 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Multi-scale Bilateral Motion Network for Gait Recognition
Sep 26, 2022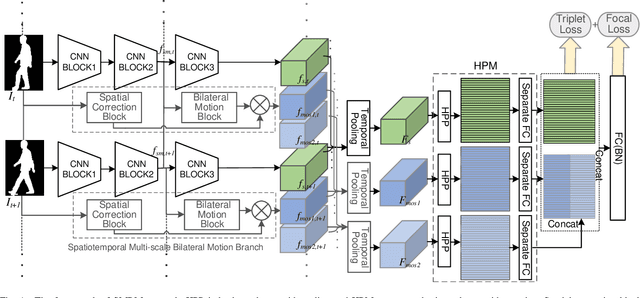
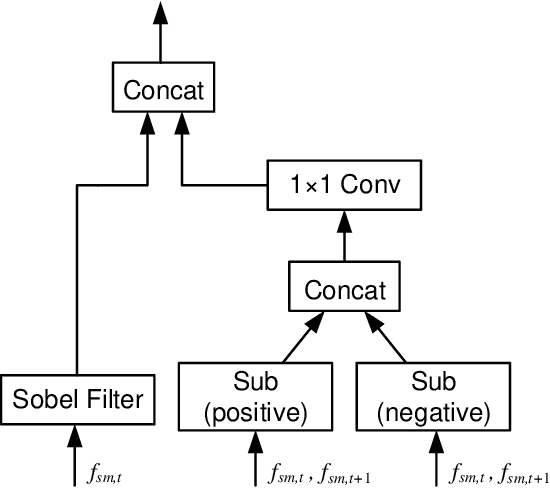
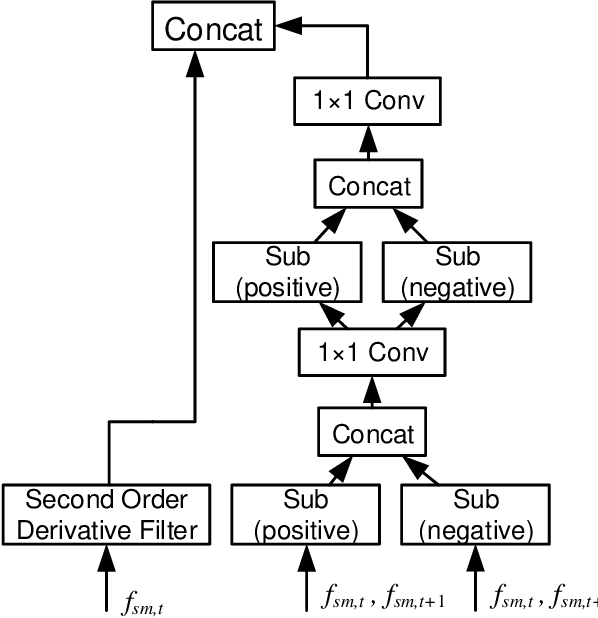
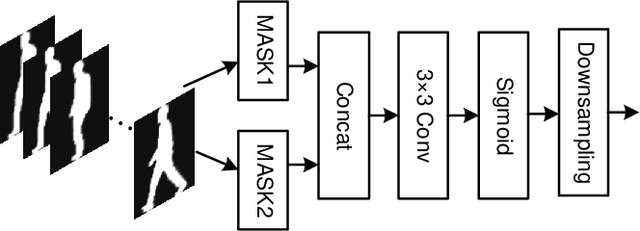
The critical goal of gait recognition is to acquire the inter-frame walking habit representation from the gait sequences. The relations between frames, however, have not received adequate attention in comparison to the intra-frame features. In this paper, motivated by optical flow, the bilateral motion-oriented features are proposed, which can allow the classic convolutional structure to have the capability to directly portray gait movement patterns at the feature level. Based on such features, we develop a set of multi-scale temporal representations that force the motion context to be richly described at various levels of temporal resolution. Furthermore, a correction block is devised to eliminate the segmentation noise of silhouettes for getting more precise gait information. Subsequently, the temporal feature set and the spatial features are combined to comprehensively characterize gait processes. Extensive experiments are conducted on CASIA-B and OU-MVLP datasets, and the results achieve an outstanding identification performance, which has demonstrated the effectiveness of the proposed approach.
