 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Wavelet-domain Diffusion for 3D Shape Generation, Inversion, and Manipulation
Feb 01, 2023



This paper presents a new approach for 3D shape generation, inversion, and manipulation, through a direct generative modeling on a continuous implicit representation in wavelet domain. Specifically, we propose a compact wavelet representation with a pair of coarse and detail coefficient volumes to implicitly represent 3D shapes via truncated signed distance functions and multi-scale biorthogonal wavelets. Then, we design a pair of neural networks: a diffusion-based generator to produce diverse shapes in the form of the coarse coefficient volumes and a detail predictor to produce compatible detail coefficient volumes for introducing fine structures and details. Further, we may jointly train an encoder network to learn a latent space for inverting shapes, allowing us to enable a rich variety of whole-shape and region-aware shape manipulations. Both quantitative and qualitative experimental results manifest the compelling shape generation, inversion, and manipulation capabilities of our approach over the state-of-the-art methods.
Sparse2Dense: Learning to Densify 3D Features for 3D Object Detection
Nov 23, 2022



LiDAR-produced point clouds are the major source for most state-of-the-art 3D object detectors. Yet, small, distant, and incomplete objects with sparse or few points are often hard to detect. We present Sparse2Dense, a new framework to efficiently boost 3D detection performance by learning to densify point clouds in latent space. Specifically, we first train a dense point 3D detector (DDet) with a dense point cloud as input and design a sparse point 3D detector (SDet) with a regular point cloud as input. Importantly, we formulate the lightweight plug-in S2D module and the point cloud reconstruction module in SDet to densify 3D features and train SDet to produce 3D features, following the dense 3D features in DDet. So, in inference, SDet can simulate dense 3D features from regular (sparse) point cloud inputs without requiring dense inputs. We evaluate our method on the large-scale Waymo Open Dataset and the Waymo Domain Adaptation Dataset, showing its high performance and efficiency over the state of the arts.
Video Instance Shadow Detection
Nov 23, 2022



Video instance shadow detection aims to simultaneously detect, segment, associate, and track paired shadow-object associations in videos. This work has three key contributions to the task. First, we design SSIS-Track, a new framework to extract shadow-object associations in videos with paired tracking and without category specification; especially, we strive to maintain paired tracking even the objects/shadows are temporarily occluded for several frames. Second, we leverage both labeled images and unlabeled videos, and explore temporal coherence by augmenting the tracking ability via an association cycle consistency loss to optimize SSIS-Track's performance. Last, we build $\textit{SOBA-VID}$, a new dataset with 232 unlabeled videos of ${5,863}$ frames for training and 60 labeled videos of ${1,182}$ frames for testing. Experimental results show that SSIS-Track surpasses baselines built from SOTA video tracking and instance-shadow-detection methods by a large margin. In the end, we showcase several video-level applications.
ISS: Image as Stepping Stone for Text-Guided 3D Shape Generation
Sep 22, 2022

