 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Radiance Transfer Fields for Relightable Novel-view Synthesis with Global Illumination
Jul 27, 2022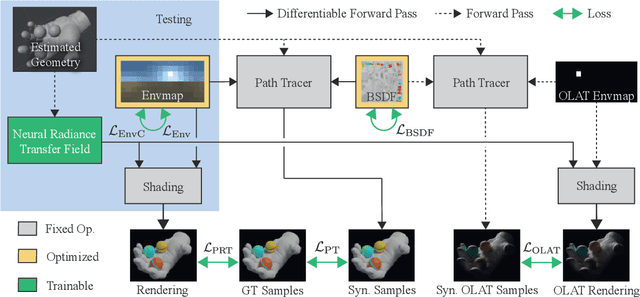
Given a set of images of a scene, the re-rendering of this scene from novel views and lighting conditions is an important and challenging problem in Computer Vision and Graphics. On the one hand, most existing works in Computer Vision usually impose many assumptions regarding the image formation process, e.g. direct illumination and predefined materials, to make scene parameter estimation tractable. On the other hand, mature Computer Graphics tools allow modeling of complex photo-realistic light transport given all the scene parameters. Combining these approaches, we propose a method for scene relighting under novel views by learning a neural precomputed radiance transfer function, which implicitly handles global illumination effects using novel environment maps. Our method can be solely supervised on a set of real images of the scene under a single unknown lighting condition. To disambiguate the task during training, we tightly integrate a differentiable path tracer in the training process and propose a combination of a synthesized OLAT and a real image loss. Results show that the recovered disentanglement of scene parameters improves significantly over the current state of the art and, thus, also our re-rendering results are more realistic and accurate.
NeuRIS: Neural Reconstruction of Indoor Scenes Using Normal Priors
Jun 27, 2022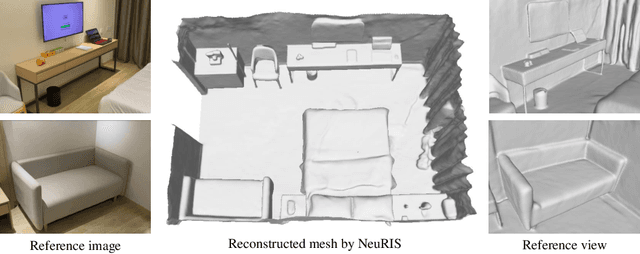
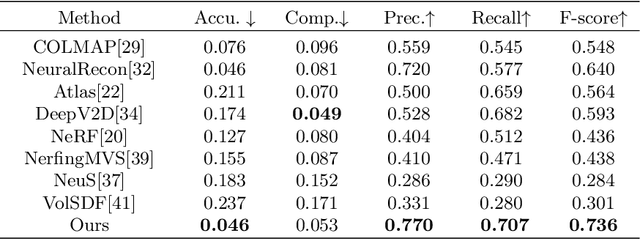
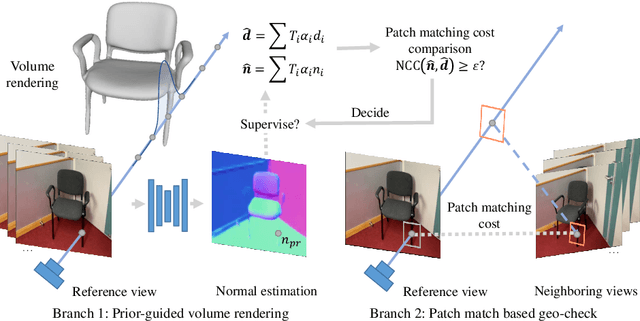

Reconstructing 3D indoor scenes from 2D images is an important task in many computer vision and graphics applications. A main challenge in this task is that large texture-less areas in typical indoor scenes make existing methods struggle to produce satisfactory reconstruction results. We propose a new method, named NeuRIS, for high quality reconstruction of indoor scenes. The key idea of NeuRIS is to integrate estimated normal of indoor scenes as a prior in a neural rendering framework for reconstructing large texture-less shapes and, importantly, to do this in an adaptive manner to also enable the reconstruction of irregular shapes with fine details. Specifically, we evaluate the faithfulness of the normal priors on-the-fly by checking the multi-view consistency of reconstruction during the optimization process. Only the normal priors accepted as faithful will be utilized for 3D reconstruction, which typically happens in the regions of smooth shapes possibly with weak texture. However, for those regions with small objects or thin structures, for which the normal priors are usually unreliable, we will only rely on visual features of the input images, since such regions typically contain relatively rich visual features (e.g., shade changes and boundary contours). Extensive experiments show that NeuRIS significantly outperforms the state-of-the-art methods in terms of reconstruction quality.
