 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering and Achieving Goals via World Models
Oct 18, 2021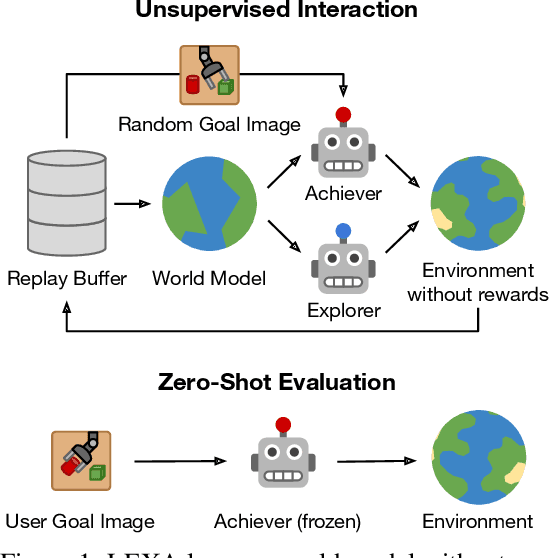
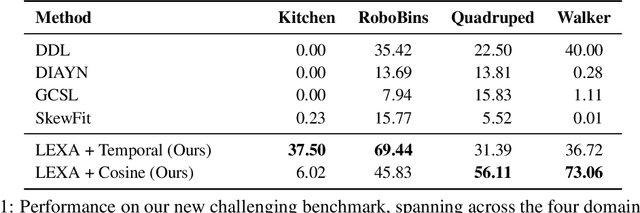
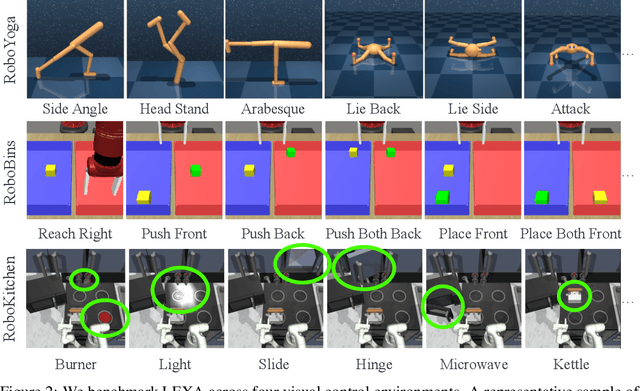
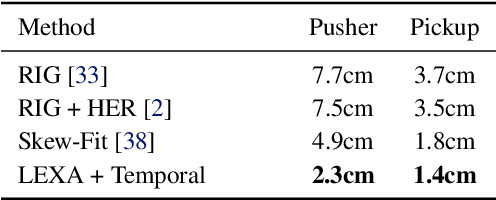
How can artificial agents learn to solve many diverse tasks in complex visual environments in the absence of any supervision? We decompose this question into two problems: discovering new goals and learning to reliably achieve them. We introduce Latent Explorer Achiever (LEXA), a unified solution to these that learns a world model from image inputs and uses it to train an explorer and an achiever policy from imagined rollouts. Unlike prior methods that explore by reaching previously visited states, the explorer plans to discover unseen surprising states through foresight, which are then used as diverse targets for the achiever to practice. After the unsupervised phase, LEXA solves tasks specified as goal images zero-shot without any additional learning. LEXA substantially outperforms previous approaches to unsupervised goal-reaching, both on prior benchmarks and on a new challenging benchmark with a total of 40 test tasks spanning across four standard robotic manipulation and locomotion domains. LEXA further achieves goals that require interacting with multiple objects in sequence. Finally, to demonstrate the scalability and generality of LEXA, we train a single general agent across four distinct environments. Code and videos at https://orybkin.github.io/lexa/
Benchmarking the Spectrum of Agent Capabilities
Sep 14, 2021
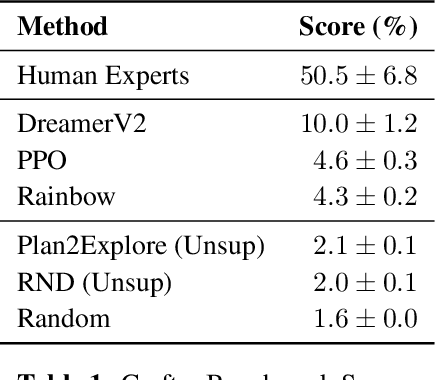

Evaluating the general abilities of intelligent agents requires complex simulation environments. Existing benchmarks typically evaluate only one narrow task per environment, requiring researchers to perform expensive training runs on many different environments. We introduce Crafter, an open world survival game with visual inputs that evaluates a wide range of general abilities within a single environment. Agents either learn from the provided reward signal or through intrinsic objectives and are evaluated by semantically meaningful achievements that can be unlocked during each episode, such as discovering resources and crafting tools. Consistently unlocking all achievements requires strong generalization, deep exploration, and long-term reasoning. We experimentally verify that Crafter is of appropriate difficulty to drive future research and provide baselines scores of reward agents and unsupervised agents. Furthermore, we observe sophisticated behaviors emerging from maximizing the reward signal, such as building tunnel systems, bridges, houses, and plantations. We hope that Crafter will accelerate research progress by quickly evaluating a wide spectrum of abilities.
