 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStories in Space: In-Context Learning Trajectories in Conceptual Belief Space
May 12, 2026Large Language Models (LLMs) update their behavior in context, which can be viewed as a form of Bayesian inference. However, the structure of the latent hypothesis space over which this inference operates remains unclear. In this work, we propose that LLMs assign beliefs over a low-dimensional geometric space - a conceptual belief space - and that in-context learning corresponds to a trajectory through this space as beliefs are updated over time. Using story understanding as a natural setting for dynamic belief updating, we combine behavioral and representational analyses to study these trajectories. We find that (1) belief updates are well-described as trajectories on low-dimensional, structured manifolds; (2) this structure is reflected consistently in both model behavior and internal representations and can be decoded with simple linear probes to predict behavior; and (3) interventions on these representations causally steer belief trajectories, with effects that can be predicted from the geometry of the conceptual space. Together, our results provide a geometric account of belief dynamics in LLMs, grounding Bayesian interpretations of in-context learning in structured conceptual representations.
Manifold Steering Reveals the Shared Geometry of Neural Network Representation and Behavior
May 06, 2026Neural representations carry rich geometric structure; but does that structure causally shape behavior? To address this question, we intervene along paths through activation space defined by different geometries, and measure the behavioral trajectories they induce. In particular, we test whether interventions that respect the geometry of activation space will yield behaviors close to those the model exhibits naturally. Concretely, we first fit an activation manifold $M_h$ to representations and a behavior manifold $M_y$ to output probability distributions. We then test the link $M_h \leftrightarrow M_y$ via interventions: we find that steering along $M_h$, which we term manifold steering, yields behavioral trajectories that follow $M_y$, while linear steering -- which assumes a Euclidean geometry -- cuts through off-manifold regions and hence produces unnatural outputs. Moreover, optimizing interventions in activation space to produce paths along $M_y$ recovers activation trajectories that trace the curvature of $M_h$. We demonstrate this bidirectional relationship between the geometry of representation and behavior across tasks and modalities. In language models, we use reasoning tasks with cyclic and sequential geometries as well as in-context learning tasks with more complex graph geometries. In a video world model, we use a task with geometry corresponding to physical dynamics. Overall, our work shows that geometry in neural representation is not merely incidental, but is in fact the proper object for enabling principled control via intervention on internals. This recasts the core problem of steering from finding the right direction to finding the right geometry.
Features as Rewards: Scalable Supervision for Open-Ended Tasks via Interpretability
Feb 11, 2026Language models trained on large-scale datasets have been shown to learn features that encode abstract concepts such as factuality or intent. Such features are traditionally used for test-time monitoring or steering. We present an alternative affordance: features as scalable supervision for open-ended tasks. We consider the case of hallucination-reduction as a desirable, yet open-ended behavior and design a reinforcement learning (RL) pipeline, titled RLFR (Reinforcement Learning from Feature Rewards), that uses features as reward functions. Grounded in a novel probing framework that identifies candidate hallucinated claims, our pipeline teaches a model to intervene and correct its completions when it is uncertain of their factuality. Furthermore, the pipeline enables scalable test-time compute, guided once more by our reward features. This end-to-end process operationalized on Gemma-3-12B-IT results in a policy that is 58% less likely to hallucinate compared to the original model (when run in tandem with our probing harness), while preserving performance on standard benchmarks. Taken together, by grounding supervision in the language of features, this paper introduces a novel paradigm in the use of interpretability for learning open-ended tasks.
Copy Suppression: Comprehensively Understanding an Attention Head
Oct 06, 2023



We present a single attention head in GPT-2 Small that has one main role across the entire training distribution. If components in earlier layers predict a certain token, and this token appears earlier in the context, the head suppresses it: we call this copy suppression. Attention Head 10.7 (L10H7) suppresses naive copying behavior which improves overall model calibration. This explains why multiple prior works studying certain narrow tasks found negative heads that systematically favored the wrong answer. We uncover the mechanism that the Negative Heads use for copy suppression with weights-based evidence and are able to explain 76.9% of the impact of L10H7 in GPT-2 Small. To the best of our knowledge, this is the most comprehensive description of the complete role of a component in a language model to date. One major effect of copy suppression is its role in self-repair. Self-repair refers to how ablating crucial model components results in downstream neural network parts compensating for this ablation. Copy suppression leads to self-repair: if an initial overconfident copier is ablated, then there is nothing to suppress. We show that self-repair is implemented by several mechanisms, one of which is copy suppression, which explains 39% of the behavior in a narrow task. Interactive visualisations of the copy suppression phenomena may be seen at our web app https://copy-suppression.streamlit.app/
The Hydra Effect: Emergent Self-repair in Language Model Computations
Jul 28, 2023We investigate the internal structure of language model computations using causal analysis and demonstrate two motifs: (1) a form of adaptive computation where ablations of one attention layer of a language model cause another layer to compensate (which we term the Hydra effect) and (2) a counterbalancing function of late MLP layers that act to downregulate the maximum-likelihood token. Our ablation studies demonstrate that language model layers are typically relatively loosely coupled (ablations to one layer only affect a small number of downstream layers). Surprisingly, these effects occur even in language models trained without any form of dropout. We analyse these effects in the context of factual recall and consider their implications for circuit-level attribution in language models.
