 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA scalable and real-time neural decoder for topological quantum codes
Dec 08, 2025Fault-tolerant quantum computing will require error rates far below those achievable with physical qubits. Quantum error correction (QEC) bridges this gap, but depends on decoders being simultaneously fast, accurate, and scalable. This combination of requirements has not yet been met by a machine-learning decoder, nor by any decoder for promising resource-efficient codes such as the colour code. Here we introduce AlphaQubit 2, a neural-network decoder that achieves near-optimal logical error rates for both surface and colour codes at large scales under realistic noise. For the colour code, it is orders of magnitude faster than other high-accuracy decoders. For the surface code, we demonstrate real-time decoding faster than 1 microsecond per cycle up to distance 11 on current commercial accelerators with better accuracy than leading real-time decoders. These results support the practical application of a wider class of promising QEC codes, and establish a credible path towards high-accuracy, real-time neural decoding at the scales required for fault-tolerant quantum computation.
The unknotting number, hard unknot diagrams, and reinforcement learning
Sep 13, 2024



We have developed a reinforcement learning agent that often finds a minimal sequence of unknotting crossing changes for a knot diagram with up to 200 crossings, hence giving an upper bound on the unknotting number. We have used this to determine the unknotting number of 57k knots. We took diagrams of connected sums of such knots with oppositely signed signatures, where the summands were overlaid. The agent has found examples where several of the crossing changes in an unknotting collection of crossings result in hyperbolic knots. Based on this, we have shown that, given knots $K$ and $K'$ that satisfy some mild assumptions, there is a diagram of their connected sum and $u(K) + u(K')$ unknotting crossings such that changing any one of them results in a prime knot. As a by-product, we have obtained a dataset of 2.6 million distinct hard unknot diagrams; most of them under 35 crossings. Assuming the additivity of the unknotting number, we have determined the unknotting number of 43 at most 12-crossing knots for which the unknotting number is unknown.
Finding Increasingly Large Extremal Graphs with AlphaZero and Tabu Search
Nov 06, 2023



This work studies a central extremal graph theory problem inspired by a 1975 conjecture of Erd\H{o}s, which aims to find graphs with a given size (number of nodes) that maximize the number of edges without having 3- or 4-cycles. We formulate this problem as a sequential decision-making problem and compare AlphaZero, a neural network-guided tree search, with tabu search, a heuristic local search method. Using either method, by introducing a curriculum -- jump-starting the search for larger graphs using good graphs found at smaller sizes -- we improve the state-of-the-art lower bounds for several sizes. We also propose a flexible graph-generation environment and a permutation-invariant network architecture for learning to search in the space of graphs.
Learning to Decode the Surface Code with a Recurrent, Transformer-Based Neural Network
Oct 09, 2023



Quantum error-correction is a prerequisite for reliable quantum computation. Towards this goal, we present a recurrent, transformer-based neural network which learns to decode the surface code, the leading quantum error-correction code. Our decoder outperforms state-of-the-art algorithmic decoders on real-world data from Google's Sycamore quantum processor for distance 3 and 5 surface codes. On distances up to 11, the decoder maintains its advantage on simulated data with realistic noise including cross-talk, leakage, and analog readout signals, and sustains its accuracy far beyond the 25 cycles it was trained on. Our work illustrates the ability of machine learning to go beyond human-designed algorithms by learning from data directly, highlighting machine learning as a strong contender for decoding in quantum computers.
