 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAN: An Efficient Hierarchical Self-Attention Network for Skeleton-Based Gesture Recognition
Jun 25, 2021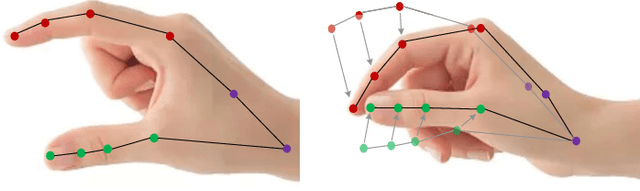
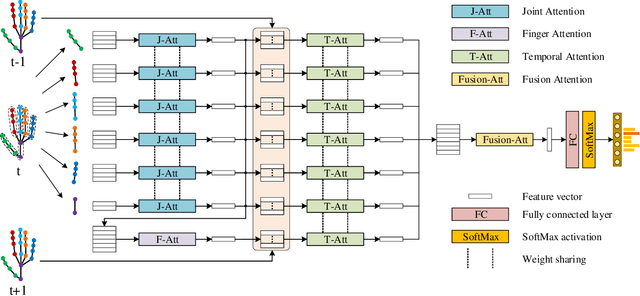
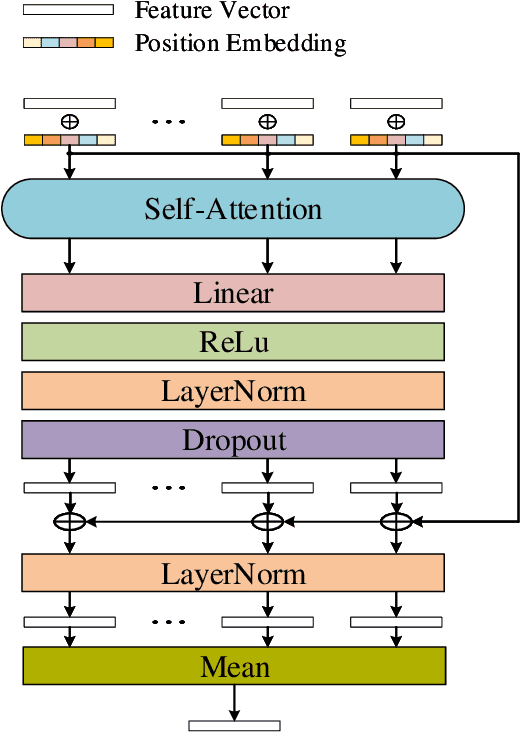
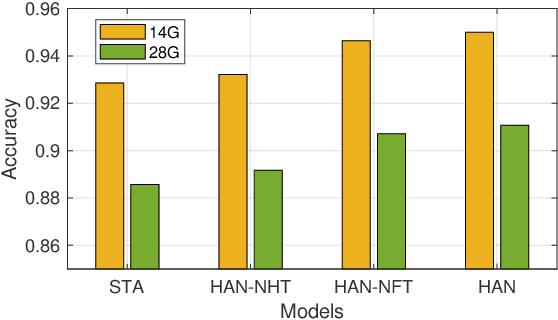
Previous methods for skeleton-based gesture recognition mostly arrange the skeleton sequence into a pseudo picture or spatial-temporal graph and apply deep Convolutional Neural Network (CNN) or Graph Convolutional Network (GCN) for feature extraction. Although achieving superior results, these methods have inherent limitations in dynamically capturing local features of interactive hand parts, and the computing efficiency still remains a serious issue. In this work, the self-attention mechanism is introduced to alleviate this problem. Considering the hierarchical structure of hand joints, we propose an efficient hierarchical self-attention network (HAN) for skeleton-based gesture recognition, which is based on pure self-attention without any CNN, RNN or GCN operators. Specifically, the joint self-attention module is used to capture spatial features of fingers, the finger self-attention module is designed to aggregate features of the whole hand. In terms of temporal features, the temporal self-attention module is utilized to capture the temporal dynamics of the fingers and the entire hand. Finally, these features are fused by the fusion self-attention module for gesture classification. Experiments show that our method achieves competitive results on three gesture recognition datasets with much lower computational complexity.
