 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models
Apr 23, 2023Large language models (LLMs) can achieve highly effective performance on various reasoning tasks by incorporating step-by-step chain-of-thought (CoT) prompting as demonstrations. However, the reasoning chains of demonstrations generated by LLMs are prone to errors, which can subsequently lead to incorrect reasoning during inference. Furthermore, inappropriate exemplars (overly simplistic or complex), can affect overall performance among varying levels of difficulty. We introduce Iter-CoT (Iterative bootstrapping in Chain-of-Thoughts Prompting), an iterative bootstrapping approach for selecting exemplars and generating reasoning chains. By utilizing iterative bootstrapping, our approach enables LLMs to autonomously rectify errors, resulting in more precise and comprehensive reasoning chains. Simultaneously, our approach selects challenging yet answerable questions accompanied by reasoning chains as exemplars with a moderate level of difficulty, which enhances the LLMs' generalizability across varying levels of difficulty. Experimental results indicate that Iter-CoT exhibits superiority, achieving competitive performance across three distinct reasoning tasks on eleven datasets.
AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators
Mar 29, 2023



Many natural language processing (NLP) tasks rely on labeled data to train machine learning models to achieve high performance. However, data annotation can be a time-consuming and expensive process, especially when the task involves a large amount of data or requires specialized domains. Recently, GPT-3.5 series models have demonstrated remarkable few-shot and zero-shot ability across various NLP tasks. In this paper, we first claim that large language models (LLMs), such as GPT-3.5, can serve as an excellent crowdsourced annotator by providing them with sufficient guidance and demonstrated examples. To make LLMs to be better annotators, we propose a two-step approach, 'explain-then-annotate'. To be more precise, we begin by creating prompts for every demonstrated example, which we subsequently utilize to prompt a LLM to provide an explanation for why the specific ground truth answer/label was chosen for that particular example. Following this, we construct the few-shot chain-of-thought prompt with the self-generated explanation and employ it to annotate the unlabeled data. We conduct experiments on three tasks, including user input and keyword relevance assessment, BoolQ and WiC. The annotation results from GPT-3.5 surpasses those from crowdsourced annotation for user input and keyword relevance assessment. Additionally, for the other two tasks, GPT-3.5 achieves results that are comparable to those obtained through crowdsourced annotation.
Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling
Jan 10, 2023We identify and overcome two key obstacles in extending the success of BERT-style pre-training, or the masked image modeling, to convolutional networks (convnets): (i) convolution operation cannot handle irregular, random-masked input images; (ii) the single-scale nature of BERT pre-training is inconsistent with convnet's hierarchical structure. For (i), we treat unmasked pixels as sparse voxels of 3D point clouds and use sparse convolution to encode. This is the first use of sparse convolution for 2D masked modeling. For (ii), we develop a hierarchical decoder to reconstruct images from multi-scale encoded features. Our method called Sparse masKed modeling (SparK) is general: it can be used directly on any convolutional model without backbone modifications. We validate it on both classical (ResNet) and modern (ConvNeXt) models: on three downstream tasks, it surpasses both state-of-the-art contrastive learning and transformer-based masked modeling by similarly large margins (around +1.0%). Improvements on object detection and instance segmentation are more substantial (up to +3.5%), verifying the strong transferability of features learned. We also find its favorable scaling behavior by observing more gains on larger models. All this evidence reveals a promising future of generative pre-training on convnets. Codes and models are released at https://github.com/keyu-tian/SparK.
GENIE: Large Scale Pre-training for Text Generation with Diffusion Model
Dec 22, 2022



In this paper, we propose a large-scale language pre-training for text GENeration using dIffusion modEl, which is named GENIE. GENIE is a pre-training sequence-to-sequence text generation model which combines Transformer and diffusion. The diffusion model accepts the latent information from the encoder, which is used to guide the denoising of the current time step. After multiple such denoise iterations, the diffusion model can restore the Gaussian noise to the diverse output text which is controlled by the input text. Moreover, such architecture design also allows us to adopt large scale pre-training on the GENIE. We propose a novel pre-training method named continuous paragraph denoise based on the characteristics of the diffusion model. Extensive experiments on the XSum, CNN/DailyMail, and Gigaword benchmarks shows that GENIE can achieves comparable performance with various strong baselines, especially after pre-training, the generation quality of GENIE is greatly improved. We have also conduct a lot of experiments on the generation diversity and parameter impact of GENIE. The code for GENIE will be made publicly available.
