joint embedding models (e.g., AudioCLIP) to disentangle the semantic audio-visual source correspondence in multi-source mixtures. Our framework, dubbed T-VSL, begins by predicting the class of sounding entities in mixtures. Subsequently, the textual representation of each sounding source is employed as guidance to disentangle fine-grained audio-visual source correspondence from multi-source mixtures, leveraging the tri-modal AudioCLIP embedding. This approach enables our framework to handle a flexible number of sources and exhibits promising zero-shot transferability to unseen classes during test time. Extensive experiments conducted on the MUSIC, VGGSound, and VGGSound-Instruments datasets demonstrate significant performance improvements over state-of-the-art methods.
PaPr: Training-Free One-Step Patch Pruning with Lightweight ConvNets for Faster Inference
Mar 24, 2024



As deep neural networks evolve from convolutional neural networks (ConvNets) to advanced vision transformers (ViTs), there is an increased need to eliminate redundant data for faster processing without compromising accuracy. Previous methods are often architecture-specific or necessitate re-training, restricting their applicability with frequent model updates. To solve this, we first introduce a novel property of lightweight ConvNets: their ability to identify key discriminative patch regions in images, irrespective of model's final accuracy or size. We demonstrate that fully-connected layers are the primary bottleneck for ConvNets performance, and their suppression with simple weight recalibration markedly enhances discriminative patch localization performance. Using this insight, we introduce PaPr, a method for substantially pruning redundant patches with minimal accuracy loss using lightweight ConvNets across a variety of deep learning architectures, including ViTs, ConvNets, and hybrid transformers, without any re-training. Moreover, the simple early-stage one-step patch pruning with PaPr enhances existing patch reduction methods. Through extensive testing on diverse architectures, PaPr achieves significantly higher accuracy over state-of-the-art patch reduction methods with similar FLOP count reduction. More specifically, PaPr reduces about 70% of redundant patches in videos with less than 0.8% drop in accuracy, and up to 3.7x FLOPs reduction, which is a 15% more reduction with 2.5% higher accuracy.
SSVOD: Semi-Supervised Video Object Detection with Sparse Annotations
Sep 04, 2023



Despite significant progress in semi-supervised learning for image object detection, several key issues are yet to be addressed for video object detection: (1) Achieving good performance for supervised video object detection greatly depends on the availability of annotated frames. (2) Despite having large inter-frame correlations in a video, collecting annotations for a large number of frames per video is expensive, time-consuming, and often redundant. (3) Existing semi-supervised techniques on static images can hardly exploit the temporal motion dynamics inherently present in videos. In this paper, we introduce SSVOD, an end-to-end semi-supervised video object detection framework that exploits motion dynamics of videos to utilize large-scale unlabeled frames with sparse annotations. To selectively assemble robust pseudo-labels across groups of frames, we introduce \textit{flow-warped predictions} from nearby frames for temporal-consistency estimation. In particular, we introduce cross-IoU and cross-divergence based selection methods over a set of estimated predictions to include robust pseudo-labels for bounding boxes and class labels, respectively. To strike a balance between confirmation bias and uncertainty noise in pseudo-labels, we propose confidence threshold based combination of hard and soft pseudo-labels. Our method achieves significant performance improvements over existing methods on ImageNet-VID, Epic-KITCHENS, and YouTube-VIS datasets. Code and pre-trained models will be released.
Instance-Aware Repeat Factor Sampling for Long-Tailed Object Detection
May 14, 2023We propose an embarrassingly simple method -- instance-aware repeat factor sampling (IRFS) to address the problem of imbalanced data in long-tailed object detection. Imbalanced datasets in real-world object detection often suffer from a large disparity in the number of instances for each class. To improve the generalization performance of object detection models on rare classes, various data sampling techniques have been proposed. Repeat factor sampling (RFS) has shown promise due to its simplicity and effectiveness. Despite its efficiency, RFS completely neglects the instance counts and solely relies on the image count during re-sampling process. However, instance count may immensely vary for different classes with similar image counts. Such variation highlights the importance of both image and instance for addressing the long-tail distributions. Thus, we propose IRFS which unifies instance and image counts for the re-sampling process to be aware of different perspectives of the imbalance in long-tailed datasets. Our method shows promising results on the challenging LVIS v1.0 benchmark dataset over various architectures and backbones, demonstrating their effectiveness in improving the performance of object detection models on rare classes with a relative $+50\%$ average precision (AP) improvement over counterpart RFS. IRFS can serve as a strong baseline and be easily incorporated into existing long-tailed frameworks.
CIFF-Net: Contextual Image Feature Fusion for Melanoma Diagnosis
Mar 07, 2023



