 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBP: Discrimination Based Block-Level Pruning for Deep Model Acceleration
Dec 21, 2019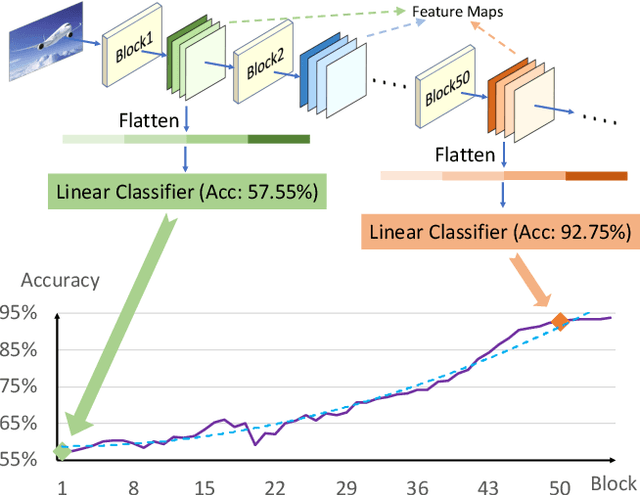
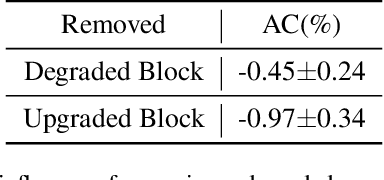
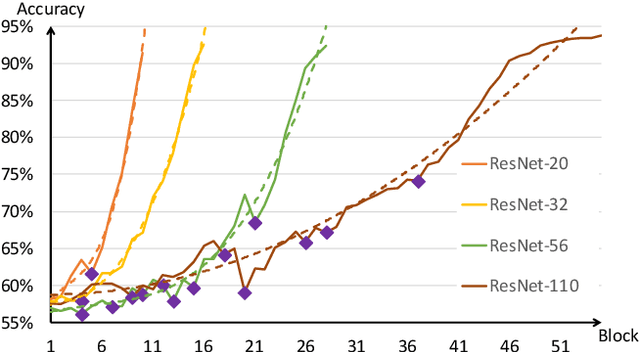
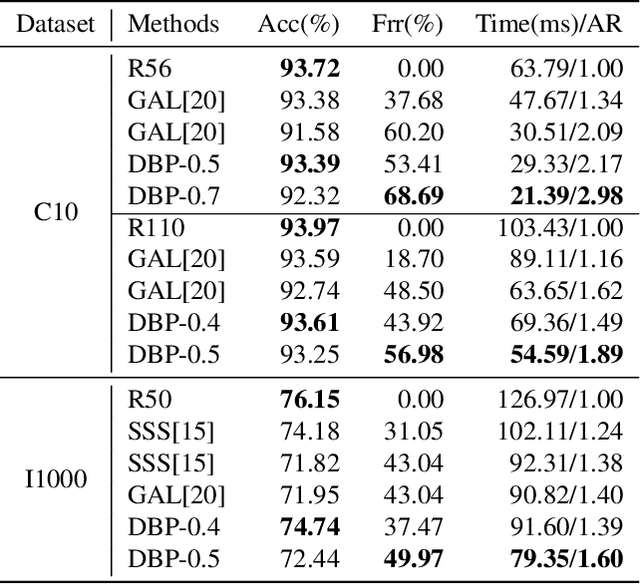
Neural network pruning is one of the most popular methods of accelerating the inference of deep convolutional neural networks (CNNs). The dominant pruning methods, filter-level pruning methods, evaluate their performance through the reduction ratio of computations and deem that a higher reduction ratio of computations is equivalent to a higher acceleration ratio in terms of inference time. However, we argue that they are not equivalent if parallel computing is considered. Given that filter-level pruning only prunes filters in layers and computations in a layer usually run in parallel, most computations reduced by filter-level pruning usually run in parallel with the un-reduced ones. Thus, the acceleration ratio of filter-level pruning is limited. To get a higher acceleration ratio, it is better to prune redundant layers because computations of different layers cannot run in parallel. In this paper, we propose our Discrimination based Block-level Pruning method (DBP). Specifically, DBP takes a sequence of consecutive layers (e.g., Conv-BN-ReLu) as a block and removes redundant blocks according to the discrimination of their output features. As a result, DBP achieves a considerable acceleration ratio by reducing the depth of CNNs. Extensive experiments show that DBP has surpassed state-of-the-art filter-level pruning methods in both accuracy and acceleration ratio. Our code will be made available soon.
