 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSign-OPT: A Query-Efficient Hard-label Adversarial Attack
Sep 28, 2019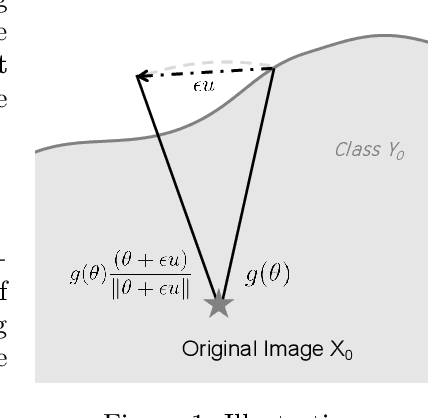
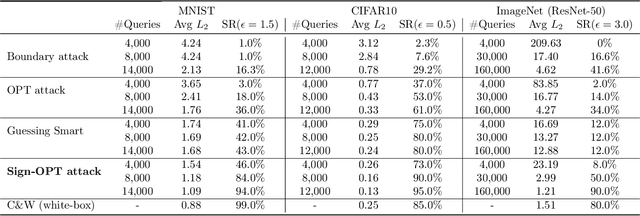

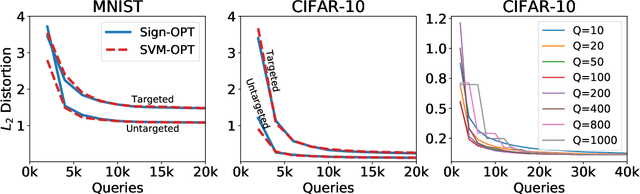
We study the most practical problem setup for evaluating adversarial robustness of a machine learning system with limited access: the hard-label black-box attack setting for generating adversarial examples, where limited model queries are allowed and only the decision is provided to a queried data input. Several algorithms have been proposed for this problem but they typically require huge amount (>20,000) of queries for attacking one example. Among them, one of the state-of-the-art approaches (Cheng et al., 2019) showed that hard-label attack can be modeled as an optimization problem where the objective function can be evaluated by binary search with additional model queries, thereby a zeroth order optimization algorithm can be applied. In this paper, we adopt the same optimization formulation but propose to directly estimate the sign of gradient at any direction instead of the gradient itself, which enjoys the benefit of single query. Using this single query oracle for retrieving sign of directional derivative, we develop a novel query-efficient Sign-OPT approach for hard-label black-box attack. We provide a convergence analysis of the new algorithm and conduct experiments on several models on MNIST, CIFAR-10 and ImageNet. We find that Sign-OPT attack consistently requires 5X to 10X fewer queries when compared to the current state-of-the-art approaches, and usually converges to an adversarial example with smaller perturbation.
Natural Adversarial Sentence Generation with Gradient-based Perturbation
Sep 06, 2019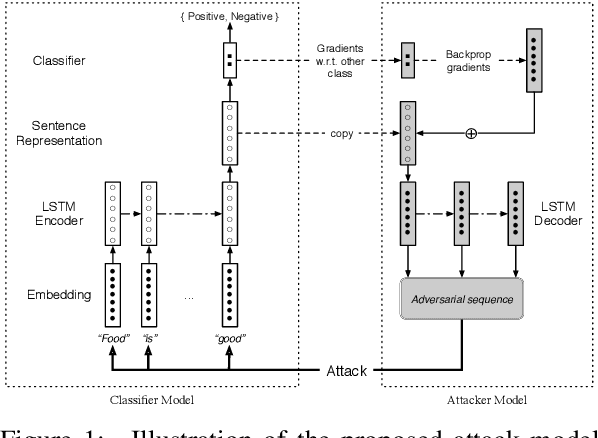

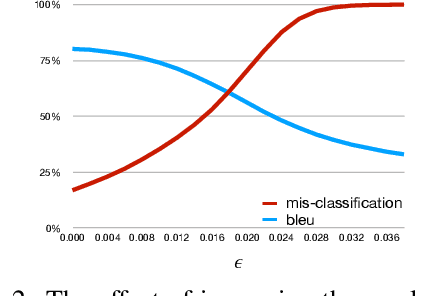

This work proposes a novel algorithm to generate natural language adversarial input for text classification models, in order to investigate the robustness of these models. It involves applying gradient-based perturbation on the sentence embeddings that are used as the features for the classifier, and learning a decoder for generation. We employ this method to a sentiment analysis model and verify its effectiveness in inducing incorrect predictions by the model. We also conduct quantitative and qualitative analysis on these examples and demonstrate that our approach can generate more natural adversaries. In addition, it can be used to successfully perform black-box attacks, which involves attacking other existing models whose parameters are not known. On a public sentiment analysis API, the proposed method introduces a 20% relative decrease in average accuracy and 74% relative increase in absolute error.