Clockwork Variational Autoencoders
Feb 20, 2021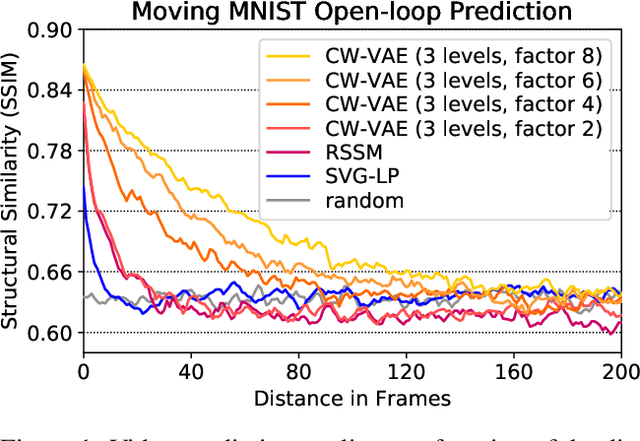
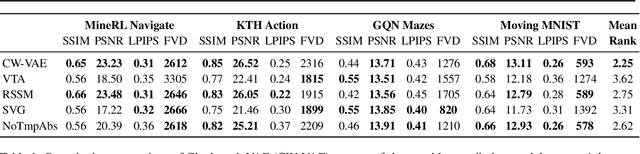
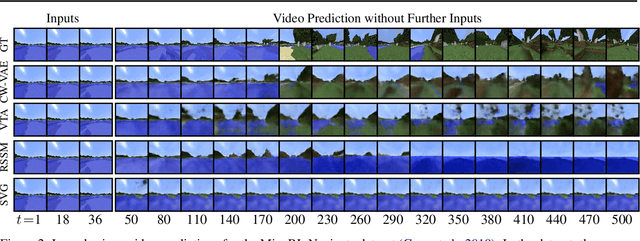
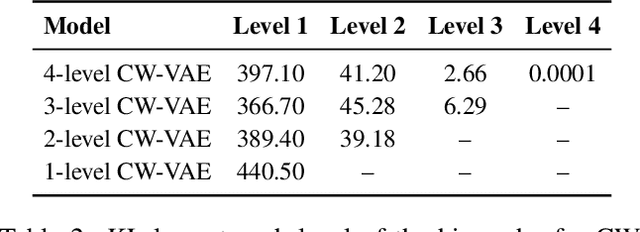
Deep learning has enabled algorithms to generate realistic images. However, accurately predicting long video sequences requires understanding long-term dependencies and remains an open challenge. While existing video prediction models succeed at generating sharp images, they tend to fail at accurately predicting far into the future. We introduce the Clockwork VAE (CW-VAE), a video prediction model that leverages a hierarchy of latent sequences, where higher levels tick at slower intervals. We demonstrate the benefits of both hierarchical latents and temporal abstraction on 4 diverse video prediction datasets with sequences of up to 1000 frames, where CW-VAE outperforms top video prediction models. Additionally, we propose a Minecraft benchmark for long-term video prediction. We conduct several experiments to gain insights into CW-VAE and confirm that slower levels learn to represent objects that change more slowly in the video, and faster levels learn to represent faster objects.
