 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlayer-Centric Multimodal Prompt Generation for Large Language Model Based Identity-Aware Basketball Video Captioning
Jul 27, 2025Existing sports video captioning methods often focus on the action yet overlook player identities, limiting their applicability. Although some methods integrate extra information to generate identity-aware descriptions, the player identities are sometimes incorrect because the extra information is independent of the video content. This paper proposes a player-centric multimodal prompt generation network for identity-aware sports video captioning (LLM-IAVC), which focuses on recognizing player identities from a visual perspective. Specifically, an identity-related information extraction module (IRIEM) is designed to extract player-related multimodal embeddings. IRIEM includes a player identification network (PIN) for extracting visual features and player names, and a bidirectional semantic interaction module (BSIM) to link player features with video content for mutual enhancement. Additionally, a visual context learning module (VCLM) is designed to capture the key video context information. Finally, by integrating the outputs of the above modules as the multimodal prompt for the large language model (LLM), it facilitates the generation of descriptions with player identities. To support this work, we construct a new benchmark called NBA-Identity, a large identity-aware basketball video captioning dataset with 9,726 videos covering 9 major event types. The experimental results on NBA-Identity and VC-NBA-2022 demonstrate that our proposed model achieves advanced performance. Code and dataset are publicly available at https://github.com/Zeyu1226-mt/LLM-IAVC.
Knowledge Graph Supported Benchmark and Video Captioning for Basketball
Jan 25, 2024



Despite the recent emergence of video captioning models, how to generate the text description with specific entity names and fine-grained actions is far from being solved, which however has great applications such as basketball live text broadcast. In this paper, a new multimodal knowledge supported basketball benchmark for video captioning is proposed. Specifically, we construct a Multimodal Basketball Game Knowledge Graph (MbgKG) to provide knowledge beyond videos. Then, a Multimodal Basketball Game Video Captioning (MbgVC) dataset that contains 9 types of fine-grained shooting events and 286 players' knowledge (i.e., images and names) is constructed based on MbgKG. We develop a novel framework in the encoder-decoder form named Entity-Aware Captioner (EAC) for basketball live text broadcast. The temporal information in video is encoded by introducing the bi-directional GRU (Bi-GRU) module. And the multi-head self-attention module is utilized to model the relationships among the players and select the key players. Besides, we propose a new performance evaluation metric named Game Description Score (GDS), which measures not only the linguistic performance but also the accuracy of the names prediction. Extensive experiments on MbgVC dataset demonstrate that EAC effectively leverages external knowledge and outperforms advanced video captioning models. The proposed benchmark and corresponding codes will be publicly available soon.
Knowledge Augmented Relation Inference for Group Activity Recognition
Mar 01, 2023



Most existing group activity recognition methods construct spatial-temporal relations merely based on visual representation. Some methods introduce extra knowledge, such as action labels, to build semantic relations and use them to refine the visual presentation. However, the knowledge they explored just stay at the semantic-level, which is insufficient for pursing notable accuracy. In this paper, we propose to exploit knowledge concretization for the group activity recognition, and develop a novel Knowledge Augmented Relation Inference framework that can effectively use the concretized knowledge to improve the individual representations. Specifically, the framework consists of a Visual Representation Module to extract individual appearance features, a Knowledge Augmented Semantic Relation Module explore semantic representations of individual actions, and a Knowledge-Semantic-Visual Interaction Module aims to integrate visual and semantic information by the knowledge. Benefiting from these modules, the proposed framework can utilize knowledge to enhance the relation inference process and the individual representations, thus improving the performance of group activity recognition. Experimental results on two public datasets show that the proposed framework achieves competitive performance compared with state-of-the-art methods.
