 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Baseline for Semi-supervised Semantic Segmentation with Strong Data Augmentation
Apr 19, 2021

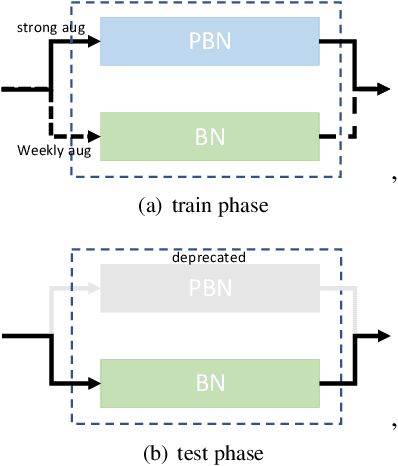

Recently, significant progress has been made on semantic segmentation. However, the success of supervised semantic segmentation typically relies on a large amount of labelled data, which is time-consuming and costly to obtain. Inspired by the success of semi-supervised learning methods in image classification, here we propose a simple yet effective semi-supervised learning framework for semantic segmentation. We demonstrate that the devil is in the details: a set of simple design and training techniques can collectively improve the performance of semi-supervised semantic segmentation significantly. Previous works [3, 27] fail to employ strong augmentation in pseudo label learning efficiently, as the large distribution change caused by strong augmentation harms the batch normalisation statistics. We design a new batch normalisation, namely distribution-specific batch normalisation (DSBN) to address this problem and demonstrate the importance of strong augmentation for semantic segmentation. Moreover, we design a self correction loss which is effective in noise resistance. We conduct a series of ablation studies to show the effectiveness of each component. Our method achieves state-of-the-art results in the semi-supervised settings on the Cityscapes and Pascal VOC datasets.
Kernel Agnostic Real-world Image Super-resolution
Apr 19, 2021
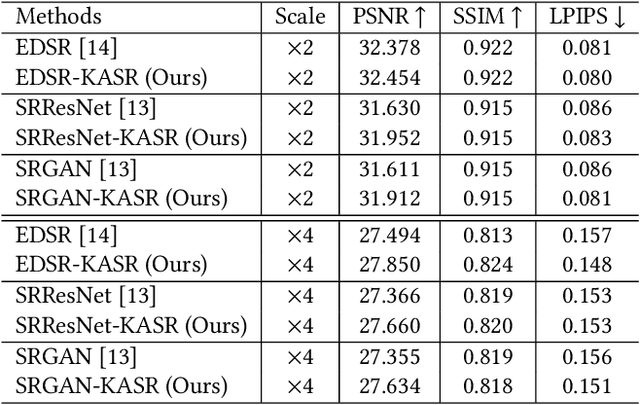
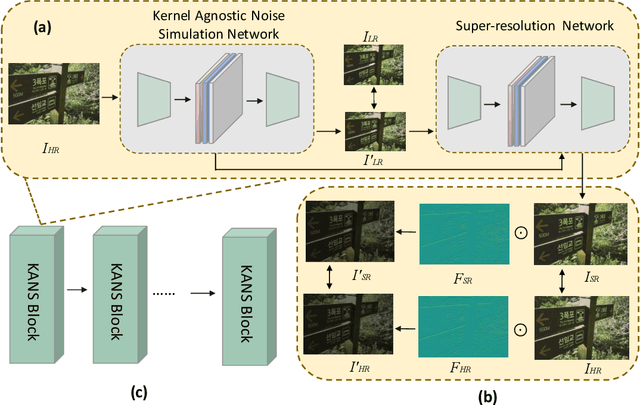
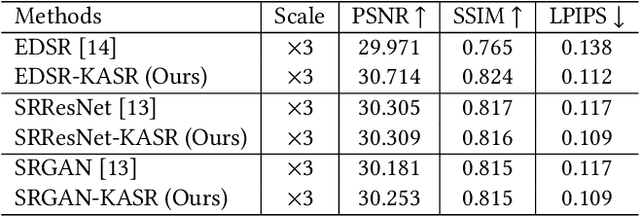
Recently, deep neural network models have achieved impressive results in various research fields. Come with it, an increasing number of attentions have been attracted by deep super-resolution (SR) approaches. Many existing methods attempt to restore high-resolution images from directly down-sampled low-resolution images or with the assumption of Gaussian degradation kernels with additive noises for their simplicities. However, in real-world scenarios, highly complex kernels and non-additive noises may be involved, even though the distorted images are visually similar to the clear ones. Existing SR models are facing difficulties to deal with real-world images under such circumstances. In this paper, we introduce a new kernel agnostic SR framework to deal with real-world image SR problem. The framework can be hanged seamlessly to multiple mainstream models. In the proposed framework, the degradation kernels and noises are adaptively modeled rather than explicitly specified. Moreover, we also propose an iterative supervision process and frequency-attended objective from orthogonal perspectives to further boost the performance. The experiments validate the effectiveness of the proposed framework on multiple real-world datasets.
