 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraction Graphs for Object Importance Estimation in On-road Driving Videos
Mar 12, 2020
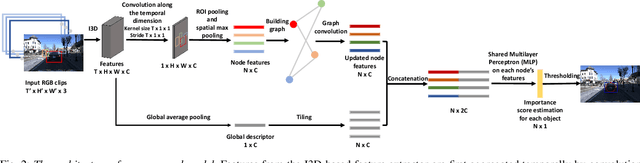


A vehicle driving along the road is surrounded by many objects, but only a small subset of them influence the driver's decisions and actions. Learning to estimate the importance of each object on the driver's real-time decision-making may help better understand human driving behavior and lead to more reliable autonomous driving systems. Solving this problem requires models that understand the interactions between the ego-vehicle and the surrounding objects. However, interactions among other objects in the scene can potentially also be very helpful, e.g., a pedestrian beginning to cross the road between the ego-vehicle and the car in front will make the car in front less important. We propose a novel framework for object importance estimation using an interaction graph, in which the features of each object node are updated by interacting with others through graph convolution. Experiments show that our model outperforms state-of-the-art baselines with much less input and pre-processing.
Learning Video Object Segmentation from Unlabeled Videos
Mar 10, 2020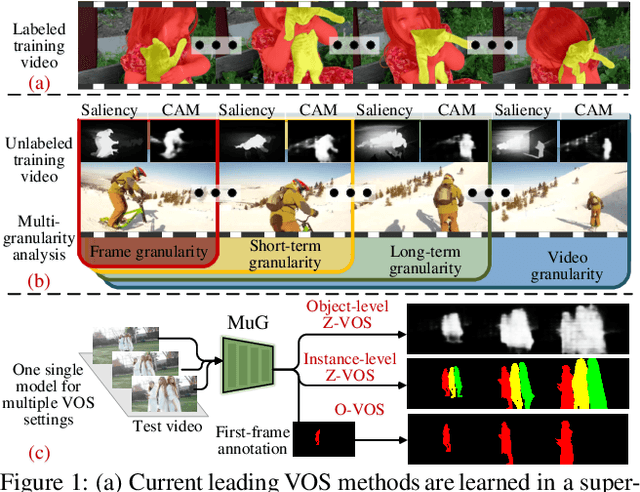
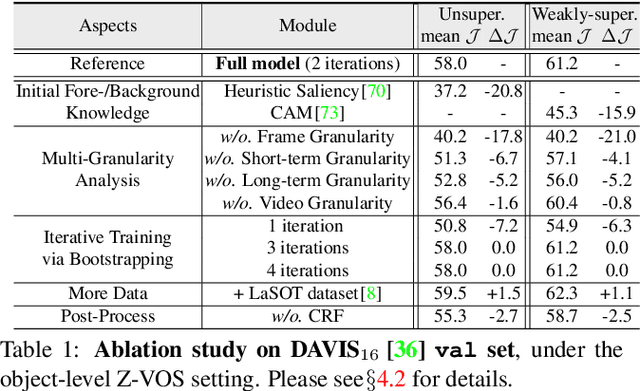
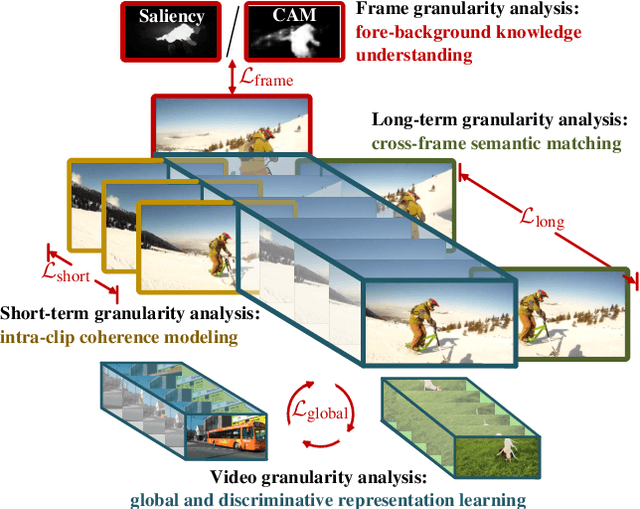

We propose a new method for video object segmentation (VOS) that addresses object pattern learning from unlabeled videos, unlike most existing methods which rely heavily on extensive annotated data. We introduce a unified unsupervised/weakly supervised learning framework, called MuG, that comprehensively captures intrinsic properties of VOS at multiple granularities. Our approach can help advance understanding of visual patterns in VOS and significantly reduce annotation burden. With a carefully-designed architecture and strong representation learning ability, our learned model can be applied to diverse VOS settings, including object-level zero-shot VOS, instance-level zero-shot VOS, and one-shot VOS. Experiments demonstrate promising performance in these settings, as well as the potential of MuG in leveraging unlabeled data to further improve the segmentation accuracy.