Adaptive Remote Sensing Image Attribute Learning for Active Object Detection
Jan 16, 2021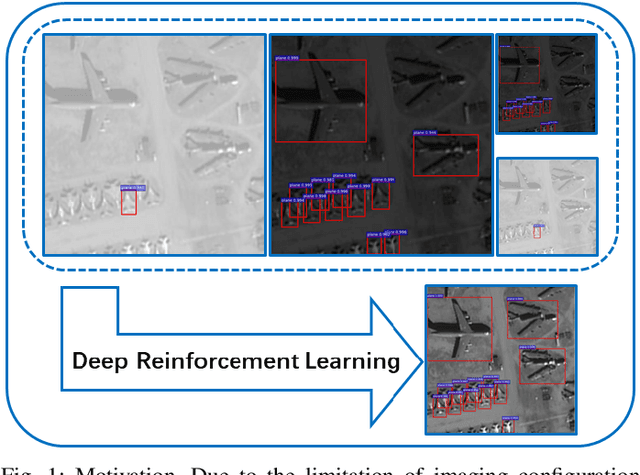
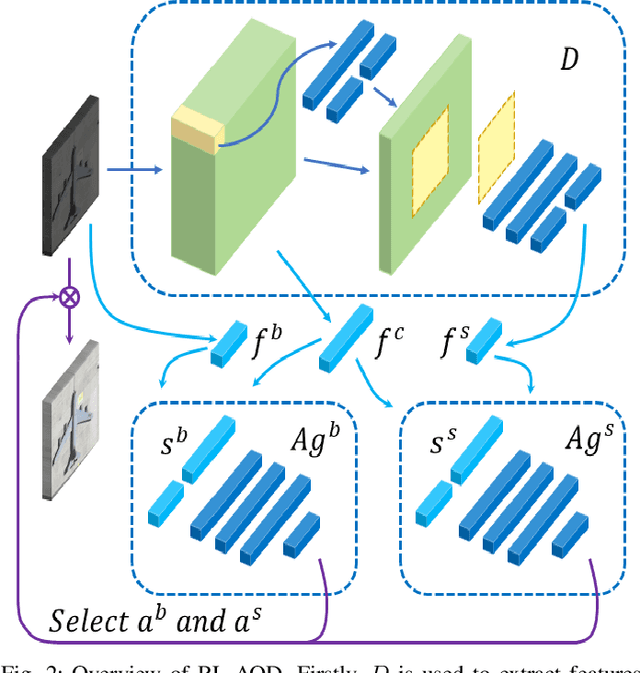
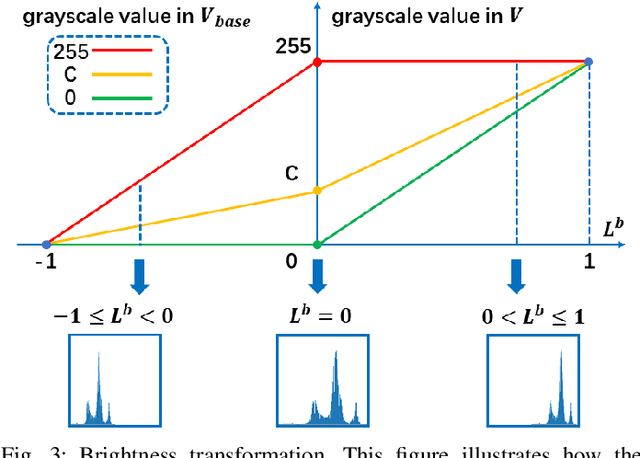
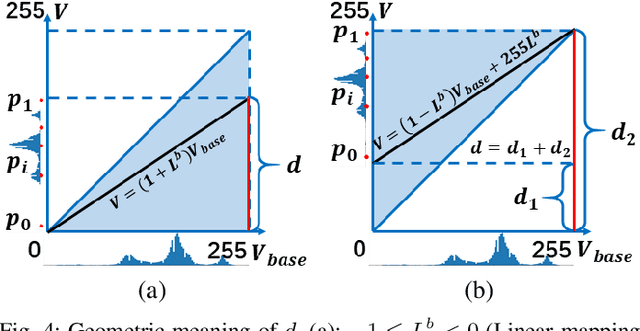
In recent years, deep learning methods bring incredible progress to the field of object detection. However, in the field of remote sensing image processing, existing methods neglect the relationship between imaging configuration and detection performance, and do not take into account the importance of detection performance feedback for improving image quality. Therefore, detection performance is limited by the passive nature of the conventional object detection framework. In order to solve the above limitations, this paper takes adaptive brightness adjustment and scale adjustment as examples, and proposes an active object detection method based on deep reinforcement learning. The goal of adaptive image attribute learning is to maximize the detection performance. With the help of active object detection and image attribute adjustment strategies, low-quality images can be converted into high-quality images, and the overall performance is improved without retraining the detector.
