 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-Watcher: A Framework for Early Detection of High-Risk Neighborhoods Ahead of COVID-19 Outbreak
Jan 27, 2021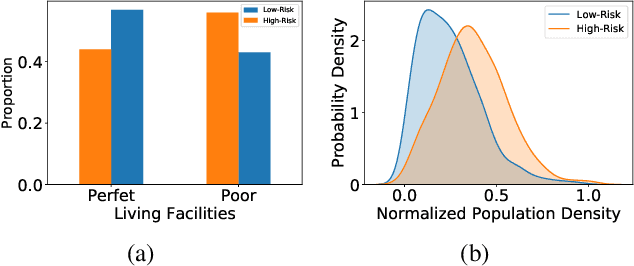
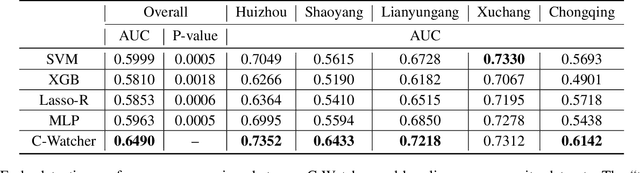
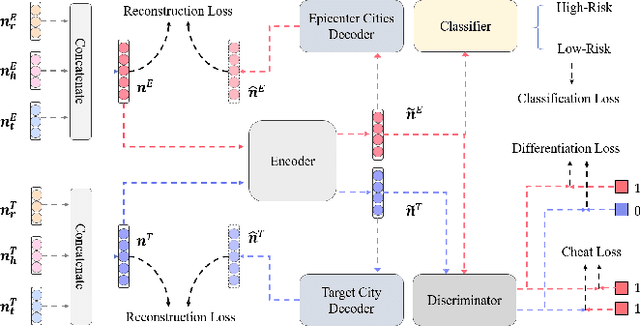
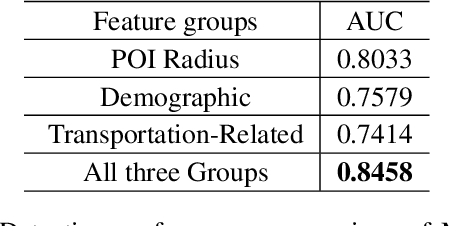
The novel coronavirus disease (COVID-19) has crushed daily routines and is still rampaging through the world. Existing solution for nonpharmaceutical interventions usually needs to timely and precisely select a subset of residential urban areas for containment or even quarantine, where the spatial distribution of confirmed cases has been considered as a key criterion for the subset selection. While such containment measure has successfully stopped or slowed down the spread of COVID-19 in some countries, it is criticized for being inefficient or ineffective, as the statistics of confirmed cases are usually time-delayed and coarse-grained. To tackle the issues, we propose C-Watcher, a novel data-driven framework that aims at screening every neighborhood in a target city and predicting infection risks, prior to the spread of COVID-19 from epicenters to the city. In terms of design, C-Watcher collects large-scale long-term human mobility data from Baidu Maps, then characterizes every residential neighborhood in the city using a set of features based on urban mobility patterns. Furthermore, to transfer the firsthand knowledge (witted in epicenters) to the target city before local outbreaks, we adopt a novel adversarial encoder framework to learn "city-invariant" representations from the mobility-related features for precise early detection of high-risk neighborhoods, even before any confirmed cases known, in the target city. We carried out extensive experiments on C-Watcher using the real-data records in the early stage of COVID-19 outbreaks, where the results demonstrate the efficiency and effectiveness of C-Watcher for early detection of high-risk neighborhoods from a large number of cities.
