 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Retrieval Conversational Question Answering
May 22, 2020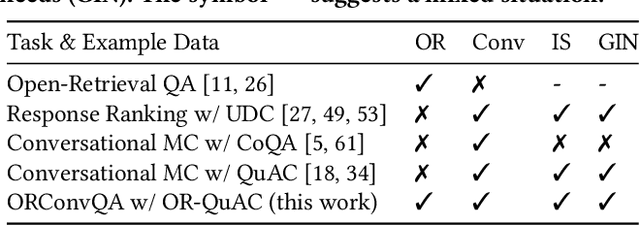
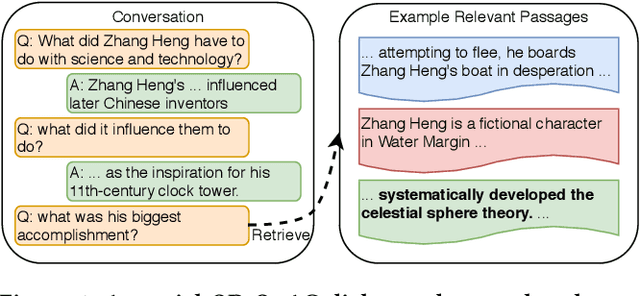
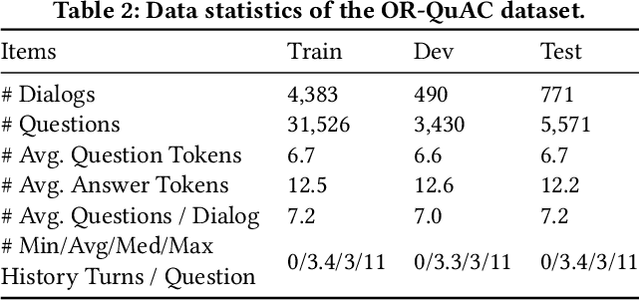
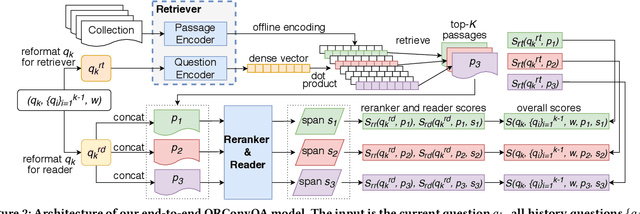
Conversational search is one of the ultimate goals of information retrieval. Recent research approaches conversational search by simplified settings of response ranking and conversational question answering, where an answer is either selected from a given candidate set or extracted from a given passage. These simplifications neglect the fundamental role of retrieval in conversational search. To address this limitation, we introduce an open-retrieval conversational question answering (ORConvQA) setting, where we learn to retrieve evidence from a large collection before extracting answers, as a further step towards building functional conversational search systems. We create a dataset, OR-QuAC, to facilitate research on ORConvQA. We build an end-to-end system for ORConvQA, featuring a retriever, a reranker, and a reader that are all based on Transformers. Our extensive experiments on OR-QuAC demonstrate that a learnable retriever is crucial for ORConvQA. We further show that our system can make a substantial improvement when we enable history modeling in all system components. Moreover, we show that the reranker component contributes to the model performance by providing a regularization effect. Finally, further in-depth analyses are performed to provide new insights into ORConvQA.
