 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Memorize; Mimic The Past: Federated Class Incremental Learning Without Episodic Memory
Jul 17, 2023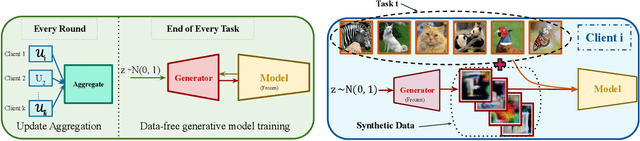
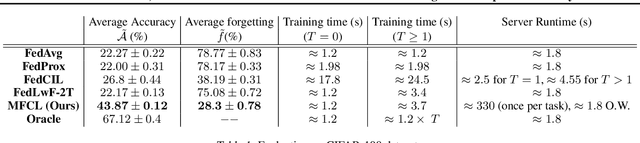

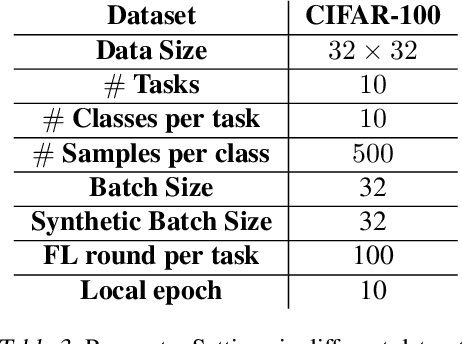
Deep learning models are prone to forgetting information learned in the past when trained on new data. This problem becomes even more pronounced in the context of federated learning (FL), where data is decentralized and subject to independent changes for each user. Continual Learning (CL) studies this so-called \textit{catastrophic forgetting} phenomenon primarily in centralized settings, where the learner has direct access to the complete training dataset. However, applying CL techniques to FL is not straightforward due to privacy concerns and resource limitations. This paper presents a framework for federated class incremental learning that utilizes a generative model to synthesize samples from past distributions instead of storing part of past data. Then, clients can leverage the generative model to mitigate catastrophic forgetting locally. The generative model is trained on the server using data-free methods at the end of each task without requesting data from clients. Therefore, it reduces the risk of data leakage as opposed to training it on the client's private data. We demonstrate significant improvements for the CIFAR-100 dataset compared to existing baselines.
FedMLSecurity: A Benchmark for Attacks and Defenses in Federated Learning and LLMs
Jun 08, 2023



This paper introduces FedMLSecurity, a benchmark that simulates adversarial attacks and corresponding defense mechanisms in Federated Learning (FL). As an integral module of the open-sourced library FedML that facilitates FL algorithm development and performance comparison, FedMLSecurity enhances the security assessment capacity of FedML. FedMLSecurity comprises two principal components: FedMLAttacker, which simulates attacks injected into FL training, and FedMLDefender, which emulates defensive strategies designed to mitigate the impacts of the attacks. FedMLSecurity is open-sourced 1 and is customizable to a wide range of machine learning models (e.g., Logistic Regression, ResNet, GAN, etc.) and federated optimizers (e.g., FedAVG, FedOPT, FedNOVA, etc.). Experimental evaluations in this paper also demonstrate the ease of application of FedMLSecurity to Large Language Models (LLMs), further reinforcing its versatility and practical utility in various scenarios.
FedML-HE: An Efficient Homomorphic-Encryption-Based Privacy-Preserving Federated Learning System
Mar 20, 2023



Federated Learning (FL) enables machine learning model training on distributed edge devices by aggregating local model updates rather than local data. However, privacy concerns arise as the FL server's access to local model updates can potentially reveal sensitive personal information by performing attacks like gradient inversion recovery. To address these concerns, privacy-preserving methods, such as Homomorphic Encryption (HE)-based approaches, have been proposed. Despite HE's post-quantum security advantages, its applications suffer from impractical overheads. In this paper, we present FedML-HE, the first practical system for efficient HE-based secure federated aggregation that provides a user/device-friendly deployment platform. FL-HE utilizes a novel universal overhead optimization scheme, significantly reducing both computation and communication overheads during deployment while providing customizable privacy guarantees. Our optimized system demonstrates considerable overhead reduction, particularly for large models (e.g., ~10x reduction for HE-federated training of ResNet-50 and ~40x reduction for BERT), demonstrating the potential for scalable HE-based FL deployment.
FedML Parrot: A Scalable Federated Learning System via Heterogeneity-aware Scheduling on Sequential and Hierarchical Training
Mar 03, 2023