An Adversarial Human Pose Estimation Network Injected with Graph Structure
Apr 05, 2021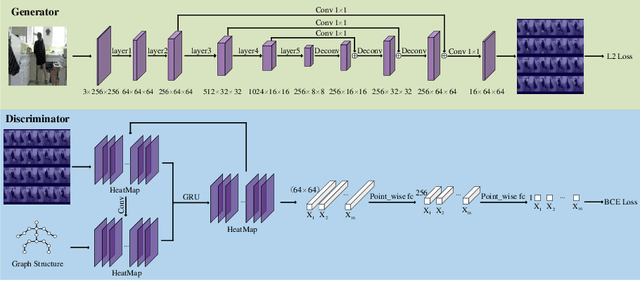
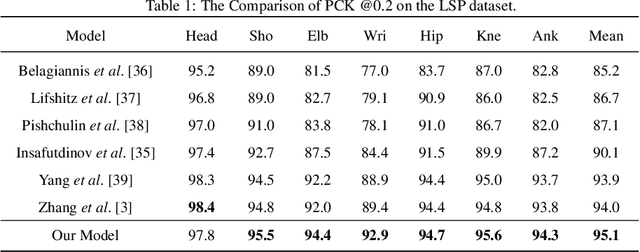
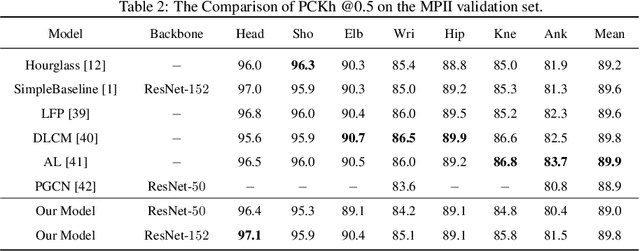

Because of the invisible human keypoints in images caused by illumination, occlusion and overlap, it is likely to produce unreasonable human pose prediction for most of the current human pose estimation methods. In this paper, we design a novel generative adversarial network (GAN) to improve the localization accuracy of visible joints when some joints are invisible. The network consists of two simple but efficient modules, Cascade Feature Network (CFN) and Graph Structure Network (GSN). First, the CFN utilizes the prediction maps from the previous stages to guide the prediction maps in the next stage to produce accurate human pose. Second, the GSN is designed to contribute to the localization of invisible joints by passing message among different joints. According to GAN, if the prediction pose produced by the generator G cannot be distinguished by the discriminator D, the generator network G has successfully obtained the underlying dependence of human joints. We conduct experiments on three widely used human pose estimation benchmark datasets, LSP, MPII and COCO, whose results show the effectiveness of our proposed framework.