Joint Attention-Driven Domain Fusion and Noise-Tolerant Learning for Multi-Source Domain Adaptation
Aug 05, 2022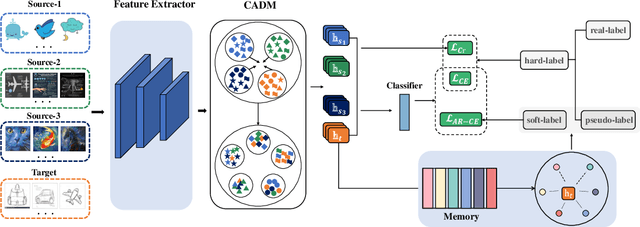
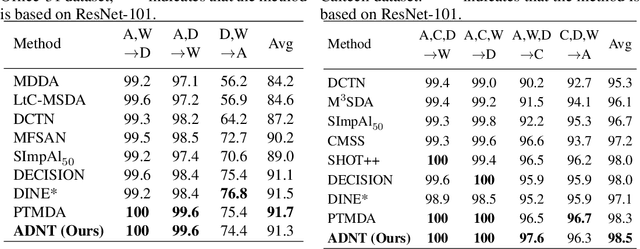
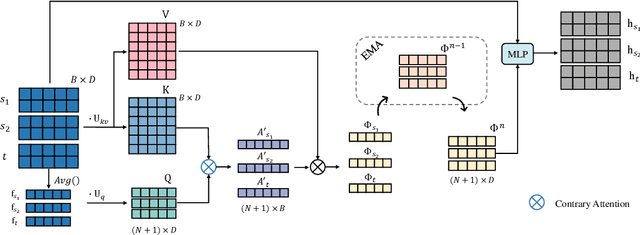
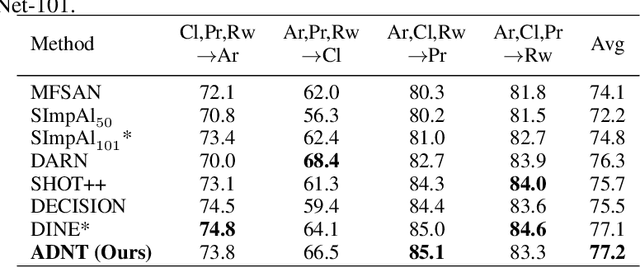
As a study on the efficient usage of data, Multi-source Unsupervised Domain Adaptation transfers knowledge from multiple source domains with labeled data to an unlabeled target domain. However, the distribution discrepancy between different domains and the noisy pseudo-labels in the target domain both lead to performance bottlenecks of the Multi-source Unsupervised Domain Adaptation methods. In light of this, we propose an approach that integrates Attention-driven Domain fusion and Noise-Tolerant learning (ADNT) to address the two issues mentioned above. Firstly, we establish a contrary attention structure to perform message passing between features and to induce domain movement. Through this approach, the discriminability of the features can also be significantly improved while the domain discrepancy is reduced. Secondly, based on the characteristics of the unsupervised domain adaptation training, we design an Adaptive Reverse Cross Entropy loss, which can directly impose constraints on the generation of pseudo-labels. Finally, combining these two approaches, experimental results on several benchmarks further validate the effectiveness of our proposed ADNT and demonstrate superior performance over the state-of-the-art methods.
Source Separation of Unknown Numbers of Single-Channel Underwater Acoustic Signals Based on Autoencoders
Jul 24, 2022
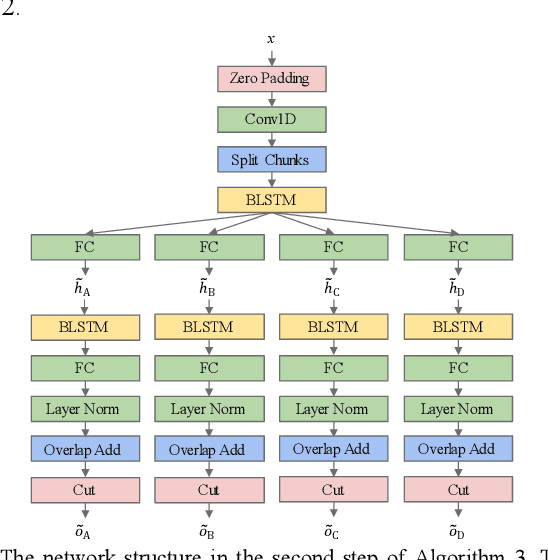
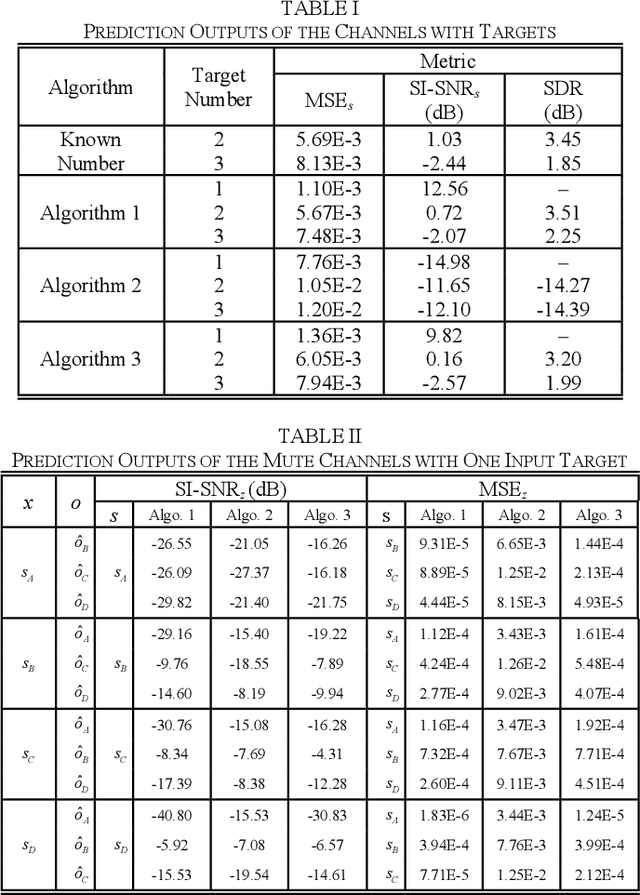
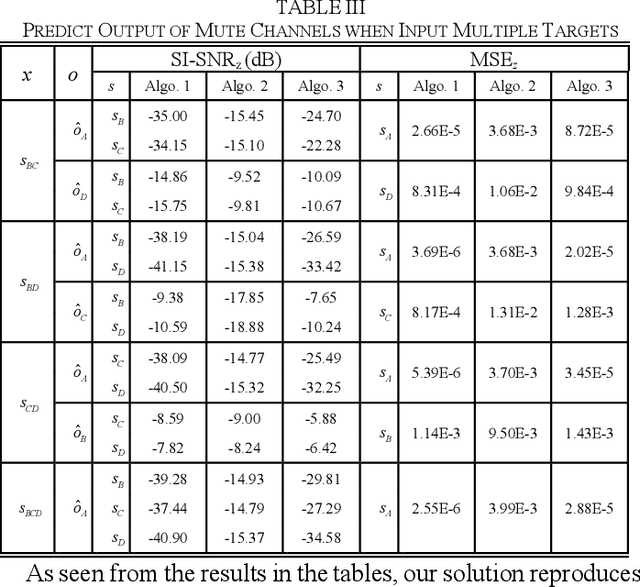
