 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTernary Hashing
Mar 19, 2021
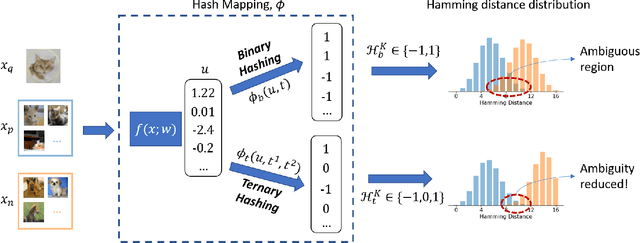
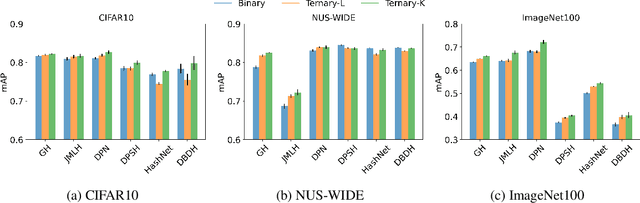
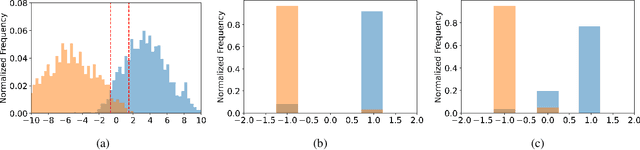
This paper proposes a novel ternary hash encoding for learning to hash methods, which provides a principled more efficient coding scheme with performances better than those of the state-of-the-art binary hashing counterparts. Two kinds of axiomatic ternary logic, Kleene logic and {\L}ukasiewicz logic are adopted to calculate the Ternary Hamming Distance (THD) for both the learning/encoding and testing/querying phases. Our work demonstrates that, with an efficient implementation of ternary logic on standard binary machines, the proposed ternary hashing is compared favorably to the binary hashing methods with consistent improvements of retrieval mean average precision (mAP) ranging from 1\% to 5.9\% as shown in CIFAR10, NUS-WIDE and ImageNet100 datasets.
Protecting Intellectual Property of Generative Adversarial Networks from Ambiguity Attack
Mar 01, 2021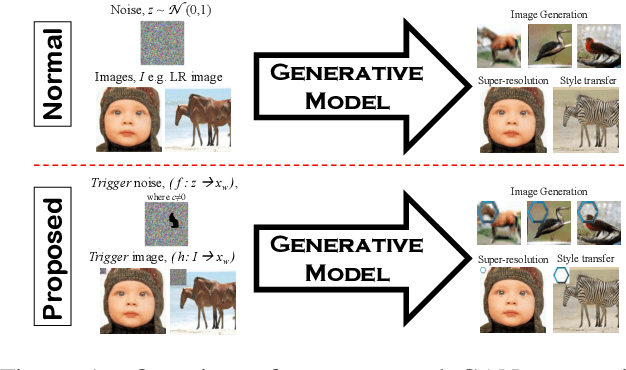



Ever since Machine Learning as a Service (MLaaS) emerges as a viable business that utilizes deep learning models to generate lucrative revenue, Intellectual Property Right (IPR) has become a major concern because these deep learning models can easily be replicated, shared, and re-distributed by any unauthorized third parties. To the best of our knowledge, one of the prominent deep learning models - Generative Adversarial Networks (GANs) which has been widely used to create photorealistic image are totally unprotected despite the existence of pioneering IPR protection methodology for Convolutional Neural Networks (CNNs). This paper therefore presents a complete protection framework in both black-box and white-box settings to enforce IPR protection on GANs. Empirically, we show that the proposed method does not compromise the original GANs performance (i.e. image generation, image super-resolution, style transfer), and at the same time, it is able to withstand both removal and ambiguity attacks against embedded watermarks.