TFPose: Direct Human Pose Estimation with Transformers
Mar 29, 2021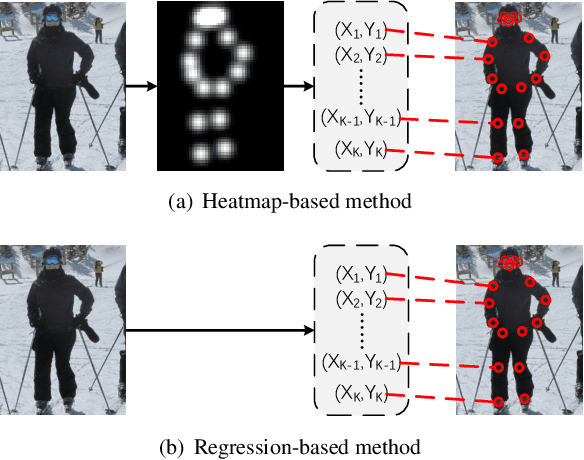

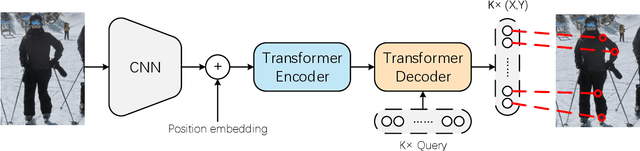
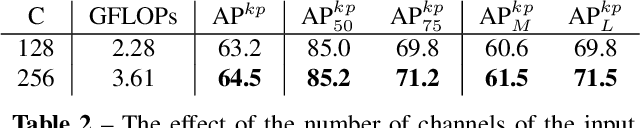
We propose a human pose estimation framework that solves the task in the regression-based fashion. Unlike previous regression-based methods, which often fall behind those state-of-the-art methods, we formulate the pose estimation task into a sequence prediction problem that can effectively be solved by transformers. Our framework is simple and direct, bypassing the drawbacks of the heatmap-based pose estimation. Moreover, with the attention mechanism in transformers, our proposed framework is able to adaptively attend to the features most relevant to the target keypoints, which largely overcomes the feature misalignment issue of previous regression-based methods and considerably improves the performance. Importantly, our framework can inherently take advantages of the structured relationship between keypoints. Experiments on the MS-COCO and MPII datasets demonstrate that our method can significantly improve the state-of-the-art of regression-based pose estimation and perform comparably with the best heatmap-based pose estimation methods.
FastFlowNet: A Lightweight Network for Fast Optical Flow Estimation
Mar 21, 2021
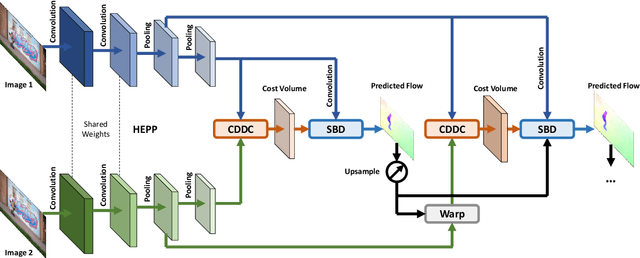
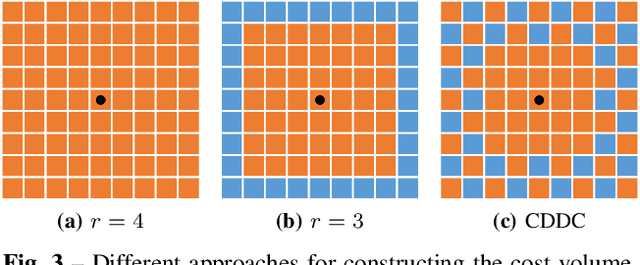
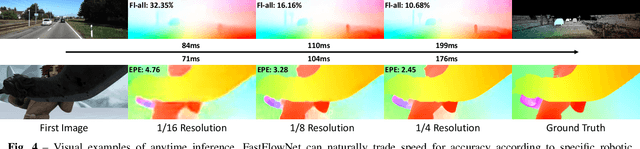
Dense optical flow estimation plays a key role in many robotic vision tasks. In the past few years, with the advent of deep learning, we have witnessed great progress in optical flow estimation. However, current networks often consist of a large number of parameters and require heavy computation costs, largely hindering its application on low power-consumption devices such as mobile phones. In this paper, we tackle this challenge and design a lightweight model for fast and accurate optical flow prediction. Our proposed FastFlowNet follows the widely-used coarse-to-fine paradigm with following innovations. First, a new head enhanced pooling pyramid (HEPP) feature extractor is employed to intensify high-resolution pyramid features while reducing parameters. Second, we introduce