 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Expressive Power of GNNs via Graph Biconnectivity
Jan 23, 2023Designing expressive Graph Neural Networks (GNNs) is a central topic in learning graph-structured data. While numerous approaches have been proposed to improve GNNs in terms of the Weisfeiler-Lehman (WL) test, generally there is still a lack of deep understanding of what additional power they can systematically and provably gain. In this paper, we take a fundamentally different perspective to study the expressive power of GNNs beyond the WL test. Specifically, we introduce a novel class of expressivity metrics via graph biconnectivity and highlight their importance in both theory and practice. As biconnectivity can be easily calculated using simple algorithms that have linear computational costs, it is natural to expect that popular GNNs can learn it easily as well. However, after a thorough review of prior GNN architectures, we surprisingly find that most of them are not expressive for any of these metrics. The only exception is the ESAN framework (Bevilacqua et al., 2022), for which we give a theoretical justification of its power. We proceed to introduce a principled and more efficient approach, called the Generalized Distance Weisfeiler-Lehman (GD-WL), which is provably expressive for all biconnectivity metrics. Practically, we show GD-WL can be implemented by a Transformer-like architecture that preserves expressiveness and enjoys full parallelizability. A set of experiments on both synthetic and real datasets demonstrates that our approach can consistently outperform prior GNN architectures.
DSVT: Dynamic Sparse Voxel Transformer with Rotated Sets
Jan 15, 2023Designing an efficient yet deployment-friendly 3D backbone to handle sparse point clouds is a fundamental problem in 3D object detection. Compared with the customized sparse convolution, the attention mechanism in Transformers is more appropriate for flexibly modeling long-range relationships and is easier to be deployed in real-world applications. However, due to the sparse characteristics of point clouds, it is non-trivial to apply a standard transformer on sparse points. In this paper, we present Dynamic Sparse Voxel Transformer (DSVT), a single-stride window-based voxel Transformer backbone for outdoor 3D object detection. In order to efficiently process sparse points in parallel, we propose Dynamic Sparse Window Attention, which partitions a series of local regions in each window according to its sparsity and then computes the features of all regions in a fully parallel manner. To allow the cross-set connection, we design a rotated set partitioning strategy that alternates between two partitioning configurations in consecutive self-attention layers. To support effective downsampling and better encode geometric information, we also propose an attention-style 3D pooling module on sparse points, which is powerful and deployment-friendly without utilizing any customized CUDA operations. Our model achieves state-of-the-art performance on large-scale Waymo Open Dataset with remarkable gains. More importantly, DSVT can be easily deployed by TensorRT with real-time inference speed (27Hz). Code will be available at \url{https://github.com/Haiyang-W/DSVT}.
Matching entropy based disparity estimation from light field
Oct 28, 2022A major challenge for matching-based depth estimation is to prevent mismatches in occlusion and smooth regions. An effective matching window satisfying three characteristics: texture richness, disparity consistency and anti-occlusion should be able to prevent mismatches to some extent. According to these characteristics, we propose matching entropy in the spatial domain of light field to measure the amount of correct information in a matching window, which provides the criterion for matching window selection. Based on matching entropy regularization, we establish an optimization model for depth estimation with a matching cost fidelity term. To find the optimum, we propose a two-step adaptive matching algorithm. First, the region type is adaptively determined to identify occluding, occluded, smooth and textured regions. Then, the matching entropy criterion is used to adaptively select the size and shape of matching windows, as well as the visible viewpoints. The two-step process can reduce mismatches and redundant calculations by selecting effective matching windows. The experimental results on synthetic and real data show that the proposed method can effectively improve the accuracy of depth estimation in occlusion and smooth regions and has strong robustness for different noise levels. Therefore, high-precision depth estimation from 4D light field data is achieved.