Temporal Collaborative Ranking Via Personalized Transformer
Aug 15, 2019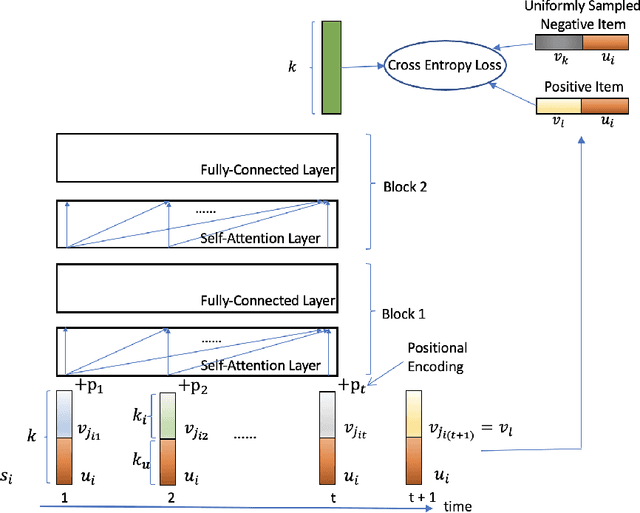
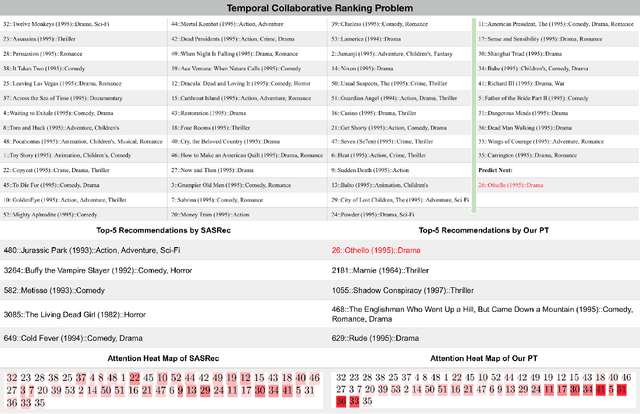

The collaborative ranking problem has been an important open research question as most recommendation problems can be naturally formulated as ranking problems. While much of collaborative ranking methodology assumes static ranking data, the importance of temporal information to improving ranking performance is increasingly apparent. Recent advances in deep learning, especially the discovery of various attention mechanisms and newer architectures in addition to widely used RNN and CNN in natural language processing, have allowed us to make better use of the temporal ordering of items that each user has engaged with. In particular, the SASRec model, inspired by the popular Transformer model in natural languages processing, has achieved state-of-art results in the temporal collaborative ranking problem and enjoyed more than 10x speed-up when compared to earlier CNN/RNN-based methods. However, SASRec is inherently an un-personalized model and does not include personalized user embeddings. To overcome this limitation, we propose a Personalized Transformer (SSE-PT) model, outperforming SASRec by almost 5% in terms of NDCG@10 on 5 real-world datasets. Furthermore, after examining some random users' engagement history and corresponding attention heat maps used during the inference stage, we find our model is not only more interpretable but also able to focus on recent engagement patterns for each user. Moreover, our SSE-PT model with a slight modification, which we call SSE-PT++, can handle extremely long sequences and outperform SASRec in ranking results with comparable training speed, striking a balance between performance and speed requirements. Code and data are open sourced at https://github.com/wuliwei9278/SSE-PT.