a new center dense dilated correlation (CDDC) layer for constructing compact cost volume that can keep large search radius with reduced computation burden. Third, an efficient shuffle block decoder (SBD) is implanted into each pyramid level to accelerate flow estimation with marginal drops in accuracy. Experiments on both synthetic Sintel data and real-world KITTI datasets demonstrate the effectiveness of the proposed approach, which needs only 1/10 computation of comparable networks to achieve on par accuracy. In particular, FastFlowNet only contains 1.37M parameters; and can execute at 90 FPS (with a single GTX 1080Ti) or 5.7 FPS (embedded Jetson TX2 GPU) on a pair of Sintel images of resolution 1024x436.
Generic Perceptual Loss for Modeling Structured Output Dependencies
Mar 18, 2021
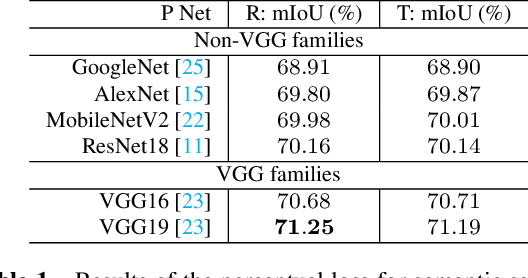
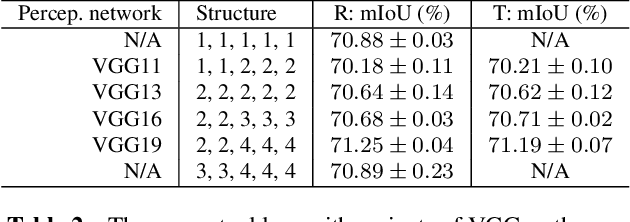
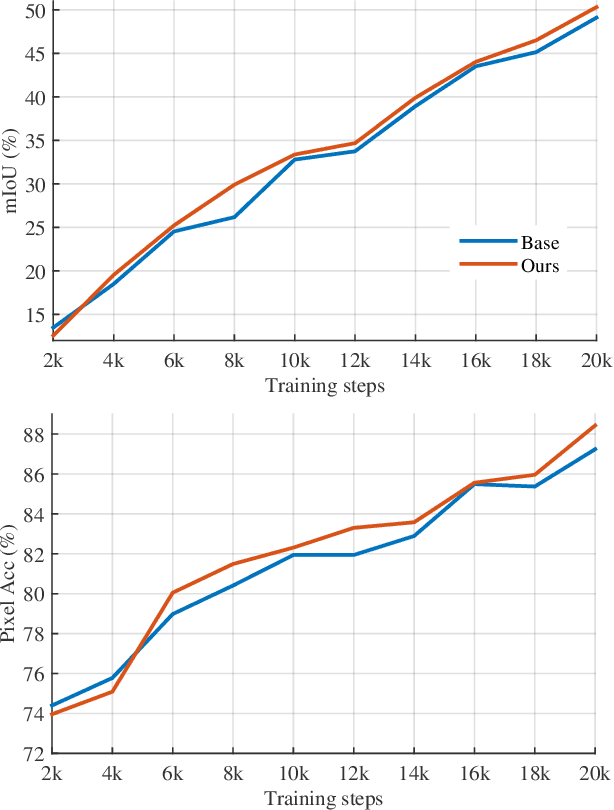
The perceptual loss has been widely used as an effective loss term in image synthesis tasks including image super-resolution, and style transfer. It was believed that the success lies in the high-level perceptual feature representations extracted from CNNs pretrained with a large set of images. Here we reveal that, what matters is the network structure instead of the trained weights. Without any learning, the structure of a deep network is sufficient to capture the dependencies between multiple levels of variable statistics using multiple layers of CNNs. This insight removes the requirements of pre-training and a particular network structure (commonly, VGG) that are previously assumed for the perceptual loss, thus enabling a significantly wider range of applications. To this end, we demonstrate that a randomly-weighted deep CNN can be used to model the structured dependencies of outputs. On a few dense per-pixel prediction tasks such as semantic segmentation, depth estimation and instance segmentation, we show improved results of using the extended randomized perceptual loss, compared to the baselines using pixel-wise loss alone. We hope that this simple, extended perceptual loss may serve as a generic structured-output loss that is applicable to most structured output learning tasks.