PI-RCNN: An Efficient Multi-sensor 3D Object Detector with Point-based Attentive Cont-conv Fusion Module
Dec 02, 2019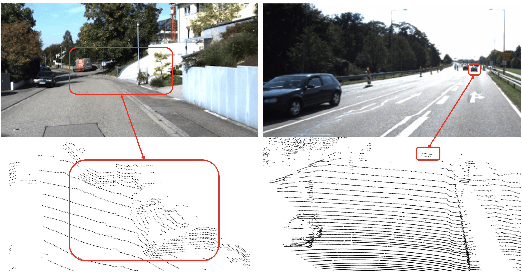
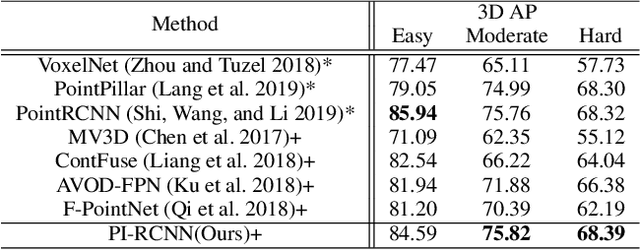
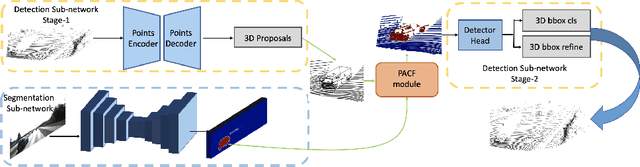
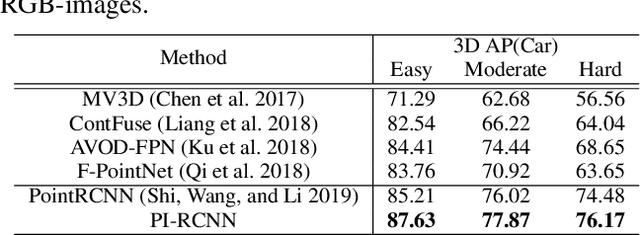
LIDAR point clouds and RGB-images are both extremely essential for 3D object detection. So many state-of-the-art 3D detection algorithms dedicate in fusing these two types of data effectively. However, their fusion methods based on Birds Eye View (BEV) or voxel format are not accurate. In this paper, we propose a novel fusion approach named Point-based Attentive Cont-conv Fusion(PACF) module, which fuses multi-sensor features directly on 3D points. Except for continuous convolution, we additionally add a Point-Pooling and an Attentive Aggregation to make the fused features more expressive. Moreover, based on the PACF module, we propose a 3D multi-sensor multi-task network called Pointcloud-Image RCNN(PI-RCNN as brief), which handles the image segmentation and 3D object detection tasks. PI-RCNN employs a segmentation sub-network to extract full-resolution semantic feature maps from images and then fuses the multi-sensor features via powerful PACF module. Beneficial from the effectiveness of the PACF module and the expressive semantic features from the segmentation module, PI-RCNN can improve much in 3D object detection. We demonstrate the effectiveness of the PACF module and PI-RCNN on the KITTI 3D Detection benchmark, and our method can achieve state-of-the-art on the metric of 3D AP.
