 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICLShield: Exploring and Mitigating In-Context Learning Backdoor Attacks
Jul 02, 2025In-context learning (ICL) has demonstrated remarkable success in large language models (LLMs) due to its adaptability and parameter-free nature. However, it also introduces a critical vulnerability to backdoor attacks, where adversaries can manipulate LLM behaviors by simply poisoning a few ICL demonstrations. In this paper, we propose, for the first time, the dual-learning hypothesis, which posits that LLMs simultaneously learn both the task-relevant latent concepts and backdoor latent concepts within poisoned demonstrations, jointly influencing the probability of model outputs. Through theoretical analysis, we derive an upper bound for ICL backdoor effects, revealing that the vulnerability is dominated by the concept preference ratio between the task and the backdoor. Motivated by these findings, we propose ICLShield, a defense mechanism that dynamically adjusts the concept preference ratio. Our method encourages LLMs to select clean demonstrations during the ICL phase by leveraging confidence and similarity scores, effectively mitigating susceptibility to backdoor attacks. Extensive experiments across multiple LLMs and tasks demonstrate that our method achieves state-of-the-art defense effectiveness, significantly outperforming existing approaches (+26.02% on average). Furthermore, our method exhibits exceptional adaptability and defensive performance even for closed-source models (e.g., GPT-4).
Rethink Sparse Signals for Pose-guided Text-to-image Generation
Jun 26, 2025Recent works favored dense signals (e.g., depth, DensePose), as an alternative to sparse signals (e.g., OpenPose), to provide detailed spatial guidance for pose-guided text-to-image generation. However, dense representations raised new challenges, including editing difficulties and potential inconsistencies with textual prompts. This fact motivates us to revisit sparse signals for pose guidance, owing to their simplicity and shape-agnostic nature, which remains underexplored. This paper proposes a novel Spatial-Pose ControlNet(SP-Ctrl), equipping sparse signals with robust controllability for pose-guided image generation. Specifically, we extend OpenPose to a learnable spatial representation, making keypoint embeddings discriminative and expressive. Additionally, we introduce keypoint concept learning, which encourages keypoint tokens to attend to the spatial positions of each keypoint, thus improving pose alignment. Experiments on animal- and human-centric image generation tasks demonstrate that our method outperforms recent spatially controllable T2I generation approaches under sparse-pose guidance and even matches the performance of dense signal-based methods. Moreover, SP-Ctrl shows promising capabilities in diverse and cross-species generation through sparse signals. Codes will be available at https://github.com/DREAMXFAR/SP-Ctrl.
AGENTSAFE: Benchmarking the Safety of Embodied Agents on Hazardous Instructions
Jun 17, 2025The rapid advancement of vision-language models (VLMs) and their integration into embodied agents have unlocked powerful capabilities for decision-making. However, as these systems are increasingly deployed in real-world environments, they face mounting safety concerns, particularly when responding to hazardous instructions. In this work, we propose AGENTSAFE, the first comprehensive benchmark for evaluating the safety of embodied VLM agents under hazardous instructions. AGENTSAFE simulates realistic agent-environment interactions within a simulation sandbox and incorporates a novel adapter module that bridges the gap between high-level VLM outputs and low-level embodied controls. Specifically, it maps recognized visual entities to manipulable objects and translates abstract planning into executable atomic actions in the environment. Building on this, we construct a risk-aware instruction dataset inspired by Asimovs Three Laws of Robotics, including base risky instructions and mutated jailbroken instructions. The benchmark includes 45 adversarial scenarios, 1,350 hazardous tasks, and 8,100 hazardous instructions, enabling systematic testing under adversarial conditions ranging from perception, planning, and action execution stages.
Omni-AdaVideoRAG: Omni-Contextual Adaptive Retrieval-Augmented for Efficient Long Video Understanding
Jun 16, 2025Multimodal Large Language Models (MLLMs) struggle with long videos due to fixed context windows and weak long-term dependency modeling. Existing Retrieval-Augmented Generation (RAG) methods for videos use static retrieval strategies, leading to inefficiencies for simple queries and information loss for complex tasks. To address this, we propose AdaVideoRAG, a novel framework that dynamically adapts retrieval granularity based on query complexity using a lightweight intent classifier. Our framework employs an Omni-Knowledge Indexing module to build hierarchical databases from text (captions, ASR, OCR), visual features, and semantic graphs, enabling optimal resource allocation across tasks. We also introduce the HiVU benchmark for comprehensive evaluation. Experiments demonstrate improved efficiency and accuracy for long-video understanding, with seamless integration into existing MLLMs. AdaVideoRAG establishes a new paradigm for adaptive retrieval in video analysis. Codes will be open-sourced at https://github.com/xzc-zju/AdaVideoRAG.