Joint Air Quality and Weather Prediction Based on Multi-Adversarial Spatiotemporal Networks
Jan 05, 2021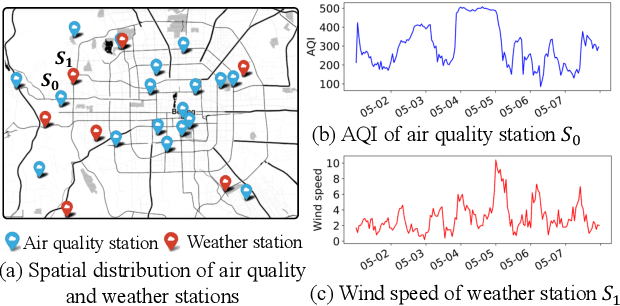
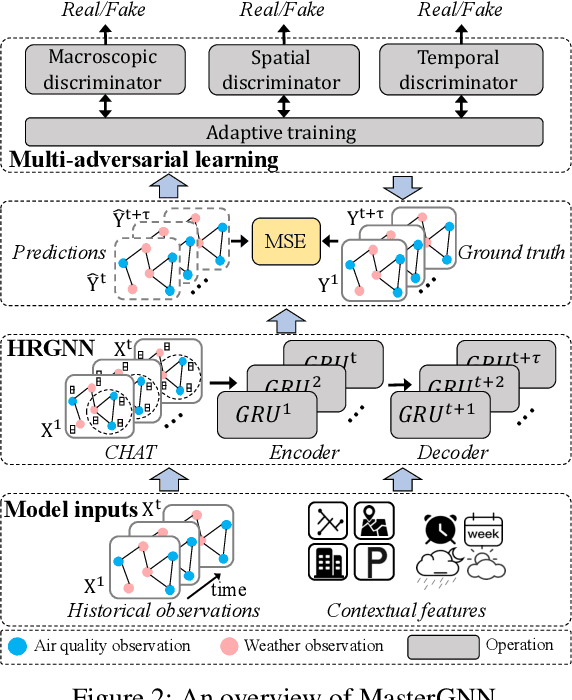
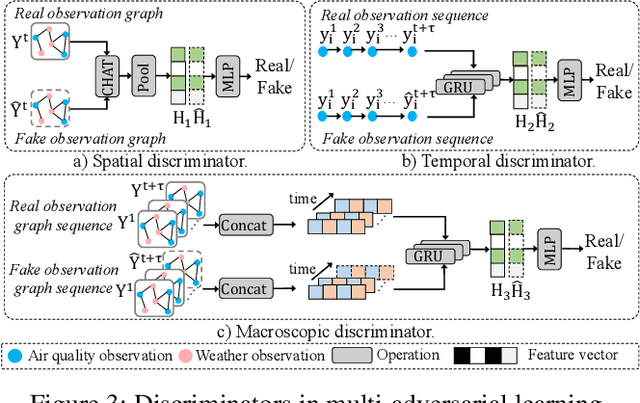
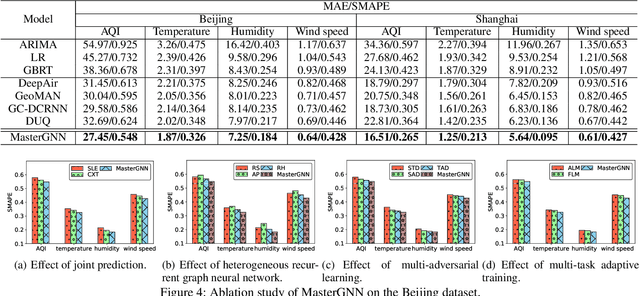
Accurate and timely air quality and weather predictions are of great importance to urban governance and human livelihood. Though many efforts have been made for air quality or weather prediction, most of them simply employ one another as feature input, which ignores the inner-connection between two predictive tasks. On the one hand, the accurate prediction of one task can help improve another task's performance. On the other hand, geospatially distributed air quality and weather monitoring stations provide additional hints for city-wide spatiotemporal dependency modeling. Inspired by the above two insights, in this paper, we propose the Multi-adversarial spatiotemporal recurrent Graph Neural Networks (MasterGNN) for joint air quality and weather predictions. Specifically, we first propose a heterogeneous recurrent graph neural network to model the spatiotemporal autocorrelation among air quality and weather monitoring stations. Then, we develop a multi-adversarial graph learning framework to against observation noise propagation introduced by spatiotemporal modeling. Moreover, we present an adaptive training strategy by formulating multi-adversarial learning as a multi-task learning problem. Finally, extensive experiments on two real-world datasets show that MasterGNN achieves the best performance compared with seven baselines on both air quality and weather prediction tasks.