Evaluating Agents without Rewards
Dec 21, 2020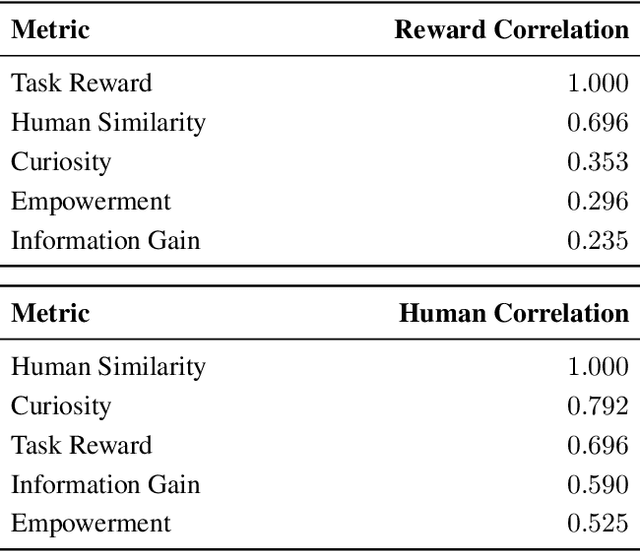
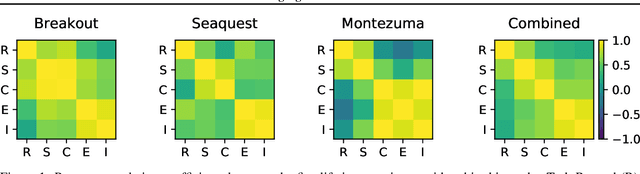
Reinforcement learning has enabled agents to solve challenging tasks in unknown environments. However, manually crafting reward functions can be time consuming, expensive, and error prone to human error. Competing objectives have been proposed for agents to learn without external supervision, but it has been unclear how well they reflect task rewards or human behavior. To accelerate the development of intrinsic objectives, we retrospectively compute potential objectives on pre-collected datasets of agent behavior, rather than optimizing them online, and compare them by analyzing their correlations. We study input entropy, information gain, and empowerment across seven agents, three Atari games, and the 3D game Minecraft. We find that all three intrinsic objectives correlate more strongly with a human behavior similarity metric than with task reward. Moreover, input entropy and information gain correlate more strongly with human similarity than task reward does, suggesting the use of intrinsic objectives for designing agents that behave similarly to human players.
Models, Pixels, and Rewards: Evaluating Design Trade-offs in Visual Model-Based Reinforcement Learning
Dec 08, 2020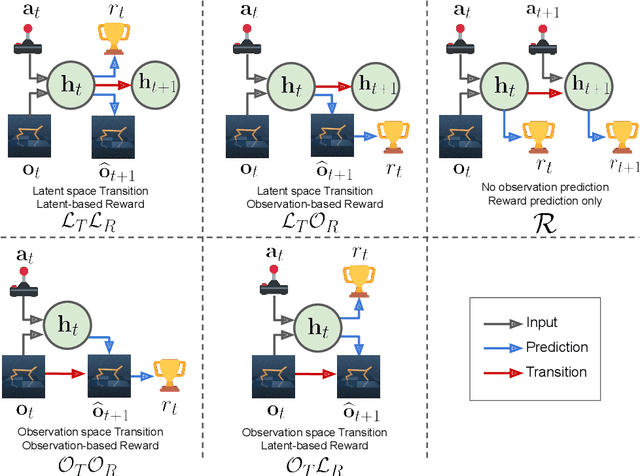

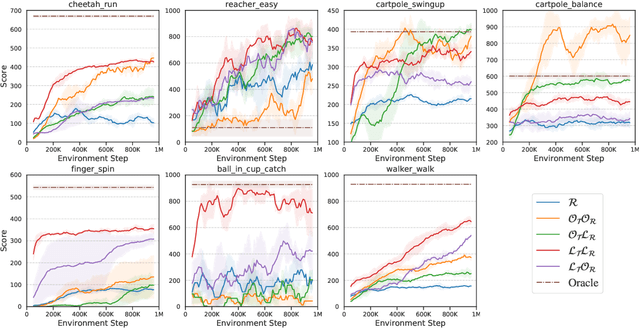
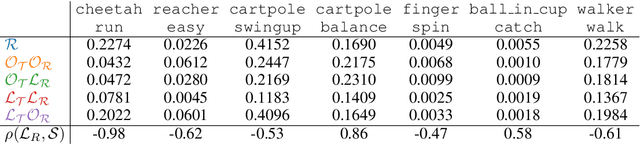
Model-based reinforcement learning (MBRL) methods have shown strong sample efficiency and performance across a variety of tasks, including when faced with high-dimensional visual observations. These methods learn to predict the environment dynamics and expected reward from interaction and use this predictive model to plan and perform the task. However, MBRL methods vary in their fundamental design choices, and there is no strong consensus in the literature on how these design decisions affect performance. In this paper, we study a number of design decisions for the predictive model in visual MBRL algorithms, focusing specifically on methods that use a predictive model for planning. We find that a range of design decisions that are often considered crucial, such as the use of latent spaces, have little effect on task performance. A big exception to this finding is that predicting future observations (i.e., images) leads to significant task performance improvement compared to only