APOLLO: An Optimized Training Approach for Long-form Numerical Reasoning
Dec 14, 2022Long-form numerical reasoning in financial analysis aims to generate a reasoning program to calculate the correct answer for a given question. Previous work followed a retriever-generator framework, where the retriever selects key facts from a long-form document, and the generator generates a reasoning program based on retrieved facts. However, they treated all facts equally without considering the different contributions of facts with and without numbers. Meanwhile, the program consistency were ignored under supervised training, resulting in lower training accuracy and diversity. To solve these problems, we proposed APOLLO to improve the long-form numerical reasoning framework. For the retriever, we adopt a number-aware negative sampling strategy to enable the retriever to be more discriminative on key numerical facts. For the generator, we design consistency-based reinforcement learning and target program augmentation strategy based on the consistency of program execution results. Experimental results on the FinQA and ConvFinQA leaderboard verify the effectiveness of our proposed method, achieving the new state-of-the-art.
Unsupervised Extractive Summarization with Heterogeneous Graph Embeddings for Chinese Document
Nov 09, 2022



In the scenario of unsupervised extractive summarization, learning high-quality sentence representations is essential to select salient sentences from the input document. Previous studies focus more on employing statistical approaches or pre-trained language models (PLMs) to extract sentence embeddings, while ignoring the rich information inherent in the heterogeneous types of interaction between words and sentences. In this paper, we are the first to propose an unsupervised extractive summarizaiton method with heterogeneous graph embeddings (HGEs) for Chinese document. A heterogeneous text graph is constructed to capture different granularities of interactions by incorporating graph structural information. Moreover, our proposed graph is general and flexible where additional nodes such as keywords can be easily integrated. Experimental results demonstrate that our method consistently outperforms the strong baseline in three summarization datasets.
Detecting Elevated Air Pollution Levels by Monitoring Web Search Queries: Deep Learning-Based Time Series Forecasting
Nov 09, 2022



Real-time air pollution monitoring is a valuable tool for public health and environmental surveillance. In recent years, there has been a dramatic increase in air pollution forecasting and monitoring research using artificial neural networks (ANNs). Most of the prior work relied on modeling pollutant concentrations collected from ground-based monitors and meteorological data for long-term forecasting of outdoor ozone, oxides of nitrogen, and PM2.5. Given that traditional, highly sophisticated air quality monitors are expensive and are not universally available, these models cannot adequately serve those not living near pollutant monitoring sites. Furthermore, because prior models were built on physical measurement data collected from sensors, they may not be suitable for predicting public health effects experienced from pollution exposure. This study aims to develop and validate models to nowcast the observed pollution levels using Web search data, which is publicly available in near real-time from major search engines. We developed novel machine learning-based models using both traditional supervised classification methods and state-of-the-art deep learning methods to detect elevated air pollution levels at the US city level, by using generally available meteorological data and aggregate Web-based search volume data derived from Google Trends. We validated the performance of these methods by predicting three critical air pollutants (ozone (O3), nitrogen dioxide (NO2), and fine particulate matter (PM2.5)), across ten major U.S. metropolitan statistical areas (MSAs) in 2017 and 2018.
