 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodiedRAG: Dynamic 3D Scene Graph Retrieval for Efficient and Scalable Robot Task Planning
Oct 31, 2024



Recent advances in Large Language Models (LLMs) have helped facilitate exciting progress for robotic planning in real, open-world environments. 3D scene graphs (3DSGs) offer a promising environment representation for grounding such LLM-based planners as they are compact and semantically rich. However, as the robot's environment scales (e.g., number of entities tracked) and the complexity of scene graph information increases (e.g., maintaining more attributes), providing the 3DSG as-is to an LLM-based planner quickly becomes infeasible due to input token count limits and attentional biases present in LLMs. Inspired by the successes of Retrieval-Augmented Generation (RAG) methods that retrieve query-relevant document chunks for LLM question and answering, we adapt the paradigm for our embodied domain. Specifically, we propose a 3D scene subgraph retrieval framework, called EmbodiedRAG, that we augment an LLM-based planner with for executing natural language robotic tasks. Notably, our retrieved subgraphs adapt to changes in the environment as well as changes in task-relevancy as the robot executes its plan. We demonstrate EmbodiedRAG's ability to significantly reduce input token counts (by an order of magnitude) and planning time (up to 70% reduction in average time per planning step) while improving success rates on AI2Thor simulated household tasks with a single-arm, mobile manipulator. Additionally, we implement EmbodiedRAG on a quadruped with a manipulator to highlight the performance benefits for robot deployment at the edge in real environments.
ConceptAgent: LLM-Driven Precondition Grounding and Tree Search for Robust Task Planning and Execution
Oct 08, 2024



Robotic planning and execution in open-world environments is a complex problem due to the vast state spaces and high variability of task embodiment. Recent advances in perception algorithms, combined with Large Language Models (LLMs) for planning, offer promising solutions to these challenges, as the common sense reasoning capabilities of LLMs provide a strong heuristic for efficiently searching the action space. However, prior work fails to address the possibility of hallucinations from LLMs, which results in failures to execute the planned actions largely due to logical fallacies at high- or low-levels. To contend with automation failure due to such hallucinations, we introduce ConceptAgent, a natural language-driven robotic platform designed for task execution in unstructured environments. With a focus on scalability and reliability of LLM-based planning in complex state and action spaces, we present innovations designed to limit these shortcomings, including 1) Predicate Grounding to prevent and recover from infeasible actions, and 2) an embodied version of LLM-guided Monte Carlo Tree Search with self reflection. In simulation experiments, ConceptAgent achieved a 19% task completion rate across three room layouts and 30 easy level embodied tasks outperforming other state-of-the-art LLM-driven reasoning baselines that scored 10.26% and 8.11% on the same benchmark. Additionally, ablation studies on moderate to hard embodied tasks revealed a 20% increase in task completion from the baseline agent to the fully enhanced ConceptAgent, highlighting the individual and combined contributions of Predicate Grounding and LLM-guided Tree Search to enable more robust automation in complex state and action spaces.
Perceive With Confidence: Statistical Safety Assurances for Navigation with Learning-Based Perception
Mar 13, 2024



Rapid advances in perception have enabled large pre-trained models to be used out of the box for processing high-dimensional, noisy, and partial observations of the world into rich geometric representations (e.g., occupancy predictions). However, safe integration of these models onto robots remains challenging due to a lack of reliable performance in unfamiliar environments. In this work, we present a framework for rigorously quantifying the uncertainty of pre-trained perception models for occupancy prediction in order to provide end-to-end statistical safety assurances for navigation. We build on techniques from conformal prediction for producing a calibrated perception system that lightly processes the outputs of a pre-trained model while ensuring generalization to novel environments and robustness to distribution shifts in states when perceptual outputs are used in conjunction with a planner. The calibrated system can be used in combination with any safe planner to provide an end-to-end statistical assurance on safety in a new environment with a user-specified threshold $1-\epsilon$. We evaluate the resulting approach - which we refer to as Perceive with Confidence (PwC) - with experiments in simulation and on hardware where a quadruped robot navigates through indoor environments containing objects unseen during training or calibration. These experiments validate the safety assurances provided by PwC and demonstrate significant improvements in empirical safety rates compared to baselines.
Online Learning for Obstacle Avoidance
Jun 14, 2023