predicting rewards. We also empirically find that image prediction accuracy, somewhat surprisingly, correlates more strongly with downstream task performance than reward prediction accuracy. We show how this phenomenon is related to exploration and how some of the lower-scoring models on standard benchmarks (that require exploration) will perform the same as the best-performing models when trained on the same training data. Simultaneously, in the absence of exploration, models that fit the data better usually perform better on the downstream task as well, but surprisingly, these are often not the same models that perform the best when learning and exploring from scratch. These findings suggest that performance and exploration place important and potentially contradictory requirements on the model.
Skill Transfer via Partially Amortized Hierarchical Planning
Nov 27, 2020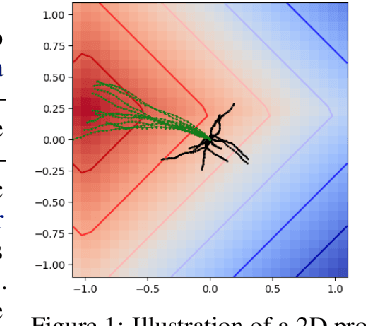
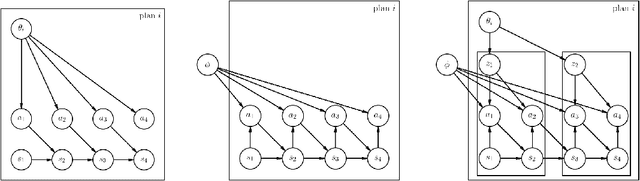
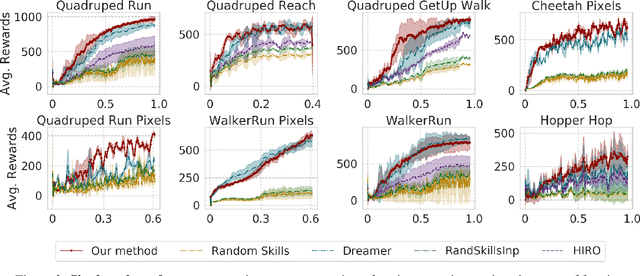
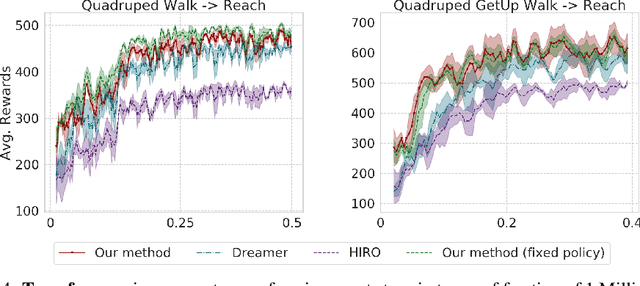
To quickly solve new tasks in complex environments, intelligent agents need to build up reusable knowledge. For example, a learned world model captures knowledge about the environment that applies to new tasks. Similarly, skills capture general behaviors that can apply to new tasks. In this paper, we investigate how these two approaches can be integrated into a single reinforcement learning agent. Specifically, we leverage the idea of partial amortization for fast adaptation at test time. For this, actions are produced by a policy that is learned over time while the skills it conditions on are chosen using online planning. We demonstrate the benefits of our design decisions across a suite of challenging locomotion tasks and demonstrate improved sample efficiency in single tasks as well as in transfer from one task to another, as compared to competitive baselines. Videos are available at: https://sites.google.com/view/partial-amortization-hierarchy/home
Mastering Atari with Discrete World Models
Oct 05, 2020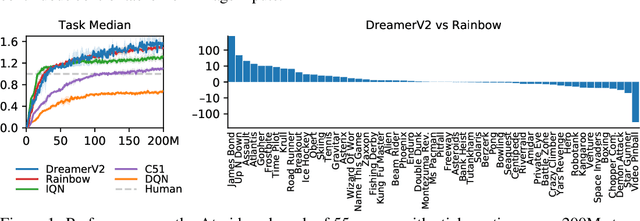
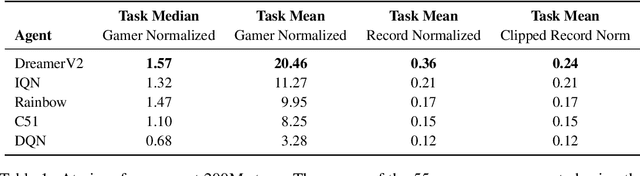
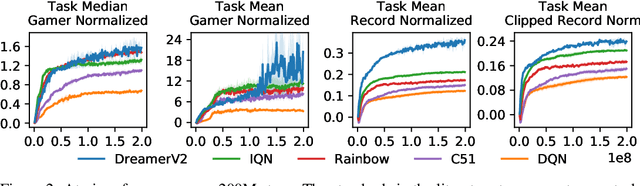