VisualBERT: A Simple and Performant Baseline for Vision and Language
Aug 09, 2019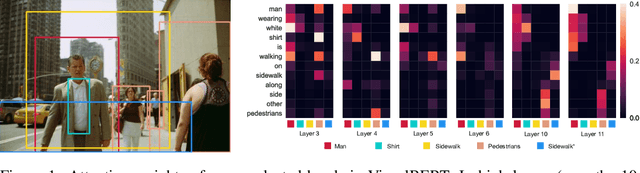
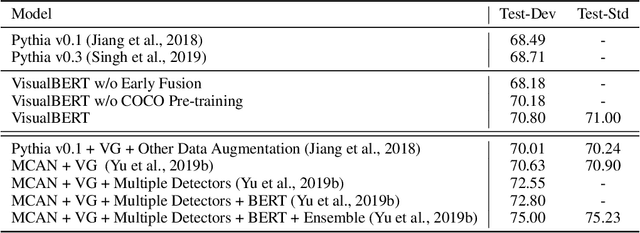
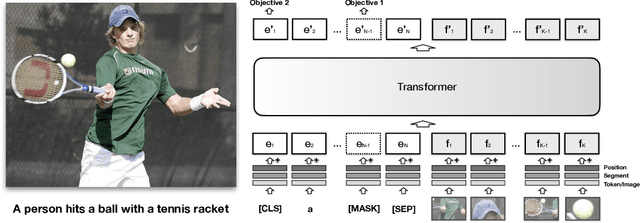
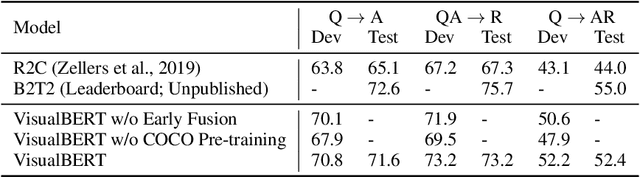
We propose VisualBERT, a simple and flexible framework for modeling a broad range of vision-and-language tasks. VisualBERT consists of a stack of Transformer layers that implicitly align elements of an input text and regions in an associated input image with self-attention. We further propose two visually-grounded language model objectives for pre-training VisualBERT on image caption data. Experiments on four vision-and-language tasks including VQA, VCR, NLVR2, and Flickr30K show that VisualBERT outperforms or rivals with state-of-the-art models while being significantly simpler. Further analysis demonstrates that VisualBERT can ground elements of language to image regions without any explicit supervision and is even sensitive to syntactic relationships, tracking, for example, associations between verbs and image regions corresponding to their arguments.
Convergence of Adversarial Training in Overparametrized Networks
Jun 19, 2019Neural networks are vulnerable to adversarial examples, i.e. inputs that are imperceptibly perturbed from natural data and yet incorrectly classified by the network. Adversarial training, a heuristic form of robust optimization that alternates between minimization and maximization steps, has proven to be among the most successful methods to train networks that are robust against a pre-defined family of perturbations. This paper provides a partial answer to the success of adversarial training. When the inner maximization problem can be solved to optimality, we prove that adversarial training finds a network of small robust train loss. When the maximization problem is solved by a heuristic algorithm, we prove that adversarial training finds a network of small robust surrogate train loss. The analysis technique leverages recent work on the analysis of neural networks via Neural Tangent Kernel (NTK), combined with online-learning when the maximization is solved by a heuristic, and the expressiveness of the NTK kernel in the $\ell_\infty$-norm.