AugFPN: Improving Multi-scale Feature Learning for Object Detection
Dec 11, 2019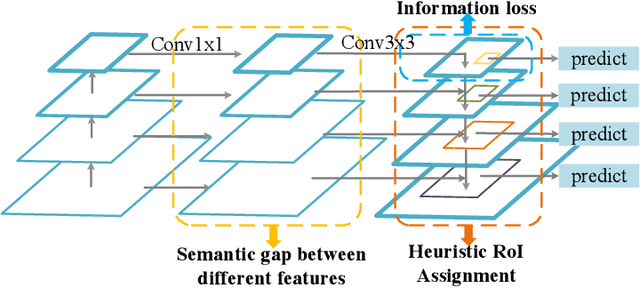
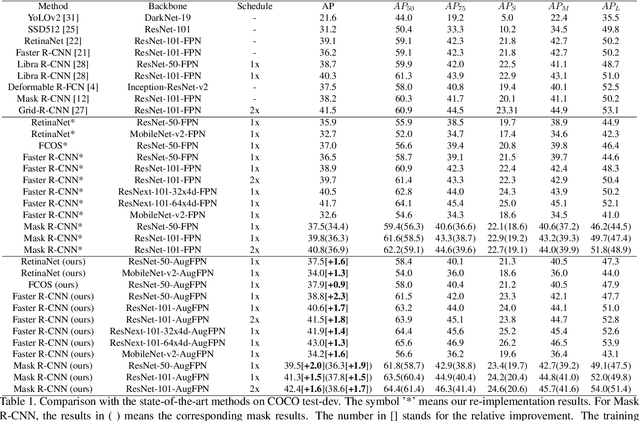
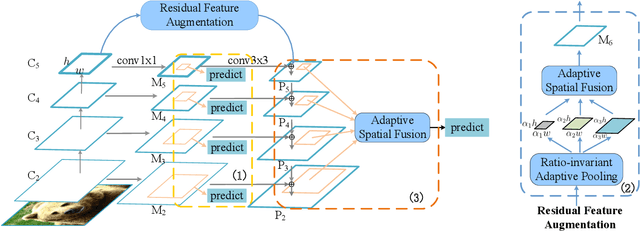
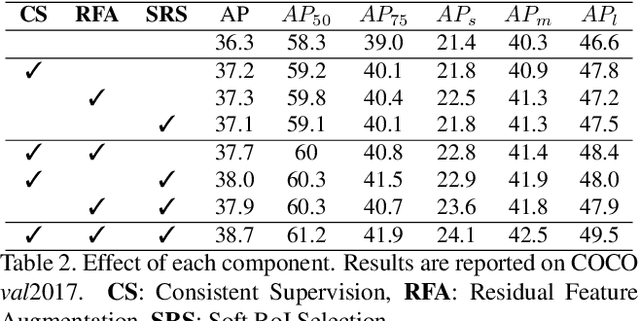
Current state-of-the-art detectors typically exploit feature pyramid to detect objects at different scales. Among them, FPN is one of the representative works that build a feature pyramid by multi-scale features summation. However, the design defects behind prevent the multi-scale features from being fully exploited. In this paper, we begin by first analyzing the design defects of feature pyramid in FPN, and then introduce a new feature pyramid architecture named AugFPN to address these problems. Specifically, AugFPN consists of three components: Consistent Supervision, Residual Feature Augmentation, and Soft RoI Selection. AugFPN narrows the semantic gaps between features of different scales before feature fusion through Consistent Supervision. In feature fusion, ratio-invariant context information is extracted by Residual Feature Augmentation to reduce the information loss of feature map at the highest pyramid level. Finally, Soft RoI Selection is employed to learn a better RoI feature adaptively after feature fusion. By replacing FPN with AugFPN in Faster R-CNN, our models achieve 2.3 and 1.6 points higher Average Precision (AP) when using ResNet50 and MobileNet-v2 as backbone respectively. Furthermore, AugFPN improves RetinaNet by 1.6 points AP and FCOS by 0.9 points AP when using ResNet50 as backbone. Codes will be made available.
