 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlimmable Domain Adaptation
Jun 14, 2022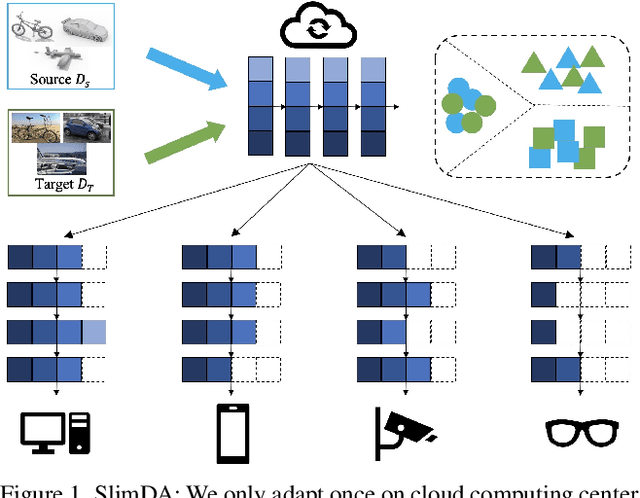

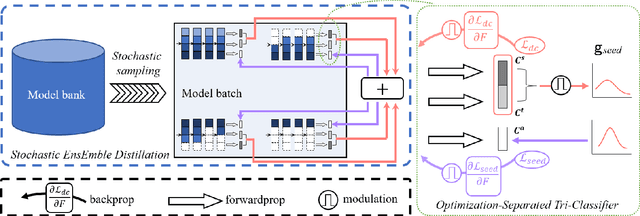
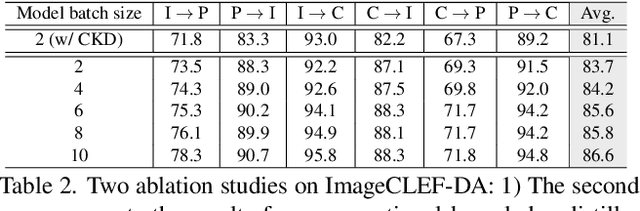
Vanilla unsupervised domain adaptation methods tend to optimize the model with fixed neural architecture, which is not very practical in real-world scenarios since the target data is usually processed by different resource-limited devices. It is therefore of great necessity to facilitate architecture adaptation across various devices. In this paper, we introduce a simple framework, Slimmable Domain Adaptation, to improve cross-domain generalization with a weight-sharing model bank, from which models of different capacities can be sampled to accommodate different accuracy-efficiency trade-offs. The main challenge in this framework lies in simultaneously boosting the adaptation performance of numerous models in the model bank. To tackle this problem, we develop a Stochastic EnsEmble Distillation method to fully exploit the complementary knowledge in the model bank for inter-model interaction. Nevertheless, considering the optimization conflict between inter-model interaction and intra-model adaptation, we augment the existing bi-classifier domain confusion architecture into an Optimization-Separated Tri-Classifier counterpart. After optimizing the model bank, architecture adaptation is leveraged via our proposed Unsupervised Performance Evaluation Metric. Under various resource constraints, our framework surpasses other competing approaches by a very large margin on multiple benchmarks. It is also worth emphasizing that our framework can preserve the performance improvement against the source-only model even when the computing complexity is reduced to $1/64$. Code will be available at https://github.com/hikvision-research/SlimDA.