The separation of single-channel underwater acoustic signals is a challenging problem with practical significance. In view of the signal separation problem with unknown numbers of signals, we propose a solution with a fixed number of output channels, enabling it to avoid the dimensional disaster caused by the permutation problem induced by the alignment of outputs to targets. Specifically, we modify two algorithms developed for known numbers of signals based on autoencoders, which are highly explainable. We also propose a new performance evaluation method for situations with mute channels. Experiments conducted on simulated mixtures of radiated ship noise show that the proposed solution can achieve similar separation performance to that attained with a known number of signals. The mute channel output is also good.
Sequential convolutional network for behavioral pattern extraction in gait recognition
Apr 23, 2021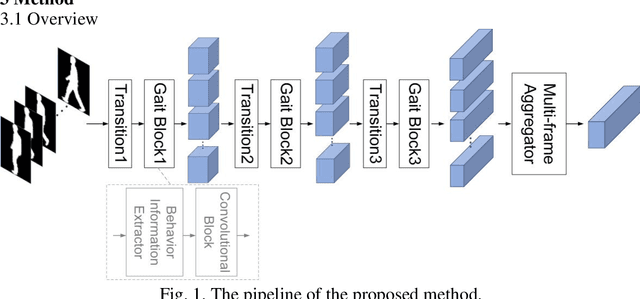
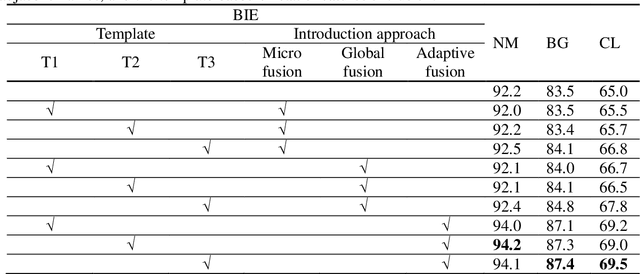
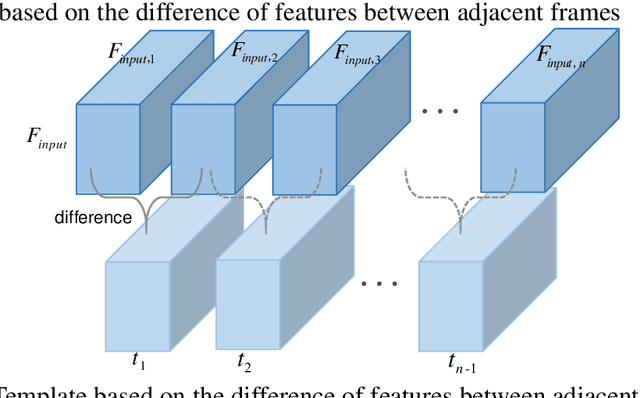
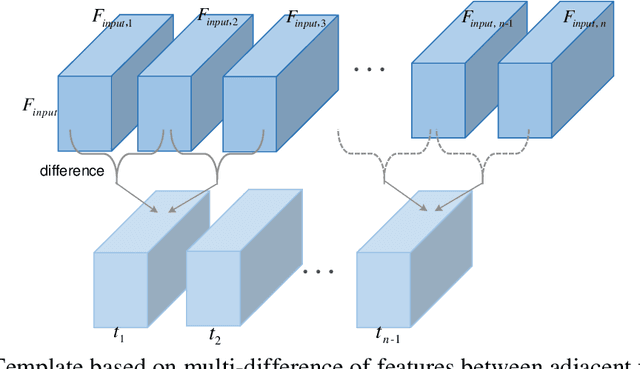
As a unique and promising biometric, video-based gait recognition has broad applications. The key step of this methodology is to learn the walking pattern of individuals, which, however, often suffers challenges to extract the behavioral feature from a sequence directly. Most existing methods just focus on either the appearance or the motion pattern. To overcome these limitations, we propose a sequential convolutional network (SCN) from a novel perspective, where spatiotemporal features can be learned by a basic convolutional backbone. In SCN, behavioral information extractors (BIE) are constructed to comprehend intermediate feature maps in time series through motion templates where the relationship between frames can be analyzed, thereby distilling the information of the walking