Zero-Shot Video Object Segmentation via Attentive Graph Neural Networks
Jan 19, 2020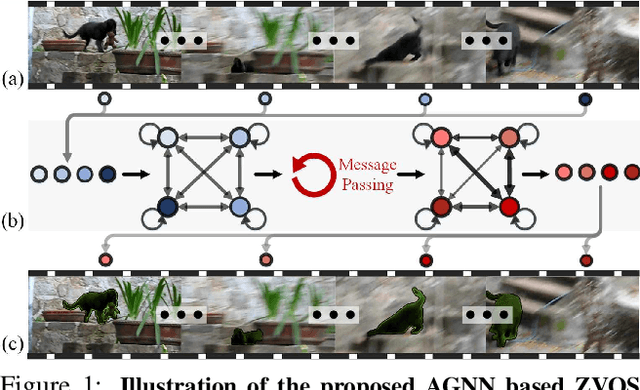

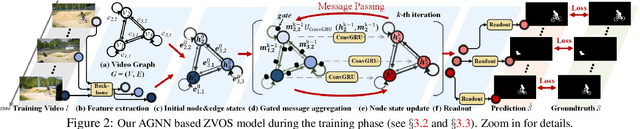
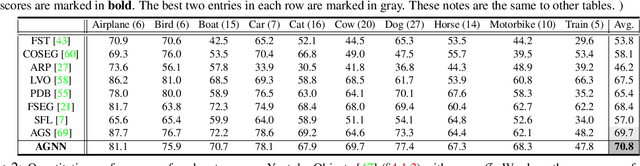
This work proposes a novel attentive graph neural network (AGNN) for zero-shot video object segmentation (ZVOS). The suggested AGNN recasts this task as a process of iterative information fusion over video graphs. Specifically, AGNN builds a fully connected graph to efficiently represent frames as nodes, and relations between arbitrary frame pairs as edges. The underlying pair-wise relations are described by a differentiable attention mechanism. Through parametric message passing, AGNN is able to efficiently capture and mine much richer and higher-order relations between video frames, thus enabling a more complete understanding of video content and more accurate foreground estimation. Experimental results on three video segmentation datasets show that AGNN sets a new state-of-the-art in each case. To further demonstrate the generalizability of our framework, we extend AGNN to an additional task: image object co-segmentation (IOCS). We perform experiments on two famous IOCS datasets and observe again the superiority of our AGNN model. The extensive experiments verify that AGNN is able to learn the underlying semantic/appearance relationships among video frames or related images, and discover the common objects.