Federated Learning (FL) enables collaborations among clients for train machine learning models while protecting their data privacy. Existing FL simulation platforms that are designed from the perspectives of traditional distributed training, suffer from laborious code migration between simulation and production, low efficiency, low GPU utility, low scalability with high hardware requirements and difficulty of simulating stateful clients. In this work, we firstly demystify the challenges and bottlenecks of simulating FL, and design a new FL system named as FedML \texttt{Parrot}. It improves the training efficiency, remarkably relaxes the requirements on the hardware, and supports efficient large-scale FL experiments with stateful clients by: (1) sequential training clients on devices; (2) decomposing original aggregation into local and global aggregation on devices and server respectively; (3) scheduling tasks to mitigate straggler problems and enhance computing utility; (4) distributed client state manager to support various FL algorithms. Besides, built upon our generic APIs and communication interfaces, users can seamlessly transform the simulation into the real-world deployment without modifying codes. We evaluate \texttt{Parrot} through extensive experiments for training diverse models on various FL datasets to demonstrate that \texttt{Parrot} can achieve simulating over 1000 clients (stateful or stateless) with flexible GPU devices setting ($4 \sim 32$) and high GPU utility, 1.2 $\sim$ 4 times faster than FedScale, and 10 $\sim$ 100 times memory saving than FedML. And we verify that \texttt{Parrot} works well with homogeneous and heterogeneous devices in three different clusters. Two FL algorithms with stateful clients and four algorithms with stateless clients are simulated to verify the wide adaptability of \texttt{Parrot} to different algorithms.
Proof-of-Contribution-Based Design for Collaborative Machine Learning on Blockchain
Feb 27, 2023



We consider a project (model) owner that would like to train a model by utilizing the local private data and compute power of interested data owners, i.e., trainers. Our goal is to design a data marketplace for such decentralized collaborative/federated learning applications that simultaneously provides i) proof-of-contribution based reward allocation so that the trainers are compensated based on their contributions to the trained model; ii) privacy-preserving decentralized model training by avoiding any data movement from data owners; iii) robustness against malicious parties (e.g., trainers aiming to poison the model); iv) verifiability in the sense that the integrity, i.e., correctness, of all computations in the data market protocol including contribution assessment and outlier detection are verifiable through zero-knowledge proofs; and v) efficient and universal design. We propose a blockchain-based marketplace design to achieve all five objectives mentioned above. In our design, we utilize a distributed storage infrastructure and an aggregator aside from the project owner and the trainers. The aggregator is a processing node that performs certain computations, including assessing trainer contributions, removing outliers, and updating hyper-parameters. We execute the proposed data market through a blockchain smart contract. The deployed smart contract ensures that the project owner cannot evade payment, and honest trainers are rewarded based on their contributions at the end of training. Finally, we implement the building blocks of the proposed data market and demonstrate their applicability in practical scenarios through extensive experiments.
Federated Analytics: A survey
Feb 02, 2023



Federated analytics (FA) is a privacy-preserving framework for computing data analytics over multiple remote parties (e.g., mobile devices) or silo-ed institutional entities (e.g., hospitals, banks) without sharing the data among parties. Motivated by the practical use cases of federated analytics, we follow a systematic discussion on federated analytics in this article. In particular, we discuss the unique characteristics of federated analytics and how it differs from federated learning. We also explore a wide range of FA queries and discuss various existing solutions and potential use case applications for different FA queries.
* To appear in APSIPA Transactions on Signal and Information Processing, Volume 12, Issue 1
SMILE: Scaling Mixture-of-Experts with Efficient Bi-level Routing
Dec 10, 2022