Robustness Verification of Tree-based Models
Jun 15, 2019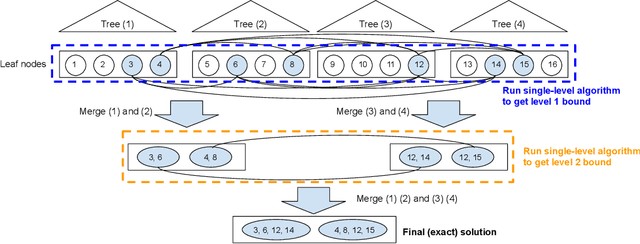
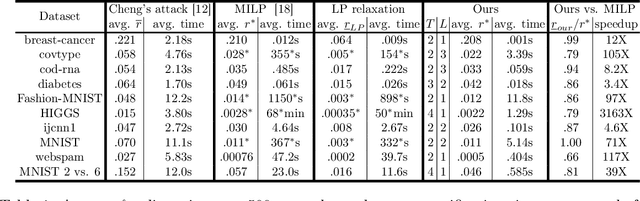
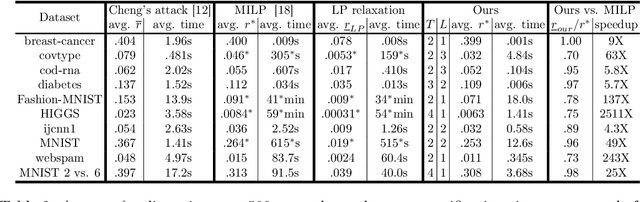
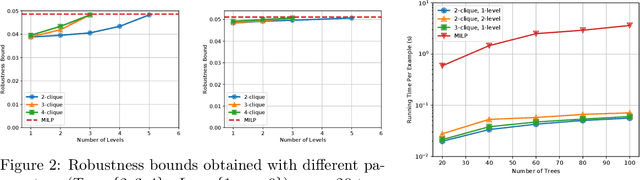
We study the robustness verification problem for tree-based models, including decision trees, random forests (RFs) and gradient boosted decision trees (GBDTs). Formal robustness verification of decision tree ensembles involves finding the exact minimal adversarial perturbation or a guaranteed lower bound of it. Existing approaches find the minimal adversarial perturbation by a mixed integer linear programming (MILP) problem, which takes exponential time so is impractical for large ensembles. Although this verification problem is NP-complete in general, we give a more precise complexity characterization. We show that there is a simple linear time algorithm for verifying a single tree, and for tree ensembles, the verification problem can be cast as a max-clique problem on a multi-partite graph with bounded boxicity. For low dimensional problems when boxicity can be viewed as constant, this reformulation leads to a polynomial time algorithm. For general problems, by exploiting the boxicity of the graph, we develop an efficient multi-level verification algorithm that can give tight lower bounds on the robustness of decision tree ensembles, while allowing iterative improvement and any-time termination. OnRF/GBDT models trained on 10 datasets, our algorithm is hundreds of times faster than the previous approach that requires solving MILPs, and is able to give tight robustness verification bounds on large GBDTs with hundreds of deep trees.