QuickSkill: Novice Skill Estimation in Online Multiplayer Games
Aug 15, 2022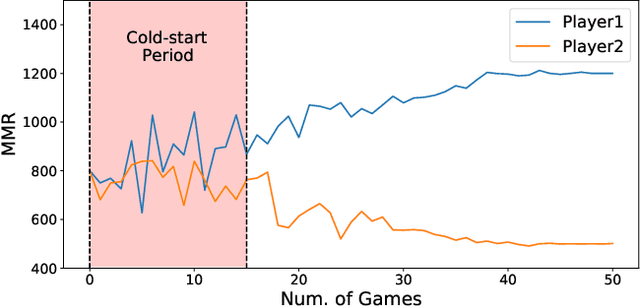

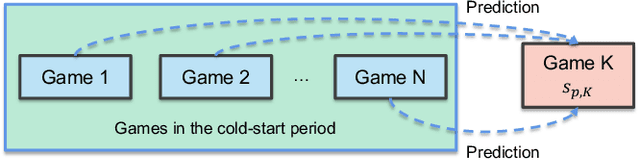
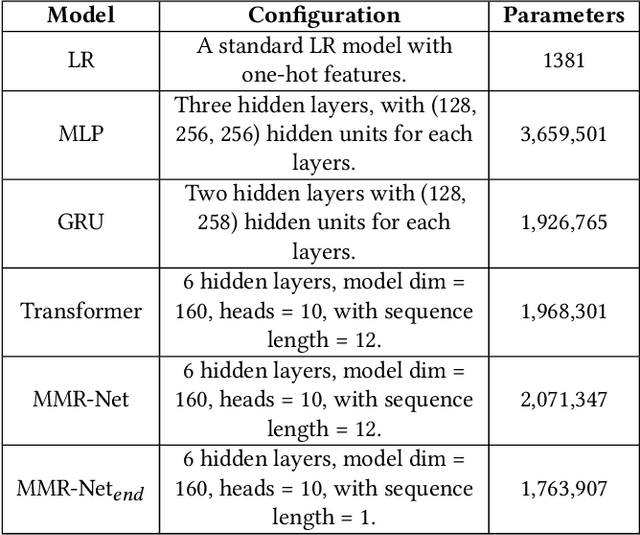
Matchmaking systems are vital for creating fair matches in online multiplayer games, which directly affects players' satisfactions and game experience. Most of the matchmaking systems largely rely on precise estimation of players' game skills to construct equitable games. However, the skill rating of a novice is usually inaccurate, as current matchmaking rating algorithms require considerable amount of games for learning the true skill of a new player. Using these unreliable skill scores at early stages for matchmaking usually leads to disparities in terms of team performance, which causes negative game experience. This is known as the ''cold-start'' problem for matchmaking rating algorithms. To overcome this conundrum, this paper proposes QuickSKill, a deep learning based novice skill estimation framework to quickly probe abilities of new players in online multiplayer games. QuickSKill extracts sequential performance features from initial few games of a player to predict his/her future skill rating with a dedicated neural network, thus delivering accurate skill estimation at the player's early game stage. By employing QuickSKill for matchmaking, game fairness can be dramatically improved in the initial cold-start period. We conduct experiments in a popular mobile multiplayer game in both offline and online scenarios. Results obtained with two real-world anonymized gaming datasets demonstrate that proposed QuickSKill delivers precise estimation of game skills for novices, leading to significantly lower team skill disparities and better player game experience. To the best of our knowledge, proposed QuickSKill is the first framework that tackles the cold-start problem for traditional skill rating algorithms.