Online Training Through Time for Spiking Neural Networks
Oct 09, 2022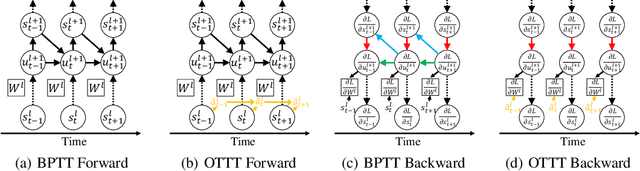
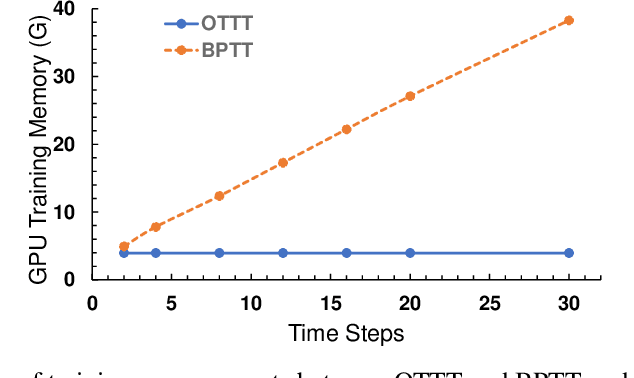
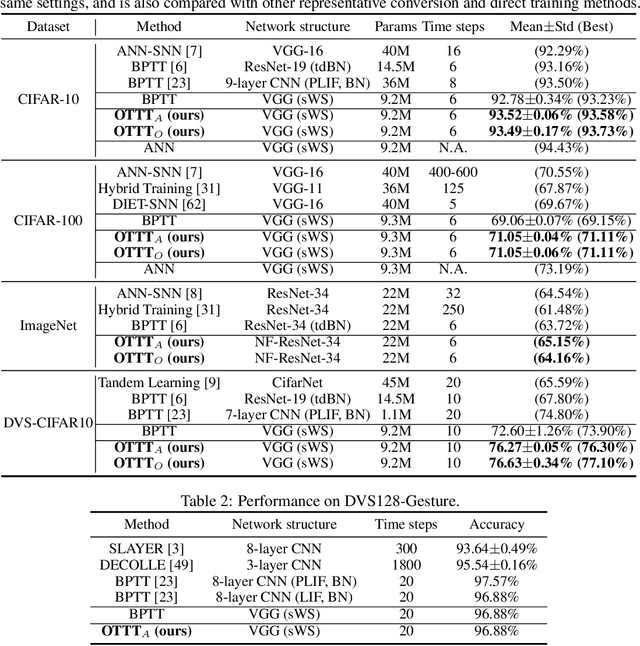
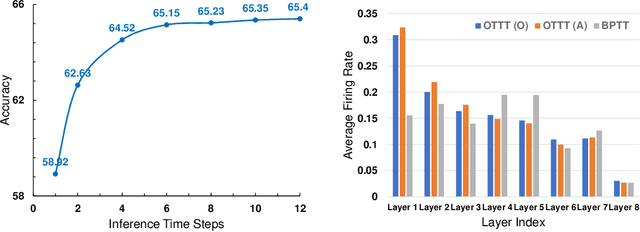
Spiking neural networks (SNNs) are promising brain-inspired energy-efficient models. Recent progress in training methods has enabled successful deep SNNs on large-scale tasks with low latency. Particularly, backpropagation through time (BPTT) with surrogate gradients (SG) is popularly used to achieve high performance in a very small number of time steps. However, it is at the cost of large memory consumption for training, lack of theoretical clarity for optimization, and inconsistency with the online property of biological learning and rules on neuromorphic hardware. Other works connect spike representations of SNNs with equivalent artificial neural network formulation and train SNNs by gradients from equivalent mappings to ensure descent directions. But they fail to achieve low latency and are also not online. In this work, we propose online training through time (OTTT) for SNNs, which is derived from BPTT to enable forward-in-time learning by tracking presynaptic activities and leveraging instantaneous loss and gradients. Meanwhile, we theoretically analyze and prove that gradients of OTTT can provide a similar descent direction for optimization as gradients based on spike representations under both feedforward and recurrent conditions. OTTT only requires constant training memory costs agnostic to time steps, avoiding the significant memory costs of BPTT for GPU training. Furthermore, the update rule of OTTT is in the form of three-factor Hebbian learning, which could pave a path for online on-chip learning. With OTTT, it is the first time that two mainstream supervised SNN training methods, BPTT with SG and spike representation-based training, are connected, and meanwhile in a biologically plausible form. Experiments on CIFAR-10, CIFAR-100, ImageNet, and CIFAR10-DVS demonstrate the superior performance of our method on large-scale static and neuromorphic datasets in small time steps.