IART: Intent-aware Response Ranking with Transformers in Information-seeking Conversation Systems
Feb 03, 2020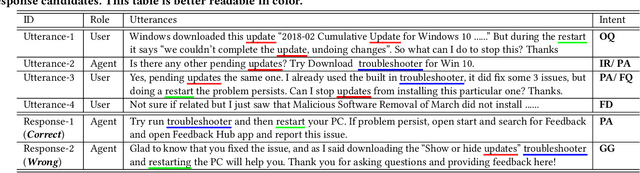
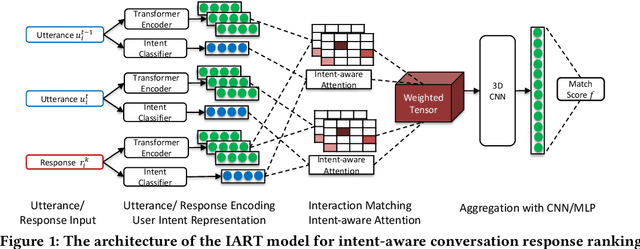
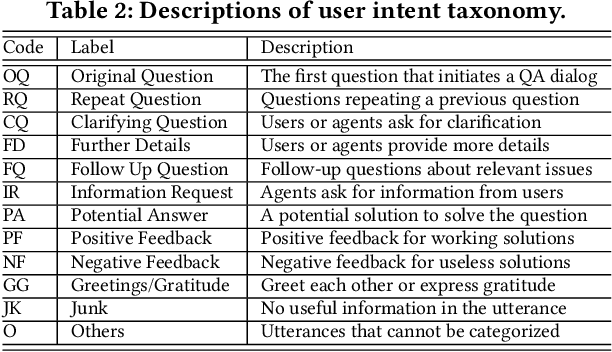
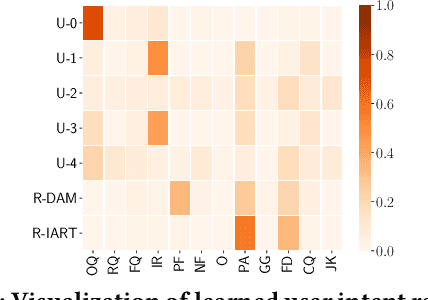
Personal assistant systems, such as Apple Siri, Google Assistant, Amazon Alexa, and Microsoft Cortana, are becoming ever more widely used. Understanding user intent such as clarification questions, potential answers and user feedback in information-seeking conversations is critical for retrieving good responses. In this paper, we analyze user intent patterns in information-seeking conversations and propose an intent-aware neural response ranking model "IART", which refers to "Intent-Aware Ranking with Transformers". IART is built on top of the integration of user intent modeling and language representation learning with the Transformer architecture, which relies entirely on a self-attention mechanism instead of recurrent nets. It incorporates intent-aware utterance attention to derive an importance weighting scheme of utterances in conversation context with the aim of better conversation history understanding. We conduct extensive experiments with three information-seeking conversation data sets including both standard benchmarks and commercial data. Our proposed model outperforms all baseline methods with respect to a variety of metrics. We also perform case studies and analysis of learned user intent and its impact on response ranking in information-seeking conversations to provide interpretation of results.
A Hybrid Retrieval-Generation Neural Conversation Model
Apr 19, 2019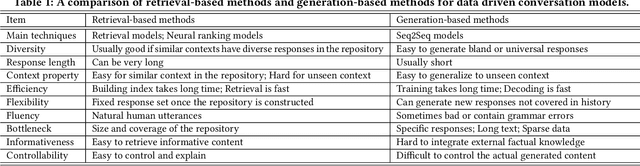
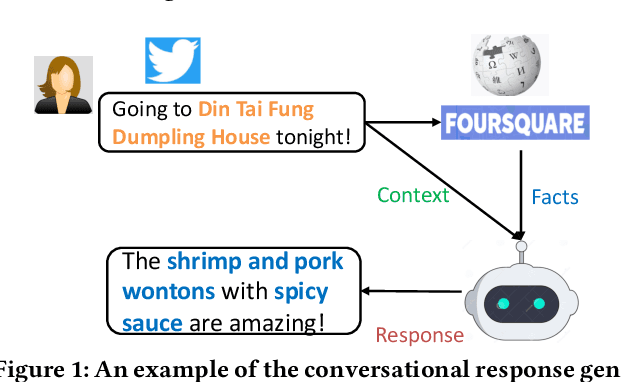

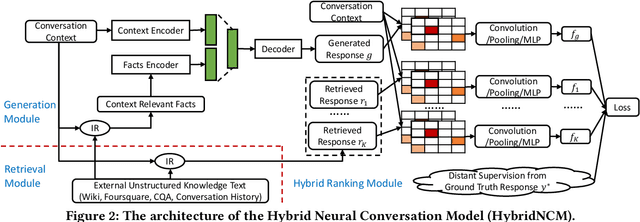
Intelligent personal assistant systems, with either text-based or voice-based conversational interfaces, are becoming increasingly popular. Most previous research has used either retrieval-based or generation-based methods. Retrieval-based methods have the advantage of returning fluent and informative responses with great diversity. The retrieved responses are easier to control and explain. However, the response retrieval performance is limited by the size of the response repository. On the other hand, although generation-based methods can return highly coherent responses given conversation context, they are likely to return universal or general responses with insufficient ground knowledge information. In this paper, we build a hybrid neural conversation model with the capability of both response retrieval and generation, in order to combine the merits of these two types of methods. Experimental results on Twitter and Foursquare data show that the proposed model can outperform both retrieval-based methods and generation-based methods (including a recently proposed knowledge-grounded neural conversation model) under both automatic evaluation metrics and human evaluation. Our models and research findings provide new insights on how to integrate text retrieval and text generation models for building conversation systems.