Towards Stable and Efficient Training of Verifiably Robust Neural Networks
Jun 14, 2019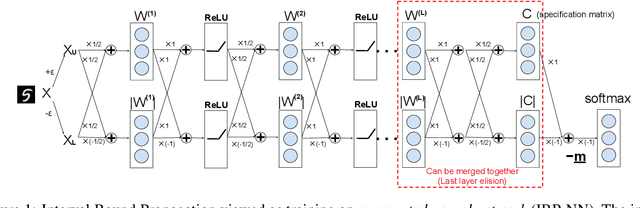
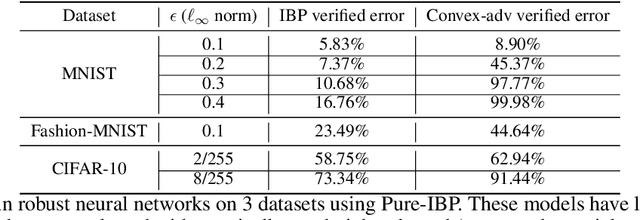
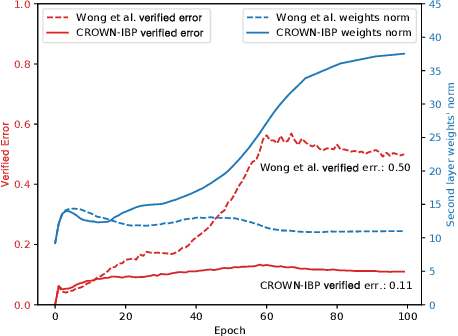
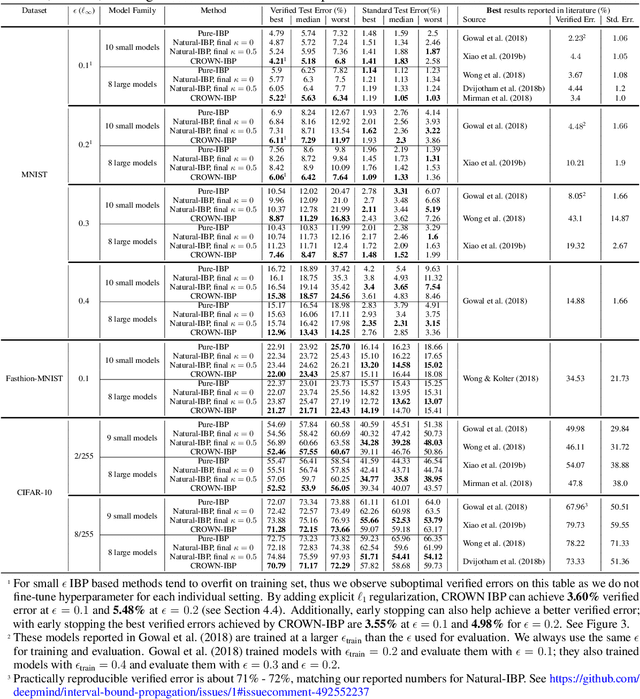
Training neural networks with verifiable robustness guarantees is challenging. Several existing successful approaches utilize relatively tight linear relaxation based bounds of neural network outputs, but they can slow down training by a factor of hundreds and over-regularize the network. Meanwhile, interval bound propagation (IBP) based training is efficient and significantly outperform linear relaxation based methods on some tasks, yet it suffers from stability issues since the bounds are much looser. In this paper, we first interpret IBP training as training an augmented network which computes non-linear bounds, thus explaining its good performance. We then propose a new certified adversarial training method, CROWN-IBP, by combining the fast IBP bounds in the forward pass and a tight linear relaxation based bound, CROWN, in the backward pass. The proposed method is computationally efficient and consistently outperforms IBP baselines on training verifiably robust neural networks. We conduct large scale experiments using 53 models on MNIST, Fashion-MNIST and CIFAR datasets. On MNIST with $\epsilon=0.3$ and $\epsilon=0.4$ ($\ell_\infty$ norm distortion) we achieve 7.46\% and 12.96\% verified error on test set, respectively, outperforming previous certified defense methods.