Conditional Positional Encodings for Vision Transformers
Mar 18, 2021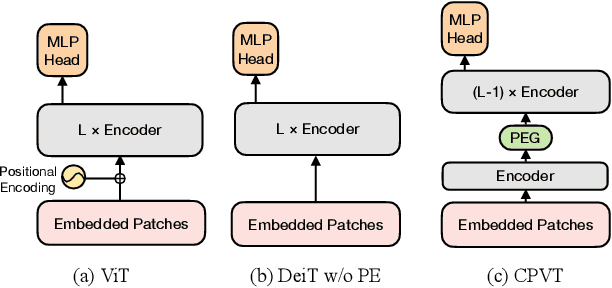
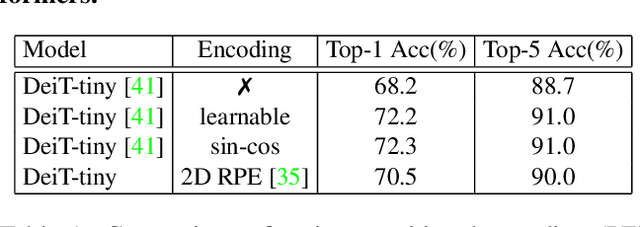
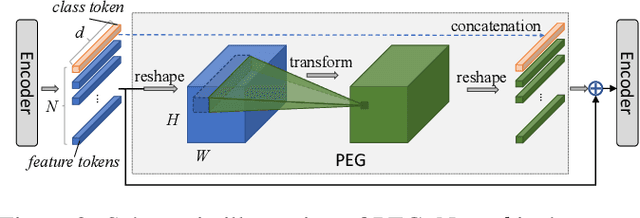
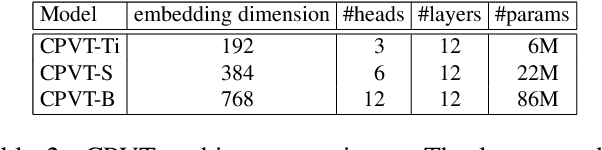
We propose a conditional positional encoding (CPE) scheme for vision Transformers. Unlike previous fixed or learnable positional encodings, which are pre-defined and independent of input tokens, CPE is dynamically generated and conditioned on the local neighborhood of the input tokens. As a result, CPE can easily generalize to the input sequences that are longer than what the model has ever seen during training. Besides, CPE can keep the desired translation-invariance in the image classification task, resulting in improved classification accuracy. CPE can be effortlessly implemented with a simple Position Encoding Generator (PEG), and it can be seamlessly incorporated into the current Transformer framework. Built on PEG, we present Conditional Position encoding Vision Transformer (CPVT). We demonstrate that CPVT has visually similar attention maps compared to those with learned positional encodings. Benefit from the conditional positional encoding scheme, we obtain state-of-the-art results on the ImageNet classification task compared with vision Transformers to date. Our code will be made available at https://github.com/Meituan-AutoML/CPVT .