Answer Interaction in Non-factoid Question Answering Systems
Jan 15, 2019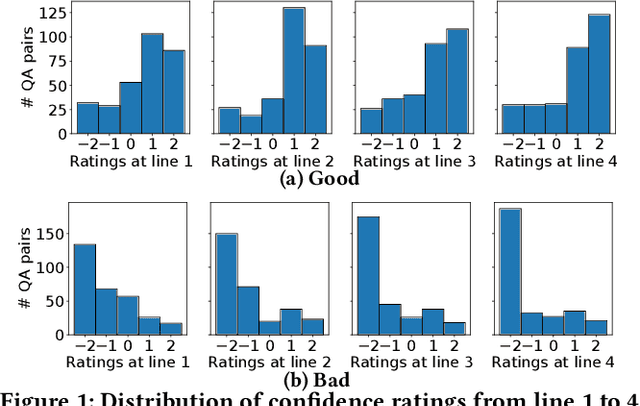
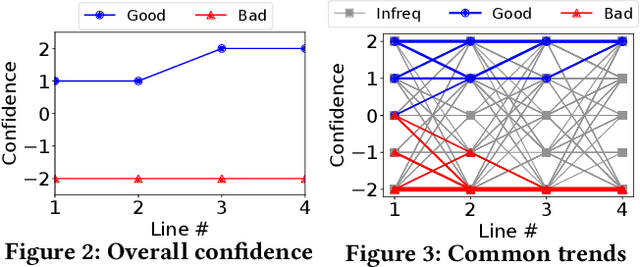
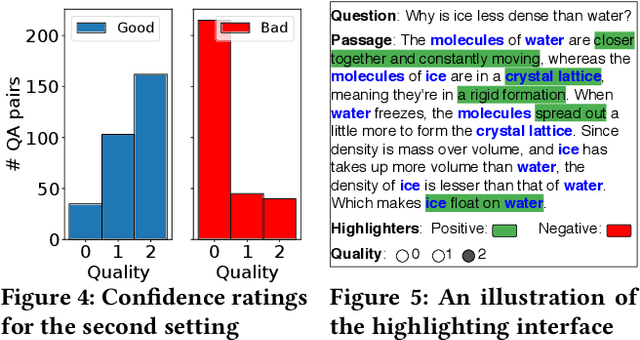
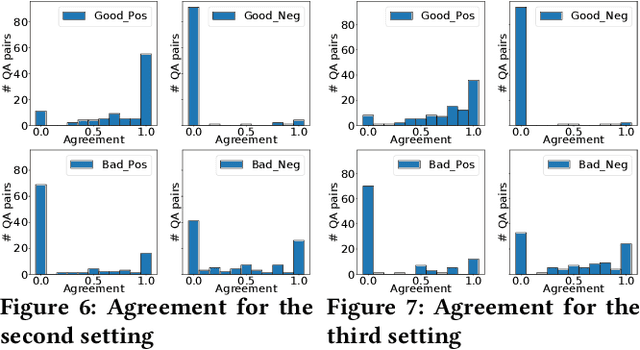
Information retrieval systems are evolving from document retrieval to answer retrieval. Web search logs provide large amounts of data about how people interact with ranked lists of documents, but very little is known about interaction with answer texts. In this paper, we use Amazon Mechanical Turk to investigate three answer presentation and interaction approaches in a non-factoid question answering setting. We find that people perceive and react to good and bad answers very differently, and can identify good answers relatively quickly. Our results provide the basis for further investigation of effective answer interaction and feedback methods.
User Intent Prediction in Information-seeking Conversations
Jan 11, 2019
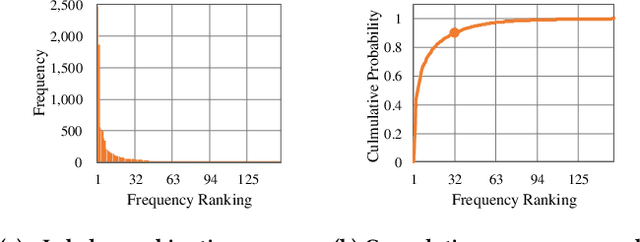
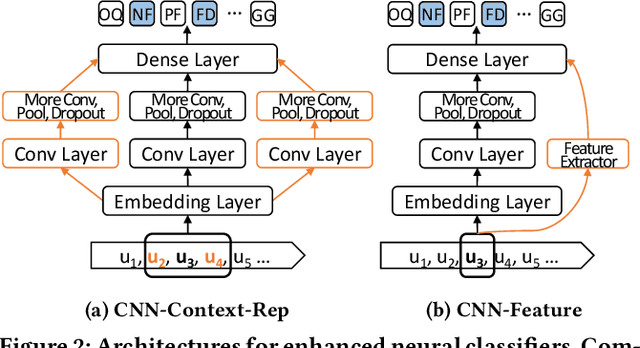
Conversational assistants are being progressively adopted by the general population. However, they are not capable of handling complicated information-seeking tasks that involve multiple turns of information exchange. Due to the limited communication bandwidth in conversational search, it is important for conversational assistants to accurately detect and predict user intent in information-seeking conversations. In this paper, we investigate two aspects of user intent prediction in an information-seeking setting. First, we extract features based on the content, structural, and sentiment characteristics of a given utterance, and use classic machine learning methods to perform user intent prediction. We then conduct an in-depth feature importance analysis to identify key features in this prediction task. We find that structural features contribute most to the prediction performance. Given this finding, we construct neural classifiers to incorporate context information and achieve better performance without feature engineering. Our findings can provide insights into the important factors and effective methods of user intent prediction in information-seeking conversations.