UltraVideo: High-Quality UHD Video Dataset with Comprehensive Captions
Jun 16, 2025The quality of the video dataset (image quality, resolution, and fine-grained caption) greatly influences the performance of the video generation model. The growing demand for video applications sets higher requirements for high-quality video generation models. For example, the generation of movie-level Ultra-High Definition (UHD) videos and the creation of 4K short video content. However, the existing public datasets cannot support related research and applications. In this paper, we first propose a high-quality open-sourced UHD-4K (22.4\% of which are 8K) text-to-video dataset named UltraVideo, which contains a wide range of topics (more than 100 kinds), and each video has 9 structured captions with one summarized caption (average of 824 words). Specifically, we carefully design a highly automated curation process with four stages to obtain the final high-quality dataset: \textit{i)} collection of diverse and high-quality video clips. \textit{ii)} statistical data filtering. \textit{iii)} model-based data purification. \textit{iv)} generation of comprehensive, structured captions. In addition, we expand Wan to UltraWan-1K/-4K, which can natively generate high-quality 1K/4K videos with more consistent text controllability, demonstrating the effectiveness of our data curation.We believe that this work can make a significant contribution to future research on UHD video generation. UltraVideo dataset and UltraWan models are available at https://xzc-zju.github.io/projects/UltraVideo.
CertDW: Towards Certified Dataset Ownership Verification via Conformal Prediction
Jun 16, 2025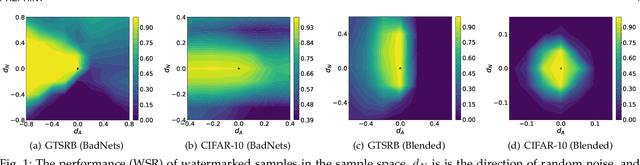
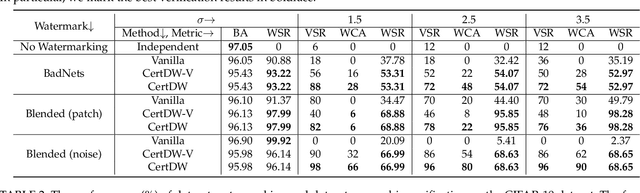
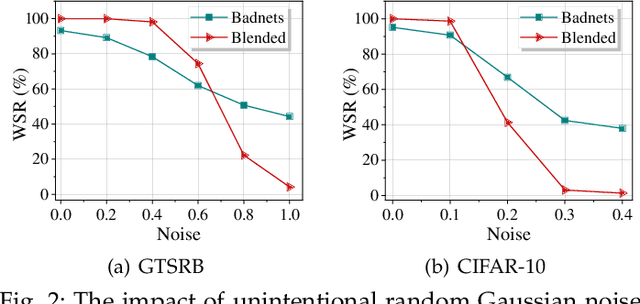
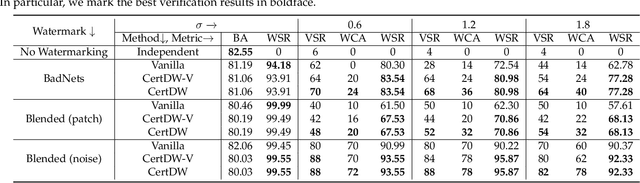
Deep neural networks (DNNs) rely heavily on high-quality open-source datasets (e.g., ImageNet) for their success, making dataset ownership verification (DOV) crucial for protecting public dataset copyrights. In this paper, we find existing DOV methods (implicitly) assume that the verification process is faithful, where the suspicious model will directly verify ownership by using the verification samples as input and returning their results. However, this assumption may not necessarily hold in practice and their performance may degrade sharply when subjected to intentional or unintentional perturbations. To address this limitation, we propose the first certified dataset watermark (i.e., CertDW) and CertDW-based certified dataset ownership verification method that ensures reliable verification even under malicious attacks, under certain conditions (e.g., constrained pixel-level perturbation). Specifically, inspired by conformal prediction, we introduce two statistical measures, including principal probability (PP) and watermark robustness (WR), to assess model prediction stability on benign and watermarked samples under noise perturbations. We prove there exists a provable lower bound between PP and WR, enabling ownership verification when a suspicious model's WR value significantly exceeds the PP values of multiple benign models trained on watermark-free datasets. If the number of PP values smaller than WR exceeds a threshold, the suspicious model is regarded as having been trained on the protected dataset. Extensive experiments on benchmark datasets verify the effectiveness of our CertDW method and its resistance to potential adaptive attacks. Our codes are at \href{https://github.com/NcepuQiaoTing/CertDW}{GitHub}.