Virtual Normal: Enforcing Geometric Constraints for Accurate and Robust Depth Prediction
Mar 09, 2021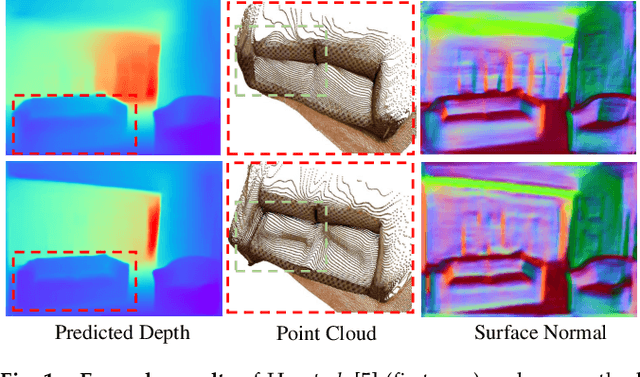
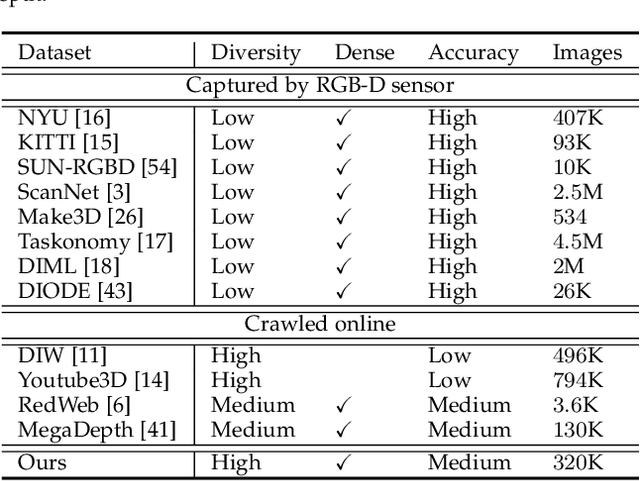
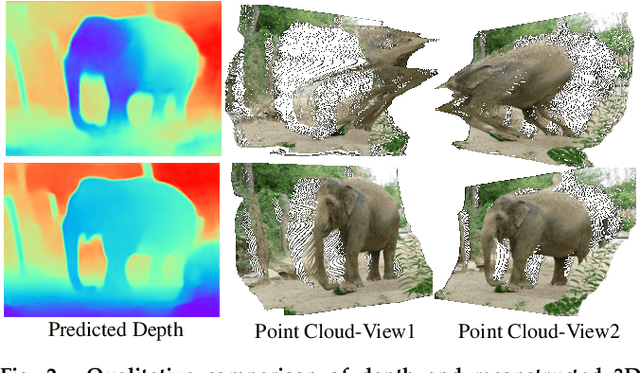
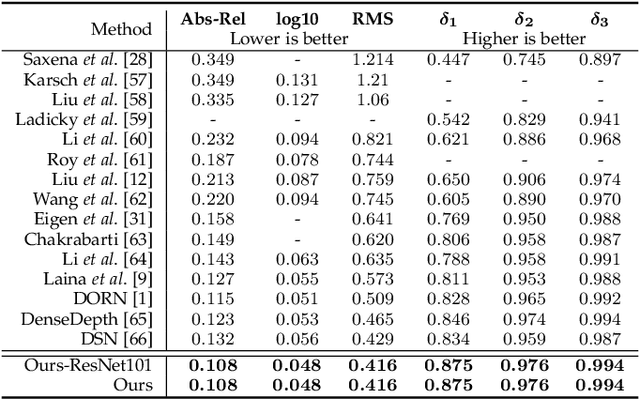
Monocular depth prediction plays a crucial role in understanding 3D scene geometry. Although recent methods have achieved impressive progress in terms of evaluation metrics such as the pixel-wise relative error, most methods neglect the geometric constraints in the 3D space. In this work, we show the importance of the high-order 3D geometric constraints for depth prediction. By designing a loss term that enforces a simple geometric constraint, namely, virtual normal directions determined by randomly sampled three points in the reconstructed 3D space, we significantly improve the accuracy and robustness of monocular depth estimation. Significantly, the virtual normal loss can not only improve the performance of learning metric depth, but also disentangle the scale information and enrich the model with better shape information. Therefore, when not having access to absolute metric depth training data, we can use virtual normal to learn a robust affine-invariant depth generated on diverse scenes. In experiments, We show state-of-the-art results of learning metric depth on NYU Depth-V2 and KITTI. From the high-quality predicted depth, we are now able to recover good 3D structures of the scene such as the point cloud and surface normal directly, eliminating the necessity of relying on additional models as was previously done. To demonstrate the excellent generalizability of learning affine-invariant depth on diverse data with the virtual normal loss, we construct a large-scale and diverse dataset for training affine-invariant depth, termed Diverse Scene Depth dataset (DiverseDepth), and test on five datasets with the zero-shot test setting. Code is available at: https://git.io/Depth