We approach the fundamental problem of obstacle avoidance for robotic systems via the lens of online learning. In contrast to prior work that either assumes worst-case realizations of uncertainty in the environment or a stationary stochastic model of uncertainty, we propose a method that is efficient to implement and provably grants instance-optimality with respect to perturbations of trajectories generated from an open-loop planner (in the sense of minimizing worst-case regret). The resulting policy adapts online to realizations of uncertainty and provably compares well with the best obstacle avoidance policy in hindsight from a rich class of policies. The method is validated in simulation on a dynamical system environment and compared to baseline open-loop planning and robust Hamilton- Jacobi reachability techniques. Further, it is implemented on a hardware example where a quadruped robot traverses a dense obstacle field and encounters input disturbances due to time delays, model uncertainty, and dynamics nonlinearities.
Switching Attention in Time-Varying Environments via Bayesian Inference of Abstractions
Nov 10, 2022



Motivated by the goal of endowing robots with a means for focusing attention in order to operate reliably in complex, uncertain, and time-varying environments, we consider how a robot can (i) determine which portions of its environment to pay attention to at any given point in time, (ii) infer changes in context (e.g., task or environment dynamics), and (iii) switch its attention accordingly. In this work, we tackle these questions by modeling context switches in a time-varying Markov decision process (MDP) framework. We utilize the theory of bisimulation-based state abstractions in order to synthesize mechanisms for paying attention to context-relevant information. We then present an algorithm based on Bayesian inference for detecting changes in the robot's context (task or environment dynamics) as it operates online, and use this to trigger switches between different abstraction-based attention mechanisms. Our approach is demonstrated on two examples: (i) an illustrative discrete-state tracking problem, and (ii) a continuous-state tracking problem implemented on a quadrupedal hardware platform. These examples demonstrate the ability of our approach to detect context switches online and robustly ignore task-irrelevant distractors by paying attention to context-relevant information.
Learning to Actively Reduce Memory Requirements for Robot Control Tasks
Aug 17, 2020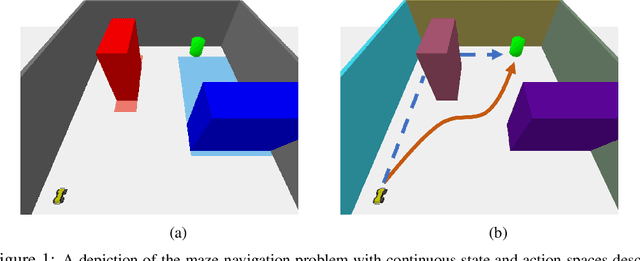
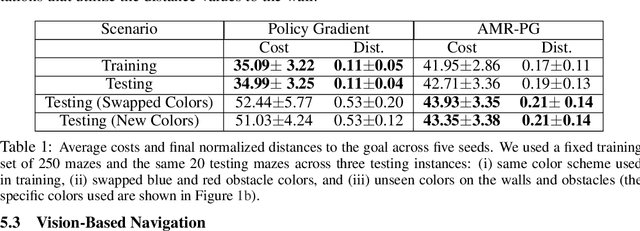
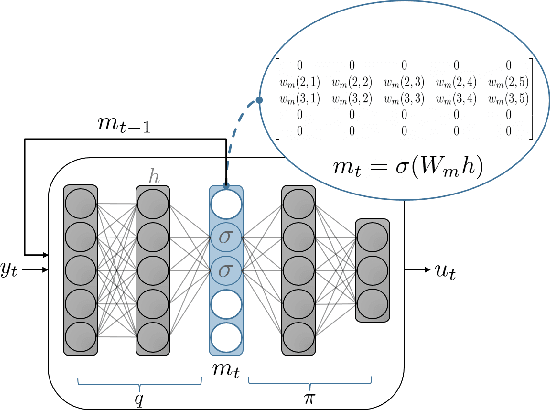
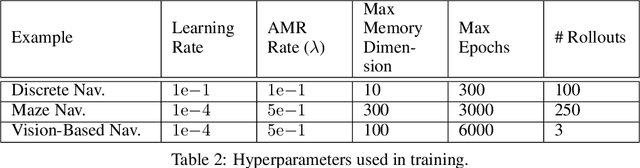
Robots equipped with rich sensing modalities (e.g., RGB-D cameras) performing long-horizon tasks motivate the need for policies that are highly memory-efficient. State-of-the-art approaches for controlling robots often use memory representations that are excessively rich for the task or rely on hand-crafted tricks for memory efficiency. Instead, this work provides a general approach for jointly synthesizing memory representations and policies; the resulting policies actively seek to reduce memory requirements (i.e., take actions that reduce memory usage). Specifically, we present a reinforcement learning framework that leverages an implementation of the group LASSO regularization to synthesize policies that employ low-dimensional and task-centric memory representations. We demonstrate the efficacy of our approach with simulated examples including navigation in discrete and continuous spaces as well as vision-based indoor navigation set in a photo-realistic simulator. The results on these examples indicate that our method is capable of finding policies that rely only on low-dimensional memory representations and actively reduce memory requirements.