A Deep Learning Approach for Characterizing Major Galaxy Mergers
Feb 09, 2021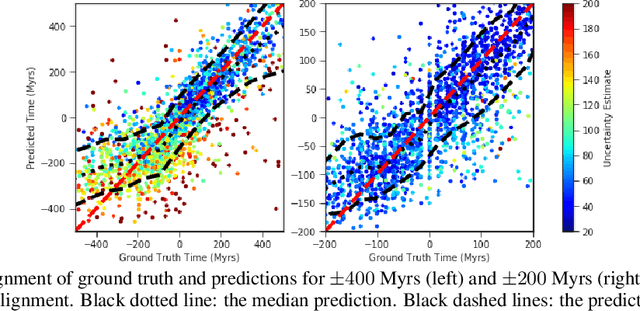

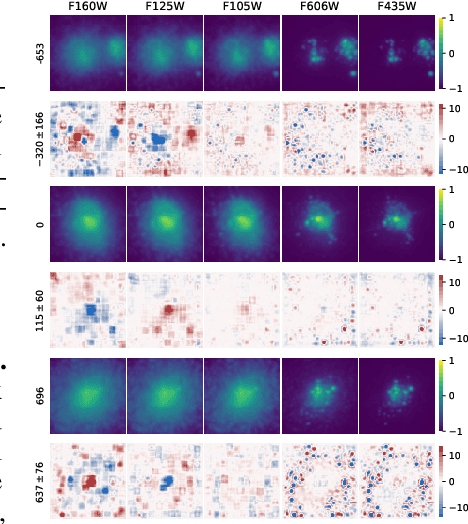
Fine-grained estimation of galaxy merger stages from observations is a key problem useful for validation of our current theoretical understanding of galaxy formation. To this end, we demonstrate a CNN-based regression model that is able to predict, for the first time, using a single image, the merger stage relative to the first perigee passage with a median error of 38.3 million years (Myrs) over a period of 400 Myrs. This model uses no specific dynamical modeling and learns only from simulated merger events. We show that our model provides reasonable estimates on real observations, approximately matching prior estimates provided by detailed dynamical modeling. We provide a preliminary interpretability analysis of our models, and demonstrate first steps toward calibrated uncertainty estimation.
Deep learning to achieve clinically applicable segmentation of head and neck anatomy for radiotherapy
Sep 12, 2018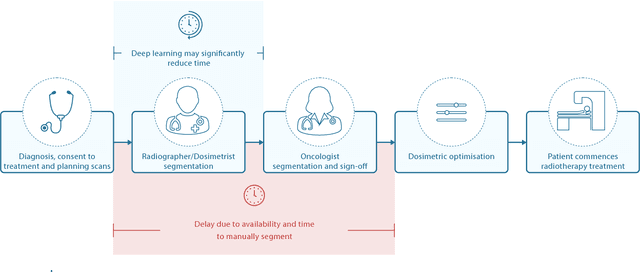
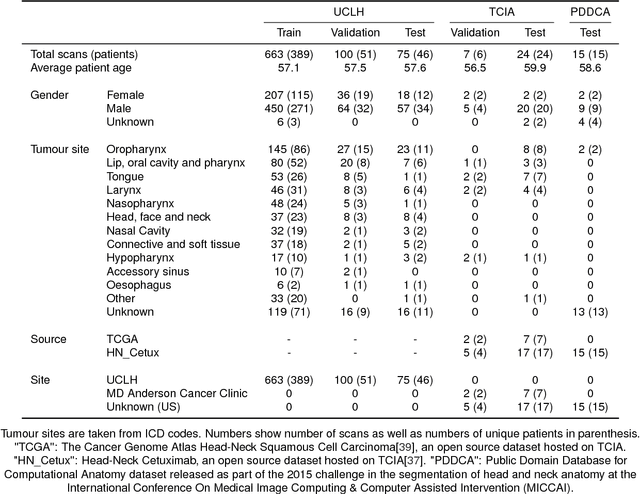