Graph Transformer for Graph-to-Sequence Learning
Nov 30, 2019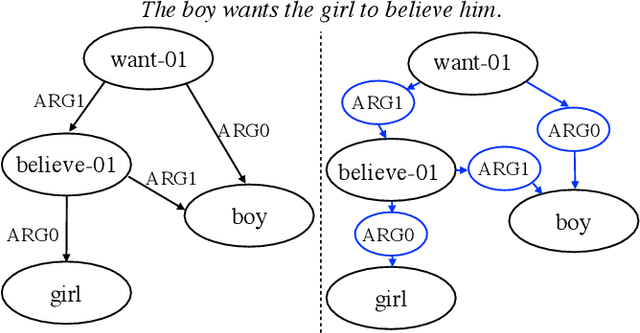

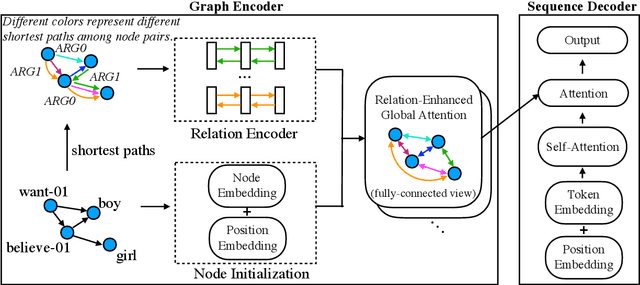
The dominant graph-to-sequence transduction models employ graph neural networks for graph representation learning, where the structural information is reflected by the receptive field of neurons. Unlike graph neural networks that restrict the information exchange between immediate neighborhood, we propose a new model, known as Graph Transformer, that uses explicit relation encoding and allows direct communication between two distant nodes. It provides a more efficient way for global graph structure modeling. Experiments on the applications of text generation from Abstract Meaning Representation (AMR) and syntax-based neural machine translation show the superiority of our proposed model. Specifically, our model achieves 27.4 BLEU on LDC2015E86 and 29.7 BLEU on LDC2017T10 for AMR-to-text generation, outperforming the state-of-the-art results by up to 2.2 points. On the syntax-based translation tasks, our model establishes new single-model state-of-the-art BLEU scores, 21.3 for English-to-German and 14.1 for English-to-Czech, improving over the existing best results, including ensembles, by over 1 BLEU.
Region Mutual Information Loss for Semantic Segmentation
Oct 26, 2019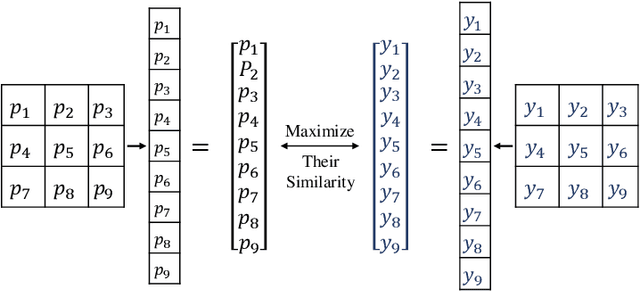

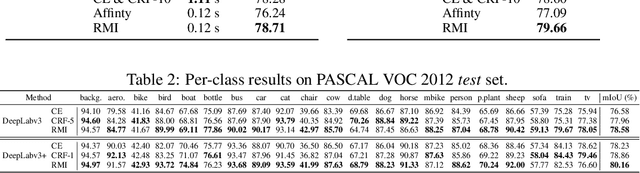

Semantic segmentation is a fundamental problem in computer vision. It is considered as a pixel-wise classification problem in practice, and most segmentation models use a pixel-wise loss as their optimization riterion. However, the pixel-wise loss ignores the dependencies between pixels in an image. Several ways to exploit the relationship between pixels have been investigated, \eg, conditional random fields (CRF) and pixel affinity based methods. Nevertheless, these methods usually require additional model branches, large extra memories, or more inference time. In this paper, we develop a region mutual information (RMI) loss to model the dependencies among pixels more simply and efficiently. In contrast to the pixel-wise loss which treats the pixels as independent samples, RMI uses one pixel and its neighbour pixels to represent this pixel. Then for each pixel in an image, we get a multi-dimensional point that encodes the relationship between pixels, and the image is cast into a multi-dimensional distribution of these high-dimensional points. The prediction and ground truth thus can achieve high order consistency through maximizing the mutual information (MI) between their multi-dimensional distributions. Moreover, as the actual value of the MI is hard to calculate, we derive a lower bound of the MI and maximize the lower bound to maximize the real value of the MI. RMI only requires a few extra computational resources in the training stage, and there is no overhead during testing. Experimental results demonstrate that RMI can achieve substantial and consistent improvements in performance on PASCAL VOC 2012 and CamVid datasets. The code is available at https://github.com/ZJULearning/RMI.
