 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Counterfactual Image Manipulation via CLIP
Jul 12, 2022
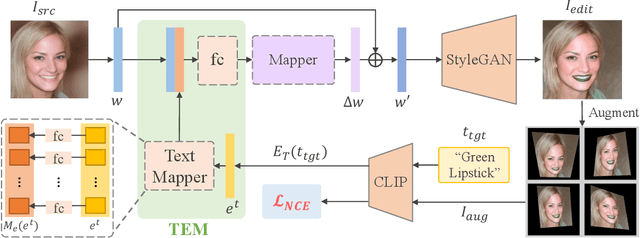
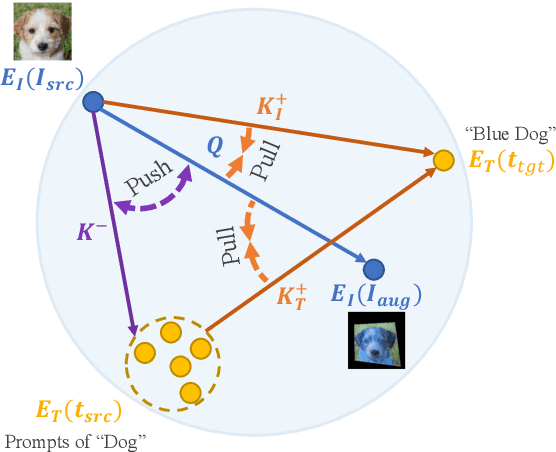

Leveraging StyleGAN's expressivity and its disentangled latent codes, existing methods can achieve realistic editing of different visual attributes such as age and gender of facial images. An intriguing yet challenging problem arises: Can generative models achieve counterfactual editing against their learnt priors? Due to the lack of counterfactual samples in natural datasets, we investigate this problem in a text-driven manner with Contrastive-Language-Image-Pretraining (CLIP), which can offer rich semantic knowledge even for various counterfactual concepts. Different from in-domain manipulation, counterfactual manipulation requires more comprehensive exploitation of semantic knowledge encapsulated in CLIP as well as more delicate handling of editing directions for avoiding being stuck in local minimum or undesired editing. To this end, we design a novel contrastive loss that exploits predefined CLIP-space directions to guide the editing toward desired directions from different perspectives. In addition, we design a simple yet effective scheme that explicitly maps CLIP embeddings (of target text) to the latent space and fuses them with latent codes for effective latent code optimization and accurate editing. Extensive experiments show that our design achieves accurate and realistic editing while driving by target texts with various counterfactual concepts.
Minimalist and High-performance Conversational Recommendation with Uncertainty Estimation for User Preference
Jul 01, 2022

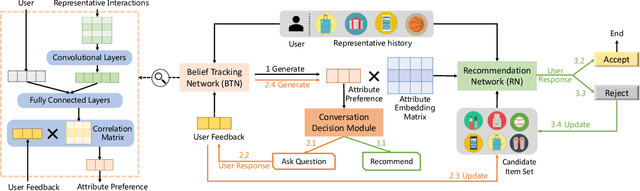
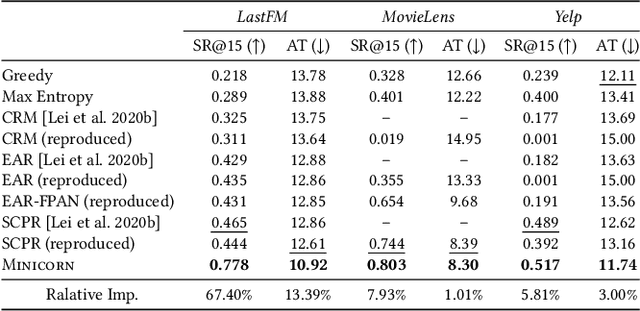
Conversational recommendation system (CRS) is emerging as a user-friendly way to capture users' dynamic preferences over candidate items and attributes. Multi-shot CRS is designed to make recommendations multiple times until the user either accepts the recommendation or leaves at the end of their patience. Existing works are trained with reinforcement learning (RL), which may suffer from unstable learning and prohibitively high demands for computing. In this work, we propose a simple and efficient CRS, MInimalist Non-reinforced Interactive COnversational Recommender Network (MINICORN). MINICORN models the epistemic uncertainty of the estimated user preference and queries the user for the attribute with the highest uncertainty. The system employs a simple network architecture and makes the query-vs-recommendation decision using a single rule. Somewhat surprisingly, this minimalist approach outperforms state-of-the-art RL methods on three real-world datasets by large margins. We hope that MINICORN will serve as a valuable baseline for future research.