* ICCV2019(Oral). Website: https://github.com/carrierlxk/AGNN
P-CapsNets: a General Form of Convolutional Neural Networks
Dec 18, 2019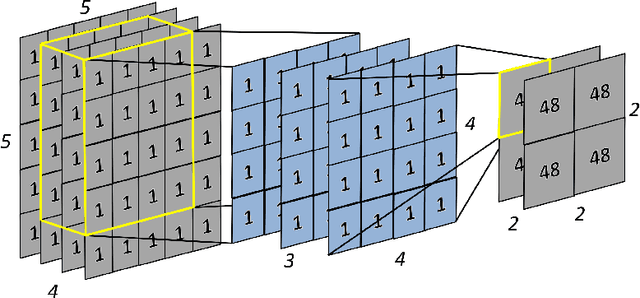
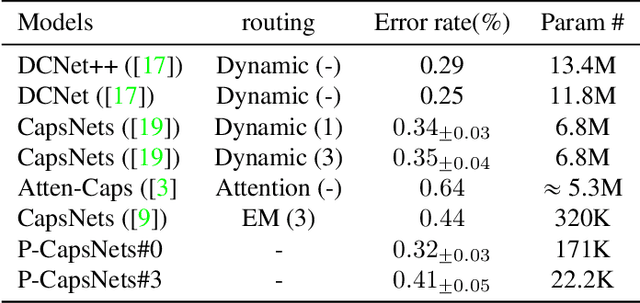
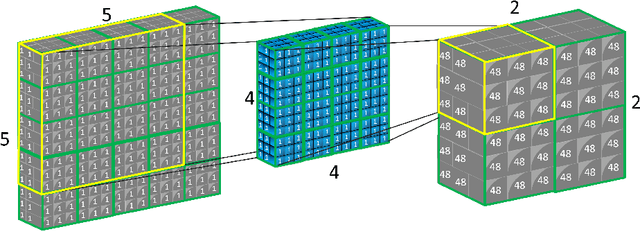
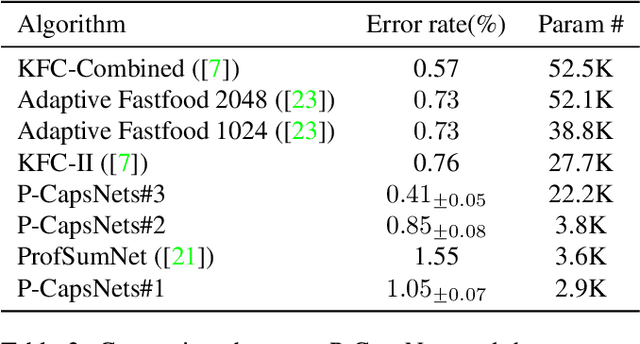
We propose Pure CapsNets (P-CapsNets) which is a generation of normal CNNs structurally. Specifically, we make three modifications to current CapsNets. First, we remove routing procedures from CapsNets based on the observation that the coupling coefficients can be learned implicitly. Second, we replace the convolutional layers in CapsNets to improve efficiency. Third, we package the capsules into rank-3 tensors to further improve efficiency. The experiment shows that P-CapsNets achieve better performance than CapsNets with varied routing procedures by using significantly fewer parameters on MNIST\&CIFAR10. The high efficiency of P-CapsNets is even comparable to some deep compressing models. For example, we achieve more than 99\% percent accuracy on MNIST by using only 3888 parameters. We visualize the capsules as well as the corresponding correlation matrix to show a possible way of initializing CapsNets in the future. We also explore the adversarial robustness of P-CapsNets compared to CNNs.