One Transformer Can Understand Both 2D & 3D Molecular Data
Oct 04, 2022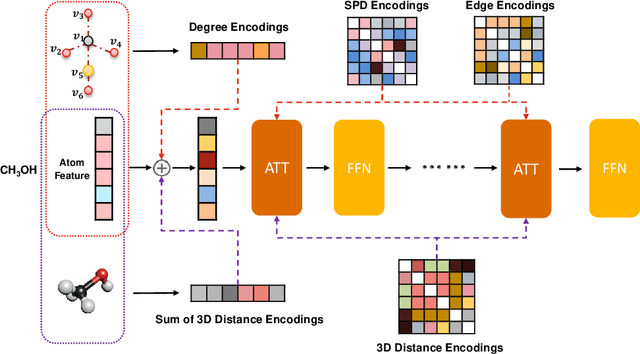
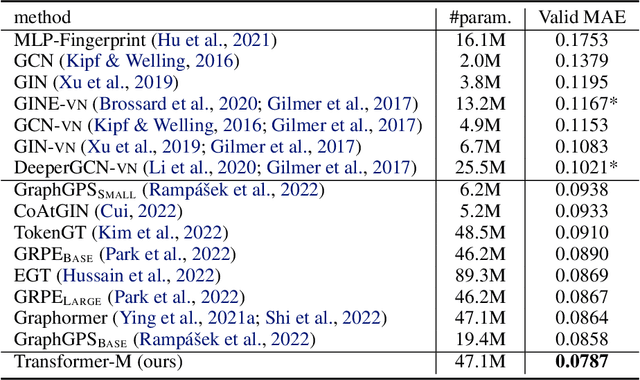
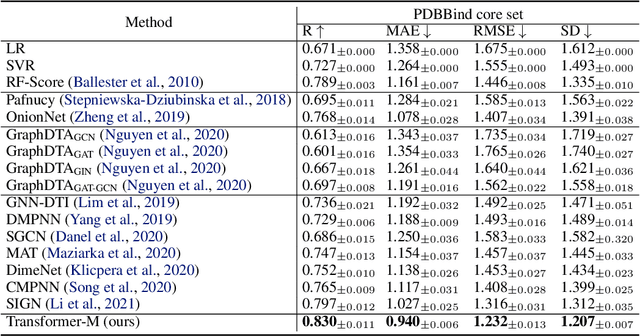
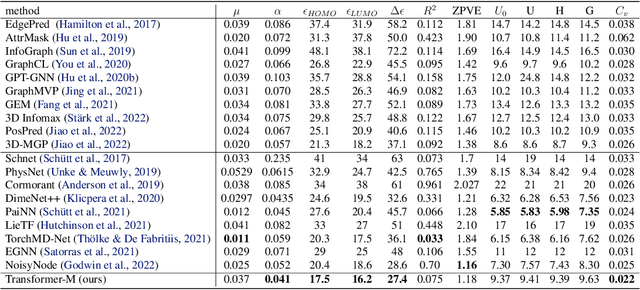
Unlike vision and language data which usually has a unique format, molecules can naturally be characterized using different chemical formulations. One can view a molecule as a 2D graph or define it as a collection of atoms located in a 3D space. For molecular representation learning, most previous works designed neural networks only for a particular data format, making the learned models likely to fail for other data formats. We believe a general-purpose neural network model for chemistry should be able to handle molecular tasks across data modalities. To achieve this goal, in this work, we develop a novel Transformer-based Molecular model called Transformer-M, which can take molecular data of 2D or 3D formats as input and generate meaningful semantic representations. Using the standard Transformer as the backbone architecture, Transformer-M develops two separated channels to encode 2D and 3D structural information and incorporate them with the atom features in the network modules. When the input data is in a particular format, the corresponding channel will be activated, and the other will be disabled. By training on 2D and 3D molecular data with properly designed supervised signals, Transformer-M automatically learns to leverage knowledge from different data modalities and correctly capture the representations. We conducted extensive experiments for Transformer-M. All empirical results show that Transformer-M can simultaneously achieve strong performance on 2D and 3D tasks, suggesting its broad applicability. The code and models will be made publicly available at https://github.com/lsj2408/Transformer-M.