Correlation Maximized Structural Similarity Loss for Semantic Segmentation
Oct 19, 2019

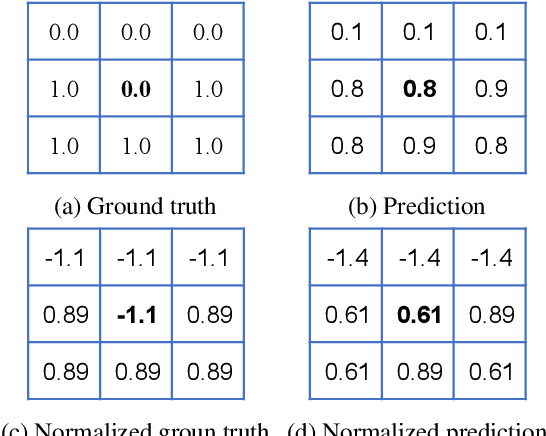
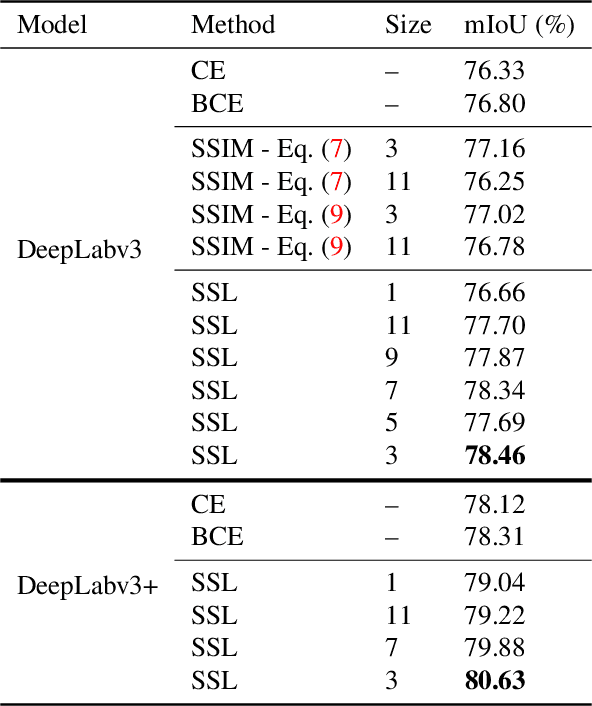
Most semantic segmentation models treat semantic segmentation as a pixel-wise classification task and use a pixel-wise classification error as their optimization criterions. However, the pixel-wise error ignores the strong dependencies among the pixels in an image, which limits the performance of the model. Several ways to incorporate the structure information of the objects have been investigated, \eg, conditional random fields (CRF), image structure priors based methods, and generative adversarial network (GAN). Nevertheless, these methods usually require extra model branches or additional memories, and some of them show limited improvements. In contrast, we propose a simple yet effective structural similarity loss (SSL) to encode the structure information of the objects, which only requires a few additional computational resources in the training phase. Inspired by the widely-used structural similarity (SSIM) index in image quality assessment, we use the linear correlation between two images to quantify their structural similarity. And the goal of the proposed SSL is to pay more attention to the positions, whose associated predictions lead to a low degree of linear correlation between two corresponding regions in the ground truth map and the predicted map. Thus the model can achieve a strong structural similarity between the two maps through minimizing the SSL over the whole map. The experimental results demonstrate that our method can achieve substantial and consistent improvements in performance on the PASCAL VOC 2012 and Cityscapes datasets. The code will be released soon.