pattern. Furthermore, a multi-frame aggregator in SCN performs feature integration on a sequence whose length is uncertain, via a mobile 3D convolutional layer. To demonstrate the effectiveness, experiments have been conducted on two popular public benchmarks, CASIA-B and OU-MVLP, and our approach is demonstrated superior performance, comparing with the state-of-art methods.
Computational efficient deep neural network with difference attention maps for facial action unit detection
Nov 27, 2020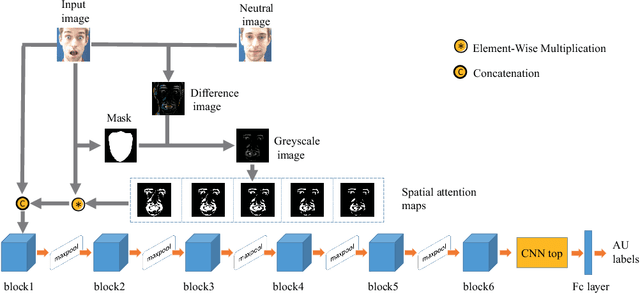


In this paper, we propose a computational efficient end-to-end training deep neural network (CEDNN) model and spatial attention maps based on difference images. Firstly, the difference image is generated by image processing. Then five binary images of difference images are obtained using different thresholds, which are used as spatial attention maps. We use group convolution to reduce model complexity. Skip connection and $\text{1}\times \text{1}$ convolution are used to ensure good performance even if the network model is not deep. As an input, spatial attention map can be selectively fed into the input of each block. The feature maps tend to focus on the parts that are related to the target task better. In addition, we only need to adjust the parameters of classifier to train different numbers of AU. It can be easily extended to varying datasets without increasing too much computation. A large number of experimental results show that the proposed CEDNN is obviously better than the traditional deep learning method on DISFA+ and CK+ datasets. After adding spatial attention maps, the result is better than the most advanced AU detection method. At the same time, the scale of the network is small, the running speed is fast, and the requirement for experimental equipment is low.
