 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Multiscale Deep Formulas in Complex Systems via Neural-Guided Lambda Calculus
Jun 05, 2026A fundamental problem in science is identifying underlying patterns of complex systems in the form of concise mathematical formulas. Current Artificial Intelligence (AI)-based methods have shown strong performance in single-scale systems, yet remain limited in identifying scale-specific formulas in multiscale complex systems. We present Deflex, an end-to-end AI method to automatically extract multiscale formulas with potentially different forms, including invariants and distributions, from complex systems. Deflex consists of two subsystems named Deflexformer and Deflexpressor. Deflexpressor is a lambda-calculus symbolic regression model for higher-order formulas. Deflexformer is a decomposable deep energy model for learning unified representations across scales. Deflexpressor generates synthetic data to pre-train Deflexformer, which then guides formula discovery by decoupling multiscale latent relationships. Across six representative complex systems with diverse behaviors, Deflex achieves up to 7-fold higher efficiency than the state-of-the-art methods while enabling automated multiscale discovery. Our work could be a useful tool for scientific discovery across disciplines.
CDC: Classification Driven Compression for Bandwidth Efficient Edge-Cloud Collaborative Deep Learning
May 04, 2020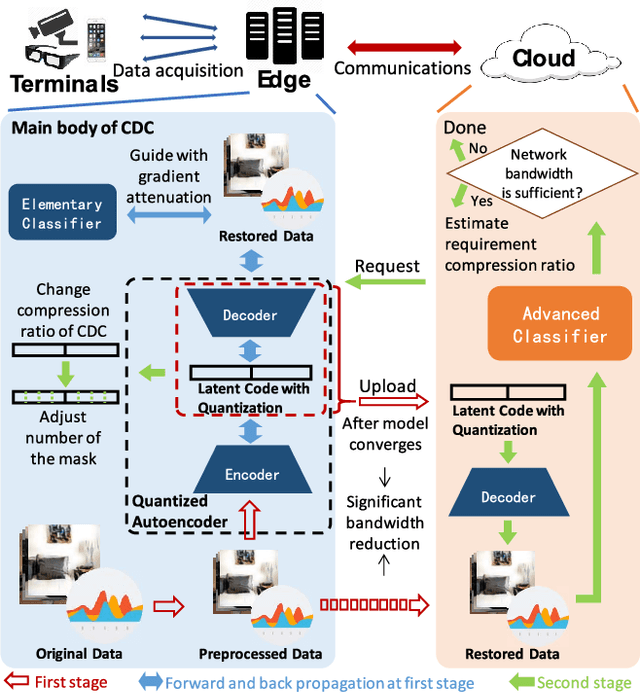
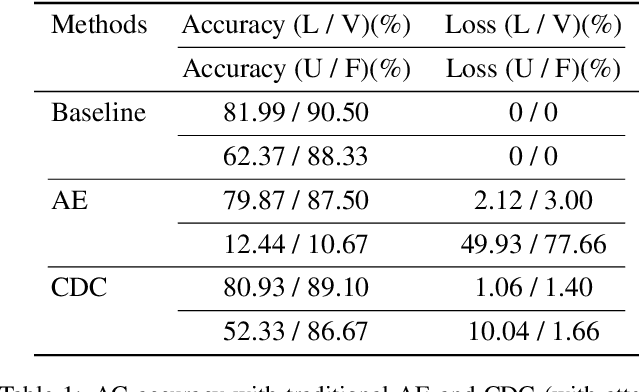
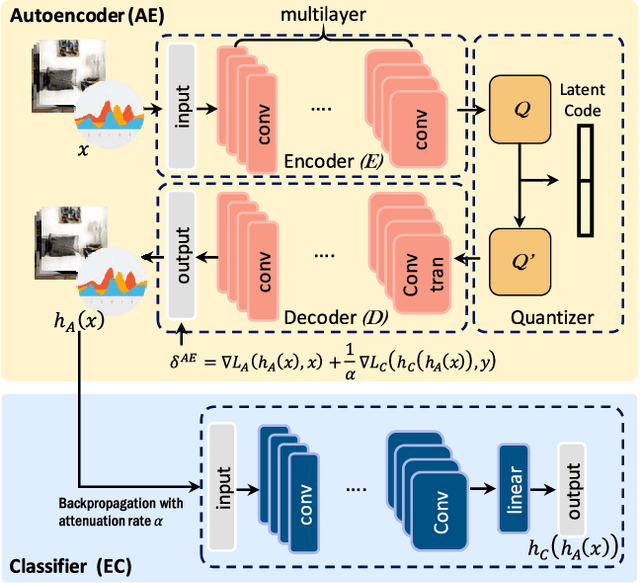
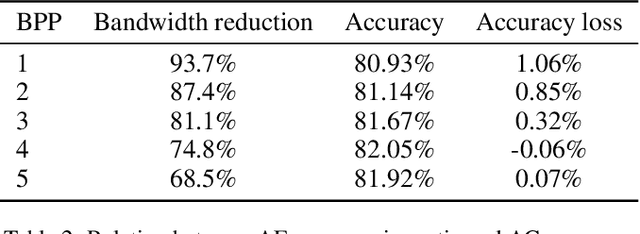
The emerging edge-cloud collaborative Deep Learning (DL) paradigm aims at improving the performance of practical DL implementations in terms of cloud bandwidth consumption, response latency, and data privacy preservation. Focusing on bandwidth efficient edge-cloud collaborative training of DNN-based classifiers, we present CDC, a Classification Driven Compression framework that reduces bandwidth consumption while preserving classification accuracy of edge-cloud collaborative DL. Specifically, to reduce bandwidth consumption, for resource-limited edge servers, we develop a lightweight autoencoder with a classification guidance for compression with classification driven feature preservation, which allows edges to only upload the latent code of raw data for accurate global training on the Cloud. Additionally, we design an adjustable quantization scheme adaptively pursuing the tradeoff between bandwidth consumption and classification accuracy under different network conditions, where only fine-tuning is required for rapid compression ratio adjustment. Results of extensive experiments demonstrate that, compared with DNN training with raw data, CDC consumes 14.9 times less bandwidth with an accuracy loss no more than 1.06%, and compared with DNN training with data compressed by AE without guidance, CDC introduces at least 100% lower accuracy loss.