* To appear in CVPR 2022. Code is coming soon: https://github.com/hikvision-research/SlimDA
Label Matching Semi-Supervised Object Detection
Jun 14, 2022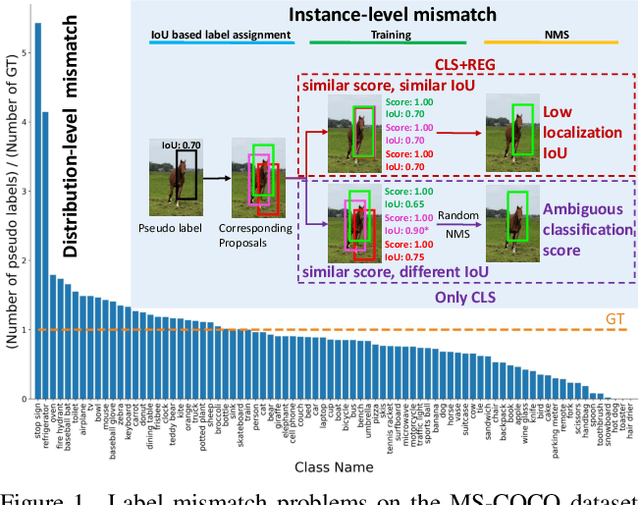
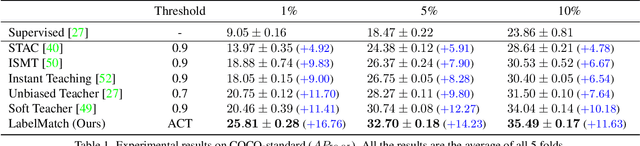
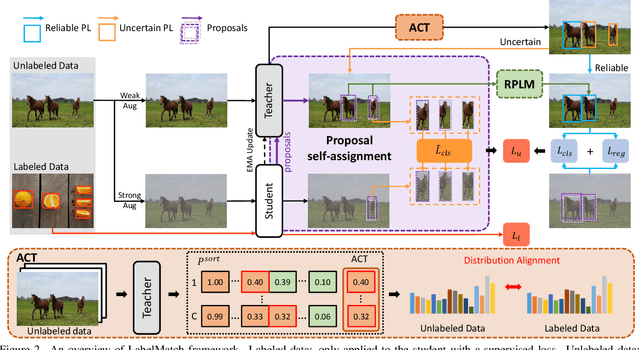

Semi-supervised object detection has made significant progress with the development of mean teacher driven self-training. Despite the promising results, the label mismatch problem is not yet fully explored in the previous works, leading to severe confirmation bias during self-training. In this paper, we delve into this problem and propose a simple yet effective LabelMatch framework from two different yet complementary perspectives, i.e., distribution-level and instance-level. For the former one, it is reasonable to approximate the class distribution of the unlabeled data from that of the labeled data according to Monte Carlo Sampling. Guided by this weakly supervision cue, we introduce a re-distribution mean teacher, which leverages adaptive label-distribution-aware confidence thresholds to generate unbiased pseudo labels to drive student learning. For the latter one, there exists an overlooked label assignment ambiguity problem across teacher-student models. To remedy this issue, we present a novel label assignment mechanism for self-training framework, namely proposal self-assignment, which injects the proposals from student into teacher and generates accurate pseudo labels to match each proposal in the student model accordingly. Experiments on both MS-COCO and PASCAL-VOC datasets demonstrate the considerable superiority of our proposed framework to other state-of-the-arts. Code will be available at https://github.com/hikvision-research/SSOD.
* To appear in CVPR 2022. Code is coming soon: https://github.com/hikvision-research/SSOD
Learning Domain Adaptive Object Detection with Probabilistic Teacher
Jun 13, 2022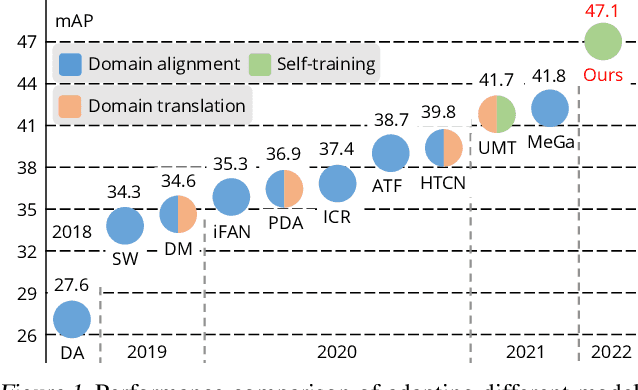
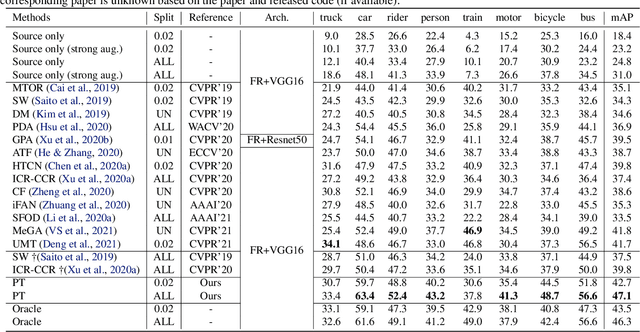
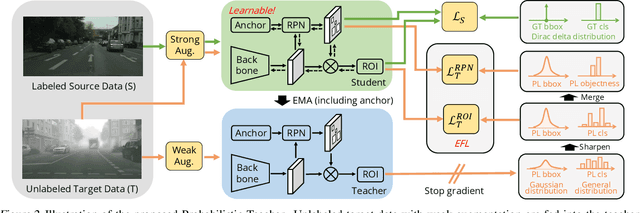
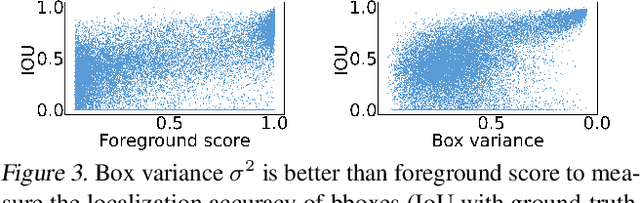
Self-training for unsupervised domain adaptive object detection is a challenging task, of which the performance depends heavily on the quality of pseudo boxes. Despite the promising results, prior works have largely overlooked the uncertainty of pseudo boxes during self-training. In this paper, we present a simple yet effective framework, termed as Probabilistic Teacher (PT), which aims to capture the uncertainty of unlabeled target data from a gradually evolving teacher and guides the learning of a student in a mutually beneficial manner. Specifically, we propose to leverage the uncertainty-guided consistency training to promote classification adaptation and localization adaptation, rather than filtering pseudo boxes via an elaborate confidence threshold. In addition, we conduct anchor adaptation in parallel with localization adaptation, since anchor can be regarded as a learnable parameter. Together with this framework, we also present a novel Entropy Focal Loss (EFL) to further facilitate the uncertainty-guided self-training. Equipped with EFL, PT outperforms all previous baselines by a large margin and achieve new state-of-the-arts.