On Non-Random Missing Labels in Semi-Supervised Learning
Jun 29, 2022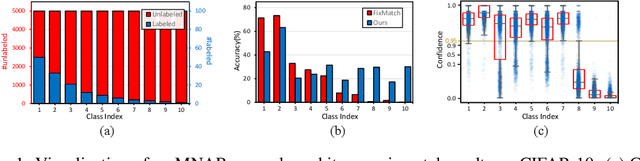
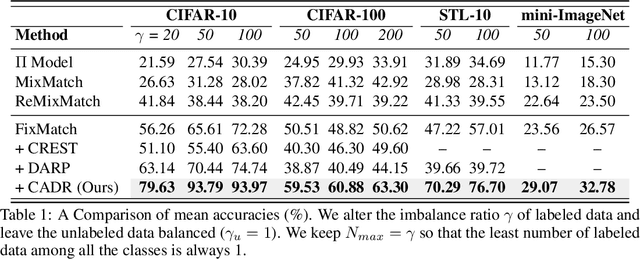
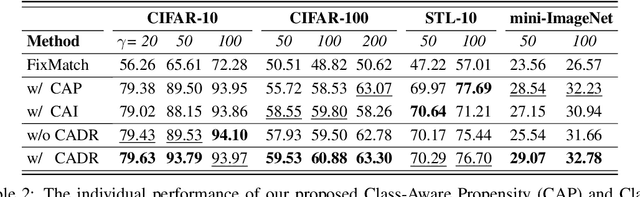
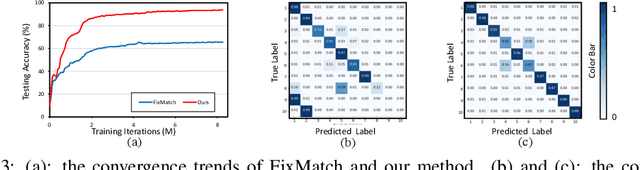
Semi-Supervised Learning (SSL) is fundamentally a missing label problem, in which the label Missing Not At Random (MNAR) problem is more realistic and challenging, compared to the widely-adopted yet naive Missing Completely At Random assumption where both labeled and unlabeled data share the same class distribution. Different from existing SSL solutions that overlook the role of "class" in causing the non-randomness, e.g., users are more likely to label popular classes, we explicitly incorporate "class" into SSL. Our method is three-fold: 1) We propose Class-Aware Propensity (CAP) that exploits the unlabeled data to train an improved classifier using the biased labeled data. 2) To encourage rare class training, whose model is low-recall but high-precision that discards too many pseudo-labeled data, we propose Class-Aware Imputation (CAI) that dynamically decreases (or increases) the pseudo-label assignment threshold for rare (or frequent) classes. 3) Overall, we integrate CAP and CAI into a Class-Aware Doubly Robust (CADR) estimator for training an unbiased SSL model. Under various MNAR settings and ablations, our method not only significantly outperforms existing baselines but also surpasses other label bias removal SSL methods. Please check our code at: https://github.com/JoyHuYY1412/CADR-FixMatch.
