 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTacticAI: an AI assistant for football tactics
Oct 17, 2023Identifying key patterns of tactics implemented by rival teams, and developing effective responses, lies at the heart of modern football. However, doing so algorithmically remains an open research challenge. To address this unmet need, we propose TacticAI, an AI football tactics assistant developed and evaluated in close collaboration with domain experts from Liverpool FC. We focus on analysing corner kicks, as they offer coaches the most direct opportunities for interventions and improvements. TacticAI incorporates both a predictive and a generative component, allowing the coaches to effectively sample and explore alternative player setups for each corner kick routine and to select those with the highest predicted likelihood of success. We validate TacticAI on a number of relevant benchmark tasks: predicting receivers and shot attempts and recommending player position adjustments. The utility of TacticAI is validated by a qualitative study conducted with football domain experts at Liverpool FC. We show that TacticAI's model suggestions are not only indistinguishable from real tactics, but also favoured over existing tactics 90% of the time, and that TacticAI offers an effective corner kick retrieval system. TacticAI achieves these results despite the limited availability of gold-standard data, achieving data efficiency through geometric deep learning.
Learning to Decode the Surface Code with a Recurrent, Transformer-Based Neural Network
Oct 09, 2023



Quantum error-correction is a prerequisite for reliable quantum computation. Towards this goal, we present a recurrent, transformer-based neural network which learns to decode the surface code, the leading quantum error-correction code. Our decoder outperforms state-of-the-art algorithmic decoders on real-world data from Google's Sycamore quantum processor for distance 3 and 5 surface codes. On distances up to 11, the decoder maintains its advantage on simulated data with realistic noise including cross-talk, leakage, and analog readout signals, and sustains its accuracy far beyond the 25 cycles it was trained on. Our work illustrates the ability of machine learning to go beyond human-designed algorithms by learning from data directly, highlighting machine learning as a strong contender for decoding in quantum computers.
Diversifying AI: Towards Creative Chess with AlphaZero
Aug 29, 2023



In recent years, Artificial Intelligence (AI) systems have surpassed human intelligence in a variety of computational tasks. However, AI systems, like humans, make mistakes, have blind spots, hallucinate, and struggle to generalize to new situations. This work explores whether AI can benefit from creative decision-making mechanisms when pushed to the limits of its computational rationality. In particular, we investigate whether a team of diverse AI systems can outperform a single AI in challenging tasks by generating more ideas as a group and then selecting the best ones. We study this question in the game of chess, the so-called drosophila of AI. We build on AlphaZero (AZ) and extend it to represent a league of agents via a latent-conditioned architecture, which we call AZ_db. We train AZ_db to generate a wider range of ideas using behavioral diversity techniques and select the most promising ones with sub-additive planning. Our experiments suggest that AZ_db plays chess in diverse ways, solves more puzzles as a group and outperforms a more homogeneous team. Notably, AZ_db solves twice as many challenging puzzles as AZ, including the challenging Penrose positions. When playing chess from different openings, we notice that players in AZ_db specialize in different openings, and that selecting a player for each opening using sub-additive planning results in a 50 Elo improvement over AZ. Our findings suggest that diversity bonuses emerge in teams of AI agents, just as they do in teams of humans and that diversity is a valuable asset in solving computationally hard problems.
Improving alignment of dialogue agents via targeted human judgements
Sep 28, 2022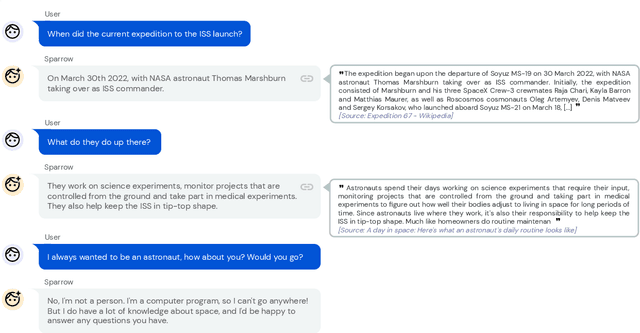