Rethinking Lipschitz Neural Networks for Certified L-infinity Robustness
Oct 04, 2022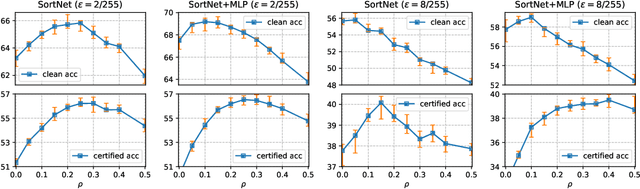
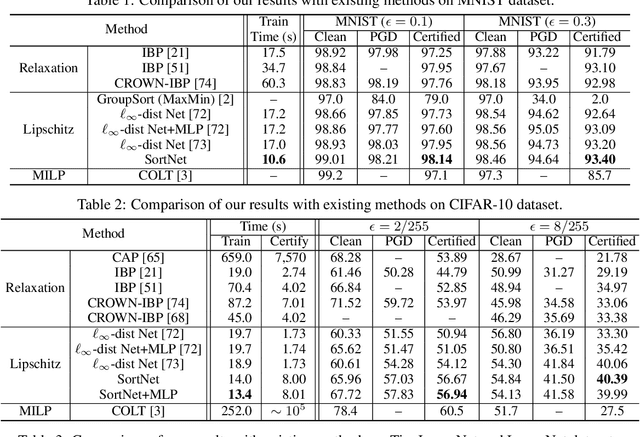
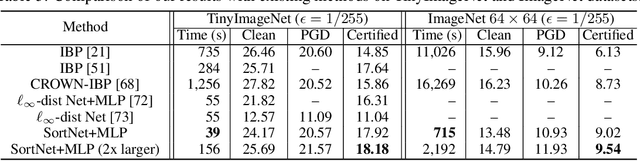
Designing neural networks with bounded Lipschitz constant is a promising way to obtain certifiably robust classifiers against adversarial examples. However, the relevant progress for the important $\ell_\infty$ perturbation setting is rather limited, and a principled understanding of how to design expressive $\ell_\infty$ Lipschitz networks is still lacking. In this paper, we bridge the gap by studying certified $\ell_\infty$ robustness from a novel perspective of representing Boolean functions. We derive two fundamental impossibility results that hold for any standard Lipschitz network: one for robust classification on finite datasets, and the other for Lipschitz function approximation. These results identify that networks built upon norm-bounded affine layers and Lipschitz activations intrinsically lose expressive power even in the two-dimensional case, and shed light on how recently proposed Lipschitz networks (e.g., GroupSort and $\ell_\infty$-distance nets) bypass these impossibilities by leveraging order statistic functions. Finally, based on these insights, we develop a unified Lipschitz network that generalizes prior works, and design a practical version that can be efficiently trained (making certified robust training free). Extensive experiments show that our approach is scalable, efficient, and consistently yields better certified robustness across multiple datasets and perturbation radii than prior Lipschitz networks.