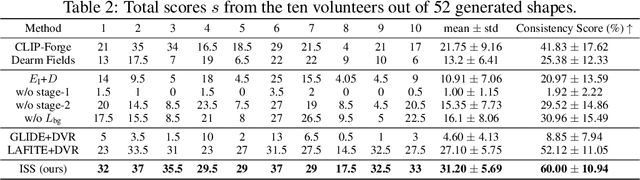

Text-guided 3D shape generation remains challenging due to the absence of large paired text-shape data, the substantial semantic gap between these two modalities, and the structural complexity of 3D shapes. This paper presents a new framework called Image as Stepping Stone (ISS) for the task by introducing 2D image as a stepping stone to connect the two modalities and to eliminate the need for paired text-shape data. Our key contribution is a two-stage feature-space-alignment approach that maps CLIP features to shapes by harnessing a pre-trained single-view reconstruction (SVR) model with multi-view supervisions: first map the CLIP image feature to the detail-rich shape space in the SVR model, then map the CLIP text feature to the shape space and optimize the mapping by encouraging CLIP consistency between the input text and the rendered images. Further, we formulate a text-guided shape stylization module to dress up the output shapes with novel textures. Beyond existing works on 3D shape generation from text, our new approach is general for creating shapes in a broad range of categories, without requiring paired text-shape data. Experimental results manifest that our approach outperforms the state-of-the-arts and our baselines in terms of fidelity and consistency with text. Further, our approach can stylize the generated shapes with both realistic and fantasy structures and textures.
Learning Reconstructability for Drone Aerial Path Planning
Sep 21, 2022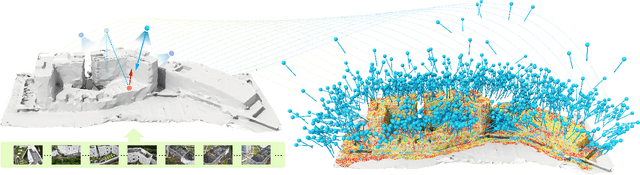
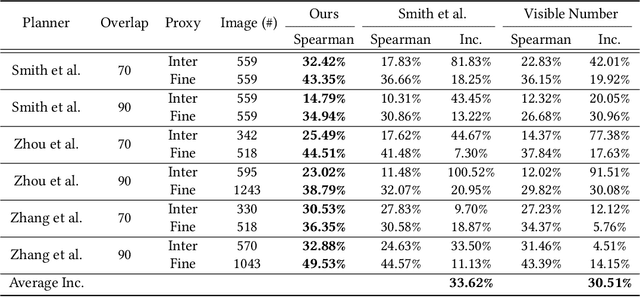
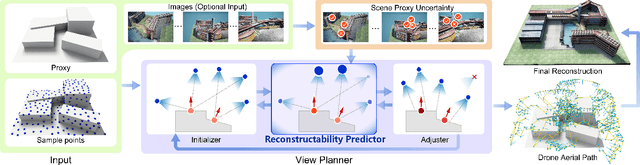