Learn to Predict How Humans Manipulate Large-sized Objects from Interactive Motions
Jun 25, 2022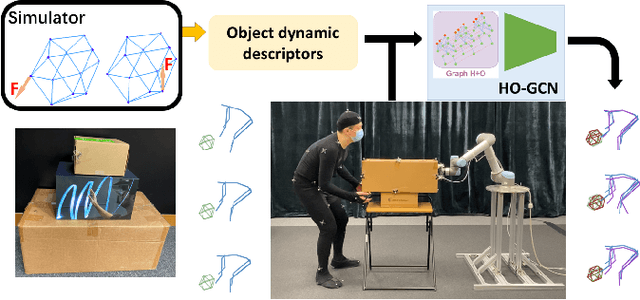

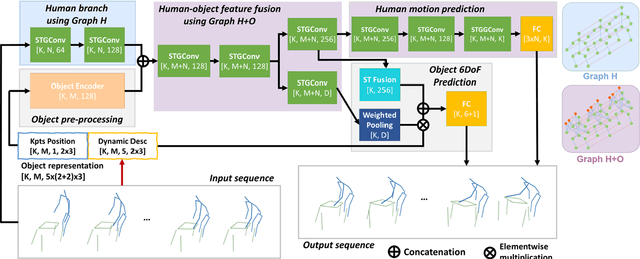
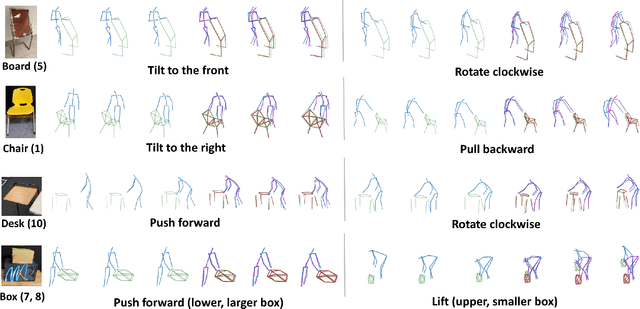
Understanding human intentions during interactions has been a long-lasting theme, that has applications in human-robot interaction, virtual reality and surveillance. In this study, we focus on full-body human interactions with large-sized daily objects and aim to predict the future states of objects and humans given a sequential observation of human-object interaction. As there is no such dataset dedicated to full-body human interactions with large-sized daily objects, we collected a large-scale dataset containing thousands of interactions for training and evaluation purposes. We also observe that an object's intrinsic physical properties are useful for the object motion prediction, and thus design a set of object dynamic descriptors to encode such intrinsic properties. We treat the object dynamic descriptors as a new modality and propose a graph neural network, HO-GCN, to fuse motion data and dynamic descriptors for the prediction task. We show the proposed network that consumes dynamic descriptors can achieve state-of-the-art prediction results and help the network better generalize to unseen objects. We also demonstrate the predicted results are useful for human-robot collaborations.