Domain Adaptation for Semantic Segmentation with Maximum Squares Loss
Sep 30, 2019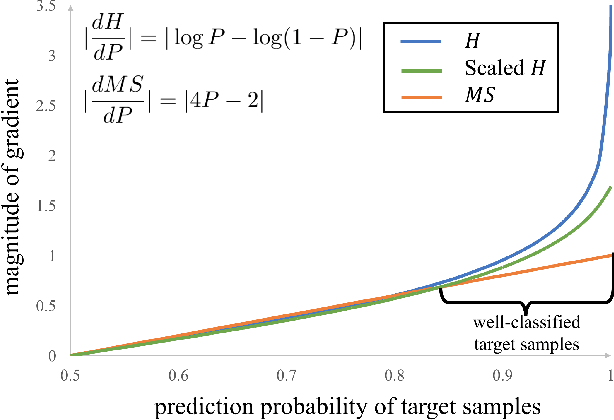

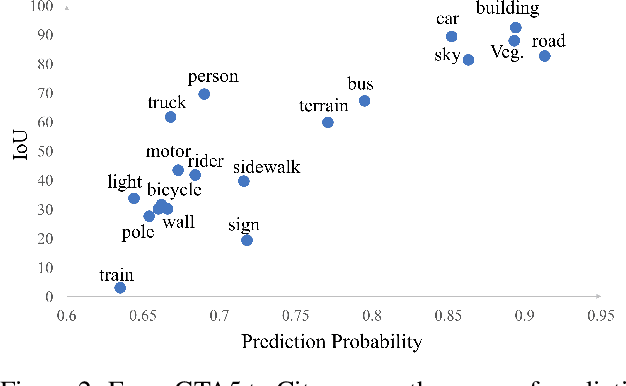
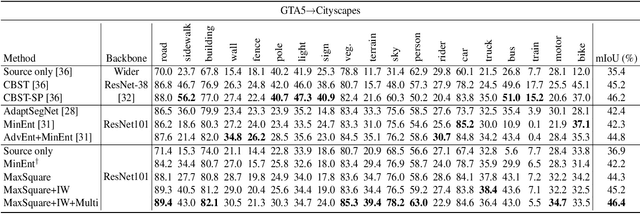
Deep neural networks for semantic segmentation always require a large number of samples with pixel-level labels, which becomes the major difficulty in their real-world applications. To reduce the labeling cost, unsupervised domain adaptation (UDA) approaches are proposed to transfer knowledge from labeled synthesized datasets to unlabeled real-world datasets. Recently, some semi-supervised learning methods have been applied to UDA and achieved state-of-the-art performance. One of the most popular approaches in semi-supervised learning is the entropy minimization method. However, when applying the entropy minimization to UDA for semantic segmentation, the gradient of the entropy is biased towards samples that are easy to transfer. To balance the gradient of well-classified target samples, we propose the maximum squares loss. Our maximum squares loss prevents the training process being dominated by easy-to-transfer samples in the target domain. Besides, we introduce the image-wise weighting ratio to alleviate the class imbalance in the unlabeled target domain. Both synthetic-to-real and cross-city adaptation experiments demonstrate the effectiveness of our proposed approach. The code is released at https://github. com/ZJULearning/MaxSquareLoss.