Intelligent agents need to generalize from past experience to achieve goals in complex environments. World models facilitate such generalization and allow learning behaviors from imagined outcomes to increase sample-efficiency. While learning world models from image inputs has recently become feasible for some tasks, modeling Atari games accurately enough to derive successful behaviors has remained an open challenge for many years. We introduce DreamerV2, a reinforcement learning agent that learns behaviors purely from predictions in the compact latent space of a powerful world model. The world model uses discrete representations and is trained separately from the policy. DreamerV2 constitutes the first agent that achieves human-level performance on the Atari benchmark of 55 tasks by learning behaviors inside a separately trained world model. With the same computational budget and wall-clock time, DreamerV2 reaches 200M frames and exceeds the final performance of the top single-GPU agents IQN and Rainbow.
Action and Perception as Divergence Minimization
Oct 05, 2020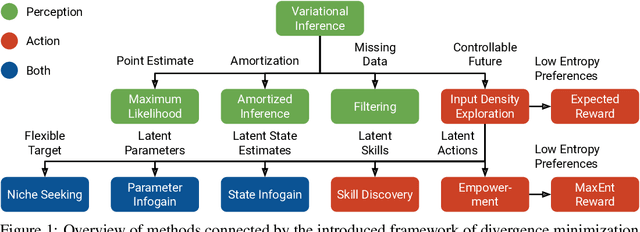
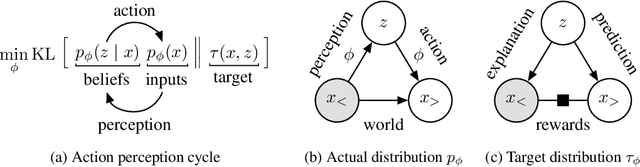
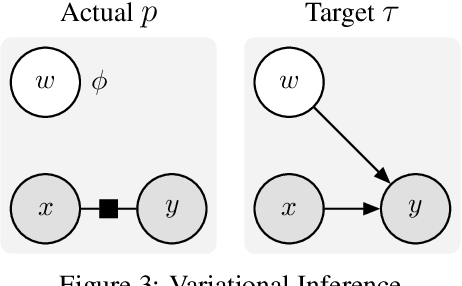
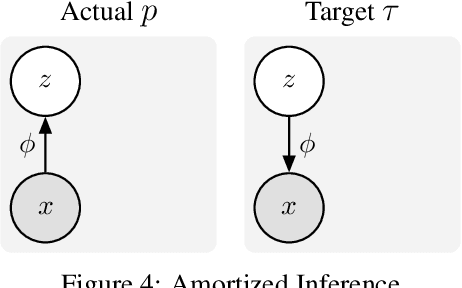
We introduce a unified objective for action and perception of intelligent agents. Extending representation learning and control, we minimize the joint divergence between the combined system of agent and environment and a target distribution. Intuitively, such agents use perception to align their beliefs with the world, and use actions to align the world with their beliefs. Minimizing the joint divergence to an expressive target maximizes the mutual information between the agent's representations and inputs, thus inferring representations that are informative of past inputs and exploring future inputs that are informative of the representations. This lets us explain intrinsic objectives, such as representation learning, information gain, empowerment, and skill discovery from minimal assumptions. Moreover, interpreting the target distribution as a latent variable model suggests powerful world models as a path toward highly adaptive agents that seek large niches in their environments, rendering task rewards optional. The framework provides a common language for comparing a wide range of objectives, advances the understanding of latent variables for decision making, and offers a recipe for designing novel objectives. We recommend deriving future agent objectives the joint divergence to facilitate comparison, to point out the agent's target distribution, and to identify the intrinsic objective terms needed to reach that distribution.