Meta-Reinforced Synthetic Data for One-Shot Fine-Grained Visual Recognition
Nov 17, 2019
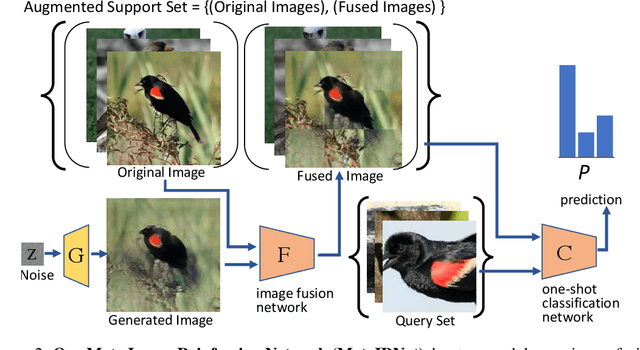
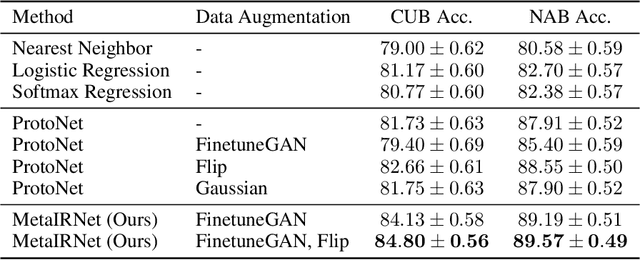
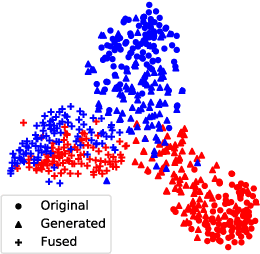
One-shot fine-grained visual recognition often suffers from the problem of training data scarcity for new fine-grained classes. To alleviate this problem, an off-the-shelf image generator can be applied to synthesize additional training images, but these synthesized images are often not helpful for actually improving the accuracy of one-shot fine-grained recognition. This paper proposes a meta-learning framework to combine generated images with original images, so that the resulting ``hybrid'' training images can improve one-shot learning. Specifically, the generic image generator is updated by a few training instances of novel classes, and a Meta Image Reinforcing Network (MetaIRNet) is proposed to conduct one-shot fine-grained recognition as well as image reinforcement. The model is trained in an end-to-end manner, and our experiments demonstrate consistent improvement over baselines on one-shot fine-grained image classification benchmarks.
A Self Validation Network for Object-Level Human Attention Estimation
Oct 31, 2019
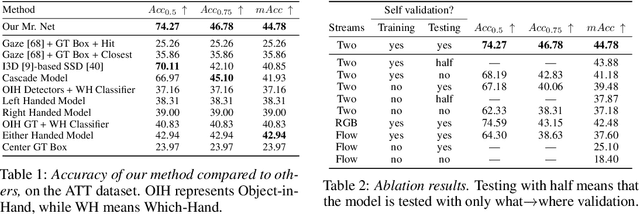
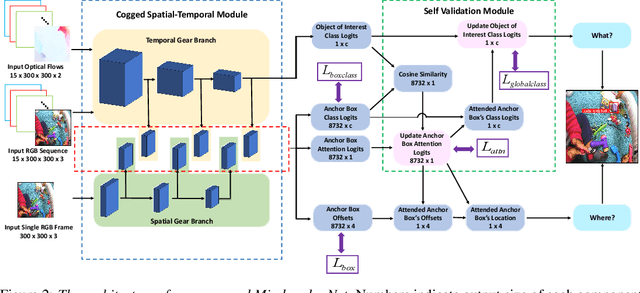

Due to the foveated nature of the human vision system, people can focus their visual attention on a small region of their visual field at a time, which usually contains only a single object. Estimating this object of attention in first-person (egocentric) videos is useful for many human-centered real-world applications such as augmented reality applications and driver assistance systems. A straightforward solution for this problem is to pick the object whose bounding box is hit by the gaze, where eye gaze point estimation is obtained from a traditional eye gaze estimator and object candidates are generated from an off-the-shelf object detector. However, such an approach can fail because it addresses the where and the what problems separately, despite that they are highly related, chicken-and-egg problems. In this paper, we propose a novel unified model that incorporates both spatial and temporal evidence in identifying as well as locating the attended object in firstperson videos. It introduces a novel Self Validation Module that enforces and leverages consistency of the where and the what concepts. We evaluate on two public datasets, demonstrating that Self Validation Module significantly benefits both training and testing and that our model outperforms the state-of-the-art.
