 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystify Protein Generation with Hierarchical Conditional Diffusion Models
Jul 24, 2025Generating novel and functional protein sequences is critical to a wide range of applications in biology. Recent advancements in conditional diffusion models have shown impressive empirical performance in protein generation tasks. However, reliable generations of protein remain an open research question in de novo protein design, especially when it comes to conditional diffusion models. Considering the biological function of a protein is determined by multi-level structures, we propose a novel multi-level conditional diffusion model that integrates both sequence-based and structure-based information for efficient end-to-end protein design guided by specified functions. By generating representations at different levels simultaneously, our framework can effectively model the inherent hierarchical relations between different levels, resulting in an informative and discriminative representation of the generated protein. We also propose a Protein-MMD, a new reliable evaluation metric, to evaluate the quality of generated protein with conditional diffusion models. Our new metric is able to capture both distributional and functional similarities between real and generated protein sequences while ensuring conditional consistency. We experiment with the benchmark datasets, and the results on conditional protein generation tasks demonstrate the efficacy of the proposed generation framework and evaluation metric.
Computing Approximate Graph Edit Distance via Optimal Transport
Dec 25, 2024Given a graph pair $(G^1, G^2)$, graph edit distance (GED) is defined as the minimum number of edit operations converting $G^1$ to $G^2$. GED is a fundamental operation widely used in many applications, but its exact computation is NP-hard, so the approximation of GED has gained a lot of attention. Data-driven learning-based methods have been found to provide superior results compared to classical approximate algorithms, but they directly fit the coupling relationship between a pair of vertices from their vertex features. We argue that while pairwise vertex features can capture the coupling cost (discrepancy) of a pair of vertices, the vertex coupling matrix should be derived from the vertex-pair cost matrix through a more well-established method that is aware of the global context of the graph pair, such as optimal transport. In this paper, we propose an ensemble approach that integrates a supervised learning-based method and an unsupervised method, both based on optimal transport. Our learning method, GEDIOT, is based on inverse optimal transport that leverages a learnable Sinkhorn algorithm to generate the coupling matrix. Our unsupervised method, GEDGW, models GED computation as a linear combination of optimal transport and its variant, Gromov-Wasserstein discrepancy, for node and edge operations, respectively, which can be solved efficiently without needing the ground truth. Our ensemble method, GEDHOT, combines GEDIOT and GEDGW to further boost the performance. Extensive experiments demonstrate that our methods significantly outperform the existing methods in terms of the performance of GED computation, edit path generation, and model generalizability.
Enabling Quick, Accurate Crowdsourced Annotation for Elevation-Aware Flood Extent Mapping
Jul 31, 2024In order to assess damage and properly allocate relief efforts, mapping the extent of flood events is a necessary and important aspect of disaster management. In recent years, deep learning methods have evolved as an effective tool to quickly label high-resolution imagery and provide necessary flood extent mappings. These methods, though, require large amounts of annotated training data to create models that are accurate and robust to new flooded imagery. In this work, we provide FloodTrace, an application that enables effective crowdsourcing for flooded region annotation for machine learning training data, removing the requirement for annotation to be done solely by researchers. We accomplish this through two orthogonal methods within our application, informed by requirements from domain experts. First, we utilize elevation-guided annotation tools and 3D rendering to inform user annotation decisions with digital elevation model data, improving annotation accuracy. For this purpose, we provide a unique annotation method that uses topological data analysis to outperform the state-of-the-art elevation-guided annotation tool in efficiency. Second, we provide a framework for researchers to review aggregated crowdsourced annotations and correct inaccuracies using methods inspired by uncertainty visualization. We conducted a user study to confirm the application effectiveness in which 266 graduate students annotated high-resolution aerial imagery from Hurricane Matthew in North Carolina. Experimental results show the accuracy and efficiency benefits of our application apply even for untrained users. In addition, using our aggregation and correction framework, flood detection models trained on crowdsourced annotations were able to achieve performance equal to models trained on expert-labeled annotations, while requiring a fraction of the time on the part of the researcher.
EvaNet: Elevation-Guided Flood Extent Mapping on Earth Imagery
Apr 27, 2024



Accurate and timely mapping of flood extent from high-resolution satellite imagery plays a crucial role in disaster management such as damage assessment and relief activities. However, current state-of-the-art solutions are based on U-Net, which can-not segment the flood pixels accurately due to the ambiguous pixels (e.g., tree canopies, clouds) that prevent a direct judgement from only the spectral features. Thanks to the digital elevation model (DEM) data readily available from sources such as United States Geological Survey (USGS), this work explores the use of an elevation map to improve flood extent mapping. We propose, EvaNet, an elevation-guided segmentation model based on the encoder-decoder architecture with two novel techniques: (1) a loss function encoding the physical law of gravity that if a location is flooded (resp. dry), then its adjacent locations with a lower (resp. higher) elevation must also be flooded (resp. dry); (2) a new (de)convolution operation that integrates the elevation map by a location sensitive gating mechanism to regulate how much spectral features flow through adjacent layers. Extensive experiments show that EvaNet significantly outperforms the U-Net baselines, and works as a perfect drop-in replacement for U-Net in existing solutions to flood extent mapping.
Successfully Applying Lottery Ticket Hypothesis to Diffusion Model
Oct 28, 2023