Enhancing Sequential Recommendation with Graph Contrastive Learning
Jun 07, 2022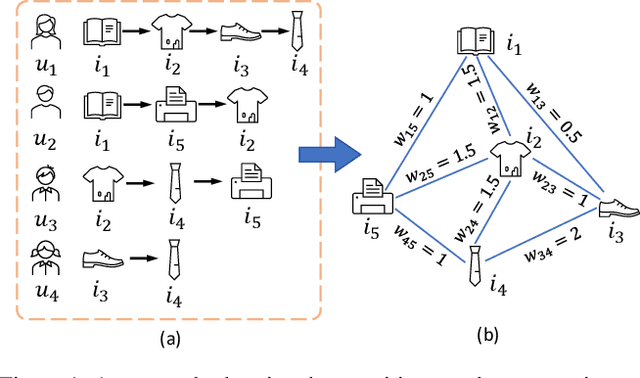
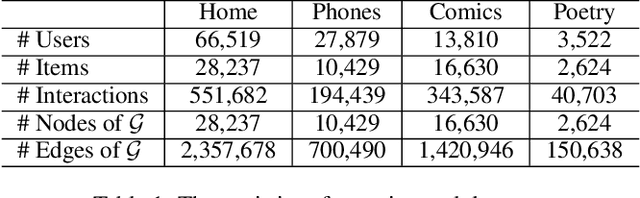
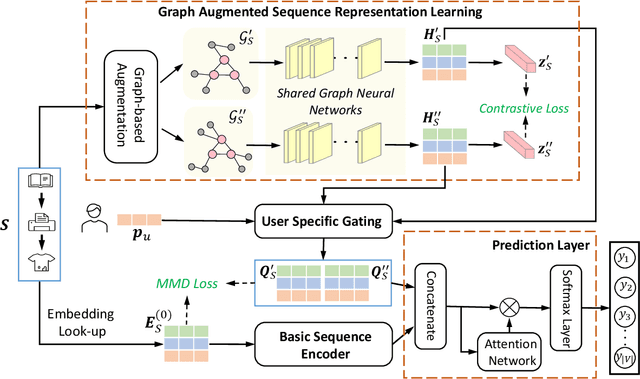
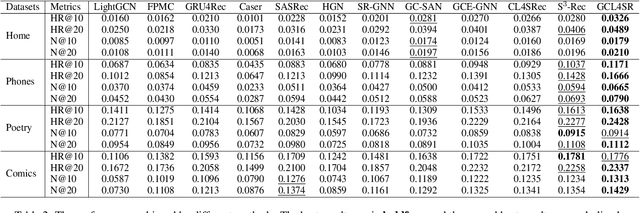
The sequential recommendation systems capture users' dynamic behavior patterns to predict their next interaction behaviors. Most existing sequential recommendation methods only exploit the local context information of an individual interaction sequence and learn model parameters solely based on the item prediction loss. Thus, they usually fail to learn appropriate sequence representations. This paper proposes a novel recommendation framework, namely Graph Contrastive Learning for Sequential Recommendation (GCL4SR). Specifically, GCL4SR employs a Weighted Item Transition Graph (WITG), built based on interaction sequences of all users, to provide global context information for each interaction and weaken the noise information in the sequence data. Moreover, GCL4SR uses subgraphs of WITG to augment the representation of each interaction sequence. Two auxiliary learning objectives have also been proposed to maximize the consistency between augmented representations induced by the same interaction sequence on WITG, and minimize the difference between the representations augmented by the global context on WITG and the local representation of the original sequence. Extensive experiments on real-world datasets demonstrate that GCL4SR consistently outperforms state-of-the-art sequential recommendation methods.