Learning Motion Priors for Efficient Video Object Detection
Nov 13, 2019
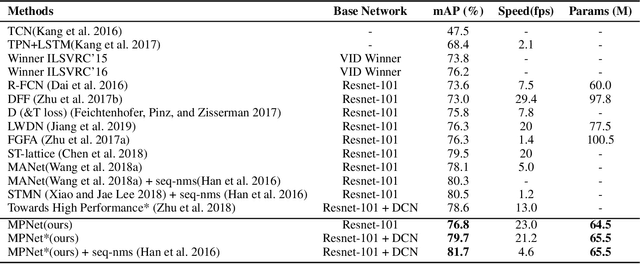
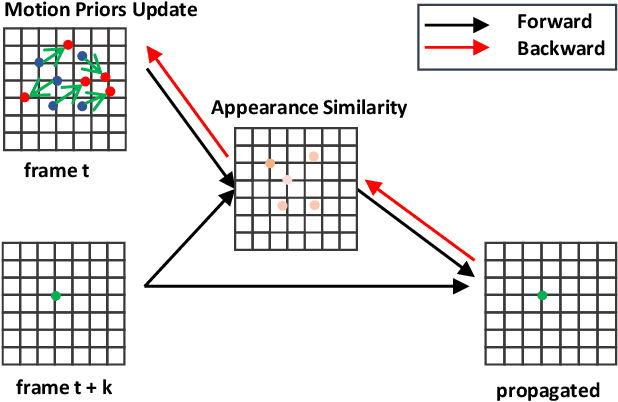
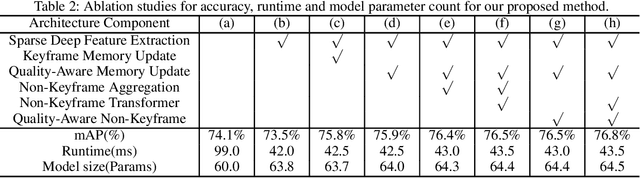
Convolution neural networks have achieved great progress on image object detection task. However, it is not trivial to transfer existing image object detection methods to the video domain since most of them are designed specifically for the image domain. Directly applying an image detector cannot achieve optimal results because of the lack of temporal information, which is vital for the video domain. Recently, image-level flow warping has been proposed to propagate features across different frames, aiming at achieving a better trade-off between accuracy and efficiency. However, the gap between image-level optical flow with high-level features can hinder the spatial propagation accuracy. To achieve a better trade-off between accuracy and efficiency, in this paper, we propose to learn motion priors for efficient video object detection. We first initialize some motion priors for each location and then use them to propagate features across frames. At the same time, Motion priors are updated adaptively to find better spatial correspondences. Without bells and whistles, the proposed framework achieves state-of-the-art performance on the ImageNet VID dataset with real-time speed.
FontGAN: A Unified Generative Framework for Chinese Character Stylization and De-stylization
Oct 28, 2019



Chinese character synthesis involves two related aspects, i.e., style maintenance and content consistency. Although some methods have achieved remarkable success in synthesizing a character with specified style from standard font, how to map characters to a specified style domain without losing their identifiability remains very challenging. In this paper, we propose a novel model named FontGAN, which integrates the character stylization and de-stylization into a unified framework. In our model, we decouple character images into style representation and content representation, which facilitates more precise control of these two types of variables, thereby improving the quality of the generated results. We also introduce two modules, namely, font consistency module (FCM) and content prior module (CPM). FCM exploits a category guided Kullback-Leibler loss to embedding the style representation into different Gaussian distributions. It constrains the characters of the same font in the training set globally. On the other hand, it enables our model to obtain style variables through sampling in testing phase. CPM provides content prior for the model to guide the content encoding process and alleviates the problem of stroke deficiency during de-stylization. Extensive experimental results on character stylization and de-stylization have demonstrated the effectiveness of our method.