EventNeRF: Neural Radiance Fields from a Single Colour Event Camera
Jun 23, 2022
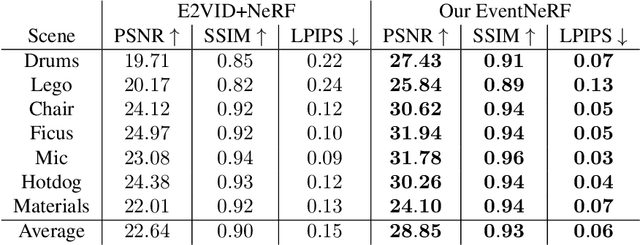

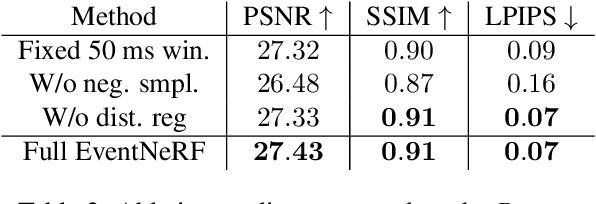
Learning coordinate-based volumetric 3D scene representations such as neural radiance fields (NeRF) has been so far studied assuming RGB or RGB-D images as inputs. At the same time, it is known from the neuroscience literature that human visual system (HVS) is tailored to process asynchronous brightness changes rather than synchronous RGB images, in order to build and continuously update mental 3D representations of the surroundings for navigation and survival. Visual sensors that were inspired by HVS principles are event cameras. Thus, events are sparse and asynchronous per-pixel brightness (or colour channel) change signals. In contrast to existing works on neural 3D scene representation learning, this paper approaches the problem from a new perspective. We demonstrate that it is possible to learn NeRF suitable for novel-view synthesis in the RGB space from asynchronous event streams. Our models achieve high visual accuracy of the rendered novel views of challenging scenes in the RGB space, even though they are trained with substantially fewer data (i.e., event streams from a single event camera moving around the object) and more efficiently (due to the inherent sparsity of event streams) than the existing NeRF models trained with RGB images. We will release our datasets and the source code, see https://4dqv.mpi-inf.mpg.de/EventNeRF/.
GAN2X: Non-Lambertian Inverse Rendering of Image GANs
Jun 18, 2022

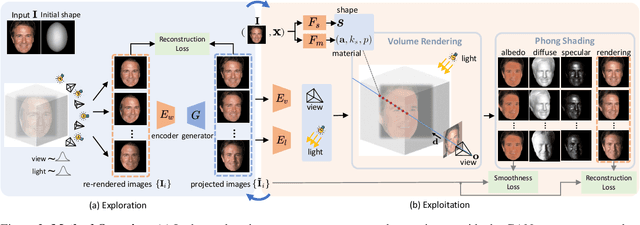

2D images are observations of the 3D physical world depicted with the geometry, material, and illumination components. Recovering these underlying intrinsic components from 2D images, also known as inverse rendering, usually requires a supervised setting with paired images collected from multiple viewpoints and lighting conditions, which is resource-demanding. In this work, we present GAN2X, a new method for unsupervised inverse rendering that only uses unpaired images for training. Unlike previous Shape-from-GAN approaches that mainly focus on 3D shapes, we take the first attempt to also recover non-Lambertian material properties by exploiting the pseudo paired data generated by a GAN. To achieve precise inverse rendering, we devise a specularity-aware neural surface representation that continuously models the geometry and material properties. A shading-based refinement technique is adopted to further distill information in the target image and recover more fine details. Experiments demonstrate that GAN2X can accurately decompose 2D images to 3D shape, albedo, and specular properties for different object categories, and achieves the state-of-the-art performance for unsupervised single-view 3D face reconstruction. We also show its applications in downstream tasks including real image editing and lifting 2D GANs to decomposed 3D GANs.