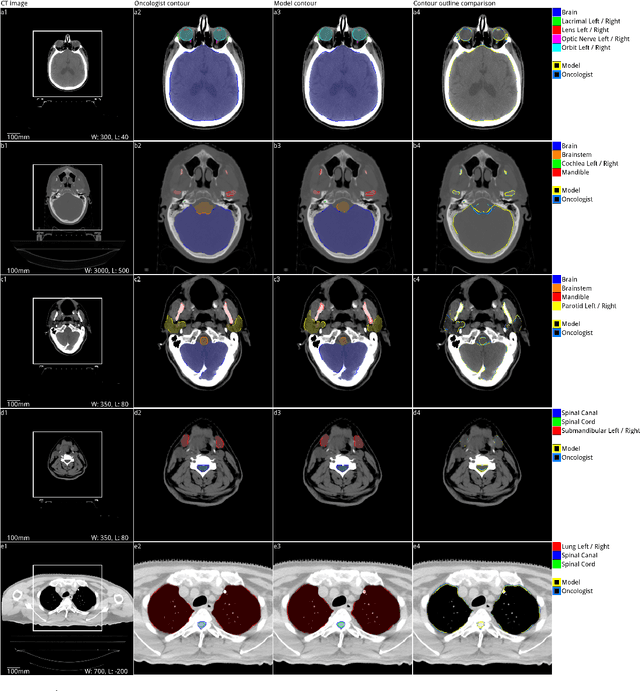
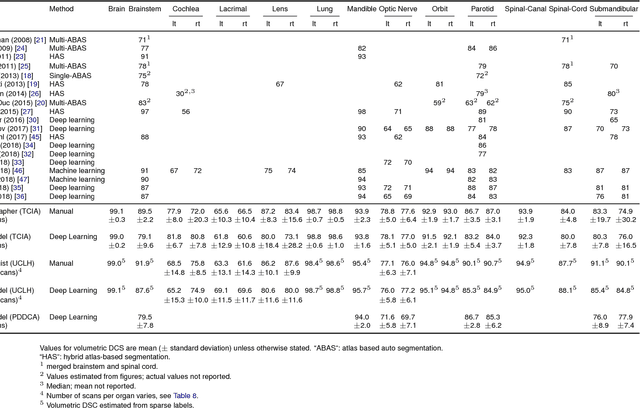
Over half a million individuals are diagnosed with head and neck cancer each year worldwide. Radiotherapy is an important curative treatment for this disease, but it requires manually intensive delineation of radiosensitive organs at risk (OARs). This planning process can delay treatment commencement. While auto-segmentation algorithms offer a potentially time-saving solution, the challenges in defining, quantifying and achieving expert performance remain. Adopting a deep learning approach, we demonstrate a 3D U-Net architecture that achieves performance similar to experts in delineating a wide range of head and neck OARs. The model was trained on a dataset of 663 deidentified computed tomography (CT) scans acquired in routine clinical practice and segmented according to consensus OAR definitions. We demonstrate its generalisability through application to an independent test set of 24 CT scans available from The Cancer Imaging Archive collected at multiple international sites previously unseen to the model, each segmented by two independent experts and consisting of 