DensePoint: Learning Densely Contextual Representation for Efficient Point Cloud Processing
Sep 09, 2019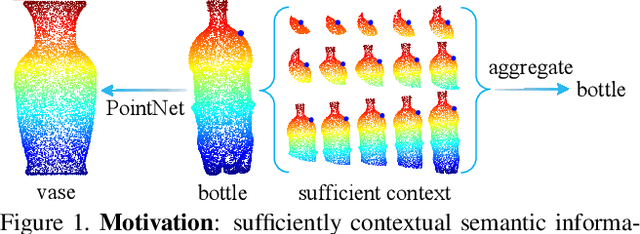
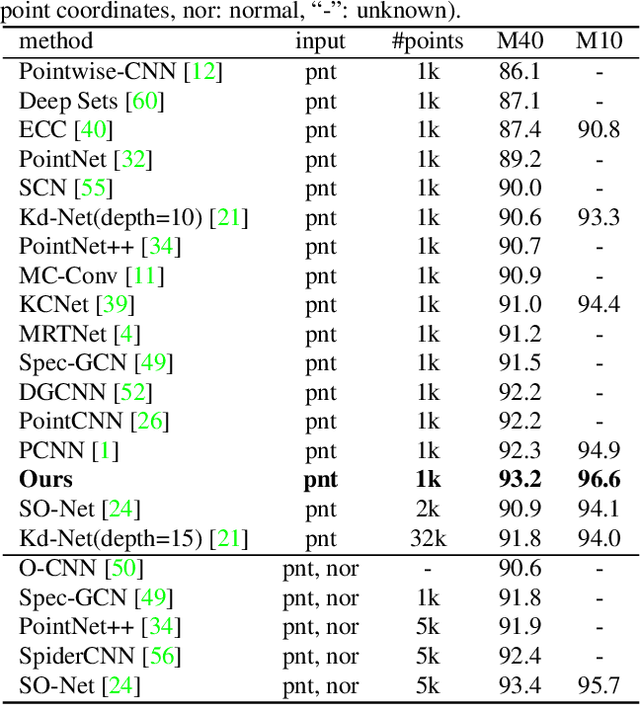
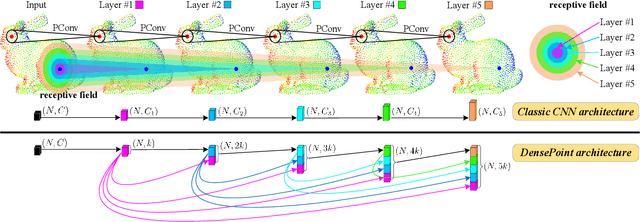
Point cloud processing is very challenging, as the diverse shapes formed by irregular points are often indistinguishable. A thorough grasp of the elusive shape requires sufficiently contextual semantic information, yet few works devote to this. Here we propose DensePoint, a general architecture to learn densely contextual representation for point cloud processing. Technically, it extends regular grid CNN to irregular point configuration by generalizing a convolution operator, which holds the permutation invariance of points, and achieves efficient inductive learning of local patterns. Architecturally, it finds inspiration from dense connection mode, to repeatedly aggregate multi-level and multi-scale semantics in a deep hierarchy. As a result, densely contextual information along with rich semantics, can be acquired by DensePoint in an organic manner, making it highly effective. Extensive experiments on challenging benchmarks across four tasks, as well as thorough model analysis, verify DensePoint achieves the state of the arts.