Learning to Compose Diversified Prompts for Image Emotion Classification
Jan 26, 2022
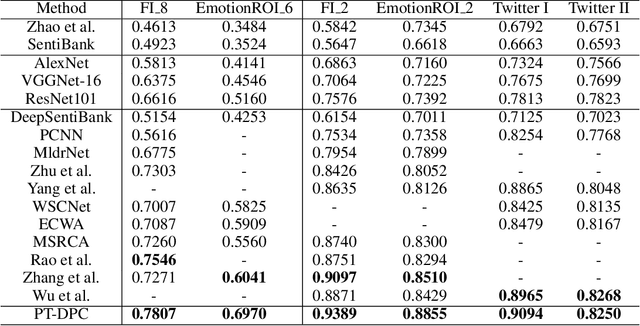
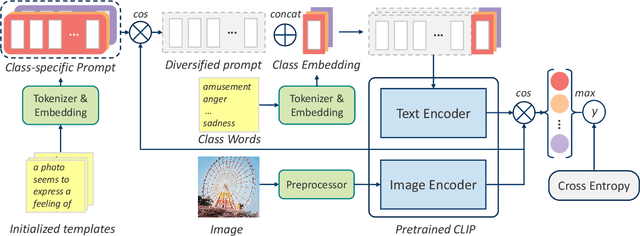

Contrastive Language-Image Pre-training (CLIP) represents the latest incarnation of pre-trained vision-language models. Although CLIP has recently shown its superior power on a wide range of downstream vision-language tasks like Visual Question Answering, it is still underexplored for Image Emotion Classification (IEC). Adapting CLIP to the IEC task has three significant challenges, tremendous training objective gap between pretraining and IEC, shared suboptimal and invariant prompts for all instances. In this paper, we propose a general framework that shows how CLIP can be effectively applied to IEC. We first introduce a prompt tuning method that mimics the pretraining objective of CLIP and thus can leverage the rich image and text semantics entailed in CLIP. Then we automatically compose instance-specific prompts by conditioning them on the categories and image contents of instances, diversifying prompts and avoiding suboptimal problems. Evaluations on six widely-used affective datasets demonstrate that our proposed method outperforms the state-of-the-art methods to a large margin (i.e., up to 9.29% accuracy gain on EmotionROI dataset) on IEC tasks, with only a few parameters trained. Our codes will be publicly available for research purposes.
Fusing Motion Patterns and Key Visual Information for Semantic Event Recognition in Basketball Videos
Jul 13, 2020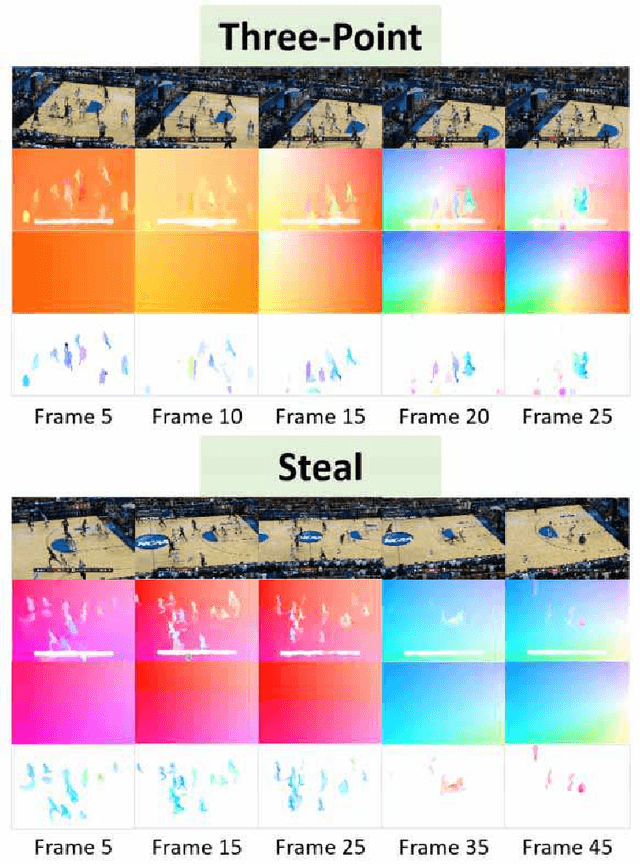
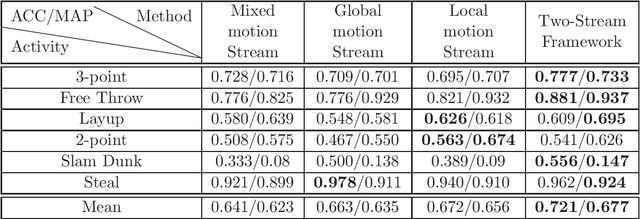


Many semantic events in team sport activities e.g. basketball often involve both group activities and the outcome (score or not). Motion patterns can be an effective means to identify different activities. Global and local motions have their respective emphasis on different activities, which are difficult to capture from the optical flow due to the mixture of global and local motions. Hence it calls for a more effective way to separate the global and local motions. When it comes to the specific case for basketball game analysis, the successful score for each round can be reliably detected by the appearance variation around the basket. Based on the observations, we propose a scheme