Core Semantic First: A Top-down Approach for AMR Parsing
Sep 12, 2019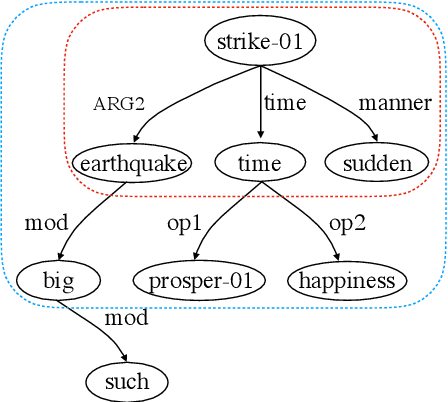
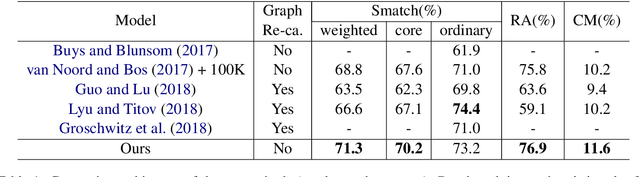
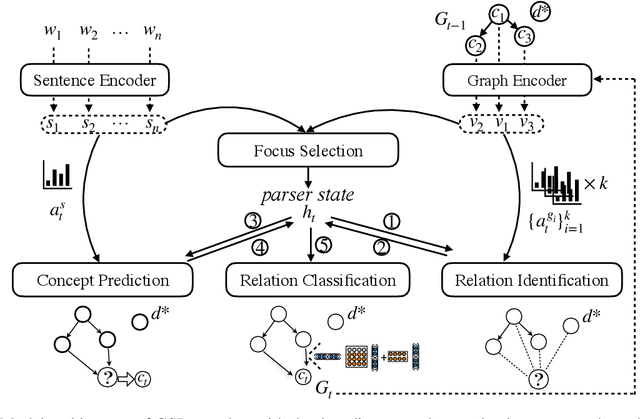
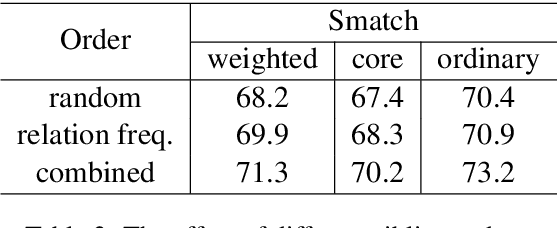
We introduce a novel scheme for parsing a piece of text into its Abstract Meaning Representation (AMR): Graph Spanning based Parsing (GSP). One novel characteristic of GSP is that it constructs a parse graph incrementally in a top-down fashion. Starting from the root, at each step, a new node and its connections to existing nodes will be jointly predicted. The output graph spans the nodes by the distance to the root, following the intuition of first grasping the main ideas then digging into more details. The \textit{core semantic first} principle emphasizes capturing the main ideas of a sentence, which is of great interest. We evaluate our model on the latest AMR sembank and achieve the state-of-the-art performance in the sense that no heuristic graph re-categorization is adopted. More importantly, the experiments show that our parser is especially good at obtaining the core semantics.