Evaluating the Robustness of Nearest Neighbor Classifiers: A Primal-Dual Perspective
Jun 10, 2019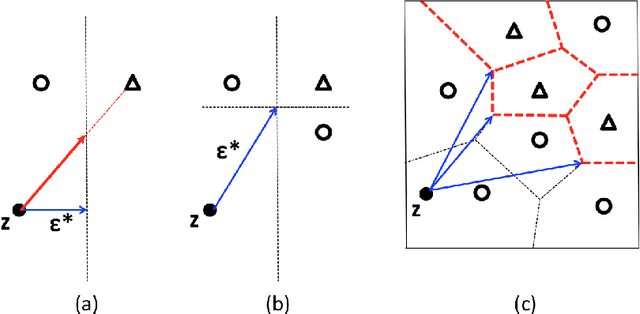
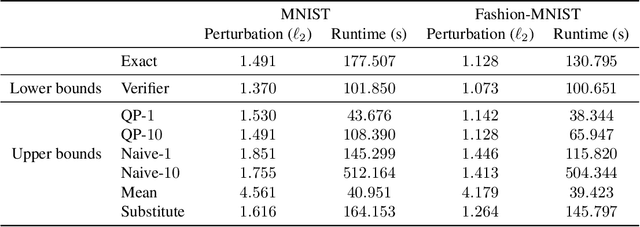
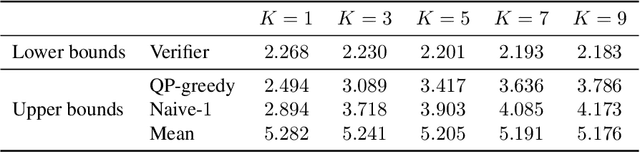
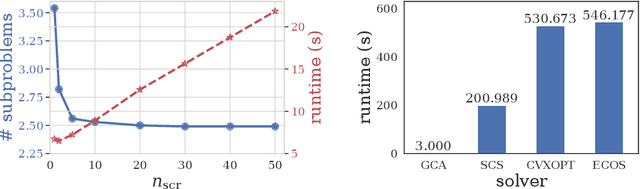
We study the problem of computing the minimum adversarial perturbation of the Nearest Neighbor (NN) classifiers. Previous attempts either conduct attacks on continuous approximations of NN models or search for the perturbation by some heuristic methods. In this paper, we propose the first algorithm that is able to compute the minimum adversarial perturbation. The main idea is to formulate the problem as a list of convex quadratic programming (QP) problems that can be efficiently solved by the proposed algorithms for 1-NN models. Furthermore, we show that dual solutions for these QP problems could give us a valid lower bound of the adversarial perturbation that can be used for formal robustness verification, giving us a nice view of attack/verification for NN models. For $K$-NN models with larger $K$, we show that the same formulation can help us efficiently compute the upper and lower bounds of the minimum adversarial perturbation, which can be used for attack and verification.
ML-LOO: Detecting Adversarial Examples with Feature Attribution
Jun 08, 2019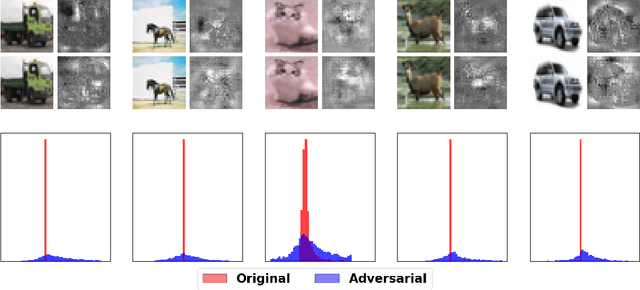
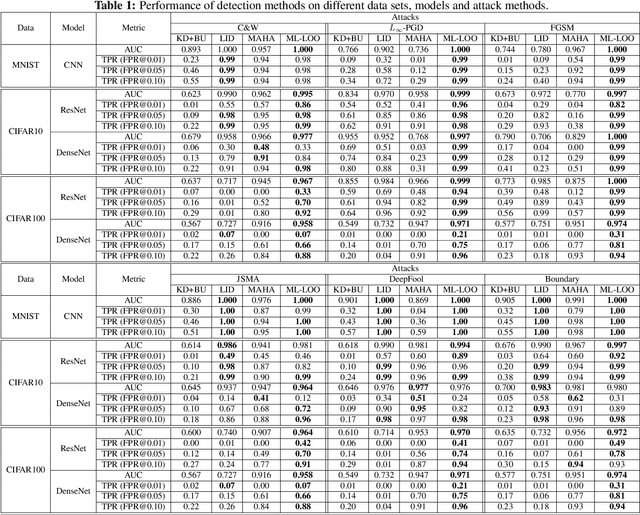
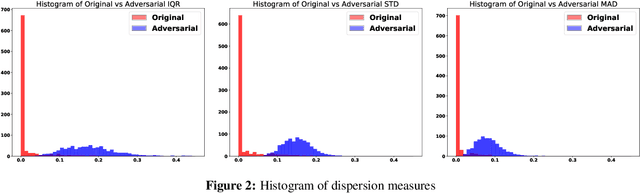
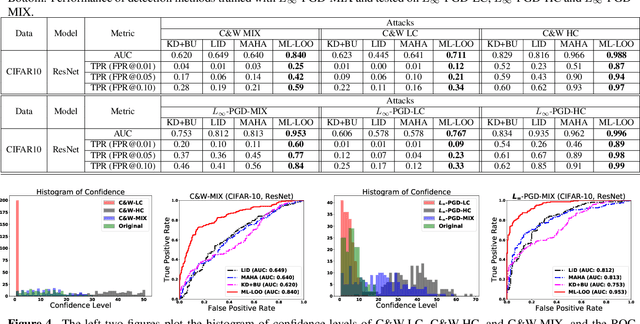
Deep neural networks obtain state-of-the-art performance on a series of tasks. However, they are easily fooled by adding a small adversarial perturbation to input. The perturbation is often human imperceptible on image data. We observe a significant difference in feature attributions of adversarially crafted examples from those of original ones. Based on this