Despite the success of diffusion models, the training and inference of diffusion models are notoriously expensive due to the long chain of the reverse process. In parallel, the Lottery Ticket Hypothesis (LTH) claims that there exists winning tickets (i.e., aproperly pruned sub-network together with original weight initialization) that can achieve performance competitive to the original dense neural network when trained in isolation. In this work, we for the first time apply LTH to diffusion models. We empirically find subnetworks at sparsity 90%-99% without compromising performance for denoising diffusion probabilistic models on benchmarks (CIFAR-10, CIFAR-100, MNIST). Moreover, existing LTH works identify the subnetworks with a unified sparsity along different layers. We observe that the similarity between two winning tickets of a model varies from block to block. Specifically, the upstream layers from two winning tickets for a model tend to be more similar than the downstream layers. Therefore, we propose to find the winning ticket with varying sparsity along different layers in the model. Experimental results demonstrate that our method can find sparser sub-models that require less memory for storage and reduce the necessary number of FLOPs. Codes are available at https://github.com/osier0524/Lottery-Ticket-to-DDPM.
Towards Understanding Sycophancy in Language Models
Oct 27, 2023



Human feedback is commonly utilized to finetune AI assistants. But human feedback may also encourage model responses that match user beliefs over truthful ones, a behaviour known as sycophancy. We investigate the prevalence of sycophancy in models whose finetuning procedure made use of human feedback, and the potential role of human preference judgments in such behavior. We first demonstrate that five state-of-the-art AI assistants consistently exhibit sycophancy across four varied free-form text-generation tasks. To understand if human preferences drive this broadly observed behavior, we analyze existing human preference data. We find that when a response matches a user's views, it is more likely to be preferred. Moreover, both humans and preference models (PMs) prefer convincingly-written sycophantic responses over correct ones a non-negligible fraction of the time. Optimizing model outputs against PMs also sometimes sacrifices truthfulness in favor of sycophancy. Overall, our results indicate that sycophancy is a general behavior of state-of-the-art AI assistants, likely driven in part by human preference judgments favoring sycophantic responses.
Rethinking Graph Lottery Tickets: Graph Sparsity Matters
May 03, 2023



Lottery Ticket Hypothesis (LTH) claims the existence of a winning ticket (i.e., a properly pruned sub-network together with original weight initialization) that can achieve competitive performance to the original dense network. A recent work, called UGS, extended LTH to prune graph neural networks (GNNs) for effectively accelerating GNN inference. UGS simultaneously prunes the graph adjacency matrix and the model weights using the same masking mechanism, but since the roles of the graph adjacency matrix and the weight matrices are very different, we find that their sparsifications lead to different performance characteristics. Specifically, we find that the performance of a sparsified GNN degrades significantly when the graph sparsity goes beyond a certain extent. Therefore, we propose two techniques to improve GNN performance when the graph sparsity is high. First, UGS prunes the adjacency matrix using a loss formulation which, however, does not properly involve all elements of the adjacency matrix; in contrast, we add a new auxiliary loss head to better guide the edge pruning by involving the entire adjacency matrix. Second, by regarding unfavorable graph sparsification as adversarial data perturbations, we formulate the pruning process as a min-max optimization problem to gain the robustness of lottery tickets when the graph sparsity is high. We further investigate the question: Can the "retrainable" winning ticket of a GNN be also effective for graph transferring learning? We call it the transferable graph lottery ticket (GLT) hypothesis. Extensive experiments were conducted which demonstrate the superiority of our proposed sparsification method over UGS, and which empirically verified our transferable GLT hypothesis.
Discovering Language Model Behaviors with Model-Written Evaluations
Dec 19, 2022



As language models (LMs) scale, they develop many novel behaviors, good and bad, exacerbating the need to evaluate how they behave. Prior work creates evaluations with crowdwork (which is time-consuming and expensive) or existing data sources (which are not always available). Here, we automatically generate evaluations with LMs. We explore approaches with varying amounts of human effort, from instructing LMs to write yes/no questions to making complex Winogender schemas with multiple stages of LM-based generation and filtering. Crowdworkers rate the examples as highly relevant and agree with 90-100% of labels, sometimes more so than corresponding human-written datasets. We generate 154 datasets and discover new cases of inverse scaling where LMs get worse with size. Larger LMs repeat back a dialog user's preferred answer ("sycophancy") and express greater desire to pursue concerning goals like resource acquisition and goal preservation. We also find some of the first examples of inverse scaling in RL from Human Feedback (RLHF), where more RLHF makes LMs worse. For example, RLHF makes LMs express stronger political views (on gun rights and immigration) and a greater desire to avoid shut down. Overall, LM-written evaluations are high-quality and let us quickly discover many novel LM behaviors.
Reinforcement Learning Enhanced Weighted Sampling for Accurate Subgraph Counting on Fully Dynamic Graph Streams
Nov 13, 2022