DualCF: Efficient Model Extraction Attack from Counterfactual Explanations
May 13, 2022
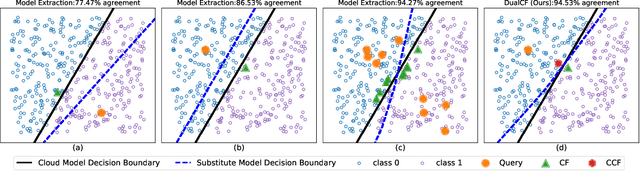
Cloud service providers have launched Machine-Learning-as-a-Service (MLaaS) platforms to allow users to access large-scale cloudbased models via APIs. In addition to prediction outputs, these APIs can also provide other information in a more human-understandable way, such as counterfactual explanations (CF). However, such extra information inevitably causes the cloud models to be more vulnerable to extraction attacks which aim to steal the internal functionality of models in the cloud. Due to the black-box nature of cloud models, however, a vast number of queries are inevitably required by existing attack strategies before the substitute model achieves high fidelity. In this paper, we propose a novel simple yet efficient querying strategy to greatly enhance the querying efficiency to steal a classification model. This is motivated by our observation that current querying strategies suffer from decision boundary shift issue induced by taking far-distant queries and close-to-boundary CFs into substitute model training. We then propose DualCF strategy to circumvent the above issues, which is achieved by taking not only CF but also counterfactual explanation of CF (CCF) as pairs of training samples for the substitute model. Extensive and comprehensive experimental evaluations are conducted on both synthetic and real-world datasets. The experimental results favorably illustrate that DualCF can produce a high-fidelity model with fewer queries efficiently and effectively.
CCLF: A Contrastive-Curiosity-Driven Learning Framework for Sample-Efficient Reinforcement Learning
May 03, 2022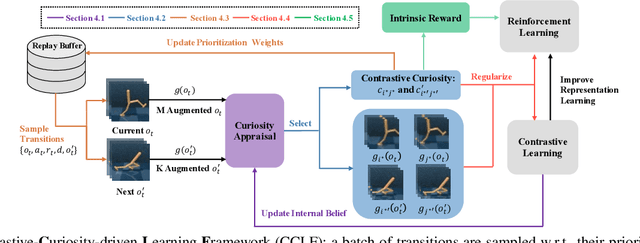
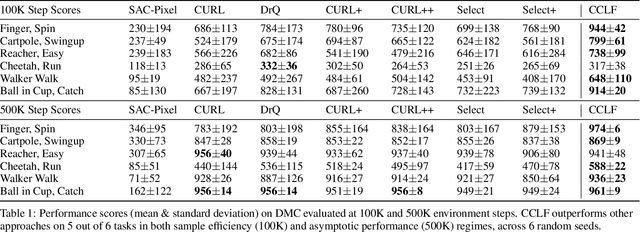
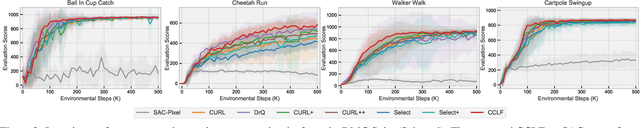

In reinforcement learning (RL), it is challenging to learn directly from high-dimensional observations, where data augmentation has recently been shown to remedy this via encoding invariances from raw pixels. Nevertheless, we empirically find that not all samples are equally important and hence simply injecting more augmented inputs may instead cause instability in Q-learning. In this paper, we approach this problem systematically by developing a model-agnostic Contrastive-Curiosity-Driven Learning Framework (CCLF), which can fully exploit sample importance and improve learning efficiency in a self-supervised manner. Facilitated by the proposed contrastive curiosity, CCLF is capable of prioritizing the experience replay, selecting the most informative augmented inputs, and more importantly regularizing the Q-function as well as the encoder to concentrate more on under-learned data. Moreover, it encourages the agent to explore with a curiosity-based reward. As a result, the agent can focus on more informative samples and learn representation invariances more efficiently, with significantly reduced augmented inputs. We apply CCLF to several base RL algorithms and evaluate on the DeepMind Control Suite, Atari, and MiniGrid benchmarks, where our approach demonstrates superior sample efficiency and learning performances compared with other state-of-the-art methods.