Sentiment-Aware Word and Sentence Level Pre-training for Sentiment Analysis
Oct 19, 2022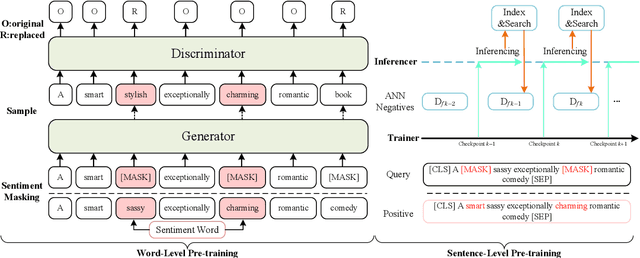
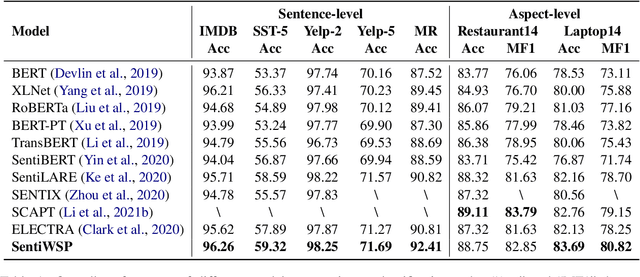
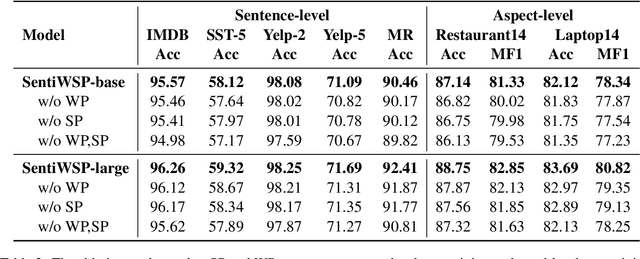
Most existing pre-trained language representation models (PLMs) are sub-optimal in sentiment analysis tasks, as they capture the sentiment information from word-level while under-considering sentence-level information. In this paper, we propose SentiWSP, a novel Sentiment-aware pre-trained language model with combined Word-level and Sentence-level Pre-training tasks. The word level pre-training task detects replaced sentiment words, via a generator-discriminator framework, to enhance the PLM's knowledge about sentiment words. The sentence level pre-training task further strengthens the discriminator via a contrastive learning framework, with similar sentences as negative samples, to encode sentiments in a sentence. Extensive experimental results show that SentiWSP achieves new state-of-the-art performance on various sentence-level and aspect-level sentiment classification benchmarks. We have made our code and model publicly available at https://github.com/XMUDM/SentiWSP.
PROD: Progressive Distillation for Dense Retrieval
Sep 27, 2022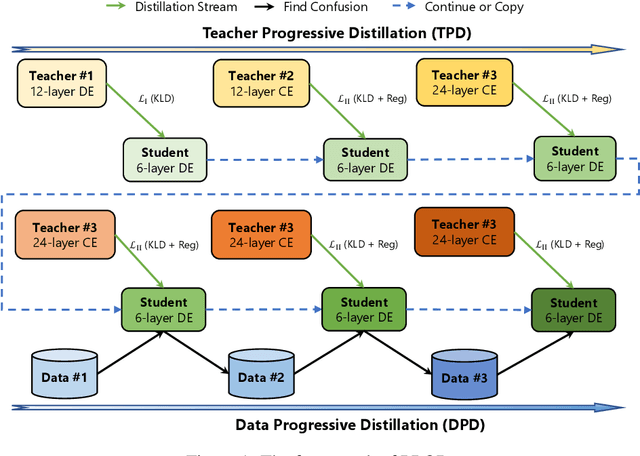
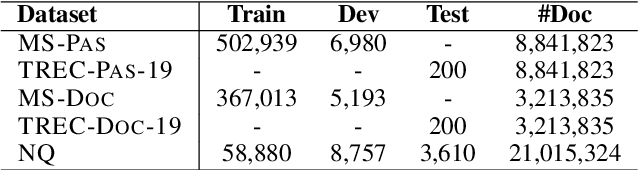
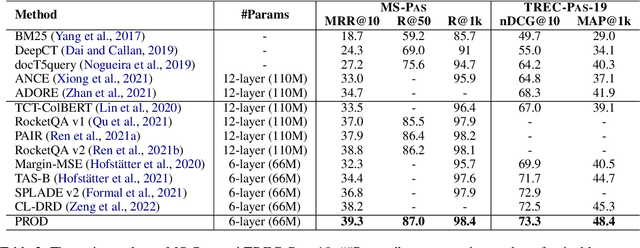
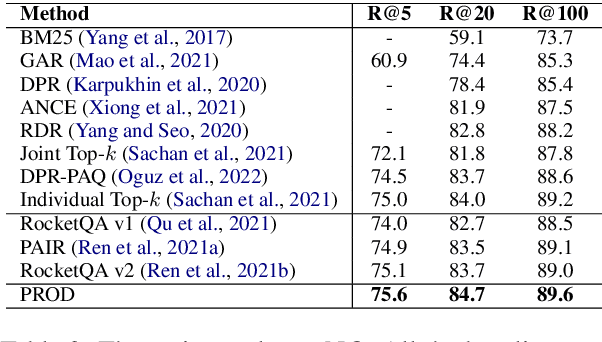
Knowledge distillation is an effective way to transfer knowledge from a strong teacher to an efficient student model. Ideally, we expect the better the teacher is, the better the student. However, this expectation does not always come true. It is common that a better teacher model results in a bad student via distillation due to the nonnegligible gap between teacher and student. To bridge the gap, we propose PROD, a PROgressive Distillation method, for dense retrieval. PROD consists of a teacher progressive distillation and a data progressive distillation to gradually improve the student. We conduct extensive experiments on five widely-used benchmarks, MS MARCO Passage, TREC Passage 19, TREC Document 19, MS MARCO Document and Natural Questions, where PROD achieves the state-of-the-art within the distillation methods for dense retrieval. The code and models will be released.