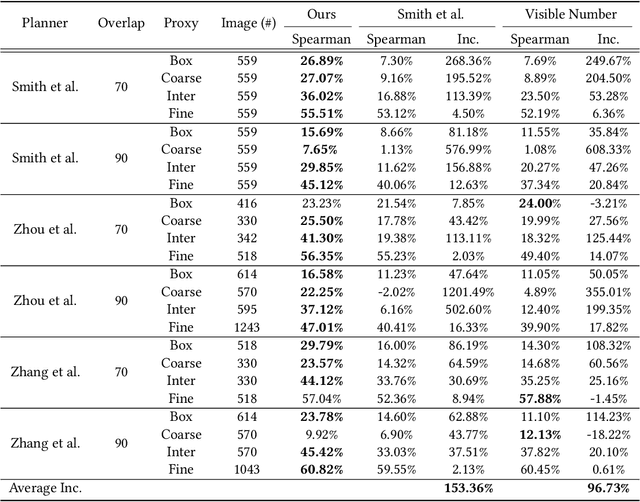
We introduce the first learning-based reconstructability predictor to improve view and path planning for large-scale 3D urban scene acquisition using unmanned drones. In contrast to previous heuristic approaches, our method learns a model that explicitly predicts how well a 3D urban scene will be reconstructed from a set of viewpoints. To make such a model trainable and simultaneously applicable to drone path planning, we simulate the proxy-based 3D scene reconstruction during training to set up the prediction. Specifically, the neural network we design is trained to predict the scene reconstructability as a function of the proxy geometry, a set of viewpoints, and optionally a series of scene images acquired in flight. To reconstruct a new urban scene, we first build the 3D scene proxy, then rely on the predicted reconstruction quality and uncertainty measures by our network, based off of the proxy geometry, to guide the drone path planning. We demonstrate that our data-driven reconstructability predictions are more closely correlated to the true reconstruction quality than prior heuristic measures. Further, our learned predictor can be easily integrated into existing path planners to yield improvements. Finally, we devise a new iterative view planning framework, based on the learned reconstructability, and show superior performance of the new planner when reconstructing both synthetic and real scenes.
Neural Wavelet-domain Diffusion for 3D Shape Generation
Sep 19, 2022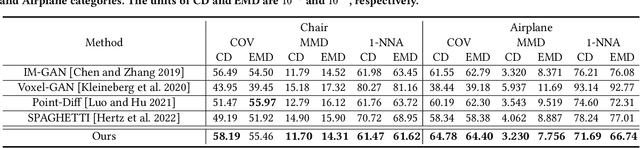
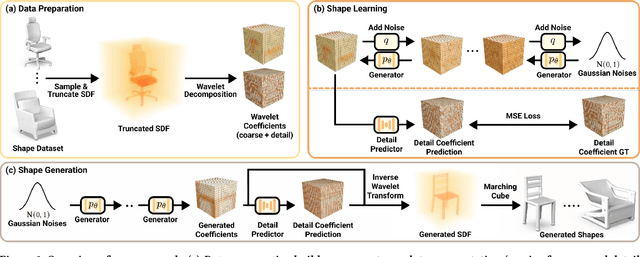
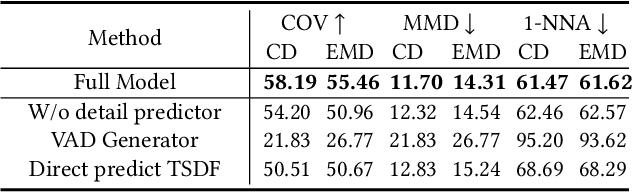