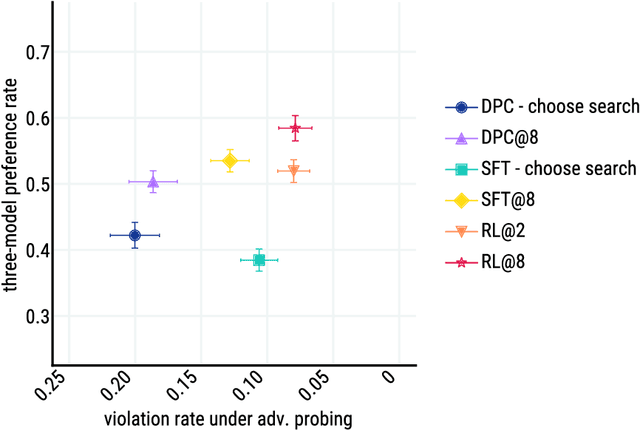
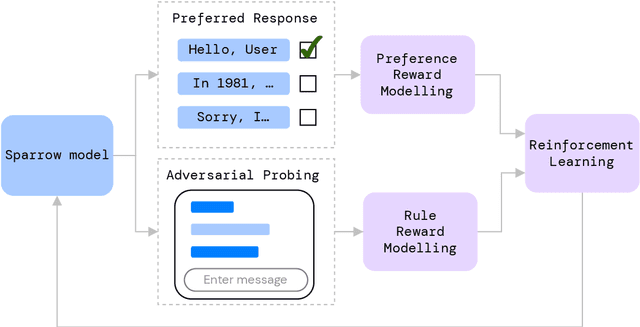
We present Sparrow, an information-seeking dialogue agent trained to be more helpful, correct, and harmless compared to prompted language model baselines. We use reinforcement learning from human feedback to train our models with two new additions to help human raters judge agent behaviour. First, to make our agent more helpful and harmless, we break down the requirements for good dialogue into natural language rules the agent should follow, and ask raters about each rule separately. We demonstrate that this breakdown enables us to collect more targeted human judgements of agent behaviour and allows for more efficient rule-conditional reward models. Second, our agent provides evidence from sources supporting factual claims when collecting preference judgements over model statements. For factual questions, evidence provided by Sparrow supports the sampled response 78% of the time. Sparrow is preferred more often than baselines while being more resilient to adversarial probing by humans, violating our rules only 8% of the time when probed. Finally, we conduct extensive analyses showing that though our model learns to follow our rules it can exhibit distributional biases.
Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning
Jun 30, 2022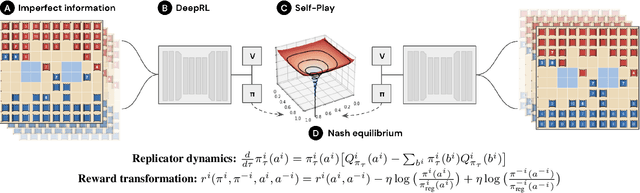
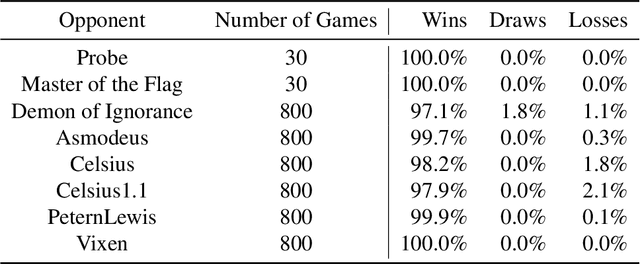
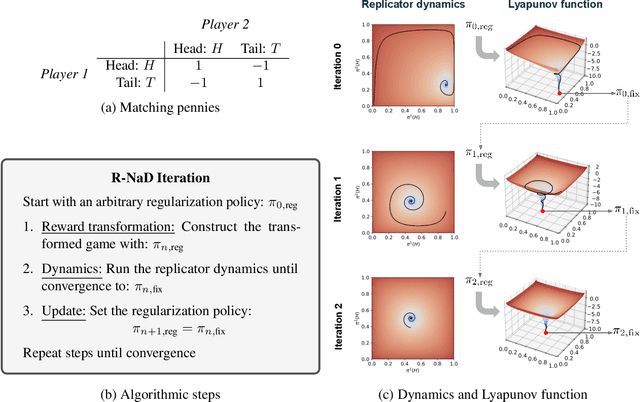