Melanoma is considered to be the deadliest variant of skin cancer causing around 75\% of total skin cancer deaths. To diagnose Melanoma, clinicians assess and compare multiple skin lesions of the same patient concurrently to gather contextual information regarding the patterns, and abnormality of the skin. So far this concurrent multi-image comparative method has not been explored by existing deep learning-based schemes. In this paper, based on contextual image feature fusion (CIFF), a deep neural network (CIFF-Net) is proposed, which integrates patient-level contextual information into the traditional approaches for improved Melanoma diagnosis by concurrent multi-image comparative method. The proposed multi-kernel self attention (MKSA) module offers better generalization of the extracted features by introducing multi-kernel operations in the self attention mechanisms. To utilize both self attention and contextual feature-wise attention, an attention guided module named contextual feature fusion (CFF) is proposed that integrates extracted features from different contextual images into a single feature vector. Finally, in comparative contextual feature fusion (CCFF) module, primary and contextual features are compared concurrently to generate comparative features. Significant improvement in performance has been achieved on the ISIC-2020 dataset over the traditional approaches that validate the effectiveness of the proposed contextual learning scheme.
AVE-CLIP: AudioCLIP-based Multi-window Temporal Transformer for Audio Visual Event Localization
Oct 11, 2022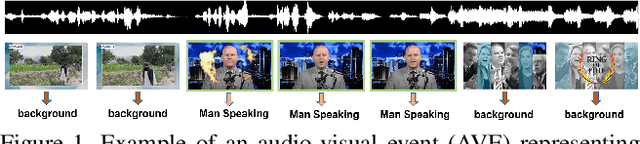
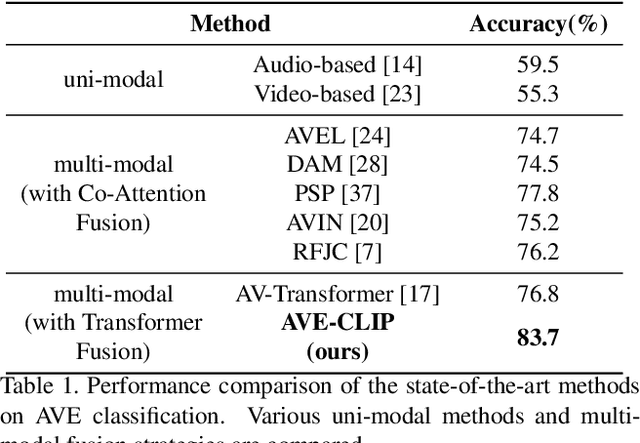
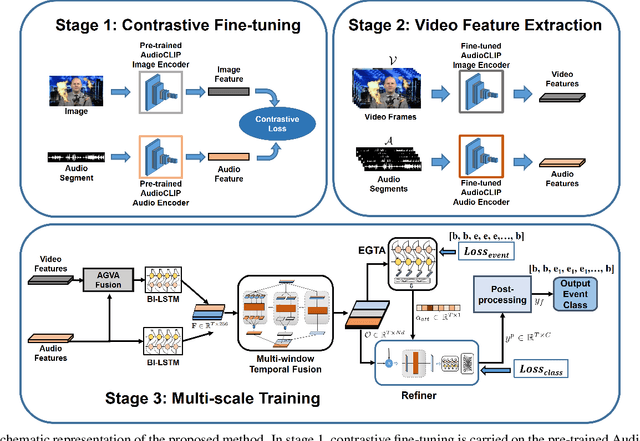

An audio-visual event (AVE) is denoted by the correspondence of the visual and auditory signals in a video segment. Precise localization of the AVEs is very challenging since it demands effective multi-modal feature correspondence to ground the short and long range temporal interactions. Existing approaches struggle in capturing the different scales of multi-modal interaction due to ineffective multi-modal training strategies. To overcome this limitation, we introduce AVE-CLIP, a novel framework that integrates the AudioCLIP pre-trained on large-scale audio-visual data with a multi-window temporal transformer to effectively operate on different temporal scales of video frames. Our contributions are three-fold: (1) We introduce a multi-stage training framework to incorporate AudioCLIP pre-trained with audio-image pairs into the AVE localization task on video frames through contrastive fine-tuning, effective mean video feature extraction, and multi-scale training phases. (2) We propose a multi-domain attention mechanism that operates on both temporal and feature domains over varying timescales to fuse the local and global feature variations. (3) We introduce a temporal refining scheme with event-guided attention followed by a simple-yet-effective post processing step to handle significant variations of the background over diverse events. Our method achieves state-of-the-art performance on the publicly available AVE dataset with 5.9% mean accuracy improvement which proves its superiority over existing approaches.