The mixture of Expert (MoE) parallelism is a recent advancement that scales up the model size with constant computational cost. MoE selects different sets of parameters (i.e., experts) for each incoming token, resulting in a sparsely-activated model. Despite several successful applications of MoE, its training efficiency degrades significantly as the number of experts increases. The routing stage in MoE relies on the efficiency of the All2All communication collective, which suffers from network congestion and has poor scalability. To mitigate these issues, we introduce SMILE, which exploits heterogeneous network bandwidth and splits a single-step routing into bi-level routing. Our experimental results show that the proposed method obtains a 2.5x speedup over Switch Transformer in terms of pretraining throughput on the Colossal Clean Crawled Corpus without losing any convergence speed.
FLamby: Datasets and Benchmarks for Cross-Silo Federated Learning in Realistic Healthcare Settings
Oct 10, 2022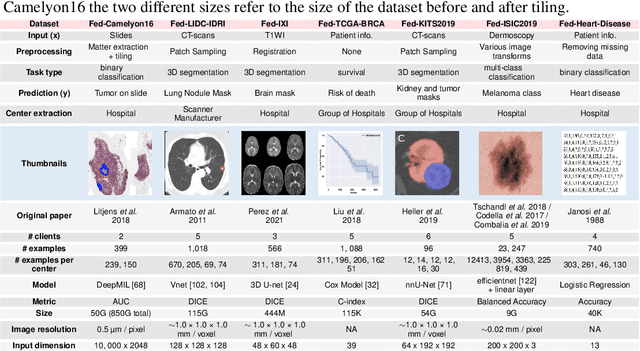
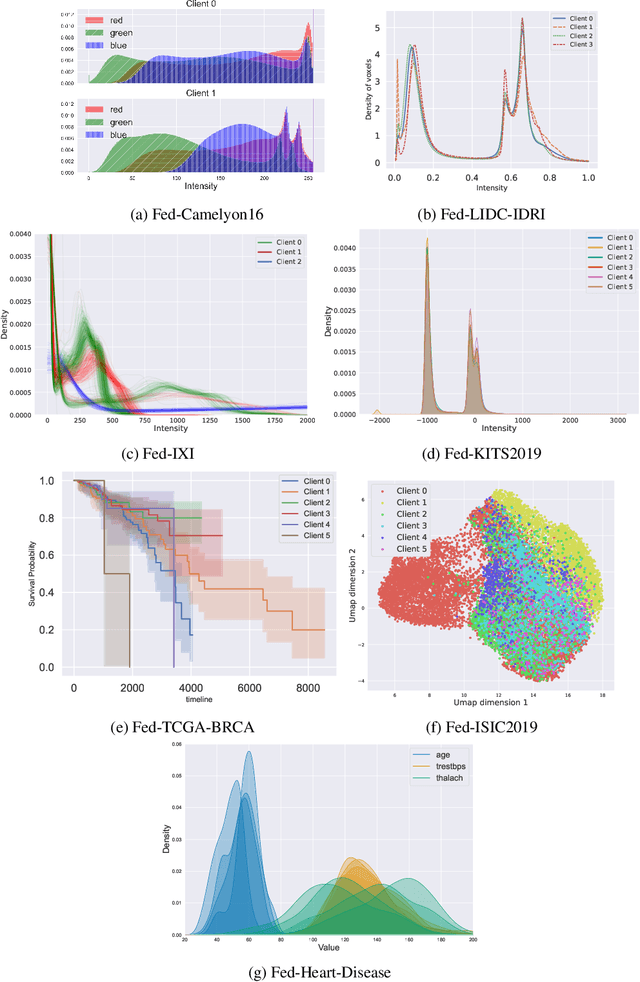
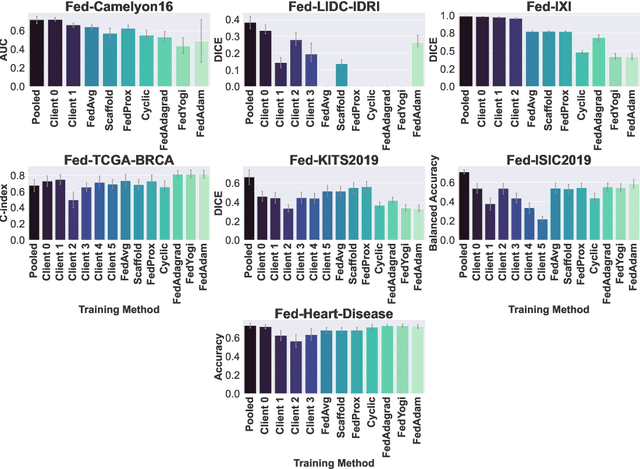