Protect, Show, Attend and Tell: Image Captioning Model with Ownership Protection
Aug 25, 2020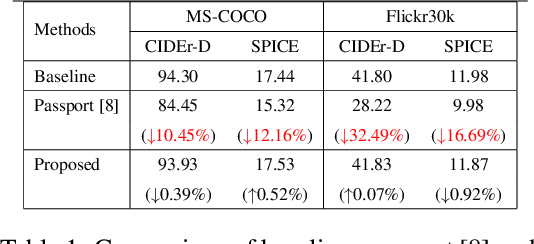
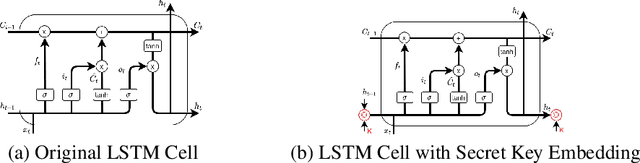
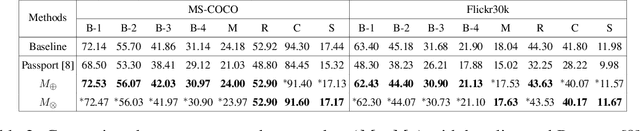

By and large, existing Intellectual Property Right (IPR) protection on deep neural networks typically i) focus on image classification task only, and ii) follow a standard digital watermarking framework that were conventionally used to protect the ownership of multimedia and video content. This paper demonstrates that current digital watermarking framework is insufficient to protect image captioning task that often regarded as one of the frontier A.I. problems. As a remedy, this paper studies and proposes two different embedding schemes in the hidden memory state of a recurrent neural network to protect image captioning model. From both theoretically and empirically points, we prove that a forged key will yield an unusable image captioning model, defeating the purpose on infringement. To the best of our knowledge, this work is the first to propose ownership protection on image captioning task. Also, extensive experiments show that the proposed method does not compromise the original image captioning performance on all common captioning metrics on Flickr30k and MS-COCO datasets, and at the same time it is able to withstand both removal and ambiguity attacks.
Rethinking Privacy Preserving Deep Learning: How to Evaluate and Thwart Privacy Attacks
Jun 23, 2020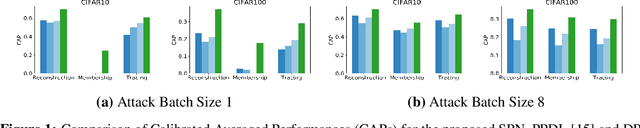

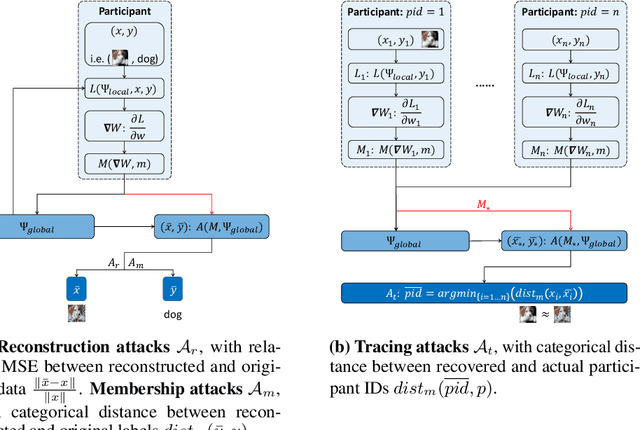
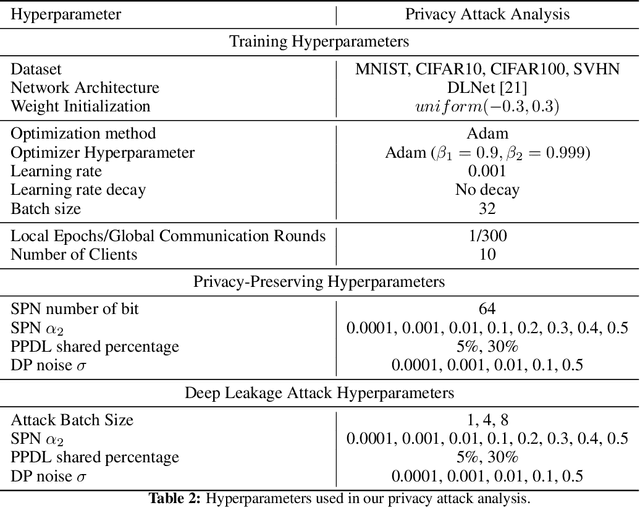
This paper investigates capabilities of Privacy-Preserving Deep Learning (PPDL) mechanisms against various forms of privacy attacks. First, we propose to quantitatively measure the trade-off between model accuracy and privacy losses incurred by reconstruction, tracing and membership attacks. Second, we formulate reconstruction attacks as solving a noisy system of linear equations, and prove that attacks are guaranteed to be defeated if condition (2) is unfulfilled. Third, based on theoretical analysis, a novel Secret Polarization Network (SPN) is proposed to thwart privacy attacks, which pose serious challenges to existing PPDL methods. Extensive experiments showed that model accuracies are improved on average by 5-20% compared with baseline mechanisms, in regimes where data privacy are satisfactorily protected.
