 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Grasp Event Signals? Exploring Pure Zero-Shot Event-based Recognition
Sep 15, 2024Recent advancements in event-based zero-shot object recognition have demonstrated promising results. However, these methods heavily depend on extensive training and are inherently constrained by the characteristics of CLIP. To the best of our knowledge, this research is the first study to explore the understanding capabilities of large language models (LLMs) for event-based visual content. We demonstrate that LLMs can achieve event-based object recognition without additional training or fine-tuning in conjunction with CLIP, effectively enabling pure zero-shot event-based recognition. Particularly, we evaluate the ability of GPT-4o / 4turbo and two other open-source LLMs to directly recognize event-based visual content. Extensive experiments are conducted across three benchmark datasets, systematically assessing the recognition accuracy of these models. The results show that LLMs, especially when enhanced with well-designed prompts, significantly improve event-based zero-shot recognition performance. Notably, GPT-4o outperforms the compared models and exceeds the recognition accuracy of state-of-the-art event-based zero-shot methods on N-ImageNet by five orders of magnitude. The implementation of this paper is available at \url{https://github.com/ChrisYu-Zz/Pure-event-based-recognition-based-LLM}.
Multiplex Graph Contrastive Learning with Soft Negatives
Sep 12, 2024Graph Contrastive Learning (GCL) seeks to learn nodal or graph representations that contain maximal consistent information from graph-structured data. While node-level contrasting modes are dominating, some efforts commence to explore consistency across different scales. Yet, they tend to lose consistent information and be contaminated by disturbing features. Here, we introduce MUX-GCL, a novel cross-scale contrastive learning paradigm that utilizes multiplex representations as effective patches. While this learning mode minimizes contaminating noises, a commensurate contrasting strategy using positional affinities further avoids information loss by correcting false negative pairs across scales. Extensive downstream experiments demonstrate that MUX-GCL yields multiple state-of-the-art results on public datasets. Our theoretical analysis further guarantees the new objective function as a stricter lower bound of mutual information of raw input features and output embeddings, which rationalizes this paradigm. Code is available at https://github.com/MUX-GCL/Code.
SCARF: Scalable Continual Learning Framework for Memory-efficient Multiple Neural Radiance Fields
Sep 06, 2024This paper introduces a novel continual learning framework for synthesising novel views of multiple scenes, learning multiple 3D scenes incrementally, and updating the network parameters only with the training data of the upcoming new scene. We build on Neural Radiance Fields (NeRF), which uses multi-layer perceptron to model the density and radiance field of a scene as the implicit function. While NeRF and its extensions have shown a powerful capability of rendering photo-realistic novel views in a single 3D scene, managing these growing 3D NeRF assets efficiently is a new scientific problem. Very few works focus on the efficient representation or continuous learning capability of multiple scenes, which is crucial for the practical applications of NeRF. To achieve these goals, our key idea is to represent multiple scenes as the linear combination of a cross-scene weight matrix and a set of scene-specific weight matrices generated from a global parameter generator. Furthermore, we propose an uncertain surface knowledge distillation strategy to transfer the radiance field knowledge of previous scenes to the new model. Representing multiple 3D scenes with such weight matrices significantly reduces memory requirements. At the same time, the uncertain surface distillation strategy greatly overcomes the catastrophic forgetting problem and maintains the photo-realistic rendering quality of previous scenes. Experiments show that the proposed approach achieves state-of-the-art rendering quality of continual learning NeRF on NeRF-Synthetic, LLFF, and TanksAndTemples datasets while preserving extra low storage cost.
ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
Sep 03, 2024



Representing robotic manipulation tasks as constraints that associate the robot and the environment is a promising way to encode desired robot behaviors. However, it remains unclear how to formulate the constraints such that they are 1) versatile to diverse tasks, 2) free of manual labeling, and 3) optimizable by off-the-shelf solvers to produce robot actions in real-time. In this work, we introduce Relational Keypoint Constraints (ReKep), a visually-grounded representation for constraints in robotic manipulation. Specifically, ReKep is expressed as Python functions mapping a set of 3D keypoints in the environment to a numerical cost. We demonstrate that by representing a manipulation task as a sequence of Relational Keypoint Constraints, we can employ a hierarchical optimization procedure to solve for robot actions (represented by a sequence of end-effector poses in SE(3)) with a perception-action loop at a real-time frequency. Furthermore, in order to circumvent the need for manual specification of ReKep for each new task, we devise an automated procedure that leverages large vision models and vision-language models to produce ReKep from free-form language instructions and RGB-D observations. We present system implementations on a wheeled single-arm platform and a stationary dual-arm platform that can perform a large variety of manipulation tasks, featuring multi-stage, in-the-wild, bimanual, and reactive behaviors, all without task-specific data or environment models. Website at https://rekep-robot.github.io.
OG-Mapping: Octree-based Structured 3D Gaussians for Online Dense Mapping
Aug 30, 2024