MaskPro: Linear-Space Probabilistic Learning for Strict (N:M)-Sparsity on Large Language Models
Jun 15, 2025The rapid scaling of large language models (LLMs) has made inference efficiency a primary bottleneck in the practical deployment. To address this, semi-structured sparsity offers a promising solution by strategically retaining $N$ elements out of every $M$ weights, thereby enabling hardware-friendly acceleration and reduced memory. However, existing (N:M)-compatible approaches typically fall into two categories: rule-based layerwise greedy search, which suffers from considerable errors, and gradient-driven combinatorial learning, which incurs prohibitive training costs. To tackle these challenges, we propose a novel linear-space probabilistic framework named MaskPro, which aims to learn a prior categorical distribution for every $M$ consecutive weights and subsequently leverages this distribution to generate the (N:M)-sparsity throughout an $N$-way sampling without replacement. Furthermore, to mitigate the training instability induced by the high variance of policy gradients in the super large combinatorial space, we propose a novel update method by introducing a moving average tracker of loss residuals instead of vanilla loss. Finally, we conduct comprehensive theoretical analysis and extensive experiments to validate the superior performance of MaskPro, as well as its excellent scalability in memory efficiency and exceptional robustness to data samples. Our code is available at https://github.com/woodenchild95/Maskpro.git.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
ME: Trigger Element Combination Backdoor Attack on Copyright Infringement
Jun 12, 2025The capability of generative diffusion models (DMs) like Stable Diffusion (SD) in replicating training data could be taken advantage of by attackers to launch the Copyright Infringement Attack, with duplicated poisoned image-text pairs. SilentBadDiffusion (SBD) is a method proposed recently, which shew outstanding performance in attacking SD in text-to-image tasks. However, the feasible data resources in this area are still limited, some of them are even constrained or prohibited due to the issues like copyright ownership or inappropriate contents; And not all of the images in current datasets are suitable for the proposed attacking methods; Besides, the state-of-the-art (SoTA) performance of SBD is far from ideal when few generated poisoning samples could be adopted for attacks. In this paper, we raised new datasets accessible for researching in attacks like SBD, and proposed Multi-Element (ME) attack method based on SBD by increasing the number of poisonous visual-text elements per poisoned sample to enhance the ability of attacking, while importing Discrete Cosine Transform (DCT) for the poisoned samples to maintain the stealthiness. The Copyright Infringement Rate (CIR) / First Attack Epoch (FAE) we got on the two new datasets were 16.78% / 39.50 and 51.20% / 23.60, respectively close to or even outperformed benchmark Pokemon and Mijourney datasets. In condition of low subsampling ratio (5%, 6 poisoned samples), MESI and DCT earned CIR / FAE of 0.23% / 84.00 and 12.73% / 65.50, both better than original SBD, which failed to attack at all.
Consistent Paths Lead to Truth: Self-Rewarding Reinforcement Learning for LLM Reasoning
Jun 10, 2025Recent advances of Reinforcement Learning (RL) have highlighted its potential in complex reasoning tasks, yet effective training often relies on external supervision, which limits the broader applicability. In this work, we propose a novel self-rewarding reinforcement learning framework to enhance Large Language Model (LLM) reasoning by leveraging the consistency of intermediate reasoning states across different reasoning trajectories. Our key insight is that correct responses often exhibit consistent trajectory patterns in terms of model likelihood: their intermediate reasoning states tend to converge toward their own final answers (high consistency) with minimal deviation toward other candidates (low volatility). Inspired by this observation, we introduce CoVo, an intrinsic reward mechanism that integrates Consistency and Volatility via a robust vector-space aggregation strategy, complemented by a curiosity bonus to promote diverse exploration. CoVo enables LLMs to perform RL in a self-rewarding manner, offering a scalable pathway for learning to reason without external supervision. Extensive experiments on diverse reasoning benchmarks show that CoVo achieves performance comparable to or even surpassing supervised RL. Our code is available at https://github.com/sastpg/CoVo.