 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrafting Adversarial Inputs for Large Vision-Language Models Using Black-Box Optimization
Jan 08, 2026Recent advancements in Large Vision-Language Models (LVLMs) have shown groundbreaking capabilities across diverse multimodal tasks. However, these models remain vulnerable to adversarial jailbreak attacks, where adversaries craft subtle perturbations to bypass safety mechanisms and trigger harmful outputs. Existing white-box attacks methods require full model accessibility, suffer from computing costs and exhibit insufficient adversarial transferability, making them impractical for real-world, black-box settings. To address these limitations, we propose a black-box jailbreak attack on LVLMs via Zeroth-Order optimization using Simultaneous Perturbation Stochastic Approximation (ZO-SPSA). ZO-SPSA provides three key advantages: (i) gradient-free approximation by input-output interactions without requiring model knowledge, (ii) model-agnostic optimization without the surrogate model and (iii) lower resource requirements with reduced GPU memory consumption. We evaluate ZO-SPSA on three LVLMs, including InstructBLIP, LLaVA and MiniGPT-4, achieving the highest jailbreak success rate of 83.0% on InstructBLIP, while maintaining imperceptible perturbations comparable to white-box methods. Moreover, adversarial examples generated from MiniGPT-4 exhibit strong transferability to other LVLMs, with ASR reaching 64.18%. These findings underscore the real-world feasibility of black-box jailbreaks and expose critical weaknesses in the safety mechanisms of current LVLMs
Probing the Robustness of Vision-Language Pretrained Models: A Multimodal Adversarial Attack Approach
Aug 24, 2024



Vision-language pretraining (VLP) with transformers has demonstrated exceptional performance across numerous multimodal tasks. However, the adversarial robustness of these models has not been thoroughly investigated. Existing multimodal attack methods have largely overlooked cross-modal interactions between visual and textual modalities, particularly in the context of cross-attention mechanisms. In this paper, we study the adversarial vulnerability of recent VLP transformers and design a novel Joint Multimodal Transformer Feature Attack (JMTFA) that concurrently introduces adversarial perturbations in both visual and textual modalities under white-box settings. JMTFA strategically targets attention relevance scores to disrupt important features within each modality, generating adversarial samples by fusing perturbations and leading to erroneous model predictions. Experimental results indicate that the proposed approach achieves high attack success rates on vision-language understanding and reasoning downstream tasks compared to existing baselines. Notably, our findings reveal that the textual modality significantly influences the complex fusion processes within VLP transformers. Moreover, we observe no apparent relationship between model size and adversarial robustness under our proposed attacks. These insights emphasize a new dimension of adversarial robustness and underscore potential risks in the reliable deployment of multimodal AI systems.
Trustworthy Sensor Fusion against Inaudible Command Attacks in Advanced Driver-Assistance System
May 30, 2023



There are increasing concerns about malicious attacks on autonomous vehicles. In particular, inaudible voice command attacks pose a significant threat as voice commands become available in autonomous driving systems. How to empirically defend against these inaudible attacks remains an open question. Previous research investigates utilizing deep learning-based multimodal fusion for defense, without considering the model uncertainty in trustworthiness. As deep learning has been applied to increasingly sensitive tasks, uncertainty measurement is crucial in helping improve model robustness, especially in mission-critical scenarios. In this paper, we propose the Multimodal Fusion Framework (MFF) as an intelligent security system to defend against inaudible voice command attacks. MFF fuses heterogeneous audio-vision modalities using VGG family neural networks and achieves the detection accuracy of 92.25% in the comparative fusion method empirical study. Additionally, extensive experiments on audio-vision tasks reveal the model's uncertainty. Using Expected Calibration Errors, we measure calibration errors and Monte-Carlo Dropout to estimate the predictive distribution for the proposed models. Our findings show empirically to train robust multimodal models, improve standard accuracy and provide a further step toward interpretability. Finally, we discuss the pros and cons of our approach and its applicability for Advanced Driver Assistance Systems.
Robust Sensor Fusion Algorithms Against VoiceCommand Attacks in Autonomous Vehicles
Apr 20, 2021
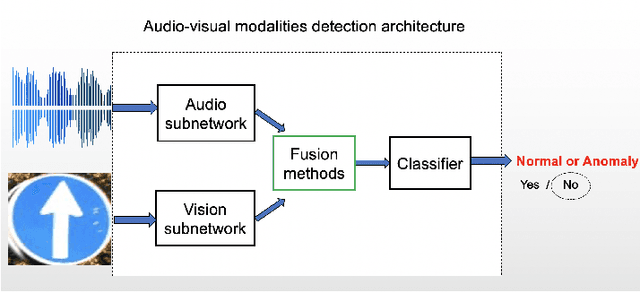
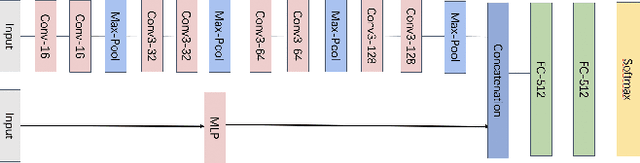
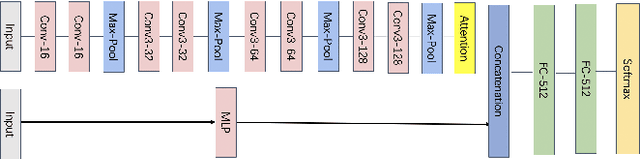
With recent advances in autonomous driving, Voice Control Systems have become increasingly adopted as human-vehicle interaction methods. This technology enables drivers to use voice commands to control the vehicle and will be soon available in Advanced Driver Assistance Systems (ADAS). Prior work has shown that Siri, Alexa and Cortana, are highly vulnerable to inaudible command attacks. This could be extended to ADAS in real-world applications and such inaudible command threat is difficult to detect due to microphone nonlinearities. In this paper, we aim to develop a more practical solution by using camera views to defend against inaudible command attacks where ADAS are capable of detecting their environment via multi-sensors. To this end, we propose a novel multimodal deep learning classification system to defend against inaudible command attacks. Our experimental results confirm the feasibility of the proposed defense methods and the best classification accuracy reaches 89.2%. Code is available at https://github.com/ITSEG-MQ/Sensor-Fusion-Against-VoiceCommand-Attacks.