3D Gaussian splatting (3DGS) has recently demonstrated promising advancements in RGB-D online dense mapping. Nevertheless, existing methods excessively rely on per-pixel depth cues to perform map densification, which leads to significant redundancy and increased sensitivity to depth noise. Additionally, explicitly storing 3D Gaussian parameters of room-scale scene poses a significant storage challenge. In this paper, we introduce OG-Mapping, which leverages the robust scene structural representation capability of sparse octrees, combined with structured 3D Gaussian representations, to achieve efficient and robust online dense mapping. Moreover, OG-Mapping employs an anchor-based progressive map refinement strategy to recover the scene structures at multiple levels of detail. Instead of maintaining a small number of active keyframes with a fixed keyframe window as previous approaches do, a dynamic keyframe window is employed to allow OG-Mapping to better tackle false local minima and forgetting issues. Experimental results demonstrate that OG-Mapping delivers more robust and superior realism mapping results than existing Gaussian-based RGB-D online mapping methods with a compact model, and no additional post-processing is required.
A longitudinal sentiment analysis of Sinophobia during COVID-19 using large language models
Aug 29, 2024The COVID-19 pandemic has exacerbated xenophobia, particularly Sinophobia, leading to widespread discrimination against individuals of Chinese descent. Large language models (LLMs) are pre-trained deep learning models used for natural language processing (NLP) tasks. The ability of LLMs to understand and generate human-like text makes them particularly useful for analysing social media data to detect and evaluate sentiments. We present a sentiment analysis framework utilising LLMs for longitudinal sentiment analysis of the Sinophobic sentiments expressed in X (Twitter) during the COVID-19 pandemic. The results show a significant correlation between the spikes in Sinophobic tweets, Sinophobic sentiments and surges in COVID-19 cases, revealing that the evolution of the pandemic influenced public sentiment and the prevalence of Sinophobic discourse. Furthermore, the sentiment analysis revealed a predominant presence of negative sentiments, such as annoyance and denial, which underscores the impact of political narratives and misinformation shaping public opinion. The lack of empathetic sentiment which was present in previous studies related to COVID-19 highlights the way the political narratives in media viewed the pandemic and how it blamed the Chinese community. Our study highlights the importance of transparent communication in mitigating xenophobic sentiments during global crises.
Performance Analysis of Photon-Limited Free-Space Optical Communications with Practical Photon-Counting Receivers
Aug 24, 2024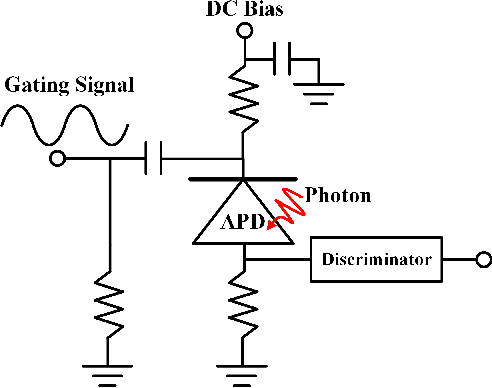
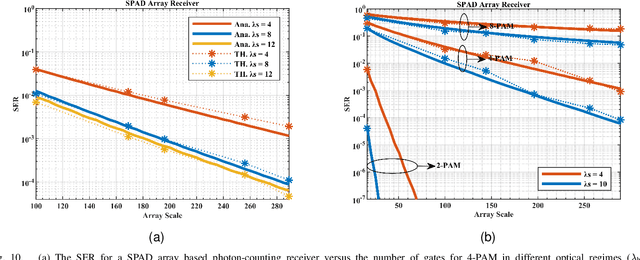
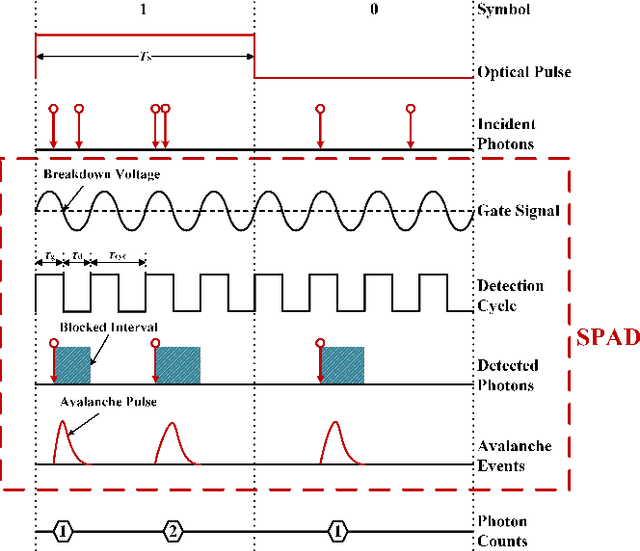
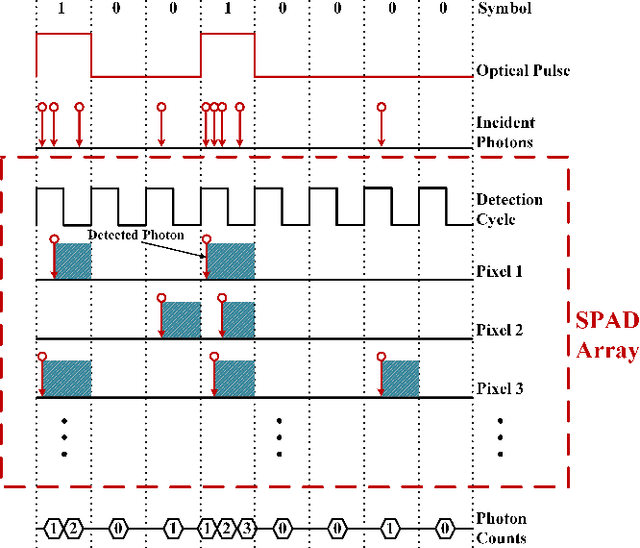
The non-perfect factors of practical photon-counting receiver are recognized as a significant challenge for long-distance photon-limited free-space optical (FSO) communication systems. This paper presents a comprehensive analytical framework for modeling the statistical properties of time-gated single-photon avalanche diode (TG-SPAD) based photon-counting receivers in presence of dead time, non-photon-number-resolving and afterpulsing effect. Drawing upon the non-Markovian characteristic of afterpulsing effect, we formulate a closed-form approximation for the probability mass function (PMF) of photon counts, when high-order pulse amplitude modulation (PAM) is used. Unlike the photon counts from a perfect photon-counting receiver, which adhere to a Poisson arrival process, the photon counts from a practical TG-SPAD based receiver are instead approximated by a binomial distribution. Additionally, by employing the maximum likelihood (ML) criterion, we derive a refined closed-form formula for determining the threshold in high-order PAM, thereby facilitating the development of an analytical model for the symbol error rate (SER). Utilizing this analytical SER model, the system performance is investigated. The numerical results underscore the crucial need to suppress background radiation below the tolerated threshold and to maintain a sufficient number of gates in order to achieve a target SER.
Probing the Robustness of Vision-Language Pretrained Models: A Multimodal Adversarial Attack Approach
Aug 24, 2024