Unbiased 4D: Monocular 4D Reconstruction with a Neural Deformation Model
Jun 16, 2022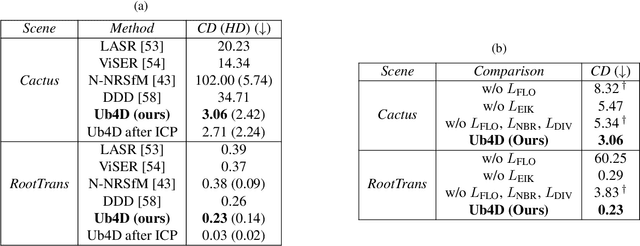
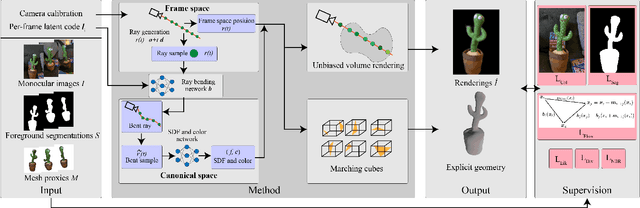

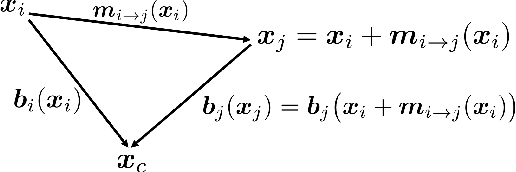
Capturing general deforming scenes is crucial for many computer graphics and vision applications, and it is especially challenging when only a monocular RGB video of the scene is available. Competing methods assume dense point tracks, 3D templates, large-scale training datasets, or only capture small-scale deformations. In contrast to those, our method, Ub4D, makes none of these assumptions while outperforming the previous state of the art in challenging scenarios. Our technique includes two new, in the context of non-rigid 3D reconstruction, components, i.e., 1) A coordinate-based and implicit neural representation for non-rigid scenes, which enables an unbiased reconstruction of dynamic scenes, and 2) A novel dynamic scene flow loss, which enables the reconstruction of larger deformations. Results on our new dataset, which will be made publicly available, demonstrate the clear improvement over the state of the art in terms of surface reconstruction accuracy and robustness to large deformations. Visit the project page https://4dqv.mpi-inf.mpg.de/Ub4D/.
Physics Informed Neural Fields for Smoke Reconstruction with Sparse Data
Jun 14, 2022
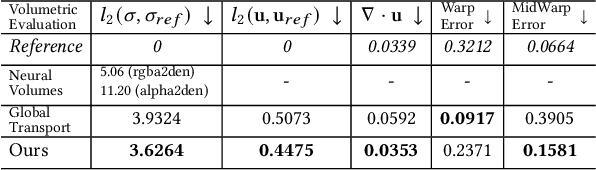

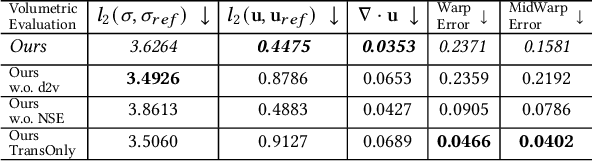
High-fidelity reconstruction of fluids from sparse multiview RGB videos remains a formidable challenge due to the complexity of the underlying physics as well as complex occlusion and lighting in captures. Existing solutions either assume knowledge of obstacles and lighting, or only focus on simple fluid scenes without obstacles or complex lighting, and thus are unsuitable for real-world scenes with unknown lighting or arbitrary obstacles. We present the first method to reconstruct dynamic fluid by leveraging the governing physics (ie, Navier -Stokes equations) in an end-to-end optimization from sparse videos without taking lighting conditions, geometry information, or boundary conditions as input. We provide a continuous spatio-temporal scene representation using neural networks as the ansatz of density and velocity solution functions for fluids as well as the radiance field for static objects. With a hybrid architecture that separates static and dynamic contents, fluid interactions with static obstacles are reconstructed for the first time without additional geometry input or human labeling. By augmenting time-varying neural radiance fields with physics-informed deep learning, our method benefits from the supervision of images and physical priors. To achieve robust optimization from sparse views, we introduced a layer-by-layer growing strategy to progressively increase the network capacity. Using progressively growing models with a new regularization term, we manage to disentangle density-color ambiguity in radiance fields without overfitting. A pretrained density-to-velocity fluid model is leveraged in addition as the data prior to avoid suboptimal velocity which underestimates vorticity but trivially fulfills physical equations. Our method exhibits high-quality results with relaxed constraints and strong flexibility on a representative set of synthetic and real flow captures.
