 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Pretraining: Language Modeling Beyond Document Boundaries
Oct 20, 2023



Large language models (LMs) are currently trained to predict tokens given document prefixes, enabling them to directly perform long-form generation and prompting-style tasks which can be reduced to document completion. Existing pretraining pipelines train LMs by concatenating random sets of short documents to create input contexts but the prior documents provide no signal for predicting the next document. We instead present In-Context Pretraining, a new approach where language models are pretrained on a sequence of related documents, thereby explicitly encouraging them to read and reason across document boundaries. We can do In-Context Pretraining by simply changing the document ordering so that each context contains related documents, and directly applying existing pretraining pipelines. However, this document sorting problem is challenging. There are billions of documents and we would like the sort to maximize contextual similarity for every document without repeating any data. To do this, we introduce approximate algorithms for finding related documents with efficient nearest neighbor search and constructing coherent input contexts with a graph traversal algorithm. Our experiments show In-Context Pretraining offers a simple and scalable approach to significantly enhance LMs'performance: we see notable improvements in tasks that require more complex contextual reasoning, including in-context learning (+8%), reading comprehension (+15%), faithfulness to previous contexts (+16%), long-context reasoning (+5%), and retrieval augmentation (+9%).
Self-Alignment with Instruction Backtranslation
Aug 14, 2023



We present a scalable method to build a high quality instruction following language model by automatically labelling human-written text with corresponding instructions. Our approach, named instruction backtranslation, starts with a language model finetuned on a small amount of seed data, and a given web corpus. The seed model is used to construct training examples by generating instruction prompts for web documents (self-augmentation), and then selecting high quality examples from among these candidates (self-curation). This data is then used to finetune a stronger model. Finetuning LLaMa on two iterations of our approach yields a model that outperforms all other LLaMa-based models on the Alpaca leaderboard not relying on distillation data, demonstrating highly effective self-alignment.
FacTool: Factuality Detection in Generative AI -- A Tool Augmented Framework for Multi-Task and Multi-Domain Scenarios
Jul 26, 2023



The emergence of generative pre-trained models has facilitated the synthesis of high-quality text, but it has also posed challenges in identifying factual errors in the generated text. In particular: (1) A wider range of tasks now face an increasing risk of containing factual errors when handled by generative models. (2) Generated texts tend to be lengthy and lack a clearly defined granularity for individual facts. (3) There is a scarcity of explicit evidence available during the process of fact checking. With the above challenges in mind, in this paper, we propose FacTool, a task and domain agnostic framework for detecting factual errors of texts generated by large language models (e.g., ChatGPT). Experiments on four different tasks (knowledge-based QA, code generation, mathematical reasoning, and scientific literature review) show the efficacy of the proposed method. We release the code of FacTool associated with ChatGPT plugin interface at https://github.com/GAIR-NLP/factool .
Multi-Dimensional Evaluation of Text Summarization with In-Context Learning
Jun 01, 2023



Evaluation of natural language generation (NLG) is complex and multi-dimensional. Generated text can be evaluated for fluency, coherence, factuality, or any other dimensions of interest. Most frameworks that perform such multi-dimensional evaluation require training on large manually or synthetically generated datasets. In this paper, we study the efficacy of large language models as multi-dimensional evaluators using in-context learning, obviating the need for large training datasets. Our experiments show that in-context learning-based evaluators are competitive with learned evaluation frameworks for the task of text summarization, establishing state-of-the-art on dimensions such as relevance and factual consistency. We then analyze the effects of factors such as the selection and number of in-context examples on performance. Finally, we study the efficacy of in-context learning based evaluators in evaluating zero-shot summaries written by large language models such as GPT-3.
Look-back Decoding for Open-Ended Text Generation
May 22, 2023Given a prefix (context), open-ended generation aims to decode texts that are coherent, which don't abruptly drift from previous topics, and informative, which don't suffer from undesired repetitions. In this paper, we propose Look-back, an improved decoding algorithm that leverages the Kullback-Leibler divergence to track the distribution distance between current and historical decoding steps. Thus Look-back can automatically predict potential repetitive phrase and topic drift, and remove tokens that may cause the failure modes, restricting the next token probability distribution within a plausible distance to the history. We perform decoding experiments on document continuation and story generation, and demonstrate that Look-back is able to generate more fluent and coherent text, outperforming other strong decoding methods significantly in both automatic and human evaluations.
LIMA: Less Is More for Alignment
May 18, 2023