to fuse global and local motion patterns (MPs) and key visual information (KVI) for semantic event recognition in basketball videos. Firstly, an algorithm is proposed to estimate the global motions from the mixed motions based on the intrinsic property of camera adjustments. And the local motions could be obtained from the mixed and global motions. Secondly, a two-stream 3D CNN framework is utilized for group activity recognition over the separated global and local motion patterns. Thirdly, the basket is detected and its appearance features are extracted through a CNN structure. The features are utilized to predict the success or failure. Finally, the group activity recognition and success/failure prediction results are integrated using the kronecker product for event recognition. Experiments on NCAA dataset demonstrate that the proposed method obtains state-of-the-art performance.
LFFD: A Light and Fast Face Detector for Edge Devices
May 09, 2019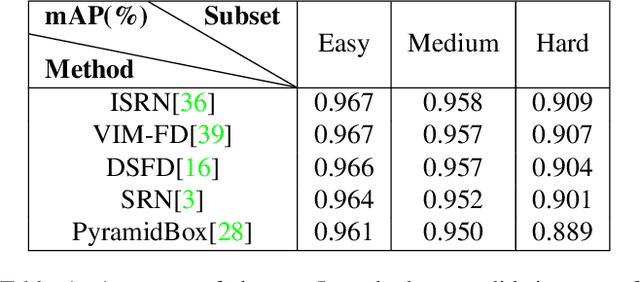
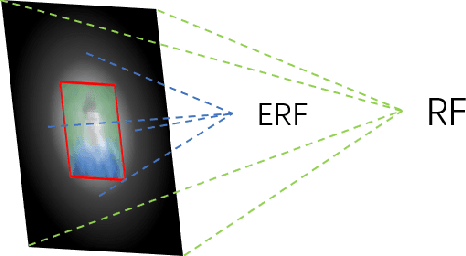
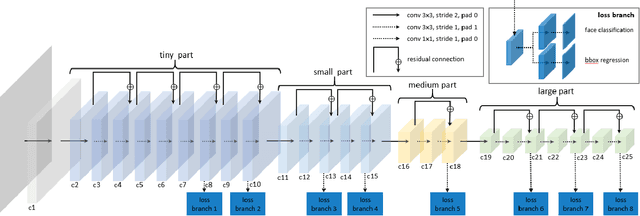
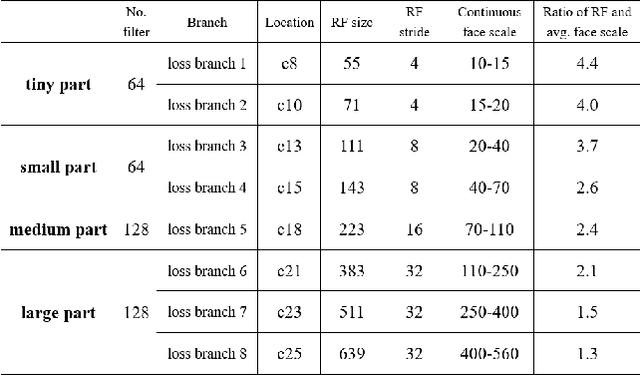
Face detection, as a fundamental technology for various applications, is always deployed on edge devices. There-fore, face detectors are supposed to have limited model size and fast inference speed. This paper introduces a Light and Fast Face Detector (LFFD) for edge devices. We rethink the receptive field (RF) in context of face detection and find that RFs can be used as inherent anchors instead of manually construction. Combining RF anchors and appropriate strides, the proposed method can cover a large range of continuous face scales with nearly 100% hit rate, rather than discrete scales. The insightful understanding of relations between effective receptive field (ERF) and face scales motivates an efficient backbone for one-stage detection. The backbone is characterized by eight detection branches and common building blocks, resulting in efficient computation. Comprehensive and extensive experiments on popular benchmarks: WIDER FACE and FDDB are conducted. A new evaluation schema is proposed for practical applications. Under the new schema, the proposed method can achieve superior accuracy (WIDER FACE Val/Test - Easy: 0.910/0.896, Medium: 0.880/0.865, Hard: 0.780/0.770; FDDB - discontinuous: 0.965, continuous: 0.719). Multiple hardware platforms are introduced to evaluate the running efficiency. The proposed methods can obtain fast inference speed (NVIDIA TITAN Xp: 131.45 FPS at 640480; NVIDIA TX2: 136.99 FPS at 160120; Raspberry Pi 3 Model B+: 8.44 FPS at 160120) with model size of 9 MB.