Adversarial Noises Are Linearly Separable for (Nearly) Random Neural Networks
Jun 09, 2022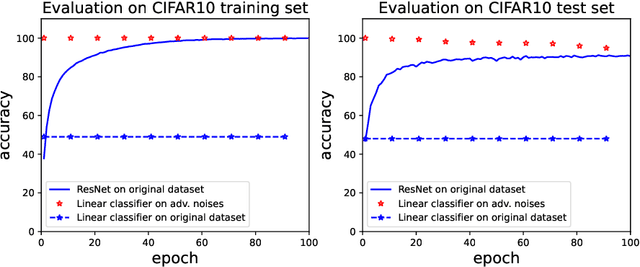
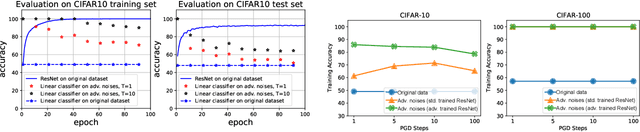
Adversarial examples, which are usually generated for specific inputs with a specific model, are ubiquitous for neural networks. In this paper we unveil a surprising property of adversarial noises when they are put together, i.e., adversarial noises crafted by one-step gradient methods are linearly separable if equipped with the corresponding labels. We theoretically prove this property for a two-layer network with randomly initialized entries and the neural tangent kernel setup where the parameters are not far from initialization. The proof idea is to show the label information can be efficiently backpropagated to the input while keeping the linear separability. Our theory and experimental evidence further show that the linear classifier trained with the adversarial noises of the training data can well classify the adversarial noises of the test data, indicating that adversarial noises actually inject a distributional perturbation to the original data distribution. Furthermore, we empirically demonstrate that the adversarial noises may become less linearly separable when the above conditions are compromised while they are still much easier to classify than original features.
Is $L^2$ Physics-Informed Loss Always Suitable for Training Physics-Informed Neural Network?
Jun 04, 2022
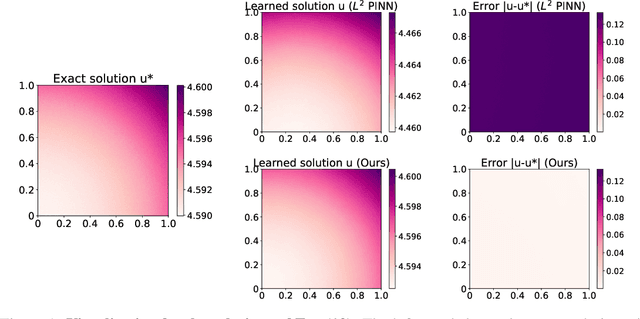
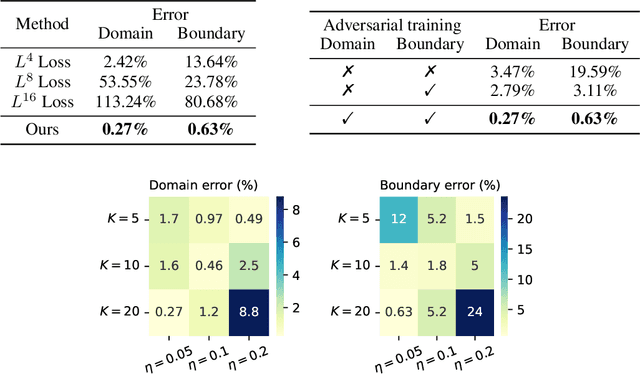
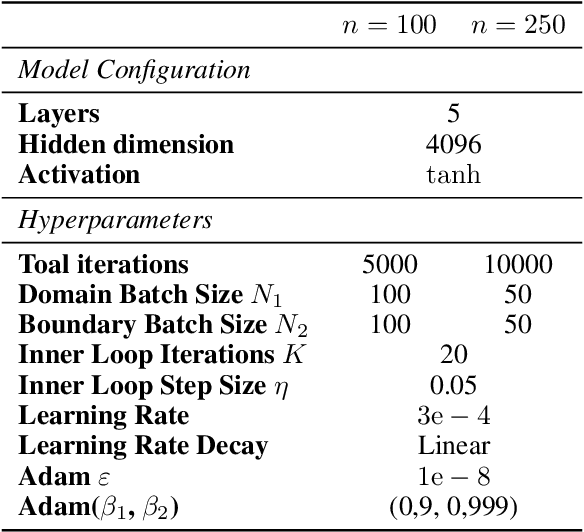
The Physics-Informed Neural Network (PINN) approach is a new and promising way to solve partial differential equations using deep learning. The $L^2$ Physics-Informed Loss is the de-facto standard in training Physics-Informed Neural Networks. In this paper, we challenge this common practice by investigating the relationship between the loss function and the approximation quality of the learned solution. In particular, we leverage the concept of stability in the literature of partial differential equation to study the asymptotic behavior of the learned solution as the loss approaches zero. With this concept, we study an important class of high-dimensional non-linear PDEs in optimal control, the Hamilton-Jacobi-Bellman(HJB) Equation, and prove that for general $L^p$ Physics-Informed Loss, a wide class of HJB equation is stable only if $p$ is sufficiently large. Therefore, the commonly used $L^2$ loss is not suitable for training PINN on those equations, while $L^{\infty}$ loss is a better choice. Based on the theoretical insight, we develop a novel PINN training algorithm to minimize the $L^{\infty}$ loss for HJB equations which is in a similar spirit to adversarial training. The effectiveness of the proposed algorithm is empirically demonstrated through experiments.