21 OARs commonly segmented in clinical practice. With appropriate validation studies and regulatory approvals, this system could improve the effectiveness of radiotherapy pathways.
Massively Parallel Methods for Deep Reinforcement Learning
Jul 16, 2015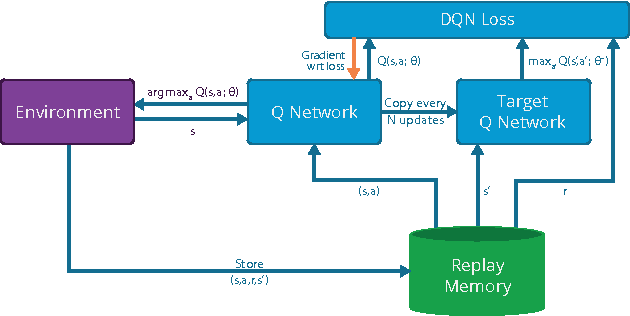
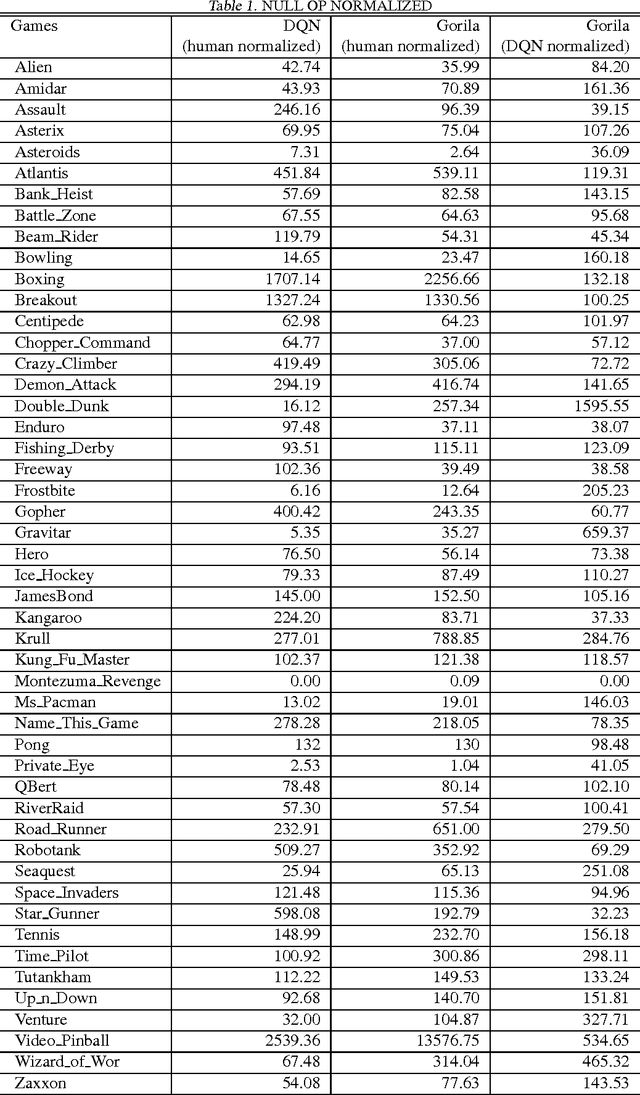
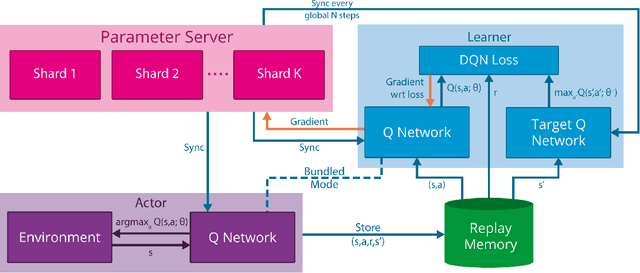
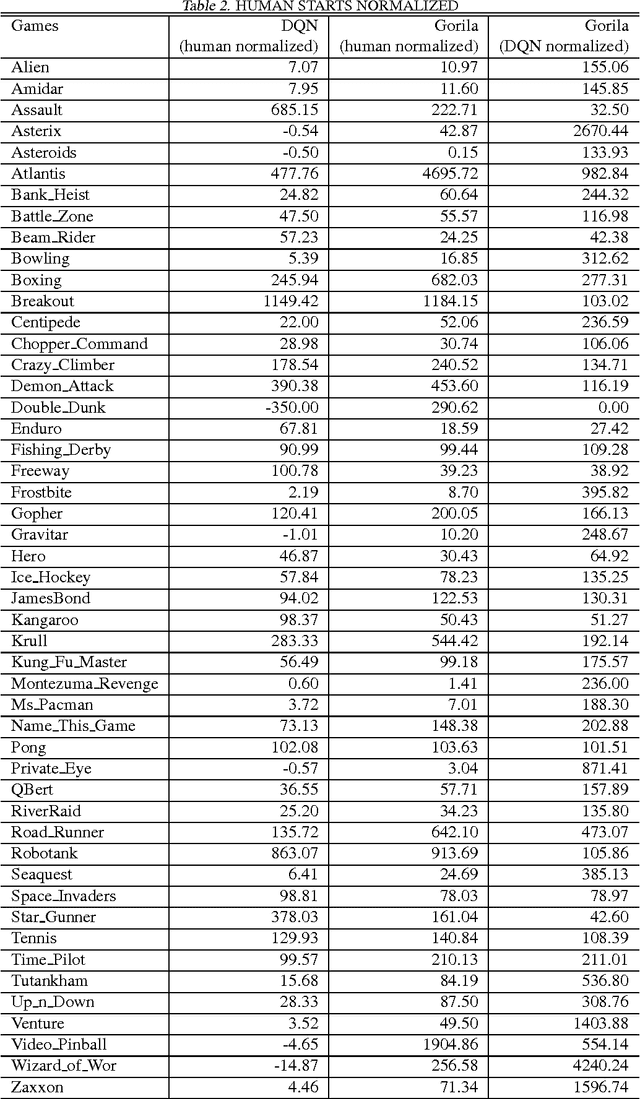
We present the first massively distributed architecture for deep reinforcement learning. This architecture uses four main components: parallel actors that generate new behaviour; parallel learners that are trained from stored experience; a distributed neural network to represent the value function or behaviour policy; and a distributed store of experience. We used our architecture to implement the Deep Q-Network algorithm (DQN). Our distributed algorithm was applied to 49 games from Atari 2600 games from the Arcade Learning Environment, using identical hyperparameters. Our performance surpassed non-distributed DQN in 41 of the 49 games and also reduced the wall-time required to achieve these results by an order of magnitude on most games.