Relation-Shape Convolutional Neural Network for Point Cloud Analysis
May 26, 2019
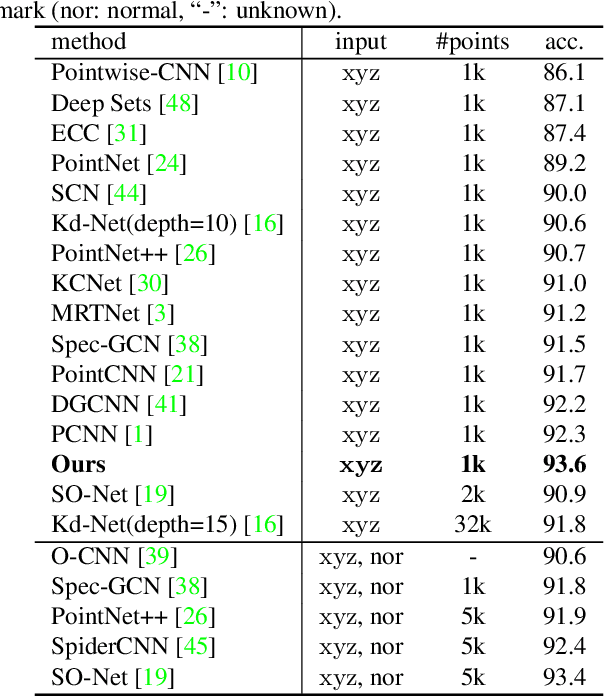

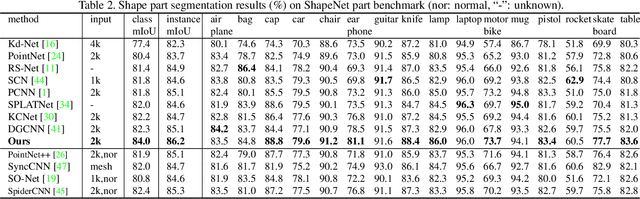
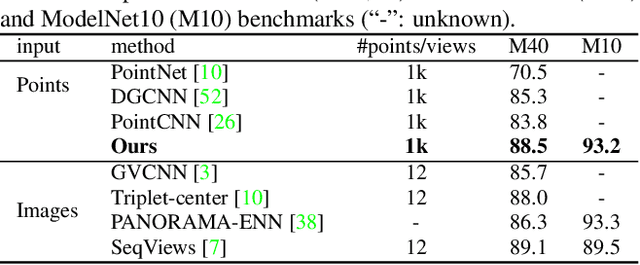
Point cloud analysis is very challenging, as the shape implied in irregular points is difficult to capture. In this paper, we propose RS-CNN, namely, Relation-Shape Convolutional Neural Network, which extends regular grid CNN to irregular configuration for point cloud analysis. The key to RS-CNN is learning from relation, i.e., the geometric topology constraint among points. Specifically, the convolutional weight for local point set is forced to learn a high-level relation expression from predefined geometric priors, between a sampled point from this point set and the others. In this way, an inductive local representation with explicit reasoning about the spatial layout of points can be obtained, which leads to much shape awareness and robustness. With this convolution as a basic operator, RS-CNN, a hierarchical architecture can be developed to achieve contextual shape-aware learning for point cloud analysis. Extensive experiments on challenging benchmarks across three tasks verify RS-CNN achieves the state of the arts.
LFFD: A Light and Fast Face Detector for Edge Devices
May 09, 2019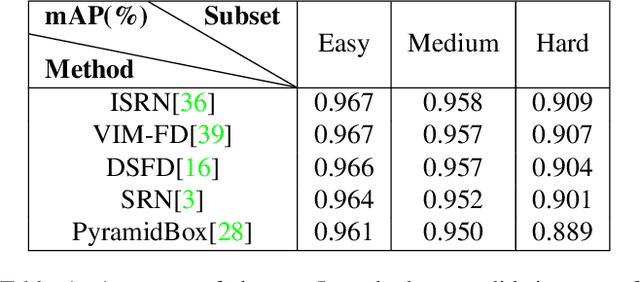
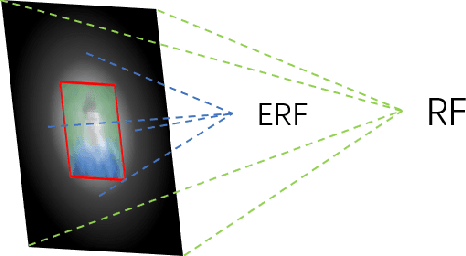
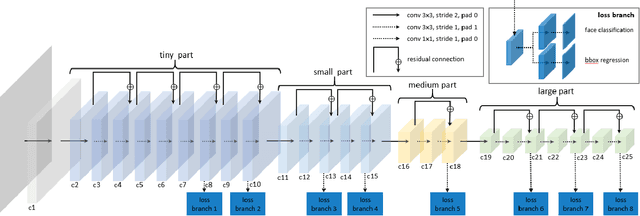
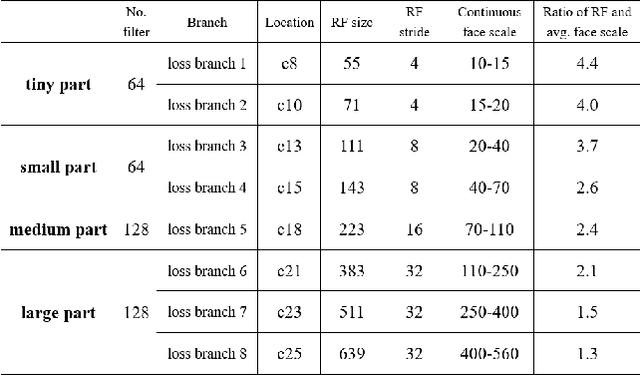
Face detection, as a fundamental technology for various applications, is always deployed on edge devices. There-fore, face detectors are supposed to have limited model size and fast inference speed. This paper introduces a Light and Fast Face Detector (LFFD) for edge devices. We rethink the receptive field (RF) in context of face detection and find that RFs can be used as inherent anchors instead of manually construction. Combining RF anchors and appropriate strides, the proposed method can cover a large range of continuous