Person image generation with semantic attention network for person re-identification
Aug 18, 2020
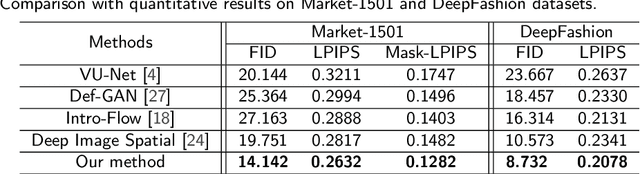
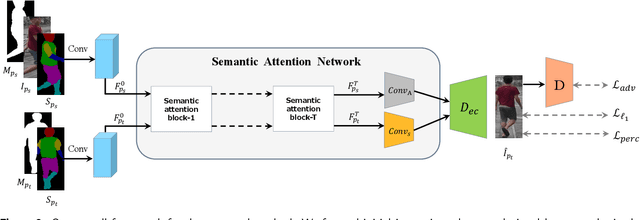
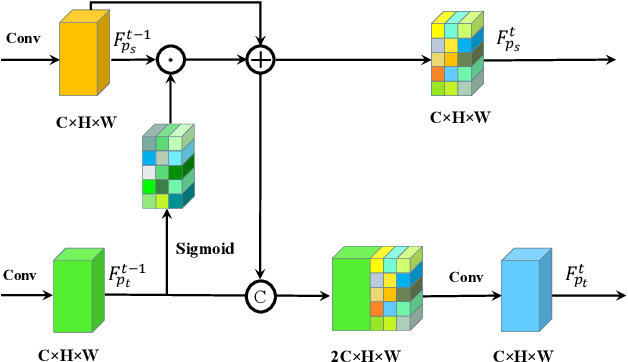
Pose variation is one of the key factors which prevents the network from learning a robust person re-identification (Re-ID) model. To address this issue, we propose a novel person pose-guided image generation method, which is called the semantic attention network. The network consists of several semantic attention blocks, where each block attends to preserve and update the pose code and the clothing textures. The introduction of the binary segmentation mask and the semantic parsing is important for seamlessly stitching foreground and background in the pose-guided image generation. Compared with other methods, our network can characterize better body shape and keep clothing attributes, simultaneously. Our synthesized image can obtain better appearance and shape consistency related to the original image. Experimental results show that our approach is competitive with respect to both quantitative and qualitative results on Market-1501 and DeepFashion. Furthermore, we conduct extensive evaluations by using person re-identification (Re-ID) systems trained with the pose-transferred person based augmented data. The experiment shows that our approach can significantly enhance the person Re-ID accuracy.
HEU Emotion: A Large-scale Database for Multi-modal Emotion Recognition in the Wild
Jul 24, 2020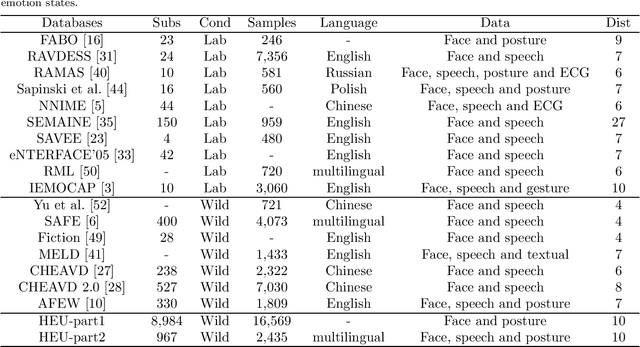
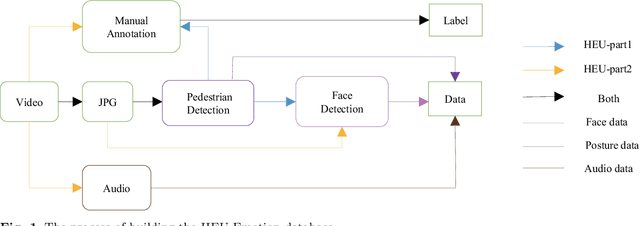


The study of affective computing in the wild setting is underpinned by databases. Existing multimodal emotion databases in the real-world conditions are few and small, with a limited number of subjects and expressed in a single language. To meet this requirement, we collected, annotated, and prepared to release a new natural state video database (called HEU Emotion). HEU Emotion contains a total of 19,004 video clips, which is divided into two parts according to the data source. The first part contains videos downloaded from Tumblr, Google, and Giphy, including 10 emotions and two modalities (facial expression and body posture). The second part includes corpus taken manually from movies, TV series, and variety shows, consisting of 10 emotions and three modalities (facial expression, body posture, and emotional speech). HEU Emotion is by far the most extensive multi-modal emotional database with 9,951 subjects. In order to provide a benchmark for emotion recognition, we used many conventional machine learning and deep learning methods to evaluate HEU Emotion. We proposed a Multi-modal Attention module to fuse multi-modal features adaptively. After multi-modal fusion, the recognition accuracies for the two parts increased by 2.19% and 4.01% respectively over those of single-modal facial expression recognition.