Ontology Based Global and Collective Motion Patterns for Event Classification in Basketball Videos
Mar 19, 2019
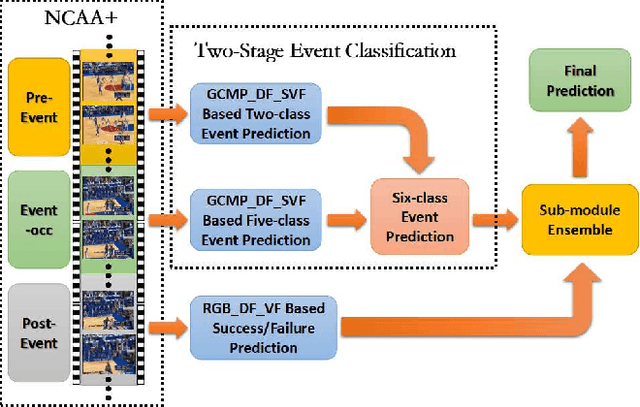

In multi-person videos, especially team sport videos, a semantic event is usually represented as a confrontation between two teams of players, which can be represented as collective motion. In broadcast basketball videos, specific camera motions are used to present specific events. Therefore, a semantic event in broadcast basketball videos is closely related to both the global motion (camera motion) and the collective motion. A semantic event in basketball videos can be generally divided into three stages: pre-event, event occurrence (event-occ), and post-event. In this paper, we propose an ontology-based global and collective motion pattern (On_GCMP) algorithm for basketball event classification. First, a two-stage GCMP based event classification scheme is proposed. The GCMP is extracted using optical flow. The two-stage scheme progressively combines a five-class event classification algorithm on event-occs and a two-class event classification algorithm on pre-events. Both algorithms utilize sequential convolutional neural networks (CNNs) and long short-term memory (LSTM) networks to extract the spatial and temporal features of GCMP for event classification. Second, we utilize post-event segments to predict success/failure using deep features of images in the video frames (RGB_DF_VF) based algorithms. Finally the event classification results and success/failure classification results are integrated to obtain the final results. To evaluate the proposed scheme, we collected a new dataset called NCAA+, which is automatically obtained from the NCAA dataset by extending the fixed length of video clips forward and backward of the corresponding semantic events. The experimental results demonstrate that the proposed scheme achieves the mean average precision of 58.10% on NCAA+. It is higher by 6.50% than state-of-the-art on NCAA.