A Better Way to Attend: Attention with Trees for Video Question Answering
Sep 05, 2019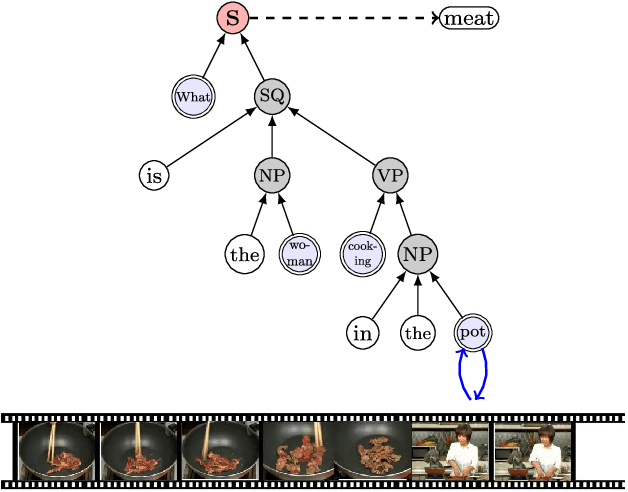


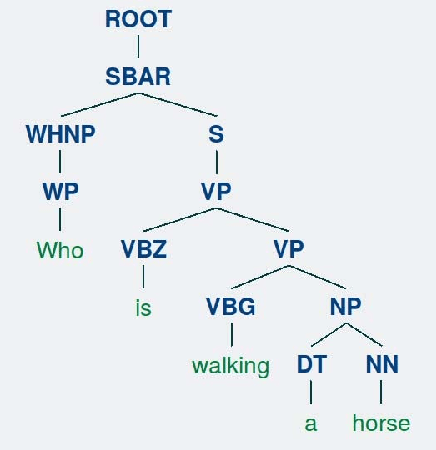
We propose a new attention model for video question answering. The main idea of the attention models is to locate on the most informative parts of the visual data. The attention mechanisms are quite popular these days. However, most existing visual attention mechanisms regard the question as a whole. They ignore the word-level semantics where each word can have different attentions and some words need no attention. Neither do they consider the semantic structure of the sentences. Although the Extended Soft Attention (E-SA) model for video question answering leverages the word-level attention, it performs poorly on long question sentences. In this paper, we propose the heterogeneous tree-structured memory network (HTreeMN) for video question answering. Our proposed approach is based upon the syntax parse trees of the question sentences. The HTreeMN treats the words differently where the \textit{visual} words are processed with an attention module and the \textit{verbal} ones not. It also utilizes the semantic structure of the sentences by combining the neighbors based on the recursive structure of the parse trees. The understandings of the words and the videos are propagated and merged from leaves to the root. Furthermore, we build a hierarchical attention mechanism to distill the attended features. We evaluate our approach on two datasets. The experimental results show the superiority of our HTreeMN model over the other attention models especially on complex questions. Our code is available on github. Our code is available at https://github.com/ZJULearning/TreeAttention
* 12 pages
Training-Time-Friendly Network for Real-Time Object Detection
Sep 02, 2019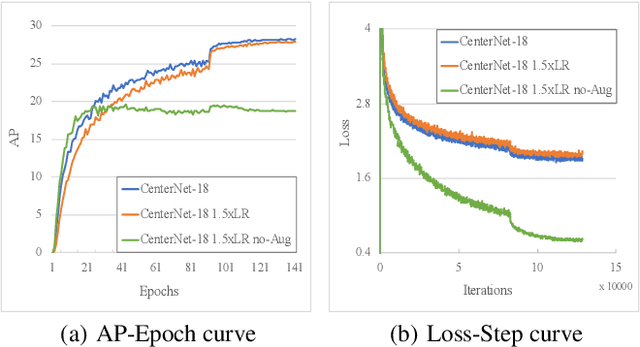
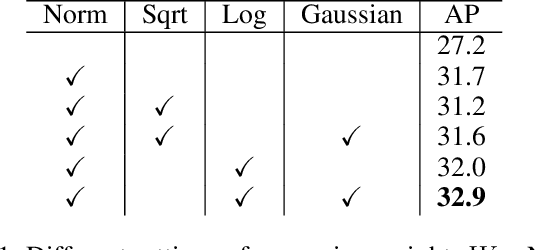
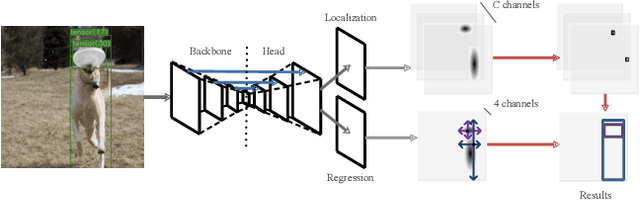
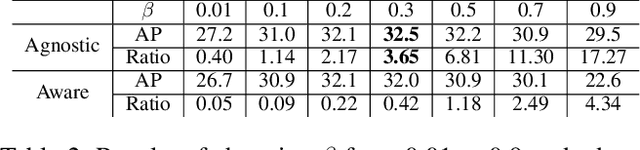