SimMC: Simple Masked Contrastive Learning of Skeleton Representations for Unsupervised Person Re-Identification
Apr 28, 2022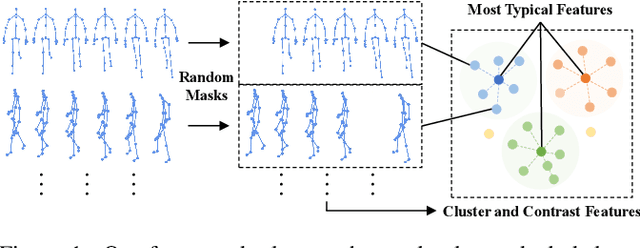
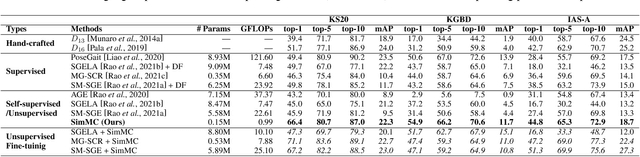
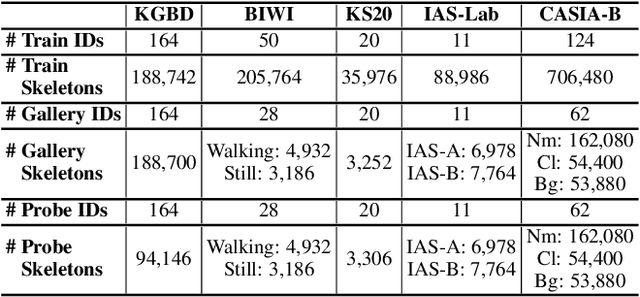
Recent advances in skeleton-based person re-identification (re-ID) obtain impressive performance via either hand-crafted skeleton descriptors or skeleton representation learning with deep learning paradigms. However, they typically require skeletal pre-modeling and label information for training, which leads to limited applicability of these methods. In this paper, we focus on unsupervised skeleton-based person re-ID, and present a generic Simple Masked Contrastive learning (SimMC) framework to learn effective representations from unlabeled 3D skeletons for person re-ID. Specifically, to fully exploit skeleton features within each skeleton sequence, we first devise a masked prototype contrastive learning (MPC) scheme to cluster the most typical skeleton features (skeleton prototypes) from different subsequences randomly masked from raw sequences, and contrast the inherent similarity between skeleton features and different prototypes to learn discriminative skeleton representations without using any label. Then, considering that different subsequences within the same sequence usually enjoy strong correlations due to the nature of motion continuity, we propose the masked intra-sequence contrastive learning (MIC) to capture intra-sequence pattern consistency between subsequences, so as to encourage learning more effective skeleton representations for person re-ID. Extensive experiments validate that the proposed SimMC outperforms most state-of-the-art skeleton-based methods. We further show its scalability and efficiency in enhancing the performance of existing models. Our codes are available at https://github.com/Kali-Hac/SimMC.
SSD-KD: A Self-supervised Diverse Knowledge Distillation Method for Lightweight Skin Lesion Classification Using Dermoscopic Images
Mar 30, 2022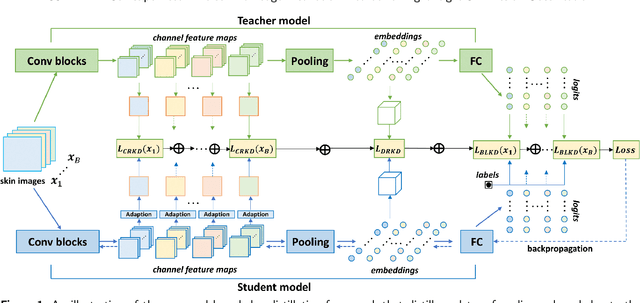

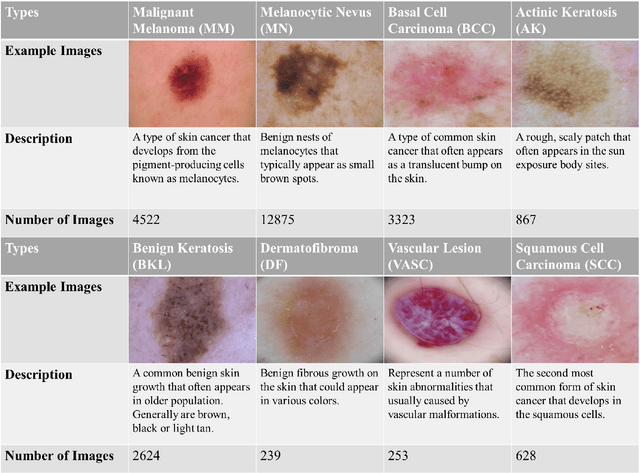