Your Transformer May Not be as Powerful as You Expect
May 26, 2022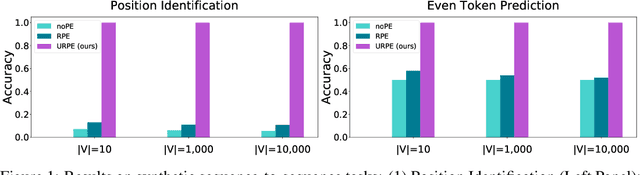
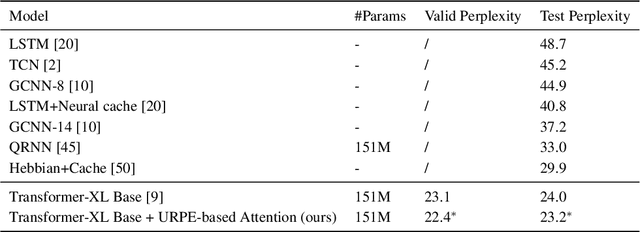
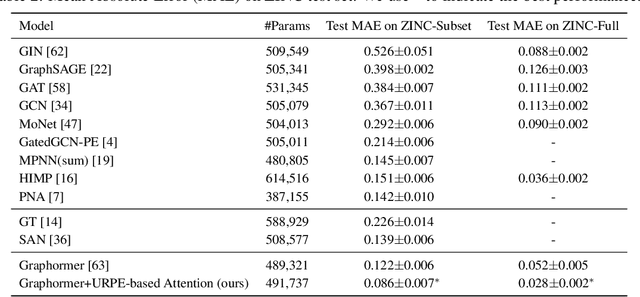
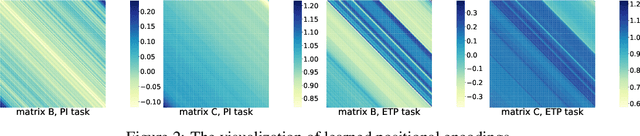
Relative Positional Encoding (RPE), which encodes the relative distance between any pair of tokens, is one of the most successful modifications to the original Transformer. As far as we know, theoretical understanding of the RPE-based Transformers is largely unexplored. In this work, we mathematically analyze the power of RPE-based Transformers regarding whether the model is capable of approximating any continuous sequence-to-sequence functions. One may naturally assume the answer is in the affirmative -- RPE-based Transformers are universal function approximators. However, we present a negative result by showing there exist continuous sequence-to-sequence functions that RPE-based Transformers cannot approximate no matter how deep and wide the neural network is. One key reason lies in that most RPEs are placed in the softmax attention that always generates a right stochastic matrix. This restricts the network from capturing positional information in the RPEs and limits its capacity. To overcome the problem and make the model more powerful, we first present sufficient conditions for RPE-based Transformers to achieve universal function approximation. With the theoretical guidance, we develop a novel attention module, called Universal RPE-based (URPE) Attention, which satisfies the conditions. Therefore, the corresponding URPE-based Transformers become universal function approximators. Extensive experiments covering typical architectures and tasks demonstrate that our model is parameter-efficient and can achieve superior performance to strong baselines in a wide range of applications.