* To appear in ICML 2022. Code is coming soon: https://github.com/hikvision-research/ProbabilisticTeacher
Transductive CLIP with Class-Conditional Contrastive Learning
Jun 13, 2022
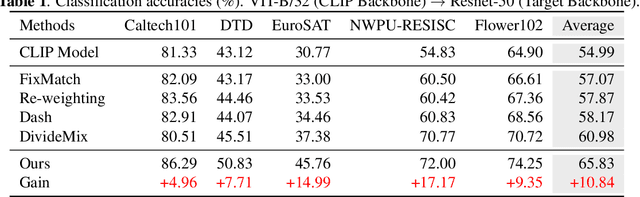
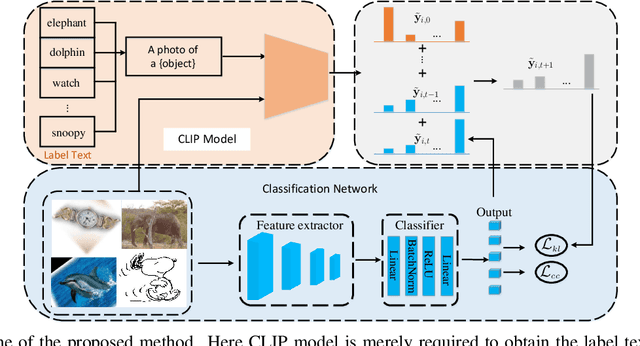
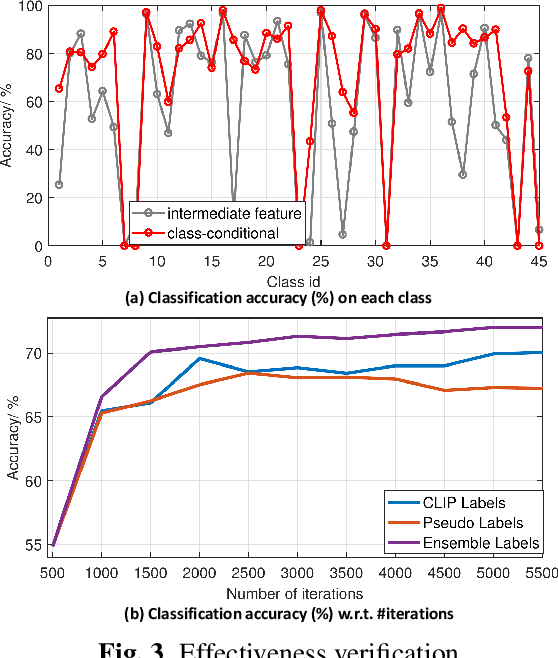
Inspired by the remarkable zero-shot generalization capacity of vision-language pre-trained model, we seek to leverage the supervision from CLIP model to alleviate the burden of data labeling. However, such supervision inevitably contains the label noise, which significantly degrades the discriminative power of the classification model. In this work, we propose Transductive CLIP, a novel framework for learning a classification network with noisy labels from scratch. Firstly, a class-conditional contrastive learning mechanism is proposed to mitigate the reliance on pseudo labels and boost the tolerance to noisy labels. Secondly, ensemble labels is adopted as a pseudo label updating strategy to stabilize the training of deep neural networks with noisy labels. This framework can reduce the impact of noisy labels from CLIP model effectively by combining both techniques. Experiments on multiple benchmark datasets demonstrate the substantial improvements over other state-of-the-art methods.