Tracr: Compiled Transformers as a Laboratory for Interpretability
Jan 12, 2023Interpretability research aims to build tools for understanding machine learning (ML) models. However, such tools are inherently hard to evaluate because we do not have ground truth information about how ML models actually work. In this work, we propose to build transformer models manually as a testbed for interpretability research. We introduce Tracr, a "compiler" for translating human-readable programs into weights of a transformer model. Tracr takes code written in RASP, a domain-specific language (Weiss et al. 2021), and translates it into weights for a standard, decoder-only, GPT-like transformer architecture. We use Tracr to create a range of ground truth transformers that implement programs including computing token frequencies, sorting, and Dyck-n parenthesis checking, among others. To enable the broader research community to explore and use compiled models, we provide an open-source implementation of Tracr at https://github.com/deepmind/tracr.
Acquisition of Chess Knowledge in AlphaZero
Nov 27, 2021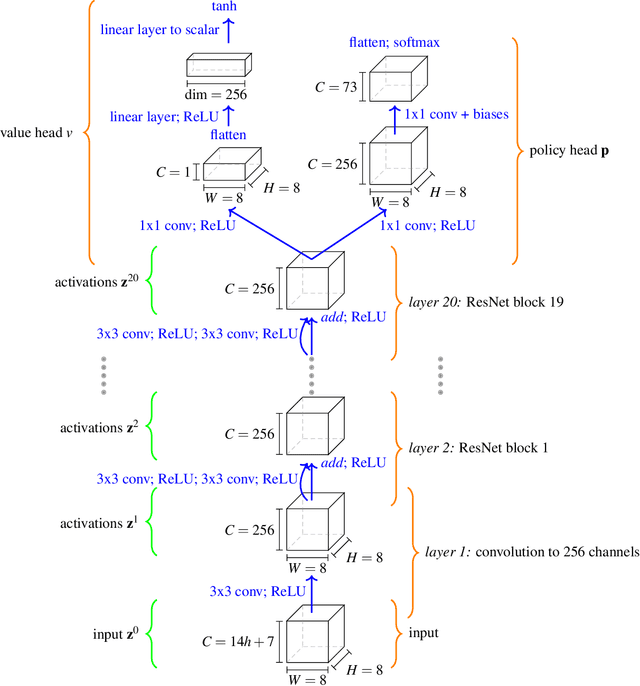

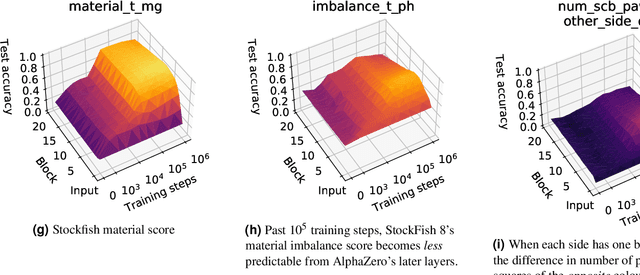
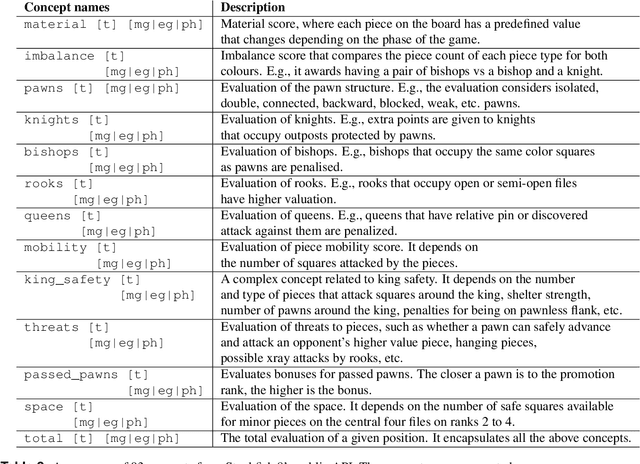
What is learned by sophisticated neural network agents such as AlphaZero? This question is of both scientific and practical interest. If the representations of strong neural networks bear no resemblance to human concepts, our ability to understand faithful explanations of their decisions will be restricted, ultimately limiting what we can achieve with neural network interpretability. In this work we provide evidence that human knowledge is acquired by the AlphaZero neural network as it trains on the game of chess. By probing for a broad range of human chess concepts we show when and where these concepts are represented in the AlphaZero network. We also provide a behavioural analysis focusing on opening play, including qualitative analysis from chess Grandmaster Vladimir Kramnik. Finally, we carry out a preliminary investigation looking at the low-level details of AlphaZero's representations, and make the resulting behavioural and representational analyses available online.