Active Object Manipulation Facilitates Visual Object Learning: An Egocentric Vision Study
Jun 04, 2019Inspired by the remarkable ability of the infant visual learning system, a recent study collected first-person images from children to analyze the `training data' that they receive. We conduct a follow-up study that investigates two additional directions. First, given that infants can quickly learn to recognize a new object without much supervision (i.e. few-shot learning), we limit the number of training images. Second, we investigate how children control the supervision signals they receive during learning based on hand manipulation of objects. Our experimental results suggest that supervision with hand manipulation is better than without hands, and the trend is consistent even when a small number of images is available.
Embodied Visual Recognition
Apr 09, 2019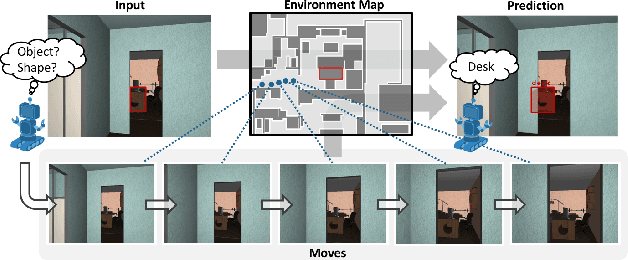
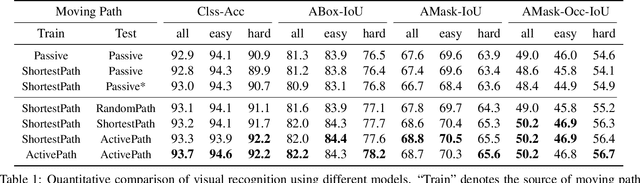
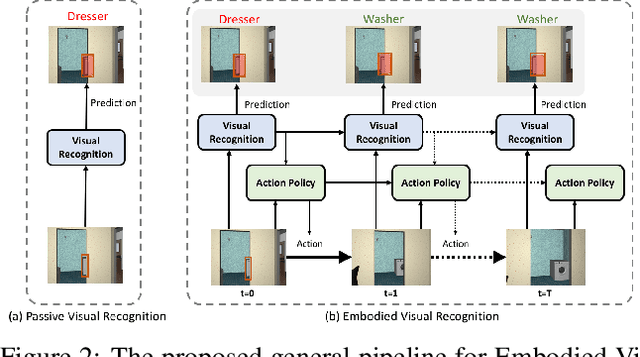
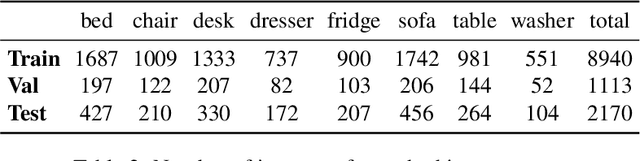
Passive visual systems typically fail to recognize objects in the amodal setting where they are heavily occluded. In contrast, humans and other embodied agents have the ability to move in the environment, and actively control the viewing angle to better understand object shapes and semantics. In this work, we introduce the task of Embodied Visual Recognition (EVR): An agent is instantiated in a 3D environment close to an occluded target object, and is free to move in the environment to perform object classification, amodal object localization, and amodal object segmentation. To address this, we develop a new model called Embodied Mask R-CNN, for agents to learn to move strategically to improve their visual recognition abilities. We conduct experiments using the House3D environment. Experimental results show that: 1) agents with embodiment (movement) achieve better visual recognition performance than passive ones; 2) in order to improve visual recognition abilities, agents can learn strategical moving paths that are different from shortest paths.