Skin cancer is one of the most common types of malignancy, affecting a large population and causing a heavy economic burden worldwide. Over the last few years, computer-aided diagnosis has been rapidly developed and make great progress in healthcare and medical practices due to the advances in artificial intelligence. However, most studies in skin cancer detection keep pursuing high prediction accuracies without considering the limitation of computing resources on portable devices. In this case, knowledge distillation (KD) has been proven as an efficient tool to help improve the adaptability of lightweight models under limited resources, meanwhile keeping a high-level representation capability. To bridge the gap, this study specifically proposes a novel method, termed SSD-KD, that unifies diverse knowledge into a generic KD framework for skin diseases classification. Our method models an intra-instance relational feature representation and integrates it with existing KD research. A dual relational knowledge distillation architecture is self-supervisedly trained while the weighted softened outputs are also exploited to enable the student model to capture richer knowledge from the teacher model. To demonstrate the effectiveness of our method, we conduct experiments on ISIC 2019, a large-scale open-accessed benchmark of skin diseases dermoscopic images. Experiments show that our distilled lightweight model can achieve an accuracy as high as 85% for the classification tasks of 8 different skin diseases with minimal parameters and computing requirements. Ablation studies confirm the effectiveness of our intra- and inter-instance relational knowledge integration strategy. Compared with state-of-the-art knowledge distillation techniques, the proposed method demonstrates improved performances for multi-diseases classification on the large-scale dermoscopy database.
What Makes Good Contrastive Learning on Small-Scale Wearable-based Tasks?
Feb 12, 2022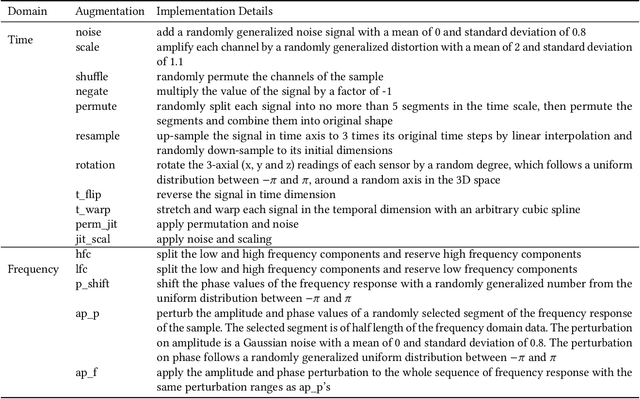
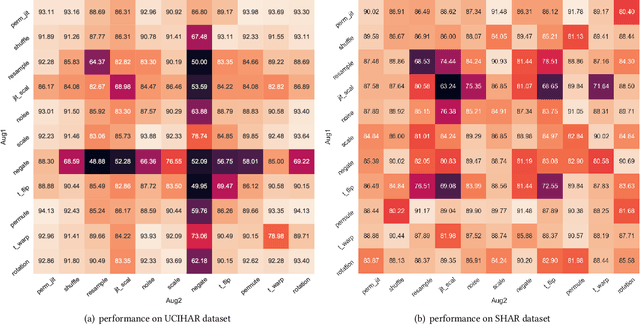

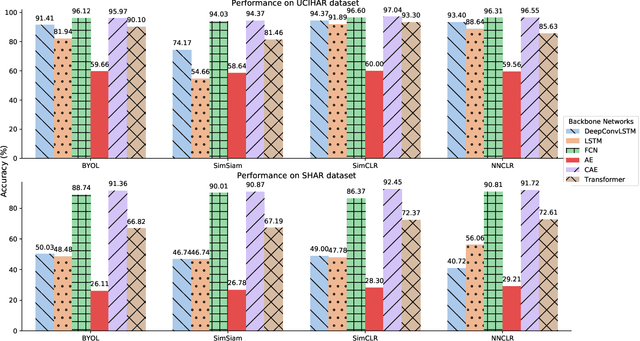
Self-supervised learning establishes a new paradigm of learning representations with much fewer or even no label annotations. Recently there has been remarkable progress on large-scale contrastive learning models which require substantial computing resources, yet such models are not practically optimal for small-scale tasks. To fill the gap, we aim to study contrastive learning on the wearable-based activity recognition task. Specifically, we conduct an in-depth study