Learning to Selectively Transfer: Reinforced Transfer Learning for Deep Text Matching
Dec 30, 2018
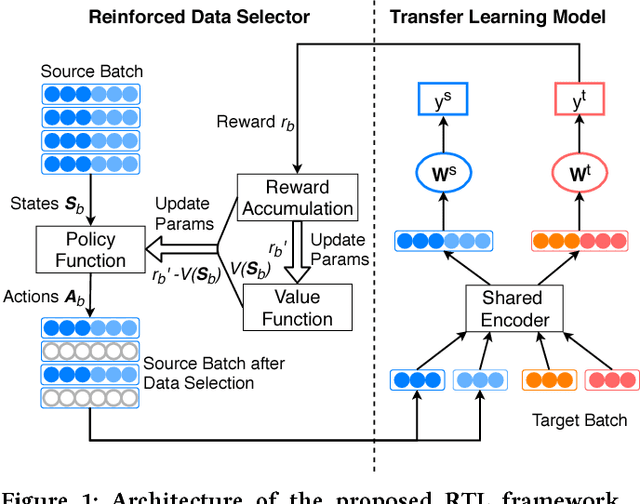
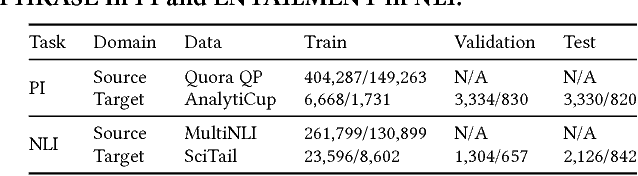
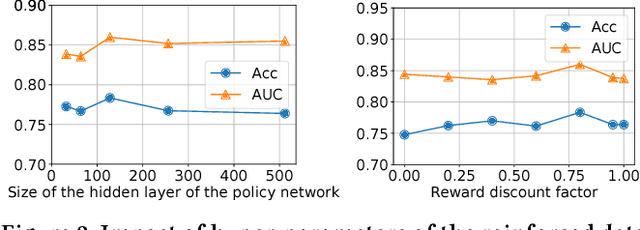
Deep text matching approaches have been widely studied for many applications including question answering and information retrieval systems. To deal with a domain that has insufficient labeled data, these approaches can be used in a Transfer Learning (TL) setting to leverage labeled data from a resource-rich source domain. To achieve better performance, source domain data selection is essential in this process to prevent the "negative transfer" problem. However, the emerging deep transfer models do not fit well with most existing data selection methods, because the data selection policy and the transfer learning model are not jointly trained, leading to sub-optimal training efficiency. In this paper, we propose a novel reinforced data selector to select high-quality source domain data to help the TL model. Specifically, the data selector "acts" on the source domain data to find a subset for optimization of the TL model, and the performance of the TL model can provide "rewards" in turn to update the selector. We build the reinforced data selector based on the actor-critic framework and integrate it to a DNN based transfer learning model, resulting in a Reinforced Transfer Learning (RTL) method. We perform a thorough experimental evaluation on two major tasks for text matching, namely, paraphrase identification and natural language inference. Experimental results show the proposed RTL can significantly improve the performance of the TL model. We further investigate different settings of states, rewards, and policy optimization methods to examine the robustness of our method. Last, we conduct a case study on the selected data and find our method is able to select source domain data whose Wasserstein distance is close to the target domain data. This is reasonable and intuitive as such source domain data can provide more transferability power to the model.