Sophisticated Inference
Jun 07, 2020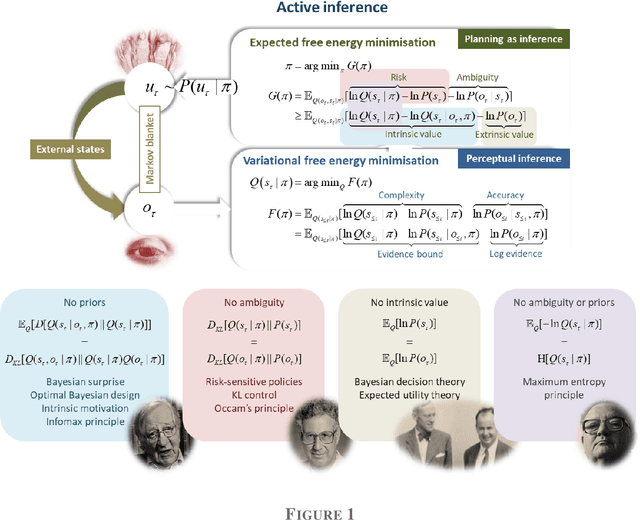
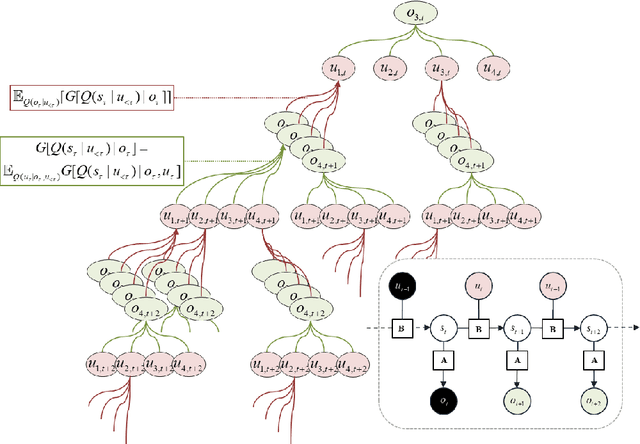
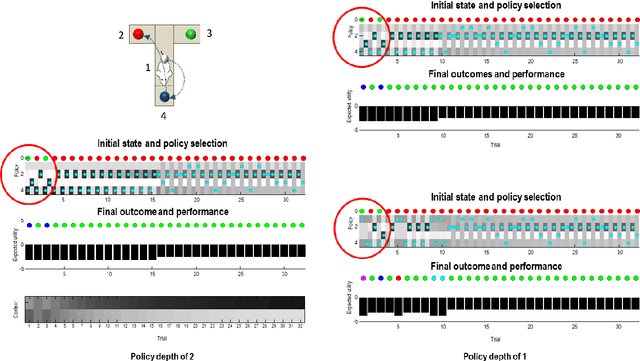
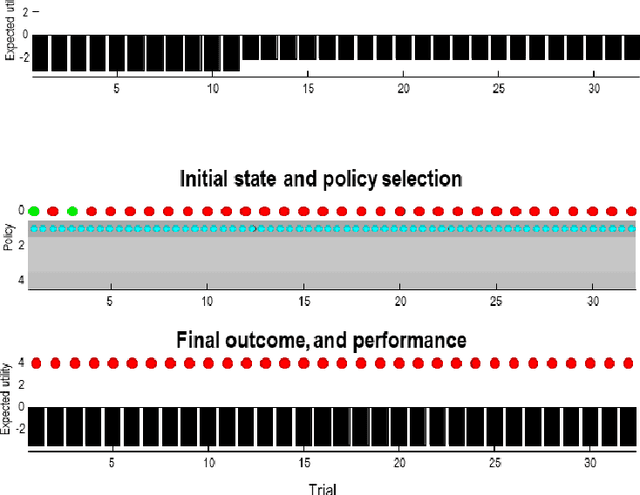
Active inference offers a first principle account of sentient behaviour, from which special and important cases can be derived, e.g., reinforcement learning, active learning, Bayes optimal inference, Bayes optimal design, etc. Active inference resolves the exploitation-exploration dilemma in relation to prior preferences, by placing information gain on the same footing as reward or value. In brief, active inference replaces value functions with functionals of (Bayesian) beliefs, in the form of an expected (variational) free energy. In this paper, we consider a sophisticated kind of active inference, using a recursive form of expected free energy. Sophistication describes the degree to which an agent has beliefs about beliefs. We consider agents with beliefs about the counterfactual consequences of action for states of affairs and beliefs about those latent states. In other words, we move from simply considering beliefs about 'what would happen if I did that' to 'what would I believe about what would happen if I did that'. The recursive form of the free energy functional effectively implements a deep tree search over actions and outcomes in the future. Crucially, this search is over sequences of belief states, as opposed to states per se. We illustrate the competence of this scheme, using numerical simulations of deep decision problems.