CoTr: Efficiently Bridging CNN and Transformer for 3D Medical Image Segmentation
Mar 04, 2021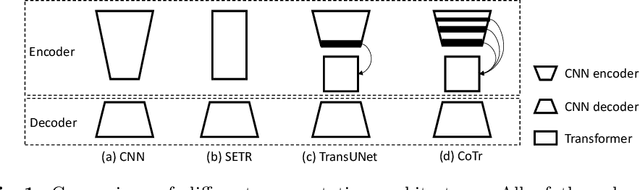
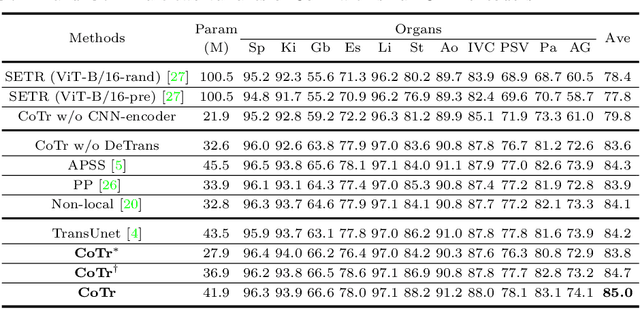
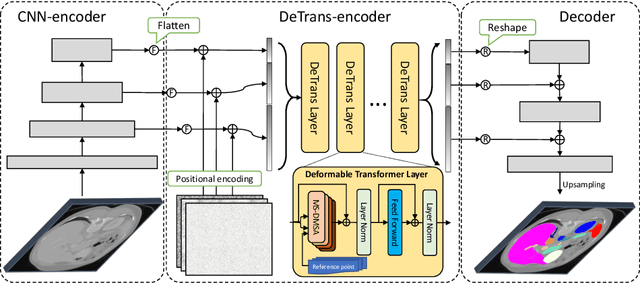
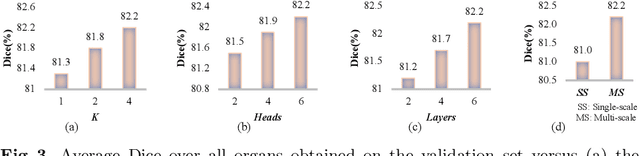
Convolutional neural networks (CNNs) have been the de facto standard for nowadays 3D medical image segmentation. The convolutional operations used in these networks, however, inevitably have limitations in modeling the long-range dependency due to their inductive bias of locality and weight sharing. Although Transformer was born to address this issue, it suffers from extreme computational and spatial complexities in processing high-resolution 3D feature maps. In this paper, we propose a novel framework that efficiently bridges a {\bf Co}nvolutional neural network and a {\bf Tr}ansformer {\bf (CoTr)} for accurate 3D medical image segmentation. Under this framework, the CNN is constructed to extract feature representations and an efficient deformable Transformer (DeTrans) is built to model the long-range dependency on the extracted feature maps. Different from the vanilla Transformer which treats all image positions equally, our DeTrans pays attention only to a small set of key positions by introducing the deformable self-attention mechanism. Thus, the computational and spatial complexities of DeTrans have been greatly reduced, making it possible to process the multi-scale and high-resolution feature maps, which are usually of paramount importance for image segmentation. We conduct an extensive evaluation on the Multi-Atlas Labeling Beyond the Cranial Vault (BCV) dataset that covers 11 major human organs. The results indicate that our CoTr leads to a substantial performance improvement over other CNN-based, transformer-based, and hybrid methods on the 3D multi-organ segmentation task. Code is available at \def\UrlFont{\rm\small\ttfamily} \url{https://github.com/YtongXie/CoTr}