Large language models are trained in two stages: (1) unsupervised pretraining from raw text, to learn general-purpose representations, and (2) large scale instruction tuning and reinforcement learning, to better align to end tasks and user preferences. We measure the relative importance of these two stages by training LIMA, a 65B parameter LLaMa language model fine-tuned with the standard supervised loss on only 1,000 carefully curated prompts and responses, without any reinforcement learning or human preference modeling. LIMA demonstrates remarkably strong performance, learning to follow specific response formats from only a handful of examples in the training data, including complex queries that range from planning trip itineraries to speculating about alternate history. Moreover, the model tends to generalize well to unseen tasks that did not appear in the training data. In a controlled human study, responses from LIMA are either equivalent or strictly preferred to GPT-4 in 43% of cases; this statistic is as high as 58% when compared to Bard and 65% versus DaVinci003, which was trained with human feedback. Taken together, these results strongly suggest that almost all knowledge in large language models is learned during pretraining, and only limited instruction tuning data is necessary to teach models to produce high quality output.
Training Trajectories of Language Models Across Scales
Dec 19, 2022



Scaling up language models has led to unprecedented performance gains, but little is understood about how the training dynamics change as models get larger. How do language models of different sizes learn during pre-training? Why do larger language models demonstrate more desirable behaviors? In this paper, we analyze the intermediate training checkpoints of differently sized OPT models (Zhang et al.,2022)--from 125M to 175B parameters--on next-token prediction, sequence-level generation, and downstream tasks. We find that 1) at a given perplexity and independent of model sizes, a similar subset of training tokens see the most significant reduction in loss, with the rest stagnating or showing double-descent behavior; 2) early in training, all models learn to reduce the perplexity of grammatical sequences that contain hallucinations, with small models halting at this suboptimal distribution and larger ones eventually learning to assign these sequences lower probabilities; 3) perplexity is a strong predictor of in-context learning performance on 74 multiple-choice tasks from BIG-Bench, and this holds independent of the model size. Together, these results show that perplexity is more predictive of model behaviors than model size or training computation.
In-context Examples Selection for Machine Translation
Dec 05, 2022Large-scale generative models show an impressive ability to perform a wide range of Natural Language Processing (NLP) tasks using in-context learning, where a few examples are used to describe a task to the model. For Machine Translation (MT), these examples are typically randomly sampled from the development dataset with a similar distribution as the evaluation set. However, it is unclear how the choice of these in-context examples and their ordering impacts the output translation quality. In this work, we aim