face scales with nearly 100% hit rate, rather than discrete scales. The insightful understanding of relations between effective receptive field (ERF) and face scales motivates an efficient backbone for one-stage detection. The backbone is characterized by eight detection branches and common building blocks, resulting in efficient computation. Comprehensive and extensive experiments on popular benchmarks: WIDER FACE and FDDB are conducted. A new evaluation schema is proposed for practical applications. Under the new schema, the proposed method can achieve superior accuracy (WIDER FACE Val/Test - Easy: 0.910/0.896, Medium: 0.880/0.865, Hard: 0.780/0.770; FDDB - discontinuous: 0.965, continuous: 0.719). Multiple hardware platforms are introduced to evaluate the running efficiency. The proposed methods can obtain fast inference speed (NVIDIA TITAN Xp: 131.45 FPS at 640480; NVIDIA TX2: 136.99 FPS at 160120; Raspberry Pi 3 Model B+: 8.44 FPS at 160120) with model size of 9 MB.
Differentiable Architecture Search with Ensemble Gumbel-Softmax
May 06, 2019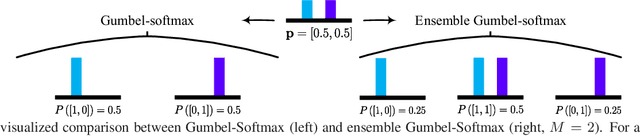
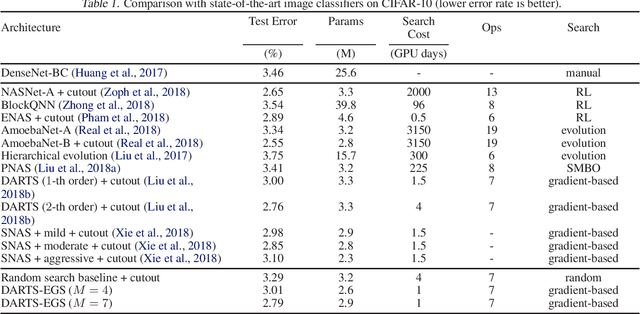
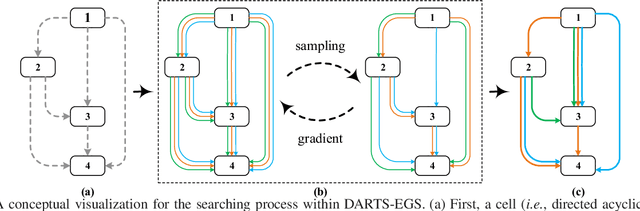
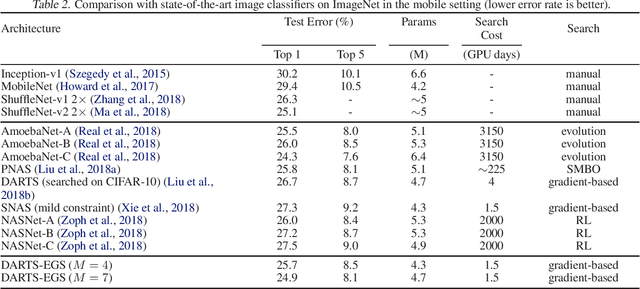
For network architecture search (NAS), it is crucial but challenging to simultaneously guarantee both effectiveness and efficiency. Towards achieving this goal, we develop a differentiable NAS solution, where the search space includes arbitrary feed-forward network consisting of the predefined number of connections. Benefiting from a proposed ensemble Gumbel-Softmax estimator, our method optimizes both the architecture of a deep network and its parameters in the same round of backward propagation, yielding an end-to-end mechanism of searching network architectures. Extensive experiments on a variety of popular datasets strongly evidence that our method is capable of discovering high-performance architectures, while guaranteeing the requisite efficiency during searching.