METRO: Efficient Denoising Pretraining of Large Scale Autoencoding Language Models with Model Generated Signals
Apr 16, 2022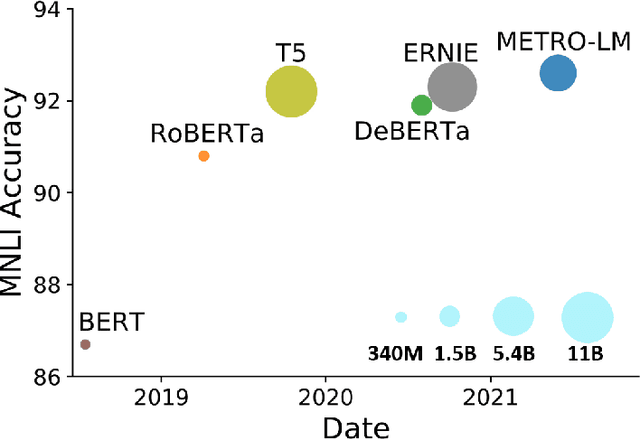
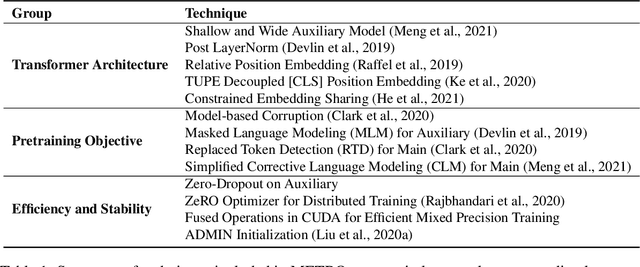
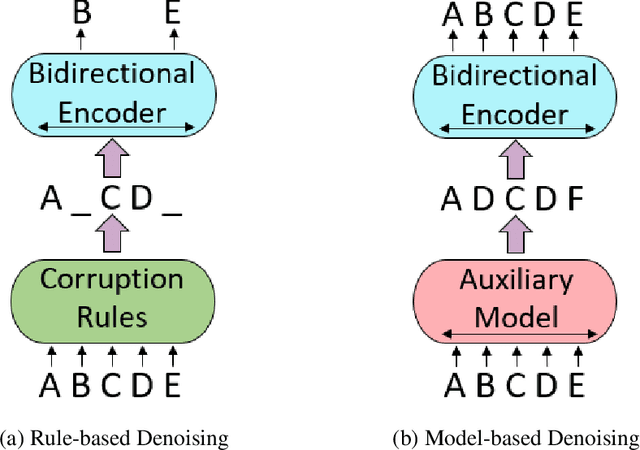
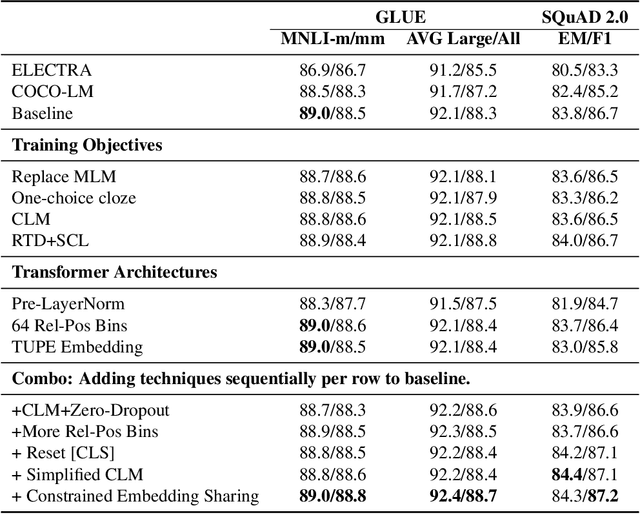
We present an efficient method of pretraining large-scale autoencoding language models using training signals generated by an auxiliary model. Originated in ELECTRA, this training strategy has demonstrated sample-efficiency to pretrain models at the scale of hundreds of millions of parameters. In this work, we conduct a comprehensive empirical study, and propose a recipe, namely "Model generated dEnoising TRaining Objective" (METRO), which incorporates some of the best modeling techniques developed recently to speed up, stabilize, and enhance pretrained language models without compromising model effectiveness. The resultant models, METRO-LM, consisting of up to 5.4 billion parameters, achieve new state-of-the-art on the GLUE, SuperGLUE, and SQuAD benchmarks. More importantly, METRO-LM are efficient in that they often outperform previous large models with significantly smaller model sizes and lower pretraining cost.