Federated Learning (FL) is a novel approach enabling several clients holding sensitive data to collaboratively train machine learning models, without centralizing data. The cross-silo FL setting corresponds to the case of few ($2$--$50$) reliable clients, each holding medium to large datasets, and is typically found in applications such as healthcare, finance, or industry. While previous works have proposed representative datasets for cross-device FL, few realistic healthcare cross-silo FL datasets exist, thereby slowing algorithmic research in this critical application. In this work, we propose a novel cross-silo dataset suite focused on healthcare, FLamby (Federated Learning AMple Benchmark of Your cross-silo strategies), to bridge the gap between theory and practice of cross-silo FL. FLamby encompasses 7 healthcare datasets with natural splits, covering multiple tasks, modalities, and data volumes, each accompanied with baseline training code. As an illustration, we additionally benchmark standard FL algorithms on all datasets. Our flexible and modular suite allows researchers to easily download datasets, reproduce results and re-use the different components for their research. FLamby is available at~\url{www.github.com/owkin/flamby}.
Partial Model Averaging in Federated Learning: Performance Guarantees and Benefits
Jan 11, 2022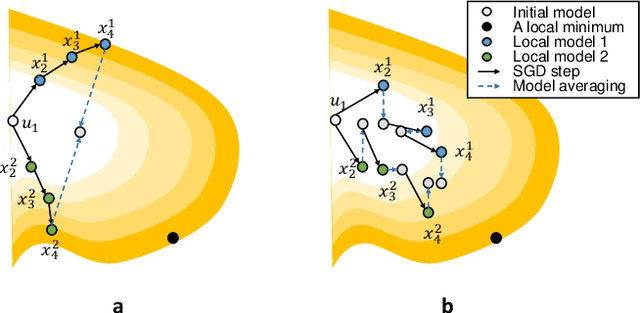
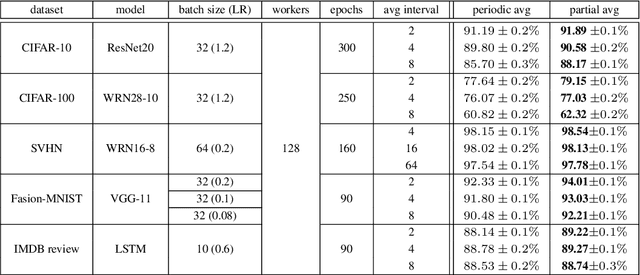
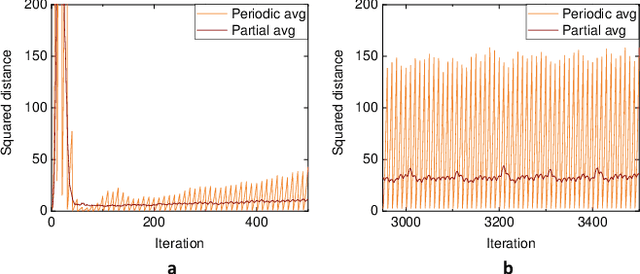

Local Stochastic Gradient Descent (SGD) with periodic model averaging (FedAvg) is a foundational algorithm in Federated Learning. The algorithm independently runs SGD on multiple workers and periodically averages the model across all the workers. When local SGD runs with many workers, however, the periodic averaging causes a significant model discrepancy across the workers making the global loss converge slowly. While recent advanced optimization methods tackle the issue focused on non-IID settings, there still exists the model discrepancy issue due to the underlying periodic model averaging. We propose a partial model averaging framework that mitigates the model discrepancy issue in Federated Learning. The partial averaging encourages the local models to stay close to each other on parameter space, and it enables to more effectively minimize the global loss. Given a fixed number of iterations and a large number of workers (128), the partial averaging achieves up to 2.2% higher validation accuracy than the periodic full averaging.
SPIDER: Searching Personalized Neural Architecture for Federated Learning
Dec 27, 2021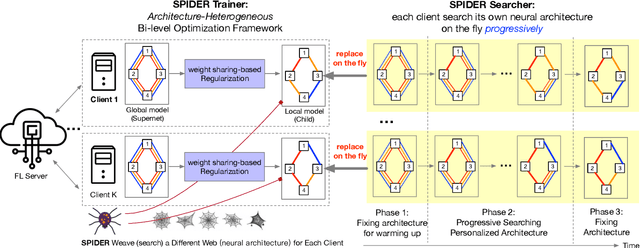
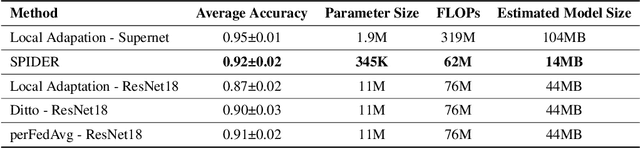

Federated learning (FL) is an efficient learning framework that assists distributed machine learning when data cannot be shared with a centralized server due to privacy and regulatory restrictions. Recent advancements in FL use predefined architecture-based learning for all the clients. However, given that clients' data are invisible to the server and data distributions are non-identical across clients, a predefined architecture discovered in a centralized setting may not be an optimal solution for all the clients in FL. Motivated by this challenge, in this work, we introduce SPIDER, an algorithmic framework that aims to Search Personalized neural architecture for federated learning. SPIDER is designed based on two unique features: (1) alternately optimizing one architecture-homogeneous global model (Supernet) in a generic FL manner and one architecture-heterogeneous local model that is connected to the global model by weight sharing-based regularization (2) achieving architecture-heterogeneous local model by a novel neural architecture search (NAS) method that can select optimal subnet progressively using operation-level perturbation on the accuracy value as the criterion. Experimental results demonstrate that SPIDER outperforms other state-of-the-art personalization methods, and the searched personalized architectures are more inference efficient.