This paper presents a new approach for 3D shape generation, enabling direct generative modeling on a continuous implicit representation in wavelet domain. Specifically, we propose a compact wavelet representation with a pair of coarse and detail coefficient volumes to implicitly represent 3D shapes via truncated signed distance functions and multi-scale biorthogonal wavelets, and formulate a pair of neural networks: a generator based on the diffusion model to produce diverse shapes in the form of coarse coefficient volumes; and a detail predictor to further produce compatible detail coefficient volumes for enriching the generated shapes with fine structures and details. Both quantitative and qualitative experimental results manifest the superiority of our approach in generating diverse and high-quality shapes with complex topology and structures, clean surfaces, and fine details, exceeding the 3D generation capabilities of the state-of-the-art models.
Boosting Single-Frame 3D Object Detection by Simulating Multi-Frame Point Clouds
Jul 12, 2022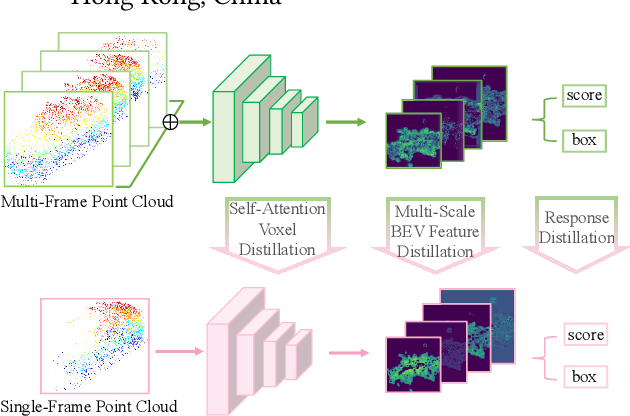
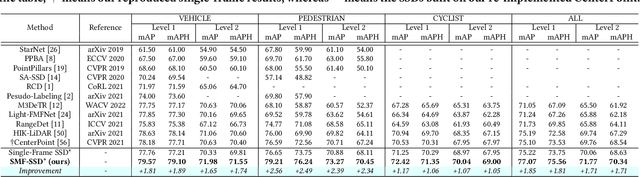
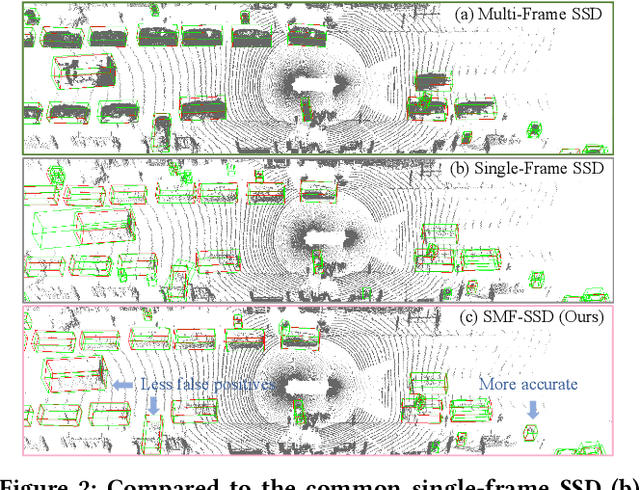
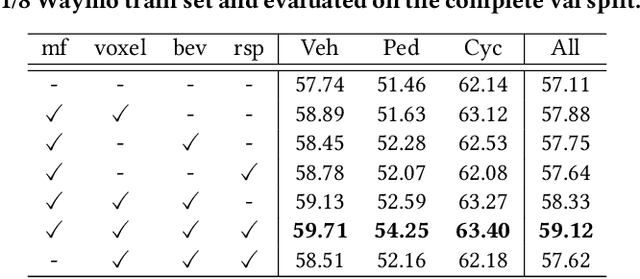
To boost a detector for single-frame 3D object detection, we present a new approach to train it to simulate features and responses following a detector trained on multi-frame point clouds. Our approach needs multi-frame point clouds only when training the single-frame detector, and once trained, it can detect objects with only single-frame point clouds as inputs during the inference. We design a novel Simulated Multi-Frame Single-Stage object Detector (SMF-SSD) framework to realize the approach: multi-view dense object fusion to densify ground-truth objects to generate a multi-frame point cloud; self-attention voxel distillation to facilitate one-to-many knowledge transfer from multi- to single-frame voxels; multi-scale BEV feature distillation to transfer knowledge in low-level spatial and high-level semantic BEV features; and adaptive response distillation to activate single-frame responses of high confidence and accurate localization. Experimental results on the Waymo test set show that our SMF-SSD consistently outperforms all state-of-the-art single-frame 3D object detectors for all object classes of difficulty levels 1 and 2 in terms of both mAP and mAPH.
Instance Shadow Detection with A Single-Stage Detector
Jul 11, 2022