* Published in IEEE ICASSP 2022
2nd Place Solution for ICCV 2021 VIPriors Image Classification Challenge: An Attract-and-Repulse Learning Approach
Jun 13, 2022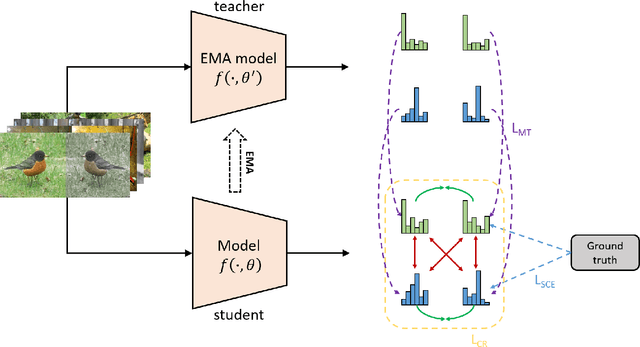

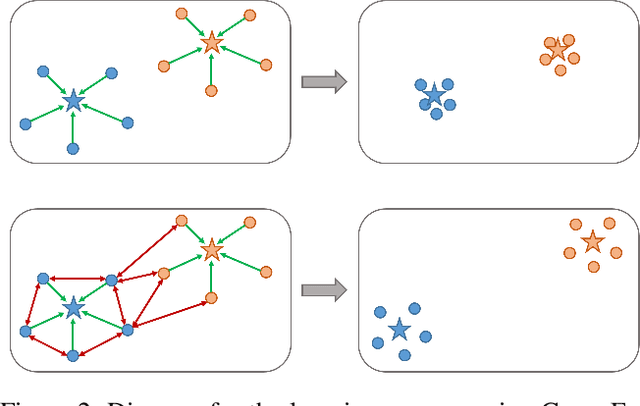

Convolutional neural networks (CNNs) have achieved significant success in image classification by utilizing large-scale datasets. However, it is still of great challenge to learn from scratch on small-scale datasets efficiently and effectively. With limited training datasets, the concepts of categories will be ambiguous since the over-parameterized CNNs tend to simply memorize the dataset, leading to poor generalization capacity. Therefore, it is crucial to study how to learn more discriminative representations while avoiding over-fitting. Since the concepts of categories tend to be ambiguous, it is important to catch more individual-wise information. Thus, we propose a new framework, termed Attract-and-Repulse, which consists of Contrastive Regularization (CR) to enrich the feature representations, Symmetric Cross Entropy (SCE) to balance the fitting for different classes and Mean Teacher to calibrate label information. Specifically, SCE and CR learn discriminative representations while alleviating over-fitting by the adaptive trade-off between the information of classes (attract) and instances (repulse). After that, Mean Teacher is used to further improve the performance via calibrating more accurate soft pseudo labels. Sufficient experiments validate the effectiveness of the Attract-and-Repulse framework. Together with other strategies, such as aggressive data augmentation, TenCrop inference, and models ensembling, we achieve the second place in ICCV 2021 VIPriors Image Classification Challenge.