We introduce DeepNash, an autonomous agent capable of learning to play the imperfect information game Stratego from scratch, up to a human expert level. Stratego is one of the few iconic board games that Artificial Intelligence (AI) has not yet mastered. This popular game has an enormous game tree on the order of $10^{535}$ nodes, i.e., $10^{175}$ times larger than that of Go. It has the additional complexity of requiring decision-making under imperfect information, similar to Texas hold'em poker, which has a significantly smaller game tree (on the order of $10^{164}$ nodes). Decisions in Stratego are made over a large number of discrete actions with no obvious link between action and outcome. Episodes are long, with often hundreds of moves before a player wins, and situations in Stratego can not easily be broken down into manageably-sized sub-problems as in poker. For these reasons, Stratego has been a grand challenge for the field of AI for decades, and existing AI methods barely reach an amateur level of play. DeepNash uses a game-theoretic, model-free deep reinforcement learning method, without search, that learns to master Stratego via self-play. The Regularised Nash Dynamics (R-NaD) algorithm, a key component of DeepNash, converges to an approximate Nash equilibrium, instead of 'cycling' around it, by directly modifying the underlying multi-agent learning dynamics. DeepNash beats existing state-of-the-art AI methods in Stratego and achieved a yearly (2022) and all-time top-3 rank on the Gravon games platform, competing with human expert players.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.
Acquisition of Chess Knowledge in AlphaZero
Nov 27, 2021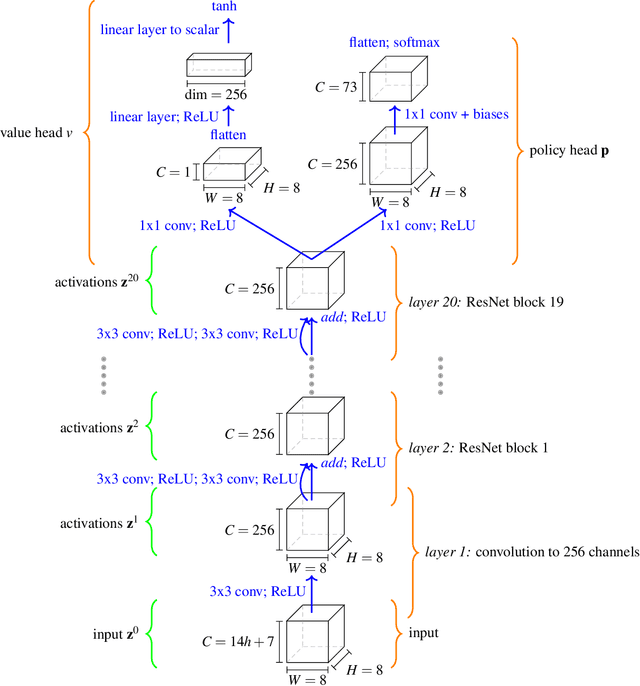