* accepted to ACM Transactions On Graphics (SIGGRAPH 2022), further info:\url{https://people.mpi-inf.mpg.de/~mchu/projects/PI-NeRF/}
HULC: 3D Human Motion Capture with Pose Manifold Sampling and Dense Contact Guidance
May 24, 2022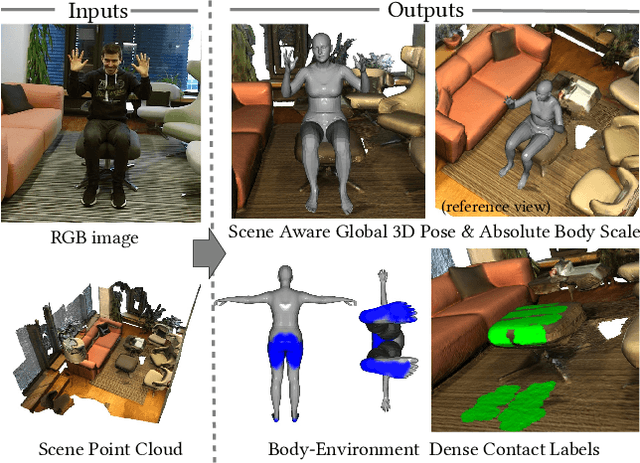
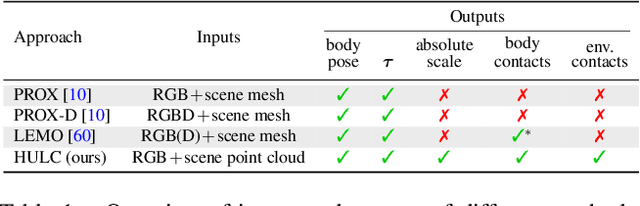
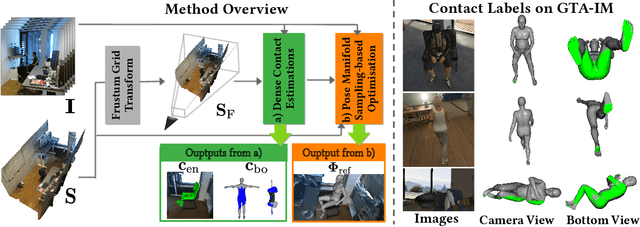
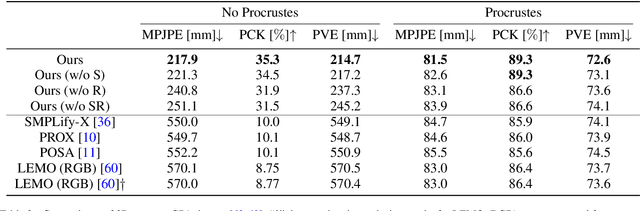
Marker-less monocular 3D human motion capture (MoCap) with scene interactions is a challenging research topic relevant for extended reality, robotics and virtual avatar generation. Due to the inherent depth ambiguity of monocular settings, 3D motions captured with existing methods often contain severe artefacts such as incorrect body-scene inter-penetrations, jitter and body floating. To tackle these issues, we propose HULC, a new approach for 3D human MoCap which is aware of the scene geometry. HULC estimates 3D poses and dense body-environment surface contacts for improved 3D localisations, as well as the absolute scale of the subject. Furthermore, we introduce a 3D pose trajectory optimisation based on a novel pose manifold sampling that resolves erroneous body-environment inter-penetrations. Although the proposed method requires less structured inputs compared to existing scene-aware monocular MoCap algorithms, it produces more physically-plausible poses: HULC significantly and consistently outperforms the existing approaches in various experiments and on different metrics.