KRNet: Towards Efficient Knowledge Replay
May 23, 2022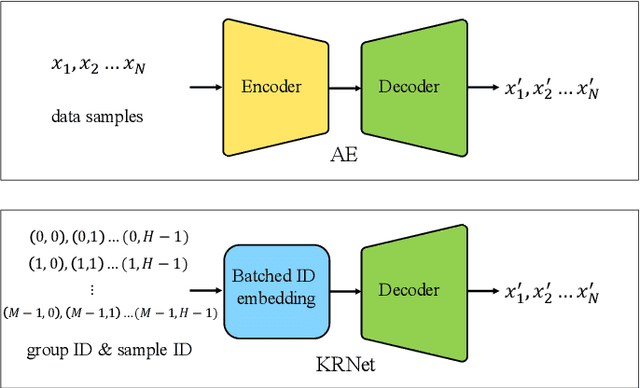
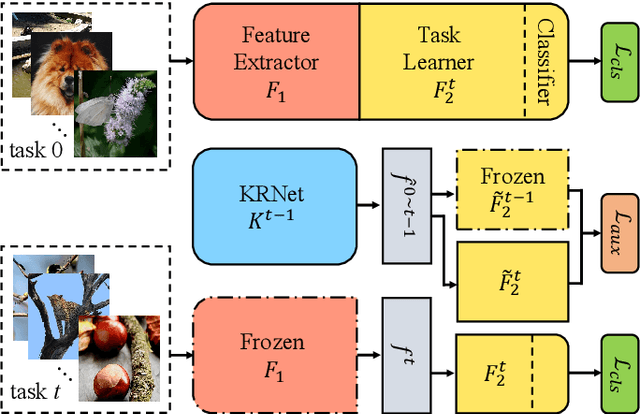
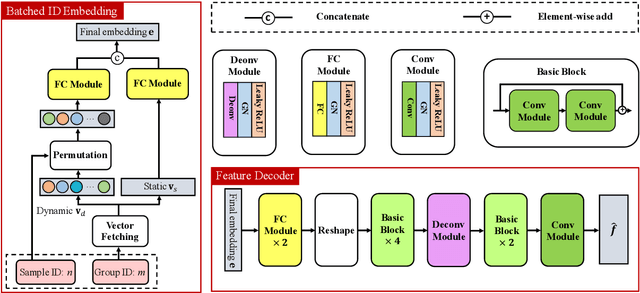
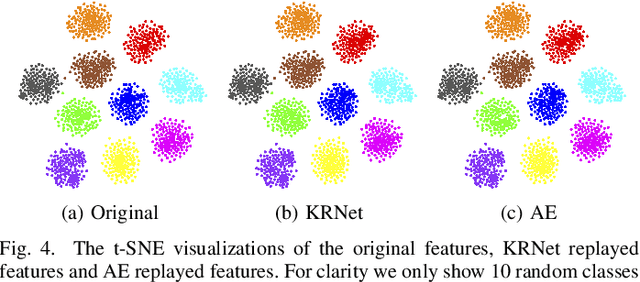
The knowledge replay technique has been widely used in many tasks such as continual learning and continuous domain adaptation. The key lies in how to effectively encode the knowledge extracted from previous data and replay them during current training procedure. A simple yet effective model to achieve knowledge replay is autoencoder. However, the number of stored latent codes in autoencoder increases linearly with the scale of data and the trained encoder is redundant for the replaying stage. In this paper, we propose a novel and efficient knowledge recording network (KRNet) which directly maps an arbitrary sample identity number to the corresponding datum. Compared with autoencoder, our KRNet requires significantly ($400\times$) less storage cost for the latent codes and can be trained without the encoder sub-network. Extensive experiments validate the efficiency of KRNet, and as a showcase, it is successfully applied in the task of continual learning.
Self-distilled Knowledge Delegator for Exemplar-free Class Incremental Learning
May 23, 2022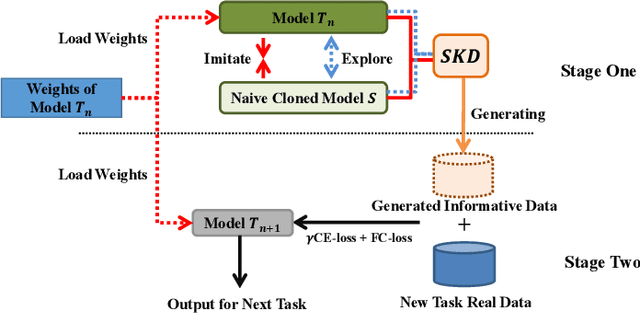
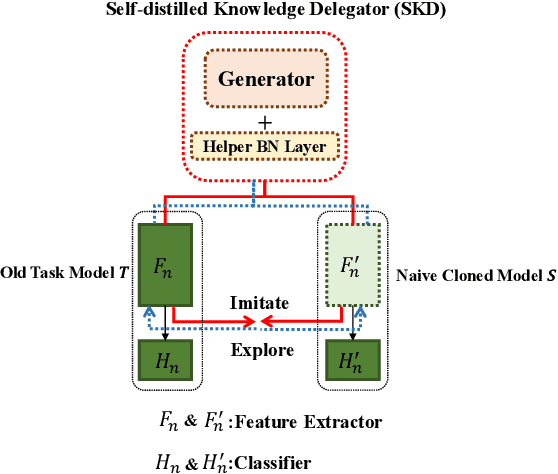
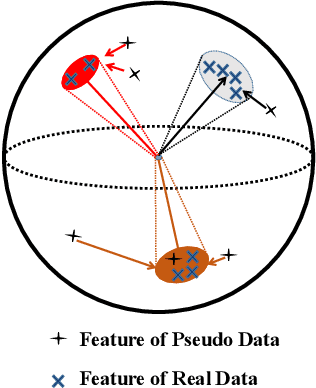
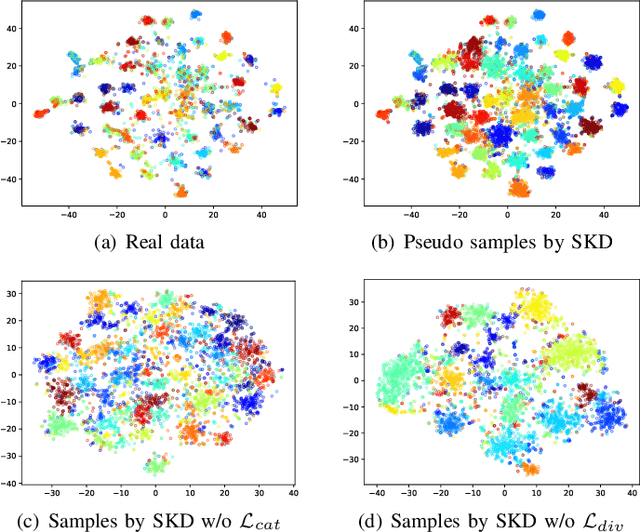
Exemplar-free incremental learning is extremely challenging due to inaccessibility of data from old tasks. In this paper, we attempt to exploit the knowledge encoded in a previously trained classification model to handle the catastrophic forgetting problem in continual learning. Specifically, we introduce a so-called knowledge delegator, which is capable of transferring knowledge from the trained model to a randomly re-initialized new model by generating informative samples. Given the previous model only, the delegator is effectively learned using a self-distillation mechanism in a data-free manner. The knowledge extracted by