Deep Discriminative Clustering Analysis
May 05, 2019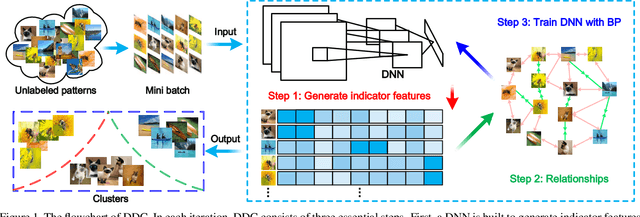
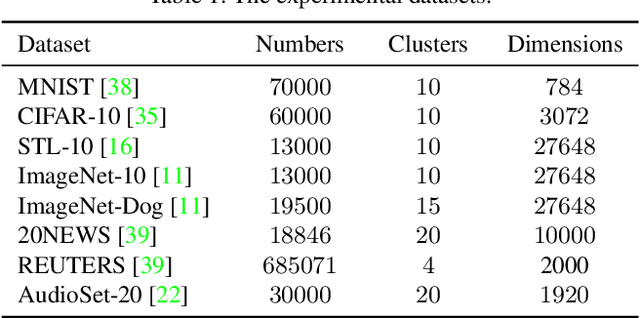
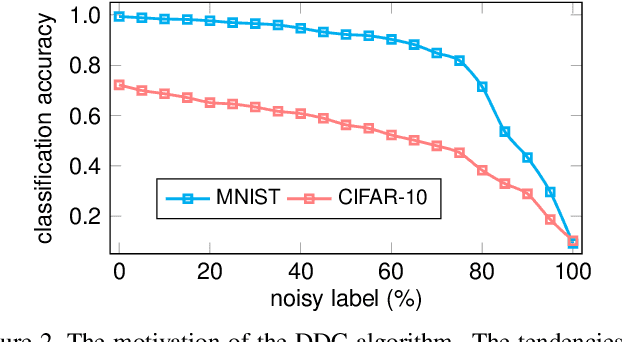
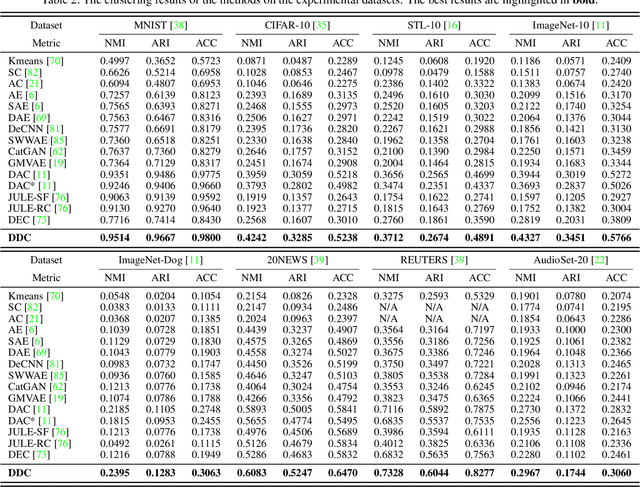
Traditional clustering methods often perform clustering with low-level indiscriminative representations and ignore relationships between patterns, resulting in slight achievements in the era of deep learning. To handle this problem, we develop Deep Discriminative Clustering (DDC) that models the clustering task by investigating relationships between patterns with a deep neural network. Technically, a global constraint is introduced to adaptively estimate the relationships, and a local constraint is developed to endow the network with the capability of learning high-level discriminative representations. By iteratively training the network and estimating the relationships in a mini-batch manner, DDC theoretically converges and the trained network enables to generate a group of discriminative representations that can be treated as clustering centers for straightway clustering. Extensive experiments strongly demonstrate that DDC outperforms current methods on eight image, text and audio datasets concurrently.