Vision-language pretraining (VLP) with transformers has demonstrated exceptional performance across numerous multimodal tasks. However, the adversarial robustness of these models has not been thoroughly investigated. Existing multimodal attack methods have largely overlooked cross-modal interactions between visual and textual modalities, particularly in the context of cross-attention mechanisms. In this paper, we study the adversarial vulnerability of recent VLP transformers and design a novel Joint Multimodal Transformer Feature Attack (JMTFA) that concurrently introduces adversarial perturbations in both visual and textual modalities under white-box settings. JMTFA strategically targets attention relevance scores to disrupt important features within each modality, generating adversarial samples by fusing perturbations and leading to erroneous model predictions. Experimental results indicate that the proposed approach achieves high attack success rates on vision-language understanding and reasoning downstream tasks compared to existing baselines. Notably, our findings reveal that the textual modality significantly influences the complex fusion processes within VLP transformers. Moreover, we observe no apparent relationship between model size and adversarial robustness under our proposed attacks. These insights emphasize a new dimension of adversarial robustness and underscore potential risks in the reliable deployment of multimodal AI systems.
A Novel Signal Detection Method for Photon-Counting Communications with Nonlinear Distortion Effects
Aug 20, 2024



This paper proposes a method for estimating and detecting optical signals in practical photon-counting receivers. There are two important aspects of non-perfect photon-counting receivers, namely, (i) dead time which results in blocking loss, and (ii) non-photon-number-resolving, which leads to counting loss during the gate-ON interval. These factors introduce nonlinear distortion to the detected photon counts. The detected photon counts depend not only on the optical intensity but also on the signal waveform, and obey a Poisson binomial process. Using the discrete Fourier transform characteristic function (DFT-CF) method, we derive the probability mass function (PMF) of the detected photon counts. Furthermore, unlike conventional methods that assume an ideal rectangle wave, we propose a novel signal estimation and decision method applicable to arbitrary waveform. We demonstrate that the proposed method achieves superior error performance compared to conventional methods. The proposed algorithm has the potential to become an essential signal processing tool for photon-counting receivers.
AirSLAM: An Efficient and Illumination-Robust Point-Line Visual SLAM System
Aug 07, 2024



In this paper, we present an efficient visual SLAM system designed to tackle both short-term and long-term illumination challenges. Our system adopts a hybrid approach that combines deep learning techniques for feature detection and matching with traditional backend optimization methods. Specifically, we propose a unified convolutional neural network (CNN) that simultaneously extracts keypoints and structural lines. These features are then associated, matched, triangulated, and optimized in a coupled manner. Additionally, we introduce a lightweight relocalization pipeline that reuses the built map, where keypoints, lines, and a structure graph are used to match the query frame with the map. To enhance the applicability of the proposed system to real-world robots, we deploy and accelerate the feature detection and matching networks using C++ and NVIDIA TensorRT. Extensive experiments conducted on various datasets demonstrate that our system outperforms other state-of-the-art visual SLAM systems in illumination-challenging environments. Efficiency evaluations show that our system can run at a rate of 73Hz on a PC and 40Hz on an embedded platform.