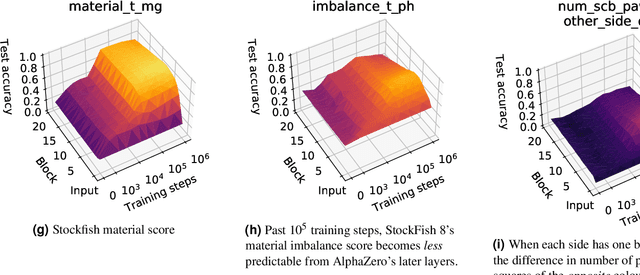
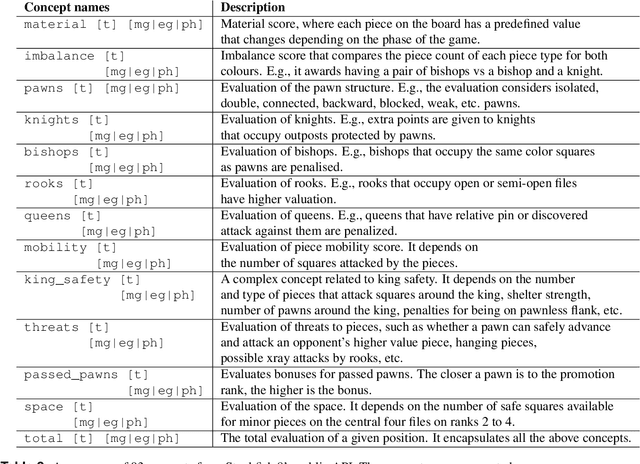
What is learned by sophisticated neural network agents such as AlphaZero? This question is of both scientific and practical interest. If the representations of strong neural networks bear no resemblance to human concepts, our ability to understand faithful explanations of their decisions will be restricted, ultimately limiting what we can achieve with neural network interpretability. In this work we provide evidence that human knowledge is acquired by the AlphaZero neural network as it trains on the game of chess. By probing for a broad range of human chess concepts we show when and where these concepts are represented in the AlphaZero network. We also provide a behavioural analysis focusing on opening play, including qualitative analysis from chess Grandmaster Vladimir Kramnik. Finally, we carry out a preliminary investigation looking at the low-level details of AlphaZero's representations, and make the resulting behavioural and representational analyses available online.
Alchemy: A structured task distribution for meta-reinforcement learning
Feb 04, 2021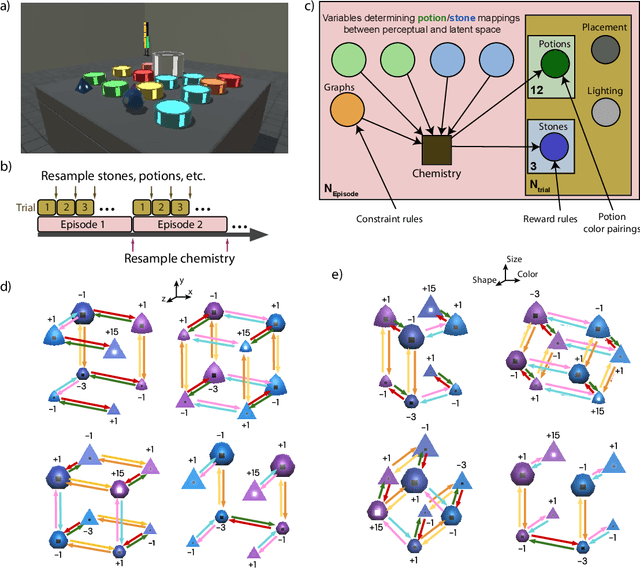

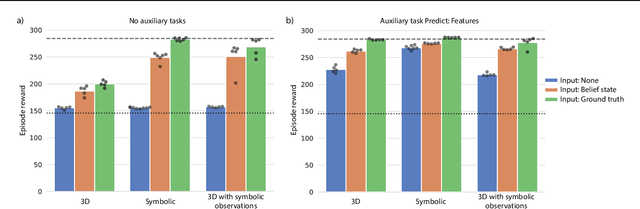

There has been rapidly growing interest in meta-learning as a method for increasing the flexibility and sample efficiency of reinforcement learning. One problem in this area of research, however, has been a scarcity of adequate benchmark tasks. In general, the structure underlying past benchmarks has either been too simple to be inherently interesting, or too ill-defined to support principled analysis. In the present work, we introduce a new benchmark for meta-RL research, which combines structural richness with structural transparency. Alchemy is a 3D video game, implemented in Unity, which involves a latent causal structure that is resampled procedurally from episode to episode, affording structure learning, online inference, hypothesis testing and action sequencing based on abstract domain knowledge. We evaluate a pair of powerful RL agents on Alchemy and present an in-depth analysis of one of these agents. Results clearly indicate a frank and specific failure of meta-learning, providing validation for Alchemy as a challenging benchmark for meta-RL. Concurrent with this report, we are releasing Alchemy as public resource, together with a suite of analysis tools and sample agent trajectories.
Game Plan: What AI can do for Football, and What Football can do for AI
Nov 18, 2020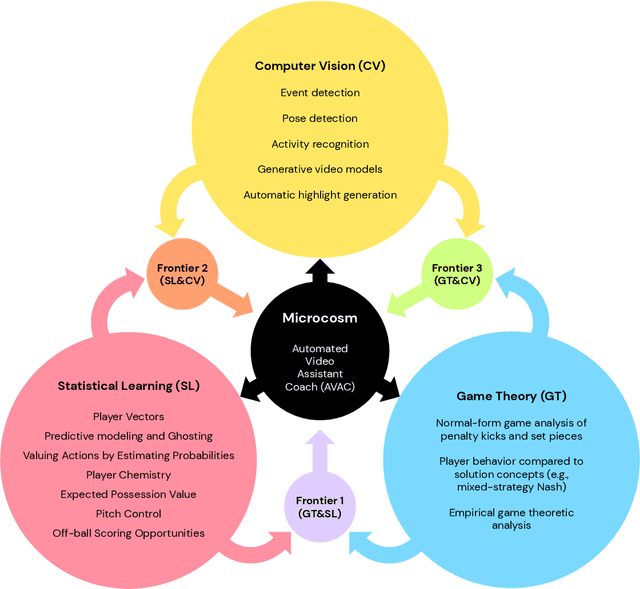