Object Detection Made Simpler by Eliminating Heuristic NMS
Feb 25, 2021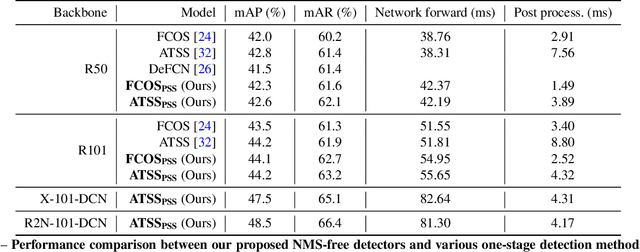
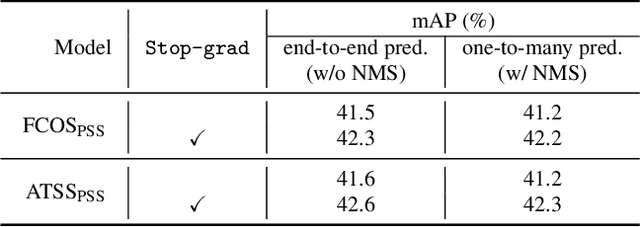
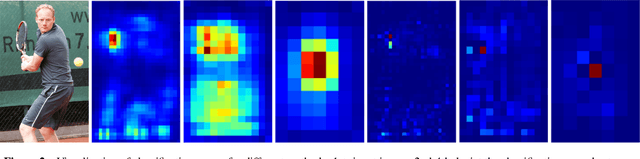
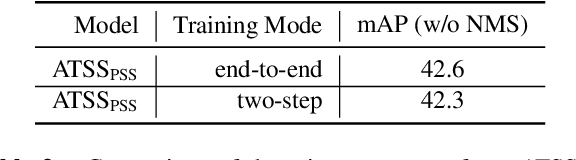
We show a simple NMS-free, end-to-end object detection framework, of which the network is a minimal modification to a one-stage object detector such as the FCOS detection model [Tian et al. 2019]. We attain on par or even improved detection accuracy compared with the original one-stage detector. It performs detection at almost the same inference speed, while being even simpler in that now the post-processing NMS (non-maximum suppression) is eliminated during inference. If the network is capable of identifying only one positive sample for prediction for each ground-truth object instance in an image, then NMS would become unnecessary. This is made possible by attaching a compact PSS head for automatic selection of the single positive sample for each instance (see Fig. 1). As the learning objective involves both one-to-many and one-to-one label assignments, there is a conflict in the labels of some training examples, making the learning challenging. We show that by employing a stop-gradient operation, we can successfully tackle this issue and train the detector. On the COCO dataset, our simple design achieves superior performance compared to both the FCOS baseline detector with NMS post-processing and the recent end-to-end NMS-free detectors. Our extensive ablation studies justify the rationale of the design choices.