Distance-aware Molecule Graph Attention Network for Drug-Target Binding Affinity Prediction
Dec 17, 2020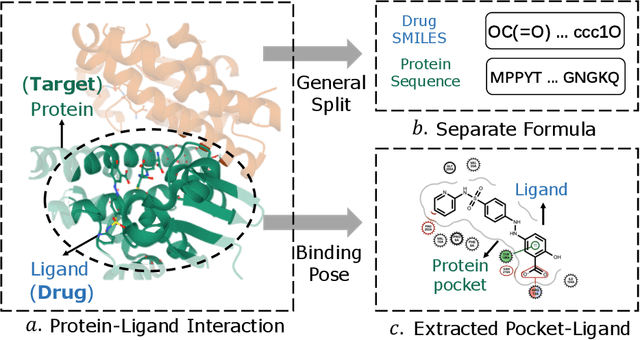

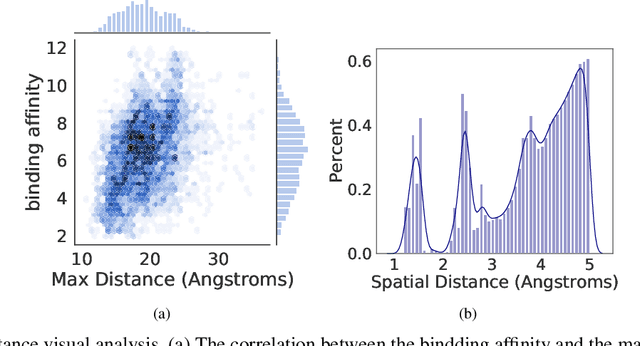
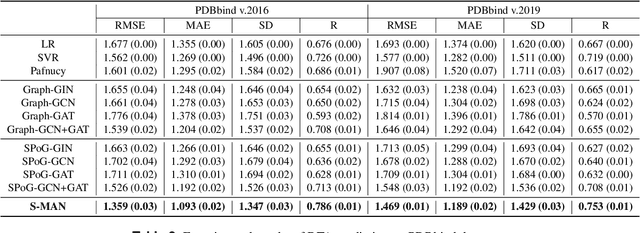
Accurately predicting the binding affinity between drugs and proteins is an essential step for computational drug discovery. Since graph neural networks (GNNs) have demonstrated remarkable success in various graph-related tasks, GNNs have been considered as a promising tool to improve the binding affinity prediction in recent years. However, most of the existing GNN architectures can only encode the topological graph structure of drugs and proteins without considering the relative spatial information among their atoms. Whereas, different from other graph datasets such as social networks and commonsense knowledge graphs, the relative spatial position and chemical bonds among atoms have significant impacts on the binding affinity. To this end, in this paper, we propose a diStance-aware Molecule graph Attention Network (S-MAN) tailored to drug-target binding affinity prediction. As a dedicated solution, we first propose a position encoding mechanism to integrate the topological structure and spatial position information into the constructed pocket-ligand graph. Moreover, we propose a novel edge-node hierarchical attentive aggregation structure which has edge-level aggregation and node-level aggregation. The hierarchical attentive aggregation can capture spatial dependencies among atoms, as well as fuse the position-enhanced information with the capability of discriminating multiple spatial relations among atoms. Finally, we conduct extensive experiments on two standard datasets to demonstrate the effectiveness of S-MAN.