Efficient Joint-Dimensional Search with Solution Space Regularization for Real-Time Semantic Segmentation
Aug 10, 2022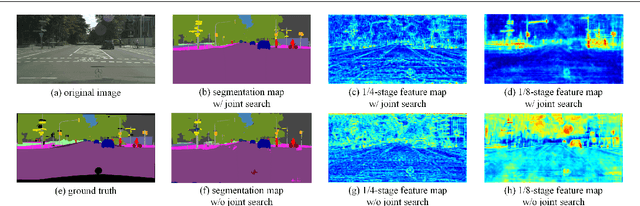
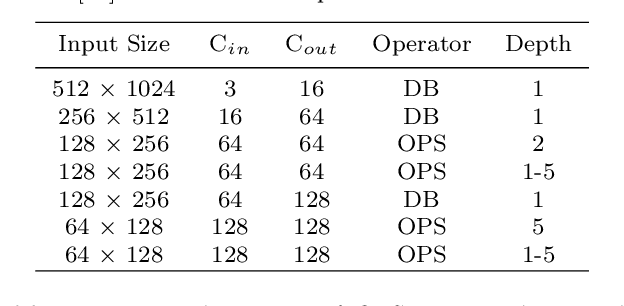
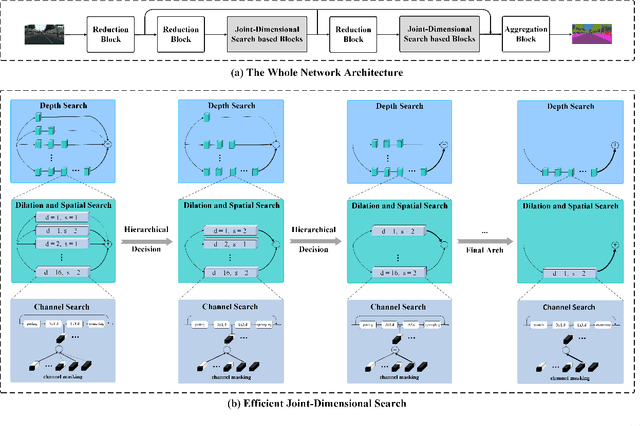
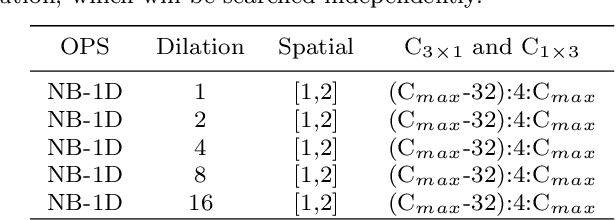
Semantic segmentation is a popular research topic in computer vision, and many efforts have been made on it with impressive results. In this paper, we intend to search an optimal network structure that can run in real-time for this problem. Towards this goal, we jointly search the depth, channel, dilation rate and feature spatial resolution, which results in a search space consisting of about 2.78*10^324 possible choices. To handle such a large search space, we leverage differential architecture search methods. However, the architecture parameters searched using existing differential methods need to be discretized, which causes the discretization gap between the architecture parameters found by the differential methods and their discretized version as the final solution for the architecture search. Hence, we relieve the problem of discretization gap from the innovative perspective of solution space regularization. Specifically, a novel Solution Space Regularization (SSR) loss is first proposed to effectively encourage the supernet to converge to its discrete one. Then, a new Hierarchical and Progressive Solution Space Shrinking method is presented to further achieve high efficiency of searching. In addition, we theoretically show that the optimization of SSR loss is equivalent to the L_0-norm regularization, which accounts for the improved search-evaluation gap. Comprehensive experiments show that the proposed search scheme can efficiently find an optimal network structure that yields an extremely fast speed (175 FPS) of segmentation with a small model size (1 M) while maintaining comparable accuracy.