This paper formulates a new problem, instance shadow detection, which aims to detect shadow instance and the associated object instance that cast each shadow in the input image. To approach this task, we first compile a new dataset with the masks for shadow instances, object instances, and shadow-object associations. We then design an evaluation metric for quantitative evaluation of the performance of instance shadow detection. Further, we design a single-stage detector to perform instance shadow detection in an end-to-end manner, where the bidirectional relation learning module and the deformable maskIoU head are proposed in the detector to directly learn the relation between shadow instances and object instances and to improve the accuracy of the predicted masks. Finally, we quantitatively and qualitatively evaluate our method on the benchmark dataset of instance shadow detection and show the applicability of our method on light direction estimation and photo editing.
Deep Parametric 3D Filters for Joint Video Denoising and Illumination Enhancement in Video Super Resolution
Jul 05, 2022

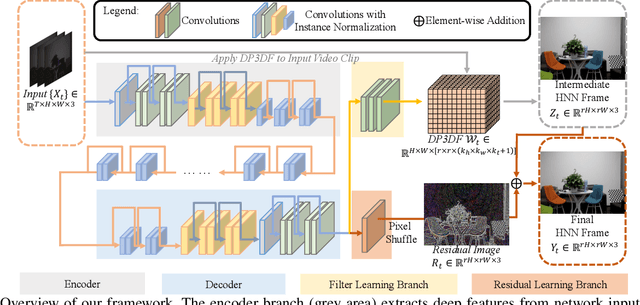
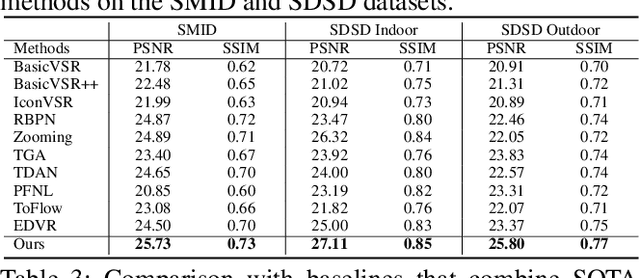
Despite the quality improvement brought by the recent methods, video super-resolution (SR) is still very challenging, especially for videos that are low-light and noisy. The current best solution is to subsequently employ best models of video SR, denoising, and illumination enhancement, but doing so often lowers the image quality, due to the inconsistency between the models. This paper presents a new parametric representation called the Deep Parametric 3D Filters (DP3DF), which incorporates local spatiotemporal information to enable simultaneous denoising, illumination enhancement, and SR efficiently in a single encoder-and-decoder network. Also, a dynamic residual frame is jointly learned with the DP3DF via a shared backbone to further boost the SR quality. We performed extensive experiments, including a large-scale user study, to show our method's effectiveness. Our method consistently surpasses the best state-of-the-art methods on all the challenging real datasets with top PSNR and user ratings, yet having a very fast run time.
Boosting 3D Object Detection by Simulating Multimodality on Point Clouds
Jun 30, 2022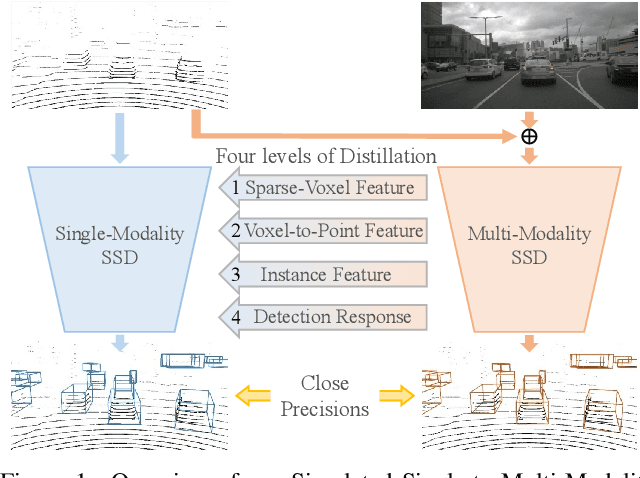


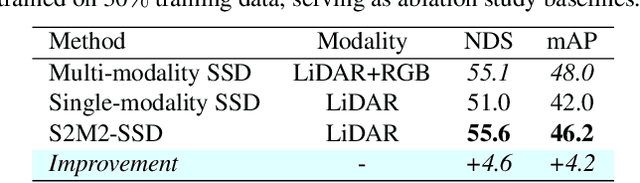
This paper presents a new approach to boost a single-modality (LiDAR) 3D object detector by teaching it to simulate features and responses that follow a multi-modality (LiDAR-image) detector. The approach needs LiDAR-image data only when training the single-modality detector, and once well-trained, it only needs LiDAR data at inference. We design a novel framework to realize the approach: response distillation to focus on the crucial response samples and avoid the background samples; sparse-voxel distillation to learn voxel semantics and relations from the estimated crucial voxels; a fine-grained voxel-to-point distillation to better attend to features of small and distant objects; and instance distillation to further enhance the deep-feature consistency. Experimental results on the nuScenes dataset show that our approach outperforms all SOTA LiDAR-only 3D detectors and even surpasses the baseline LiDAR-image detector on the key NDS metric, filling 72% mAP gap between the single- and multi-modality detectors.