Temporal Relational Modeling with Self-Supervision for Action Segmentation
Dec 14, 2020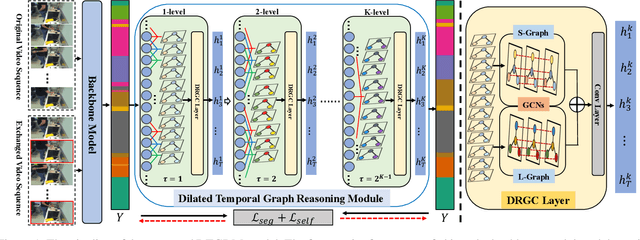
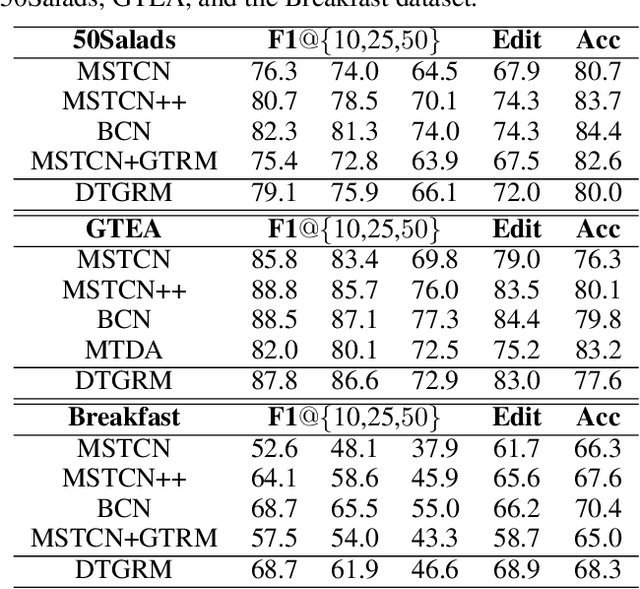
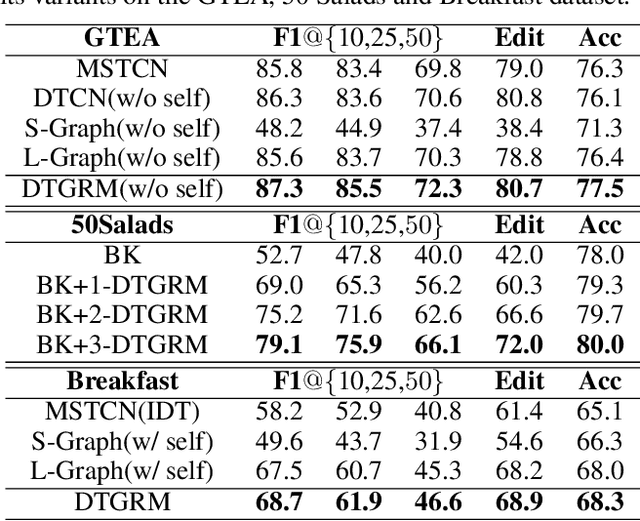

Temporal relational modeling in video is essential for human action understanding, such as action recognition and action segmentation. Although Graph Convolution Networks (GCNs) have shown promising advantages in relation reasoning on many tasks, it is still a challenge to apply graph convolution networks on long video sequences effectively. The main reason is that large number of nodes (i.e., video frames) makes GCNs hard to capture and model temporal relations in videos. To tackle this problem, in this paper, we introduce an effective GCN module, Dilated Temporal Graph Reasoning Module (DTGRM), designed to model temporal relations and dependencies between video frames at various time spans. In particular, we capture and model temporal relations via constructing multi-level dilated temporal graphs where the nodes represent frames from different moments in video. Moreover, to enhance temporal reasoning ability of the proposed model, an auxiliary self-supervised task is proposed to encourage the dilated temporal graph reasoning module to find and correct wrong temporal relations in videos. Our DTGRM model outperforms state-of-the-art action segmentation models on three challenging datasets: 50Salads, Georgia Tech Egocentric Activities (GTEA), and the Breakfast dataset. The code is available at https://github.com/redwang/DTGRM.