observation, we introduce a new framework to detect adversarial examples through thresholding a scale estimate of feature attribution scores. Furthermore, we extend our method to include multi-layer feature attributions in order to tackle the attacks with mixed confidence levels. Through vast experiments, our method achieves superior performances in distinguishing adversarial examples from popular attack methods on a variety of real data sets among state-of-the-art detection methods. In particular, our method is able to detect adversarial examples of mixed confidence levels, and transfer between different attacking methods.
Neural SDE: Stabilizing Neural ODE Networks with Stochastic Noise
Jun 05, 2019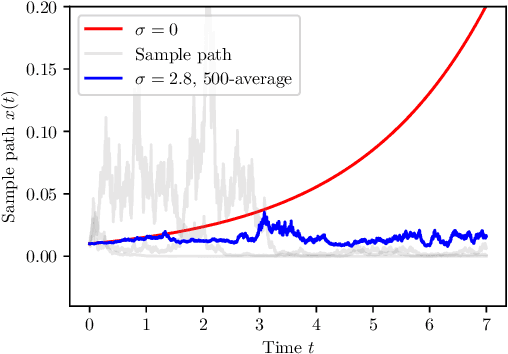

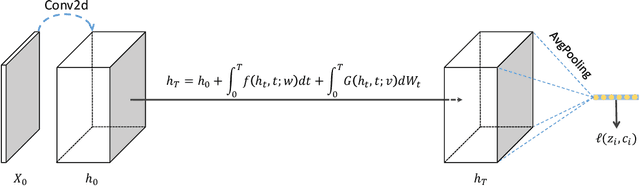
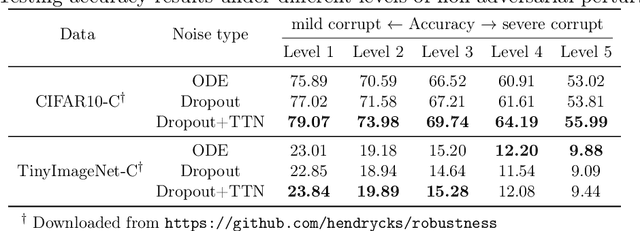
Neural Ordinary Differential Equation (Neural ODE) has been proposed as a continuous approximation to the ResNet architecture. Some commonly used regularization mechanisms in discrete neural networks (e.g. dropout, Gaussian noise) are missing in current Neural ODE networks. In this paper, we propose a new continuous neural network framework called Neural Stochastic Differential Equation (Neural SDE) network, which naturally incorporates various commonly used regularization mechanisms based on random noise injection. Our framework can model various types of noise injection frequently used in discrete networks for regularization purpose, such as dropout and additive/multiplicative noise in each block. We provide theoretical analysis explaining the improved robustness of Neural SDE models against input perturbations/adversarial attacks. Furthermore, we demonstrate that the Neural SDE network can achieve better generalization than the Neural ODE and is more resistant to adversarial and non-adversarial input perturbations.