On the General Value of Evidence, and Bilingual Scene-Text Visual Question Answering
Feb 26, 2020
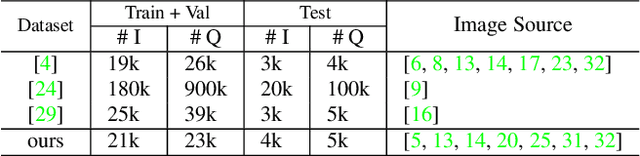

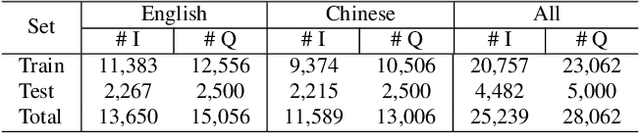
Visual Question Answering (VQA) methods have made incredible progress, but suffer from a failure to generalize. This is visible in the fact that they are vulnerable to learning coincidental correlations in the data rather than deeper relations between image content and ideas expressed in language. We present a dataset that takes a step towards addressing this problem in that it contains questions expressed in two languages, and an evaluation process that co-opts a well understood image-based metric to reflect the method's ability to reason. Measuring reasoning directly encourages generalization by penalizing answers that are coincidentally correct. The dataset reflects the scene-text version of the VQA problem, and the reasoning evaluation can be seen as a text-based version of a referring expression challenge. Experiments and analysis are provided that show the value of the dataset.
Rethinking Deep Neural Network Ownership Verification: Embedding Passports to Defeat Ambiguity Attacks
Sep 21, 2019

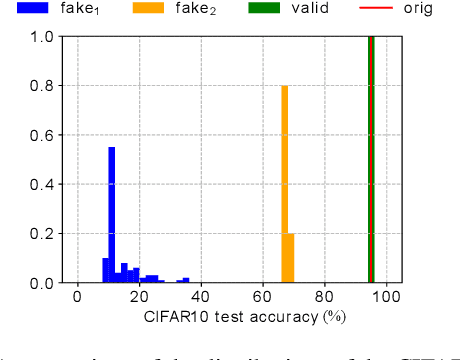
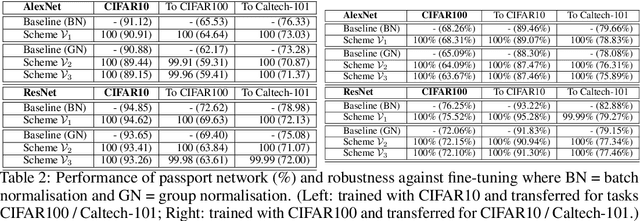
With the rapid development of deep neural networks (DNN), there emerges an urgent need to protect the trained DNN models from being illegally copied, redistributed, or abused without respecting the intellectual properties of legitimate owners. Following recent progresses along this line, we investigate a number of watermark-based DNN ownership verification methods in the face of ambiguity attacks, which aim to cast doubts on ownership verification by forging counterfeit watermarks. It is shown that ambiguity attacks pose serious challenges to existing DNN watermarking methods. As remedies to the above-mentioned loophole, this paper proposes novel passport-based DNN ownership verification schemes which are both robust to network modifications and resilient to ambiguity attacks. The gist of embedding digital passports is to design and train DNN models in a way such that, the DNN model performance of an original task will be significantly deteriorated due to forged passports. In other words genuine passports are not only verified by looking for predefined signatures, but also reasserted by the unyielding DNN model performances. Extensive experimental results justify the effectiveness of the proposed passport-based DNN ownership verification schemes. Code and models are available at https://github.com/kamwoh/DeepIPR