of contrastive learning from both algorithmic-level and task-level perspectives. For algorithmic-level analysis, we decompose contrastive models into several key components and conduct rigorous experimental evaluations to better understand the efficacy and rationale behind contrastive learning. More importantly, for task-level analysis, we show that the wearable-based signals bring unique challenges and opportunities to existing contrastive models, which cannot be readily solved by existing algorithms. Our thorough empirical studies suggest important practices and shed light on future research challenges. In the meantime, this paper presents an open-source PyTorch library \texttt{CL-HAR}, which can serve as a practical tool for researchers. The library is highly modularized and easy to use, which opens up avenues for exploring novel contrastive models quickly in the future.
From Psychological Curiosity to Artificial Curiosity: Curiosity-Driven Learning in Artificial Intelligence Tasks
Jan 20, 2022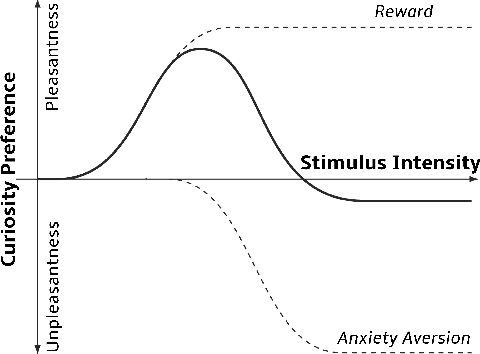
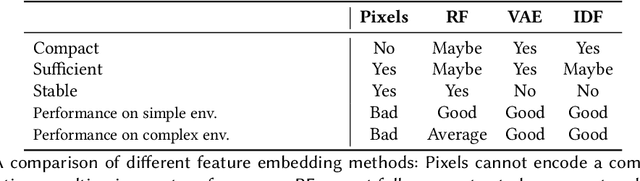
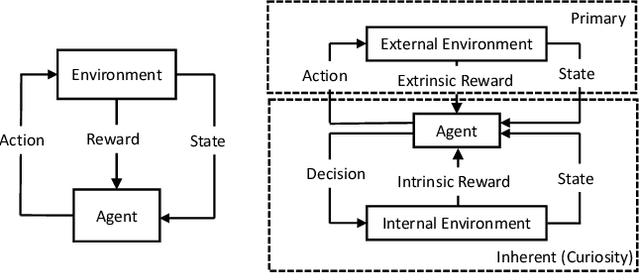
Psychological curiosity plays a significant role in human intelligence to enhance learning through exploration and information acquisition. In the Artificial Intelligence (AI) community, artificial curiosity provides a natural intrinsic motivation for efficient learning as inspired by human cognitive development; meanwhile, it can bridge the existing gap between AI research and practical application scenarios, such as overfitting, poor generalization, limited training samples, high computational cost, etc. As a result, curiosity-driven learning (CDL) has become increasingly popular, where agents are self-motivated to learn novel knowledge. In this paper, we first present a comprehensive review on the psychological study of curiosity and summarize a unified framework for quantifying curiosity as well as its arousal mechanism. Based on the psychological principle, we further survey the literature of existing CDL methods in the fields of Reinforcement Learning, Recommendation, and Classification, where both advantages and disadvantages as well as future work are discussed. As a result, this work provides fruitful insights for future CDL research and yield possible directions for further improvement.