Improving Aspect-based Sentiment Analysis with Gated Graph Convolutional Networks and Syntax-based Regulation
Oct 26, 2020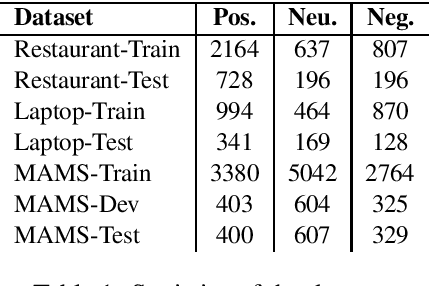
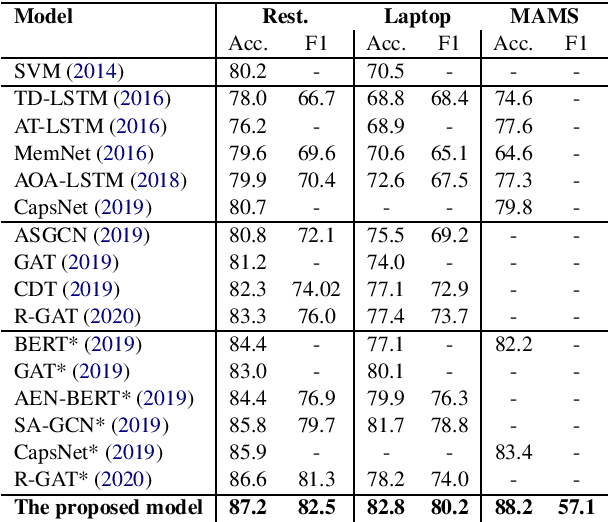
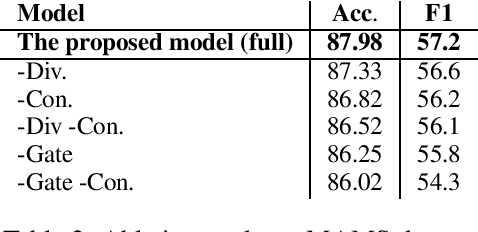

Aspect-based Sentiment Analysis (ABSA) seeks to predict the sentiment polarity of a sentence toward a specific aspect. Recently, it has been shown that dependency trees can be integrated into deep learning models to produce the state-of-the-art performance for ABSA. However, these models tend to compute the hidden/representation vectors without considering the aspect terms and fail to benefit from the overall contextual importance scores of the words that can be obtained from the dependency tree for ABSA. In this work, we propose a novel graph-based deep learning model to overcome these two issues of the prior work on ABSA. In our model, gate vectors are generated from the representation vectors of the aspect terms to customize the hidden vectors of the graph-based models toward the aspect terms. In addition, we propose a mechanism to obtain the importance scores for each word in the sentences based on the dependency trees that are then injected into the model to improve the representation vectors for ABSA. The proposed model achieves the state-of-the-art performance on three benchmark datasets.
Introducing Syntactic Structures into Target Opinion Word Extraction with Deep Learning
Oct 26, 2020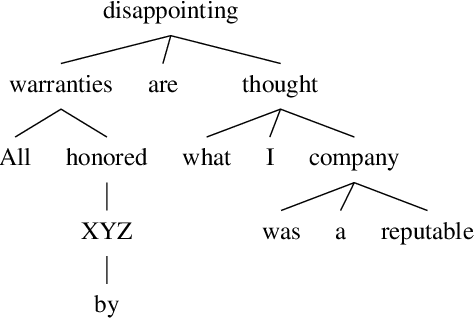
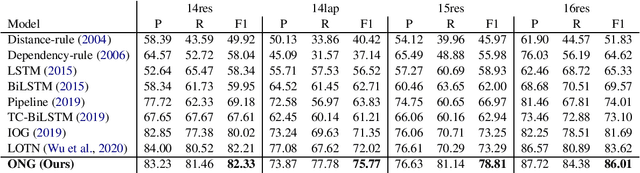
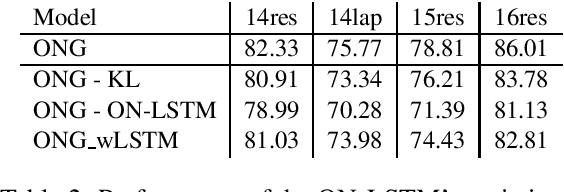
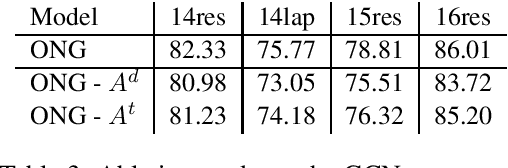
Targeted opinion word extraction (TOWE) is a sub-task of aspect based sentiment analysis (ABSA) which aims to find the opinion words for a given aspect-term in a sentence. Despite their success for TOWE, the current deep learning models fail to exploit the syntactic information of the sentences that have been proved to be useful for TOWE in the prior research. In this work, we propose to incorporate the syntactic structures of the sentences into the deep learning models for TOWE, leveraging the syntax-based opinion possibility scores and the syntactic connections between the words. We also introduce a novel regularization technique to improve the performance of the deep learning models based on the representation distinctions between the words in TOWE. The proposed model is extensively analyzed and achieves the state-of-the-art performance on four benchmark datasets.