the delegator is then utilized to maintain the performance of the model on old tasks in incremental learning. This simple incremental learning framework surpasses existing exemplar-free methods by a large margin on four widely used class incremental benchmarks, namely CIFAR-100, ImageNet-Subset, Caltech-101 and Flowers-102. Notably, we achieve comparable performance to some exemplar-based methods without accessing any exemplars.
Topology-aware Convolutional Neural Network for Efficient Skeleton-based Action Recognition
Dec 09, 2021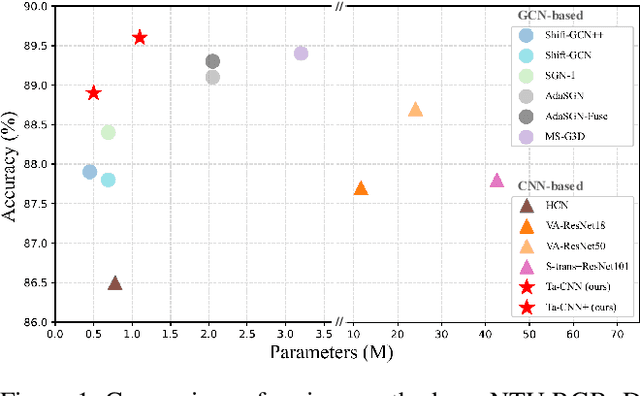
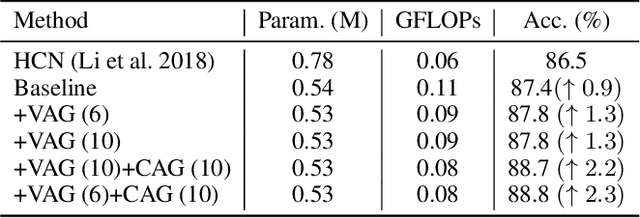
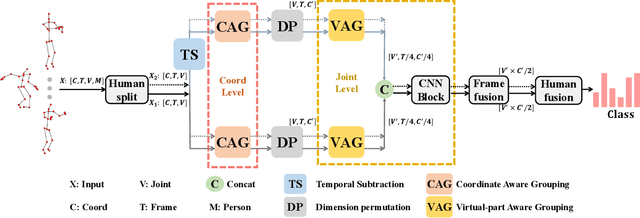
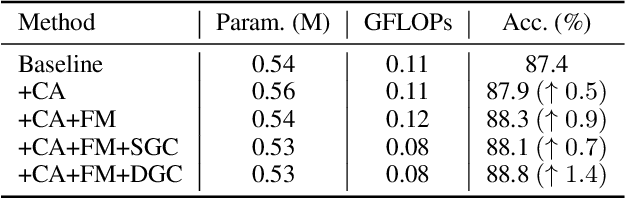
In the context of skeleton-based action recognition, graph convolutional networks (GCNs) have been rapidly developed, whereas convolutional neural networks (CNNs) have received less attention. One reason is that CNNs are considered poor in modeling the irregular skeleton topology. To alleviate this limitation, we propose a pure CNN architecture named Topology-aware CNN (Ta-CNN) in this paper. In particular, we develop a novel cross-channel feature augmentation module, which is a combo of map-attend-group-map operations. By applying the module to the coordinate level and the joint level subsequently, the topology feature is effectively enhanced. Notably, we theoretically prove that graph convolution is a special case of normal convolution when the joint dimension is treated as channels. This confirms that the topology modeling power of GCNs can also be implemented by using a CNN. Moreover, we creatively design a SkeletonMix strategy which mixes two persons in a unique manner and further boosts the performance. Extensive experiments are conducted on four widely used datasets, i.e. N-UCLA, SBU, NTU RGB+D and NTU RGB+D 120 to verify the effectiveness of Ta-CNN. We surpass existing CNN-based methods significantly. Compared with leading GCN-based methods, we achieve comparable performance with much less complexity in terms of the required GFLOPs and parameters.