BEHAVE: Dataset and Method for Tracking Human Object Interactions
Apr 14, 2022
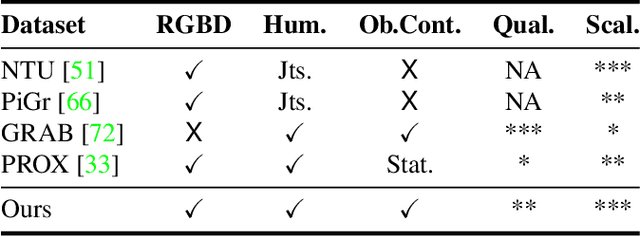


Modelling interactions between humans and objects in natural environments is central to many applications including gaming, virtual and mixed reality, as well as human behavior analysis and human-robot collaboration. This challenging operation scenario requires generalization to vast number of objects, scenes, and human actions. Unfortunately, there exist no such dataset. Moreover, this data needs to be acquired in diverse natural environments, which rules out 4D scanners and marker based capture systems. We present BEHAVE dataset, the first full body human- object interaction dataset with multi-view RGBD frames and corresponding 3D SMPL and object fits along with the annotated contacts between them. We record around 15k frames at 5 locations with 8 subjects performing a wide range of interactions with 20 common objects. We use this data to learn a model that can jointly track humans and objects in natural environments with an easy-to-use portable multi-camera setup. Our key insight is to predict correspondences from the human and the object to a statistical body model to obtain human-object contacts during interactions. Our approach can record and track not just the humans and objects but also their interactions, modeled as surface contacts, in 3D. Our code and data can be found at: http://virtualhumans.mpi-inf.mpg.de/behave
* Accepted at CVPR'22
Direct Dense Pose Estimation
Apr 04, 2022
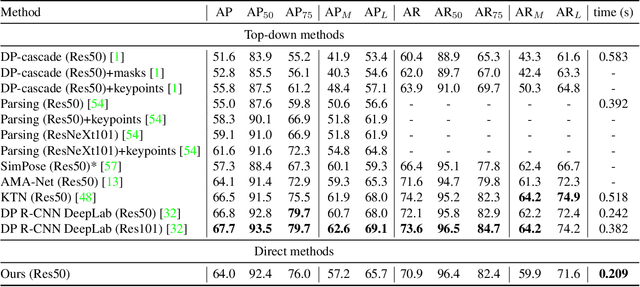
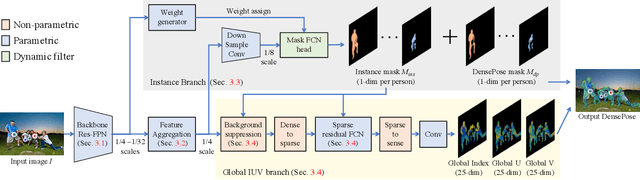

Dense human pose estimation is the problem of learning dense correspondences between RGB images and the surfaces of human bodies, which finds various applications, such as human body reconstruction, human pose transfer, and human action recognition. Prior dense pose estimation methods are all based on Mask R-CNN framework and operate in a top-down manner of first attempting to identify a bounding box for each person and matching dense correspondences in each bounding box. Consequently, these methods lack robustness due to their critical dependence on the Mask R-CNN detection, and the runtime increases drastically as the number of persons in the image increases. We therefore propose a novel alternative method for solving the dense pose estimation problem, called Direct Dense Pose (DDP). DDP first predicts the instance mask and global IUV representation separately and then combines them together. We also propose a simple yet effective 2D temporal-smoothing scheme to alleviate the temporal jitters when dealing with video data. Experiments demonstrate that DDP overcomes the limitations of previous top-down baseline methods and achieves competitive accuracy. In addition, DDP is computationally more efficient than previous dense pose estimation methods, and it reduces jitters when applied to a video sequence, which is a problem plaguing the previous methods.