to understand the properties of good in-context examples for MT in both in-domain and out-of-domain settings. We show that the translation quality and the domain of the in-context examples matter and that 1-shot noisy unrelated example can have a catastrophic impact on output quality. While concatenating multiple random examples reduces the effect of noise, a single good prompt optimized to maximize translation quality on the development dataset can elicit learned information from the pre-trained language model. Adding similar examples based on an n-gram overlap with the test source significantly and consistently improves the translation quality of the outputs, outperforming a strong kNN-MT baseline in 2 out of 4 out-of-domain datasets.
Mega: Moving Average Equipped Gated Attention
Sep 26, 2022
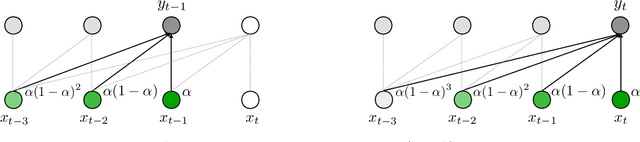
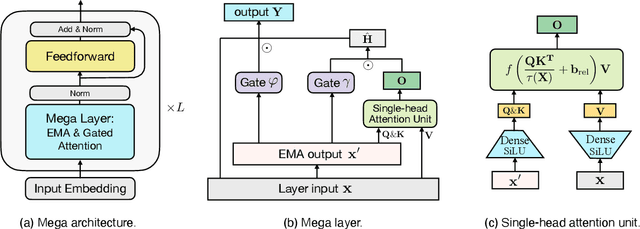
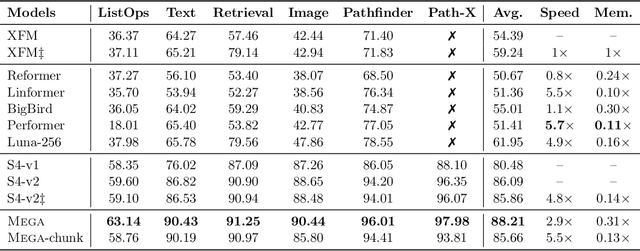
The design choices in the Transformer attention mechanism, including weak inductive bias and quadratic computational complexity, have limited its application for modeling long sequences. In this paper, we introduce Mega, a simple, theoretically grounded, single-head gated attention mechanism equipped with (exponential) moving average to incorporate inductive bias of position-aware local dependencies into the position-agnostic attention mechanism. We further propose a variant of Mega that offers linear time and space complexity yet yields only minimal quality loss, by efficiently splitting the whole sequence into multiple chunks with fixed length. Extensive experiments on a wide range of sequence modeling benchmarks, including the Long Range Arena, neural machine translation, auto-regressive language modeling, and image and speech classification, show that Mega achieves significant improvements over other sequence models, including variants of Transformers and recent state space models.
Prompt Consistency for Zero-Shot Task Generalization
Apr 29, 2022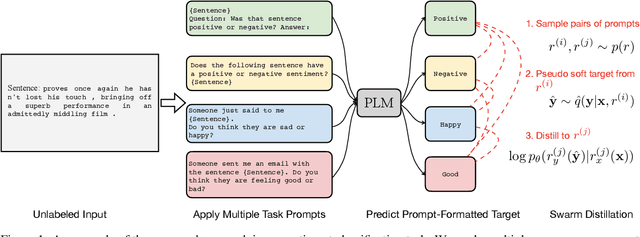
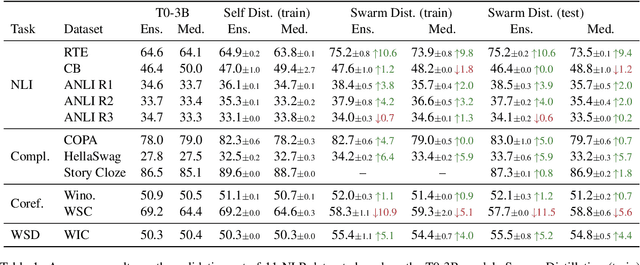
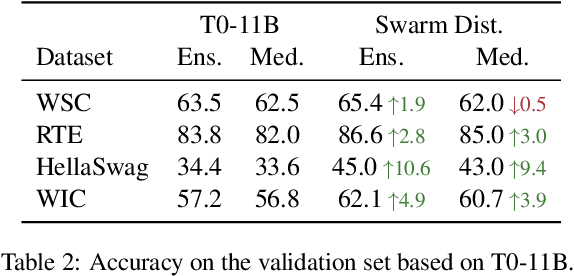
One of the most impressive results of recent NLP history is the ability of pre-trained language models to solve new tasks in a zero-shot setting. To achieve this, NLP tasks are framed as natural language prompts, generating a response indicating the predicted output. Nonetheless, the performance in such settings often lags far behind its supervised counterpart, suggesting a large space for potential improvement. In this paper, we explore methods to utilize unlabeled data to improve zero-shot performance. Specifically, we take advantage of the fact that multiple prompts can be used to specify a single task, and propose to regularize prompt consistency, encouraging consistent predictions over this diverse set of prompts. Our method makes it possible to fine-tune the model either with extra unlabeled training data, or directly on test input at inference time in an unsupervised manner. In experiments, our approach outperforms the state-of-the-art zero-shot learner, T0 (Sanh et al., 2022), on 9 out of 11 datasets across 4 NLP tasks by up to 10.6 absolute points in terms of accuracy. The gains are often attained with a small number of unlabeled examples.