Semi-Supervised Domain Generalization in Real World:New Benchmark and Strong Baseline
Nov 19, 2021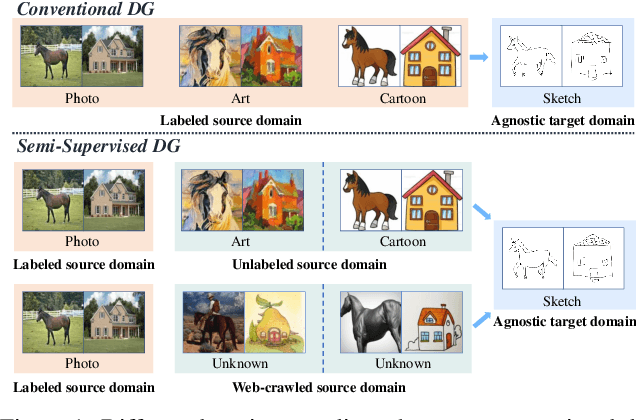
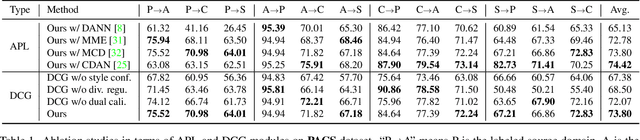
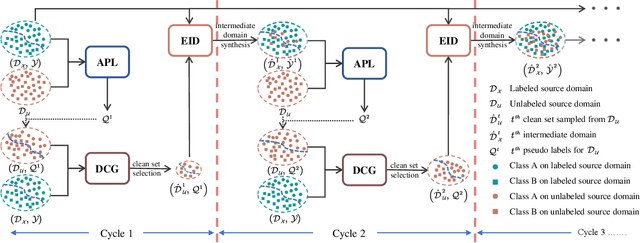
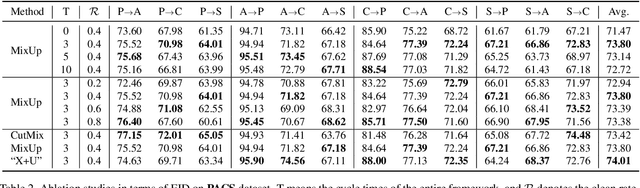
Conventional domain generalization aims to learn domain invariant representation from multiple domains, which requires accurate annotations. In realistic application scenarios, however, it is too cumbersome or even infeasible to collect and annotate the large mass of data. Yet, web data provides a free lunch to access a huge amount of unlabeled data with rich style information that can be harnessed to augment domain generalization ability. In this paper, we introduce a novel task, termed as semi-supervised domain generalization, to study how to interact the labeled and unlabeled domains, and establish two benchmarks including a web-crawled dataset, which poses a novel yet realistic challenge to push the limits of existing technologies. To tackle this task, a straightforward solution is to propagate the class information from the labeled to the unlabeled domains via pseudo labeling in conjunction with domain confusion training. Considering narrowing domain gap can improve the quality of pseudo labels and further advance domain invariant feature learning for generalization, we propose a cycle learning framework to encourage the positive feedback between label propagation and domain generalization, in favor of an evolving intermediate domain bridging the labeled and unlabeled domains in a curriculum learning manner. Experiments are conducted to validate the effectiveness of our framework. It is worth highlighting that web-crawled data benefits domain generalization as demonstrated in our results. Our code will be available later.