ICDAR 2019 Competition on Large-scale Street View Text with Partial Labeling -- RRC-LSVT
Sep 17, 2019


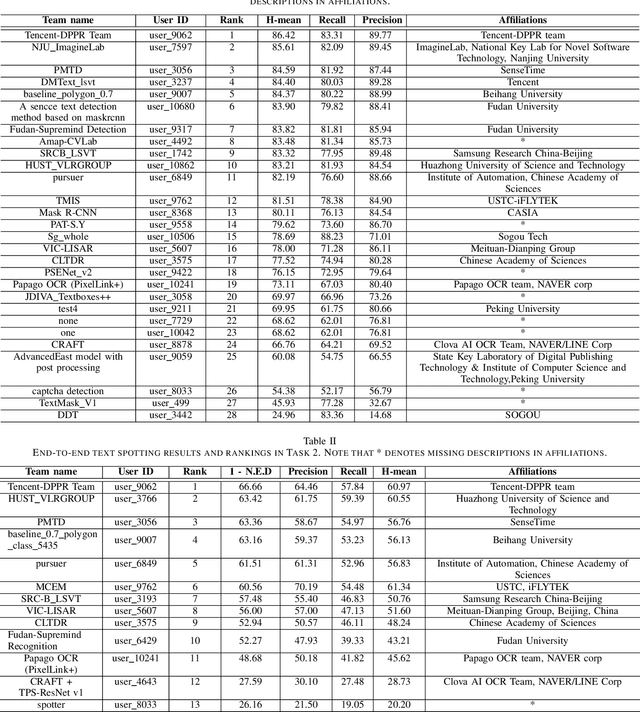
Robust text reading from street view images provides valuable information for various applications. Performance improvement of existing methods in such a challenging scenario heavily relies on the amount of fully annotated training data, which is costly and in-efficient to obtain. To scale up the amount of training data while keeping the labeling procedure cost-effective, this competition introduces a new challenge on Large-scale Street View Text with Partial Labeling (LSVT), providing 50, 000 and 400, 000 images in full and weak annotations, respectively. This competition aims to explore the abilities of state-of-the-art methods to detect and recognize text instances from large-scale street view images, closing the gap between research benchmarks and real applications. During the competition period, a total of 41 teams participated in the two proposed tasks with 132 valid submissions, i.e., text detection and end-to-end text spotting. This paper includes dataset descriptions, task definitions, evaluation protocols and results summaries of the ICDAR 2019-LSVT challenge.
ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT)
Sep 16, 2019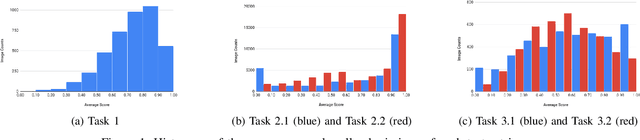



This paper reports the ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT) that consists of three major challenges: i) scene text detection, ii) scene text recognition, and iii) scene text spotting. A total of 78 submissions from 46 unique teams/individuals were received for this competition. The top performing score of each challenge is as follows: i) T1 - 82.65%, ii) T2.1 - 74.3%, iii) T2.2 - 85.32%, iv) T3.1 - 53.86%, and v) T3.2 - 54.91%. Apart from the results, this paper also details the ArT dataset, tasks description, evaluation metrics and participants methods. The dataset, the evaluation kit as well as the results are publicly available at https://rrc.cvc.uab.es/?ch=14