Towards Accurate Knowledge Transfer via Target-awareness Representation Disentanglement
Oct 16, 2020
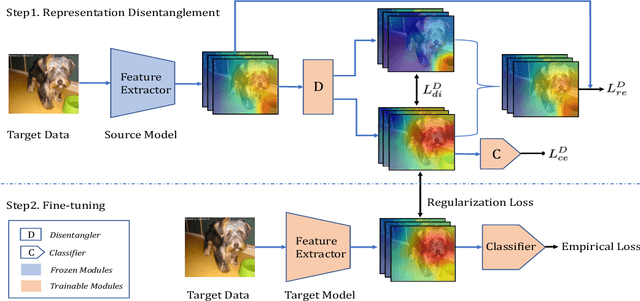
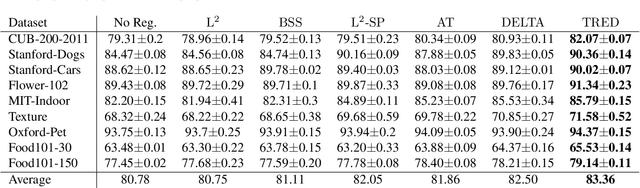
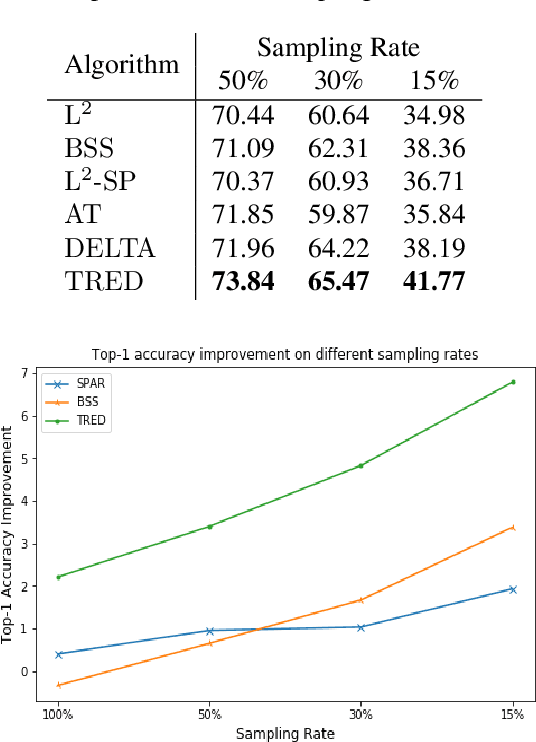
Fine-tuning deep neural networks pre-trained on large scale datasets is one of the most practical transfer learning paradigm given limited quantity of training samples. To obtain better generalization, using the starting point as the reference, either through weights or features, has been successfully applied to transfer learning as a regularizer. However, due to the domain discrepancy between the source and target tasks, there exists obvious risk of negative transfer. In this paper, we propose a novel transfer learning algorithm, introducing the idea of Target-awareness REpresentation Disentanglement (TRED), where the relevant knowledge with respect to the target task is disentangled from the original source model and used as a regularizer during fine-tuning the target model. Experiments on various real world datasets show that our method stably improves the standard fine-tuning by more than 2% in average. TRED also outperforms other state-of-the-art transfer learning regularizers such as L2-SP, AT, DELTA and BSS.