Planning to Explore via Self-Supervised World Models
May 12, 2020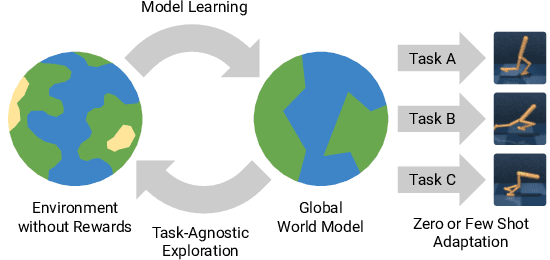
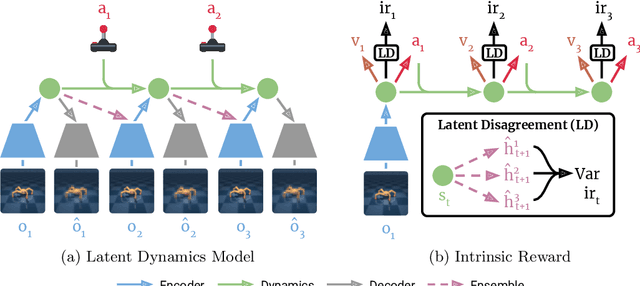
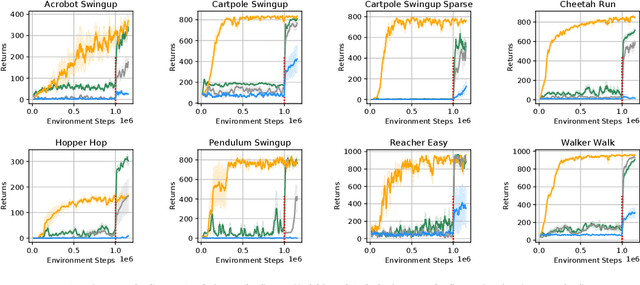
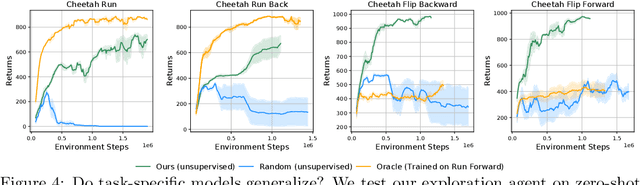
Reinforcement learning allows solving complex tasks, however, the learning tends to be task-specific and the sample efficiency remains a challenge. We present Plan2Explore, a self-supervised reinforcement learning agent that tackles both these challenges through a new approach to self-supervised exploration and fast adaptation to new tasks, which need not be known during exploration. During exploration, unlike prior methods which retrospectively compute the novelty of observations after the agent has already reached them, our agent acts efficiently by leveraging planning to seek out expected future novelty. After exploration, the agent quickly adapts to multiple downstream tasks in a zero or a few-shot manner. We evaluate on challenging control tasks from high-dimensional image inputs. Without any training supervision or task-specific interaction, Plan2Explore outperforms prior self-supervised exploration methods, and in fact, almost matches the performances oracle which has access to rewards. Videos and code at https://ramanans1.github.io/plan2explore/