Image Captioning with Sparse Recurrent Neural Network
Aug 28, 2019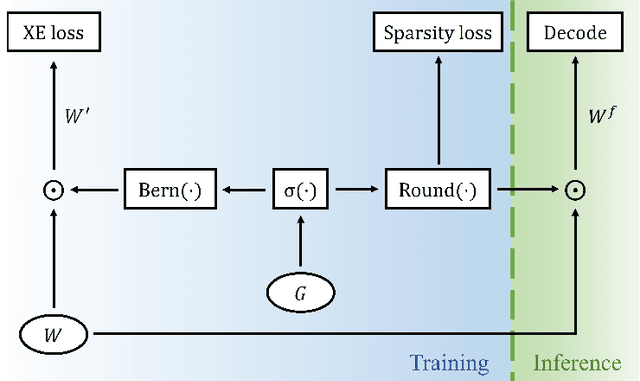
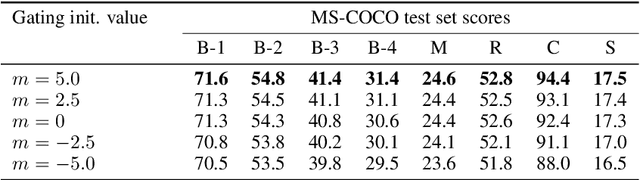
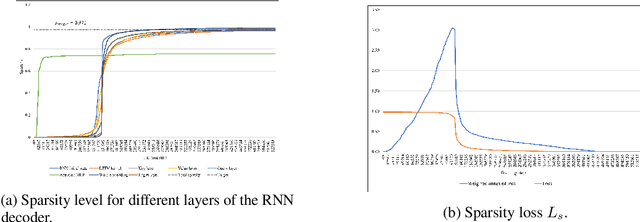
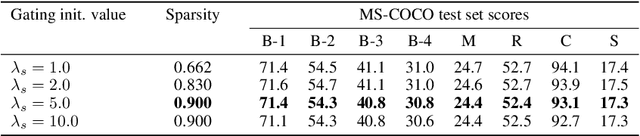
Recurrent Neural Network (RNN) has been deployed as the de facto model to tackle a wide variety of language generation problems and achieved state-of-the-art (SOTA) performance. However despite its impressive results, the large number of parameters in the RNN model makes deployment in mobile and embedded devices infeasible. Driven by this problem, many works have proposed a number of pruning methods to reduce the sizes of the RNN model. In this work, we propose an end-to-end pruning method for image captioning models equipped with visual attention. Our proposed method is able to achieve sparsity levels up to 97.5% without significant performance loss relative to the baseline (around 1% loss at 40x compression of GRU model). Our method is also simple to use and tune, facilitating faster development times for neural network practitioners. We perform extensive experiments on the popular MS-COCO dataset in order to empirically validate the efficacy of our proposed method.
Digital Passport: A Novel Technological Strategy for Intellectual Property Protection of Convolutional Neural Networks
May 10, 2019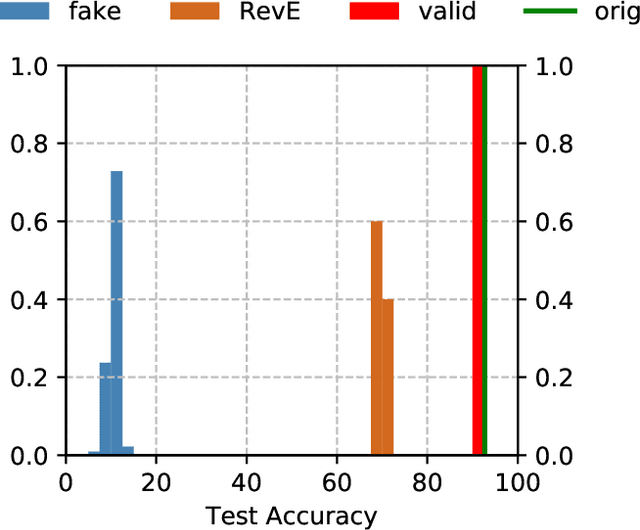

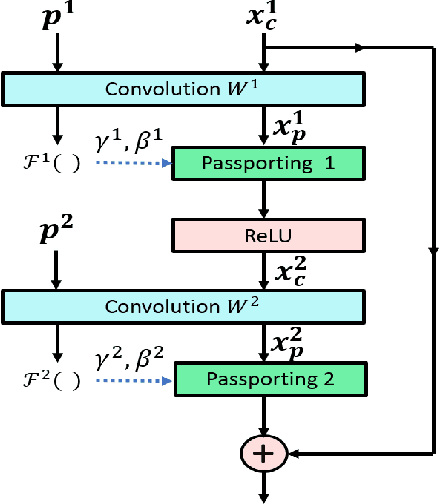
In order to prevent deep neural networks from being infringed by unauthorized parties, we propose a generic solution which embeds a designated digital passport into a network, and subsequently, either paralyzes the network functionalities for unauthorized usages or maintain its functionalities in the presence of a verified passport. Such a desired network behavior is successfully demonstrated in a number of implementation schemes, which provide reliable, preventive and timely protections against tens of thousands of fake-passport deceptions. Extensive experiments also show that the deep neural network performance under unauthorized usages deteriorate significantly (e.g. with 33% to 82% reductions of CIFAR10 classification accuracies), while networks endorsed with valid passports remain intact.