Discriminative Sounding Objects Localization via Self-supervised Audiovisual Matching
Oct 12, 2020
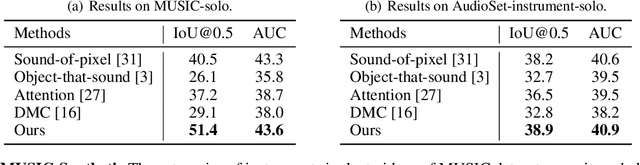
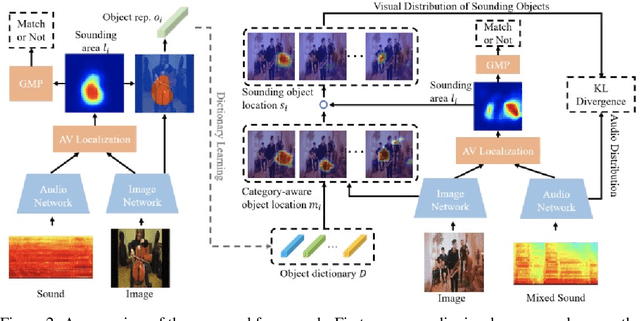
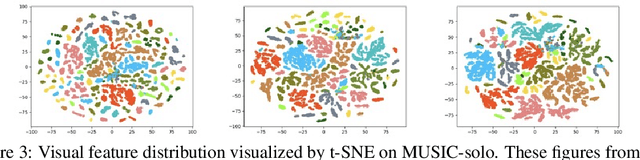
Discriminatively localizing sounding objects in cocktail-party, i.e., mixed sound scenes, is commonplace for humans, but still challenging for machines. In this paper, we propose a two-stage learning framework to perform self-supervised class-aware sounding object localization. First, we propose to learn robust object representations by aggregating the candidate sound localization results in the single source scenes. Then, class-aware object localization maps are generated in the cocktail-party scenarios by referring the pre-learned object knowledge, and the sounding objects are accordingly selected by matching audio and visual object category distributions, where the audiovisual consistency is viewed as the self-supervised signal. Experimental results in both realistic and synthesized cocktail-party videos demonstrate that our model is superior in filtering out silent objects and pointing out the location of sounding objects of different classes. Code is available at https://github.com/DTaoo/Discriminative-Sounding-Objects-Localization.
Measuring Information Transfer in Neural Networks
Sep 16, 2020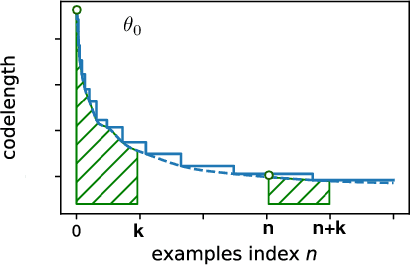
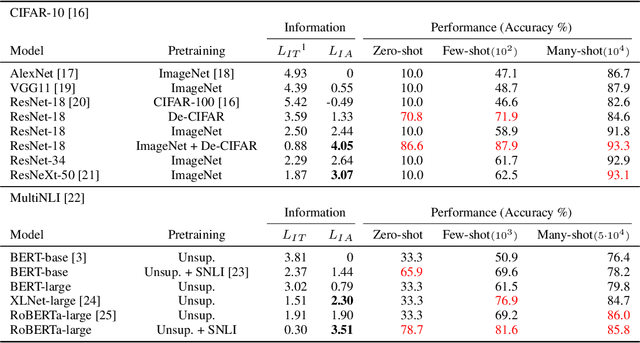
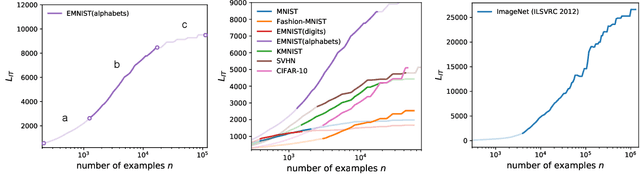
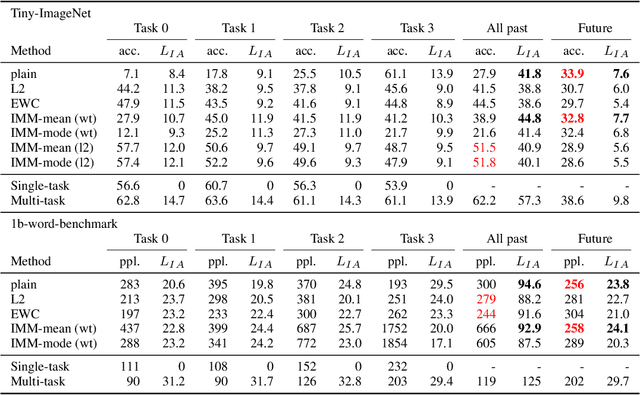
Estimation of the information content in a neural network model can be prohibitive, because of difficulty in finding an optimal codelength of the model. We propose to use a surrogate measure to bypass directly estimating model information. The proposed Information Transfer ($L_{IT}$) is a measure of model information based on prequential coding. $L_{IT}$ is theoretically connected to model information, and is consistently correlated with model information in experiments. We show that $L_{IT}$ can be used as a measure of generalizable knowledge in a model or a dataset. Therefore, $L_{IT}$ can serve as an analytical tool in deep learning. We apply $L_{IT}$ to compare and dissect information in datasets, evaluate representation models in transfer learning, and analyze catastrophic forgetting and continual learning algorithms. $L_{IT}$ provides an informational perspective which helps us discover new insights into neural network learning.