Response Ranking with Deep Matching Networks and External Knowledge in Information-seeking Conversation Systems
May 09, 2018
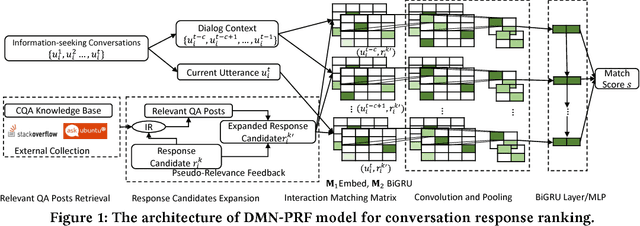
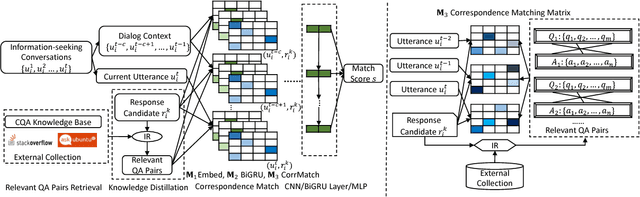
Intelligent personal assistant systems with either text-based or voice-based conversational interfaces are becoming increasingly popular around the world. Retrieval-based conversation models have the advantages of returning fluent and informative responses. Most existing studies in this area are on open domain "chit-chat" conversations or task / transaction oriented conversations. More research is needed for information-seeking conversations. There is also a lack of modeling external knowledge beyond the dialog utterances among current conversational models. In this paper, we propose a learning framework on the top of deep neural matching networks that leverages external knowledge for response ranking in information-seeking conversation systems. We incorporate external knowledge into deep neural models with pseudo-relevance feedback and QA correspondence knowledge distillation. Extensive experiments with three information-seeking conversation data sets including both open benchmarks and commercial data show that, our methods outperform various baseline methods including several deep text matching models and the state-of-the-art method on response selection in multi-turn conversations. We also perform analysis over different response types, model variations and ranking examples. Our models and research findings provide new insights on how to utilize external knowledge with deep neural models for response selection and have implications for the design of the next generation of information-seeking conversation systems.
Analyzing and Characterizing User Intent in Information-seeking Conversations
Apr 23, 2018

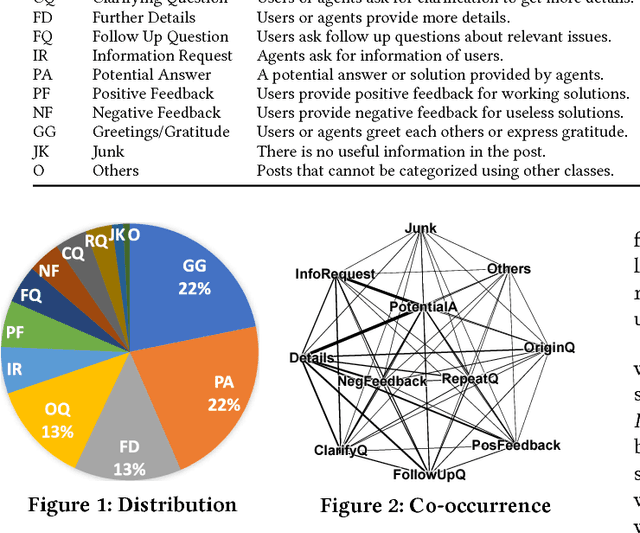
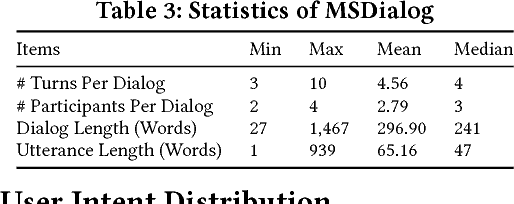
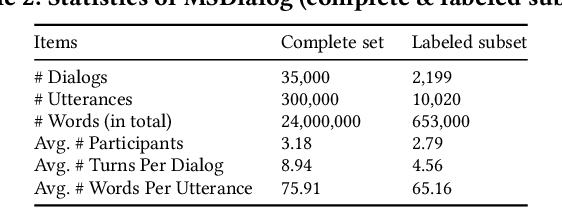
Understanding and characterizing how people interact in information-seeking conversations is crucial in developing conversational search systems. In this paper, we introduce a new dataset designed for this purpose and use it to analyze information-seeking conversations by user intent distribution, co-occurrence, and flow patterns. The MSDialog dataset is a labeled dialog dataset of question answering (QA) interactions between information seekers and providers from an online forum on Microsoft products. The dataset contains more than 2,000 multi-turn QA dialogs with 10,000 utterances that are annotated with user intent on the utterance level. Annotations were done using crowdsourcing. With MSDialog, we find some highly recurring patterns in user intent during an information-seeking process. They could be useful for designing conversational search systems. We will make our dataset freely available to encourage exploration of information-seeking conversation models.