Modern object detectors can rarely achieve short training time, fast inference speed, and high accuracy at the same time. To strike a balance between them, we propose the Training-Time-Friendly Network (TTFNet). In this work, we start with light-head, single-stage, and anchor-free designs, enabling fast inference speed. Then, we focus on shortening training time. We notice that producing more high-quality samples plays a similar role as increasing batch size, which helps enlarge the learning rate and accelerate the training process. To this end, we introduce a novel method using Gaussian kernels to produce training samples. Moreover, we design the initiative sample weights for better information utilization. Experiments on MS COCO show that our TTFNet has great advantages in balancing training time, inference speed, and accuracy. It has reduced training time by more than seven times compared to previous real-time detectors while maintaining state-of-the-art performances. In addition, our super-fast version of TTFNet-18 and TTFNet-53 can outperform SSD300 and YOLOv3 by less than one-tenth of their training time, respectively. Code has been made available at \url{https://github.com/ZJULearning/ttfnet}.
Charge-Based Prison Term Prediction with Deep Gating Network
Aug 30, 2019
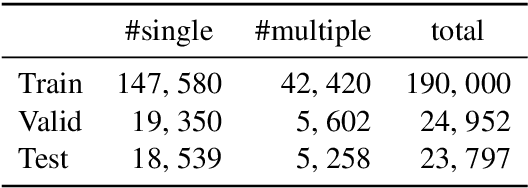
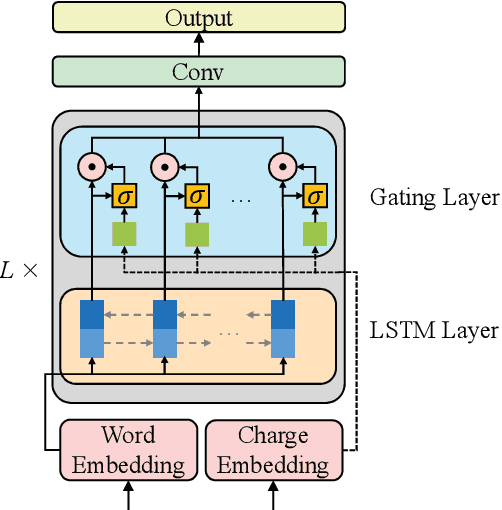
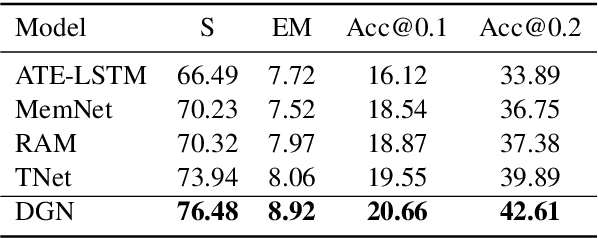
Judgment prediction for legal cases has attracted much research efforts for its practice use, of which the ultimate goal is prison term prediction. While existing work merely predicts the total prison term, in reality a defendant is often charged with multiple crimes. In this paper, we argue that charge-based prison term prediction (CPTP) not only better fits realistic needs, but also makes the total prison term prediction more accurate and interpretable. We collect the first large-scale structured data for CPTP and evaluate several competitive baselines. Based on the observation that fine-grained feature selection is the key to achieving good performance, we propose the Deep Gating Network (DGN) for charge-specific feature selection and aggregation. Experiments show that DGN achieves the state-of-the-art performance.