XMixup: Efficient Transfer Learning with Auxiliary Samples by Cross-domain Mixup
Jul 20, 2020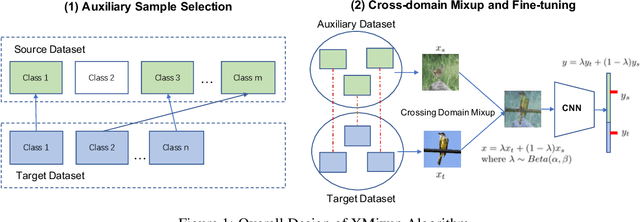
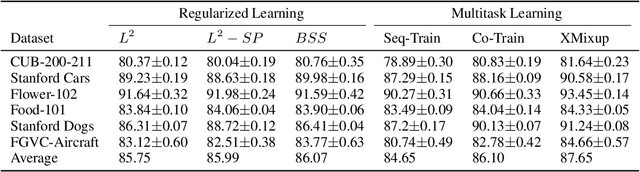
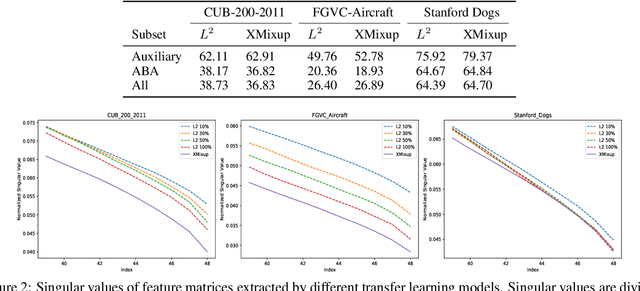
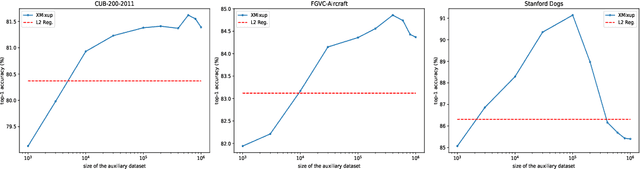
Transferring knowledge from large source datasets is an effective way to fine-tune the deep neural networks of the target task with a small sample size. A great number of algorithms have been proposed to facilitate deep transfer learning, and these techniques could be generally categorized into two groups - Regularized Learning of the target task using models that have been pre-trained from source datasets, and Multitask Learning with both source and target datasets to train a shared backbone neural network. In this work, we aim to improve the multitask paradigm for deep transfer learning via Cross-domain Mixup (XMixup). While the existing multitask learning algorithms need to run backpropagation over both the source and target datasets and usually consume a higher gradient complexity, XMixup transfers the knowledge from source to target tasks more efficiently: for every class of the target task, XMixup selects the auxiliary samples from the source dataset and augments training samples via the simple mixup strategy. We evaluate XMixup over six real world transfer learning datasets. Experiment results show that XMixup improves the accuracy by 1.9% on average. Compared with other state-of-the-art transfer learning approaches, XMixup costs much less training time while still obtains higher accuracy.