Unsupervised Domain Adaptation using Generative Models and Self-ensembling
Dec 02, 2018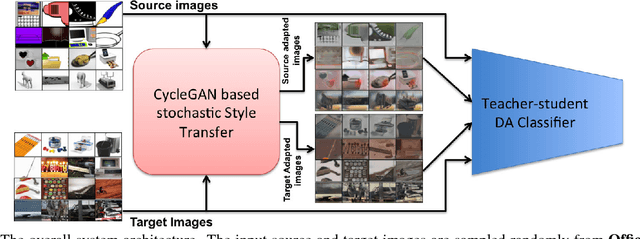

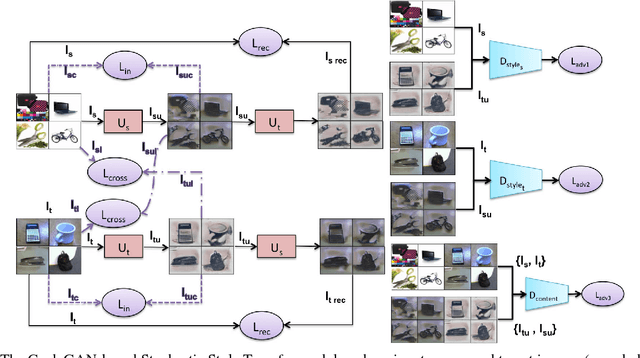

Transferring knowledge across different datasets is an important approach to successfully train deep models with a small-scale target dataset or when few labeled instances are available. In this paper, we aim at developing a model that can generalize across multiple domain shifts, so that this model can adapt from a single source to multiple targets. This can be achieved by randomizing the generation of the data of various styles to mitigate the domain mismatch. First, we present a new adaptation to the CycleGAN model to produce stochastic style transfer between two image batches of different domains. Second, we enhance the classifier performance by using a self-ensembling technique with a teacher and student model to train on both original and generated data. Finally, we present experimental results on three datasets Office-31, Office-Home, and Visual Domain adaptation. The results suggest that selfensembling is better than simple data augmentation with the newly generated data and a single model trained this way can have the best performance across all different transfer tasks.
Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models
Oct 22, 2018
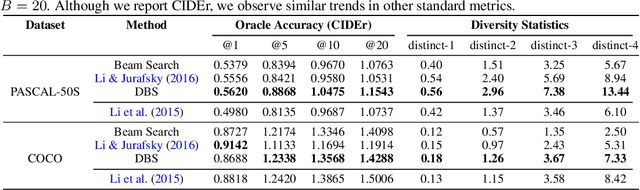
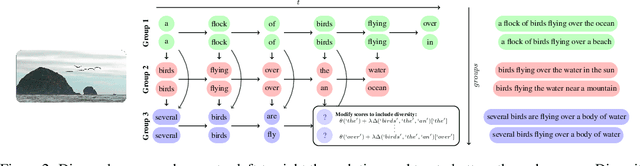
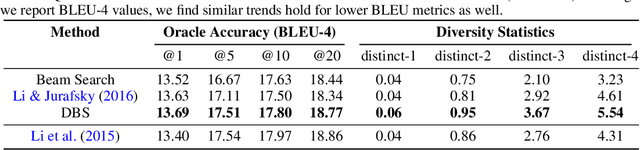
Neural sequence models are widely used to model time-series data. Equally ubiquitous is the usage of beam search (BS) as an approximate inference algorithm to decode output sequences from these models. BS explores the search space in a greedy left-right fashion retaining only the top-B candidates - resulting in sequences that differ only slightly from each other. Producing lists of nearly identical sequences is not only computationally wasteful but also typically fails to capture the inherent ambiguity of complex AI tasks. To overcome this problem, we propose Diverse Beam Search (DBS), an alternative to BS that decodes a list of diverse outputs by optimizing for a diversity-augmented objective. We observe that our method finds better top-1 solutions by controlling for the exploration and exploitation of the search space - implying that DBS is a better search algorithm. Moreover, these gains are achieved with minimal computational or memory over- head as compared to beam search. To demonstrate the broad applicability of our method, we present results on image captioning, machine translation and visual question generation using both standard quantitative metrics and qualitative human studies. Further, we study the role of diversity for image-grounded language generation tasks as the complexity of the image changes. We observe that our method consistently outperforms BS and previously proposed techniques for diverse decoding from neural sequence models.