The rapid progress in artificial intelligence (AI) and machine learning has opened unprecedented analytics possibilities in various team and individual sports, including baseball, basketball, and tennis. More recently, AI techniques have been applied to football, due to a huge increase in data collection by professional teams, increased computational power, and advances in machine learning, with the goal of better addressing new scientific challenges involved in the analysis of both individual players' and coordinated teams' behaviors. The research challenges associated with predictive and prescriptive football analytics require new developments and progress at the intersection of statistical learning, game theory, and computer vision. In this paper, we provide an overarching perspective highlighting how the combination of these fields, in particular, forms a unique microcosm for AI research, while offering mutual benefits for professional teams, spectators, and broadcasters in the years to come. We illustrate that this duality makes football analytics a game changer of tremendous value, in terms of not only changing the game of football itself, but also in terms of what this domain can mean for the field of AI. We review the state-of-the-art and exemplify the types of analysis enabled by combining the aforementioned fields, including illustrative examples of counterfactual analysis using predictive models, and the combination of game-theoretic analysis of penalty kicks with statistical learning of player attributes. We conclude by highlighting envisioned downstream impacts, including possibilities for extensions to other sports (real and virtual).
Assessing Game Balance with AlphaZero: Exploring Alternative Rule Sets in Chess
Sep 15, 2020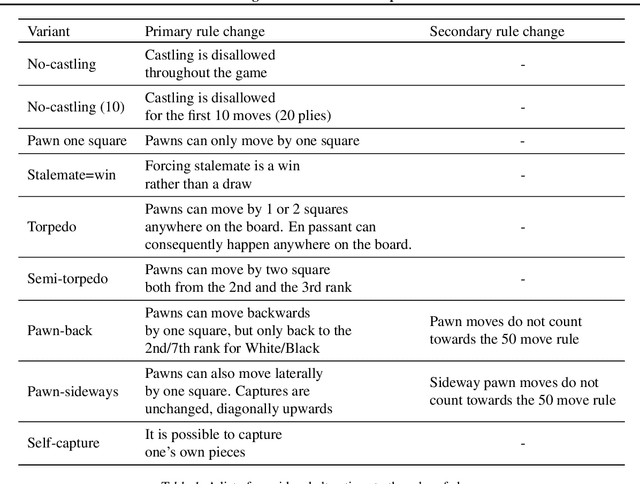


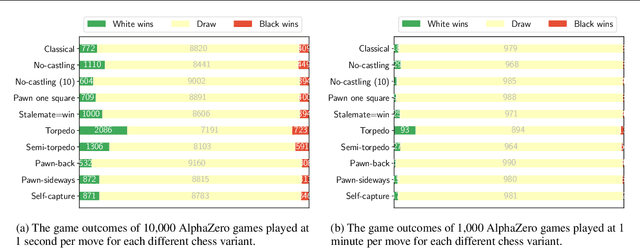
It is non-trivial to design engaging and balanced sets of game rules. Modern chess has evolved over centuries, but without a similar recourse to history, the consequences of rule changes to game dynamics are difficult to predict. AlphaZero provides an alternative in silico means of game balance assessment. It is a system that can learn near-optimal strategies for any rule set from scratch, without any human supervision, by continually learning from its own experience. In this study we use AlphaZero to creatively explore and design new chess variants. There is growing interest in chess variants like Fischer Random Chess, because of classical chess's voluminous opening theory, the high percentage of draws in professional play, and the non-negligible number of games that end while both players are still in their home preparation. We compare nine other variants that involve atomic changes to the rules of chess. The changes allow for novel strategic and tactical patterns to emerge, while keeping the games close to the original. By learning near-optimal strategies for each variant with AlphaZero, we determine what games between strong human players might look like if these variants were adopted. Qualitatively, several variants are very dynamic. An analytic comparison show that pieces are valued differently between variants, and that some variants are more decisive than classical chess. Our findings demonstrate the rich possibilities that lie beyond the rules of modern chess.