As the popularity of graph data increases, there is a growing need to count the occurrences of subgraph patterns of interest, for a variety of applications. Many graphs are massive in scale and also fully dynamic (with insertions and deletions of edges), rendering exact computation of these counts to be infeasible. Common practice is, instead, to use a small set of edges as a sample to estimate the counts. Existing sampling algorithms for fully dynamic graphs sample the edges with uniform probability. In this paper, we show that we can do much better if we sample edges based on their individual properties. Specifically, we propose a weighted sampling algorithm called WSD for estimating the subgraph count in a fully dynamic graph stream, which samples the edges based on their weights that indicate their importance and reflect their properties. We determine the weights of edges in a data-driven fashion, using a novel method based on reinforcement learning. We conduct extensive experiments to verify that our technique can produce estimates with smaller errors while often running faster compared with existing algorithms.
Deep Neural Network for 3D Surface Segmentation based on Contour Tree Hierarchy
Aug 25, 2020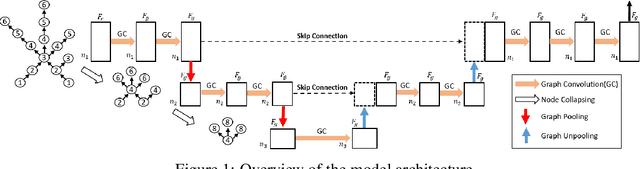
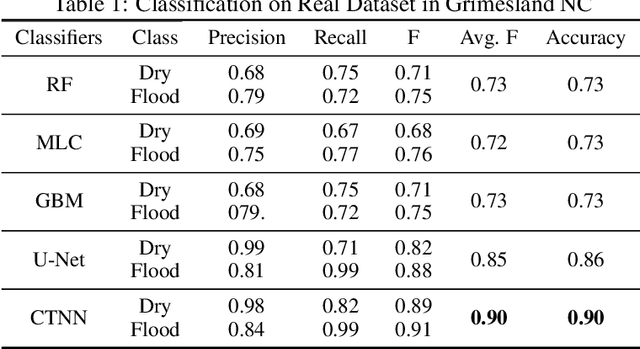
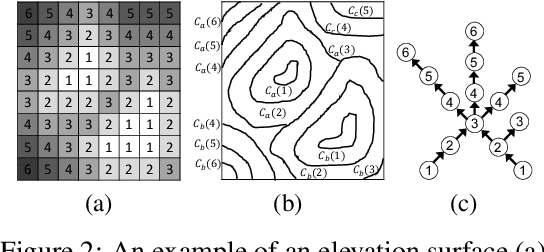
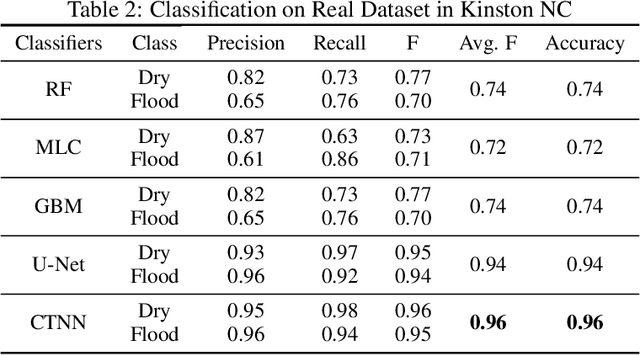
Given a 3D surface defined by an elevation function on a 2D grid as well as non-spatial features observed at each pixel, the problem of surface segmentation aims to classify pixels into contiguous classes based on both non-spatial features and surface topology. The problem has important applications in hydrology, planetary science, and biochemistry but is uniquely challenging for several reasons. First, the spatial extent of class segments follows surface contours in the topological space, regardless of their spatial shapes and directions. Second, the topological structure exists in multiple spatial scales based on different surface resolutions. Existing widely successful deep learning models for image segmentation are often not applicable due to their reliance on convolution and pooling operations to learn regular structural patterns on a grid. In contrast, we propose to represent surface topological structure by a contour tree skeleton, which is a polytree capturing the evolution of surface contours at different elevation levels. We further design a graph neural network based on the contour tree hierarchy to model surface topological structure at different spatial scales. Experimental evaluations based on real-world hydrological datasets show that our model outperforms several baseline methods in classification accuracy.