Hindsight Reward Tweaking via Conditional Deep Reinforcement Learning
Sep 06, 2021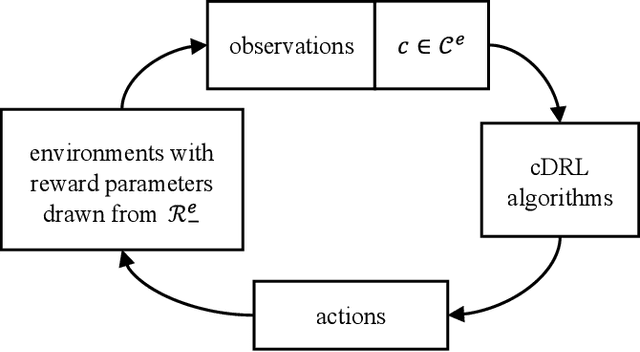
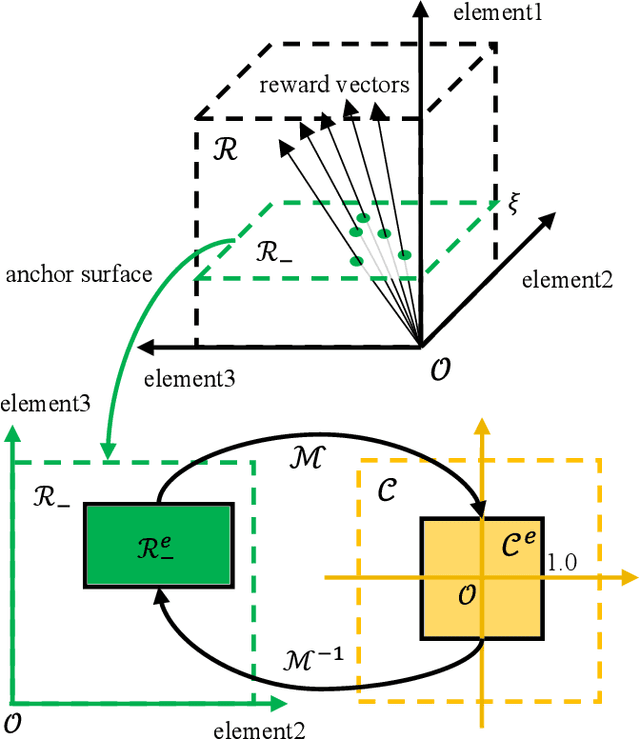
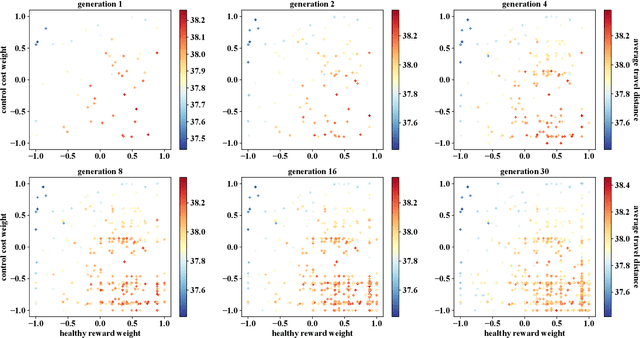
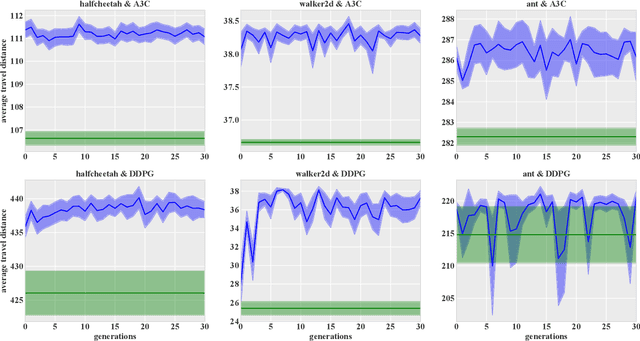
Designing optimal reward functions has been desired but extremely difficult in reinforcement learning (RL). When it comes to modern complex tasks, sophisticated reward functions are widely used to simplify policy learning yet even a tiny adjustment on them is expensive to evaluate due to the drastically increasing cost of training. To this end, we propose a hindsight reward tweaking approach by designing a novel paradigm for deep reinforcement learning to model the influences of reward functions within a near-optimal space. We simply extend the input observation with a condition vector linearly correlated with the effective environment reward parameters and train the model in a conventional manner except for randomizing reward configurations, obtaining a hyper-policy whose characteristics are sensitively regulated over the condition space. We demonstrate the feasibility of this approach and study one of its potential application in policy performance boosting with multiple MuJoCo tasks.