 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoreSpeech: Knowledge Distillation based Conditional Diffusion Model for Noise-robust Expressive TTS
Nov 04, 2022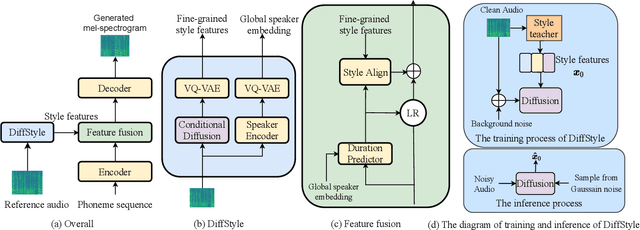
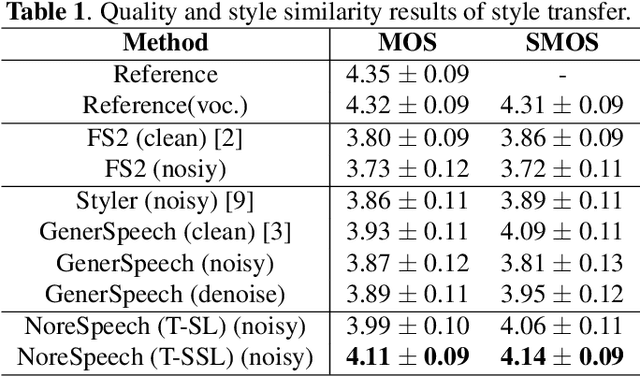

Expressive text-to-speech (TTS) can synthesize a new speaking style by imiating prosody and timbre from a reference audio, which faces the following challenges: (1) The highly dynamic prosody information in the reference audio is difficult to extract, especially, when the reference audio contains background noise. (2) The TTS systems should have good generalization for unseen speaking styles. In this paper, we present a \textbf{no}ise-\textbf{r}obust \textbf{e}xpressive TTS model (NoreSpeech), which can robustly transfer speaking style in a noisy reference utterance to synthesized speech. Specifically, our NoreSpeech includes several components: (1) a novel DiffStyle module, which leverages powerful probabilistic denoising diffusion models to learn noise-agnostic speaking style features from a teacher model by knowledge distillation; (2) a VQ-VAE block, which maps the style features into a controllable quantized latent space for improving the generalization of style transfer; and (3) a straight-forward but effective parameter-free text-style alignment module, which enables NoreSpeech to transfer style to a textual input from a length-mismatched reference utterance. Experiments demonstrate that NoreSpeech is more effective than previous expressive TTS models in noise environments. Audio samples and code are available at: \href{http://dongchaoyang.top/NoreSpeech\_demo/}{http://dongchaoyang.top/NoreSpeech\_demo/}
Bayes risk CTC: Controllable CTC alignment in Sequence-to-Sequence tasks
Oct 14, 2022
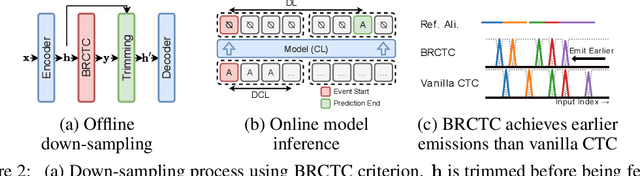
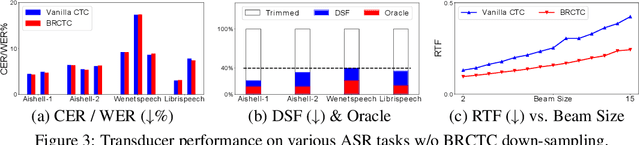
Sequence-to-Sequence (seq2seq) tasks transcribe the input sequence to a target sequence. The Connectionist Temporal Classification (CTC) criterion is widely used in multiple seq2seq tasks. Besides predicting the target sequence, a side product of CTC is to predict the alignment, which is the most probable input-long sequence that specifies a hard aligning relationship between the input and target units. As there are multiple potential aligning sequences (called paths) that are equally considered in CTC formulation, the choice of which path will be most probable and become the predicted alignment is always uncertain. In addition, it is usually observed that the alignment predicted by vanilla CTC will drift compared with its reference and rarely provides practical functionalities. Thus, the motivation of this work is to make the CTC alignment prediction controllable and thus equip CTC with extra functionalities. The Bayes risk CTC (BRCTC) criterion is then proposed in this work, in which a customizable Bayes risk function is adopted to enforce the desired characteristics of the predicted alignment. With the risk function, the BRCTC is a general framework to adopt some customizable preference over the paths in order to concentrate the posterior into a particular subset of the paths. In applications, we explore one particular preference which yields models with the down-sampling ability and reduced inference costs. By using BRCTC with another preference for early emissions, we obtain an improved performance-latency trade-off for online models. Experimentally, the proposed BRCTC reduces the inference cost of offline models by up to 47% without performance degradation and cuts down the overall latency of online systems to an unseen level.
The DKU-Tencent System for the VoxCeleb Speaker Recognition Challenge 2022
Oct 11, 2022
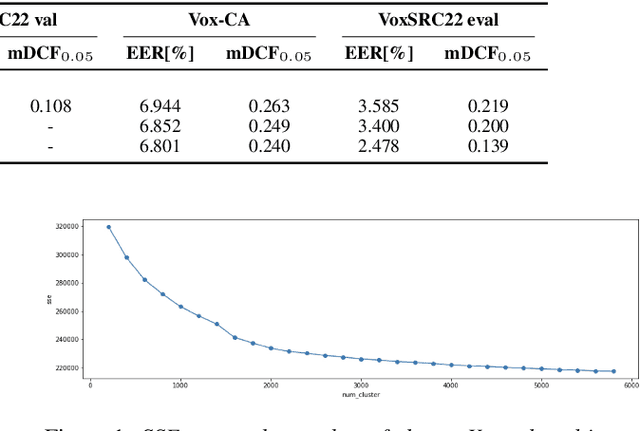
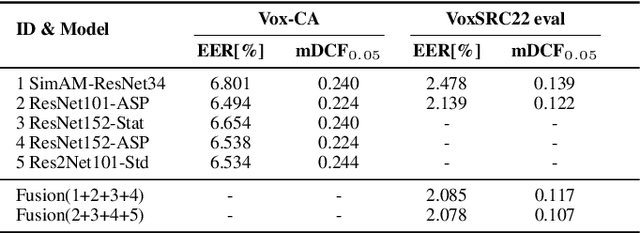
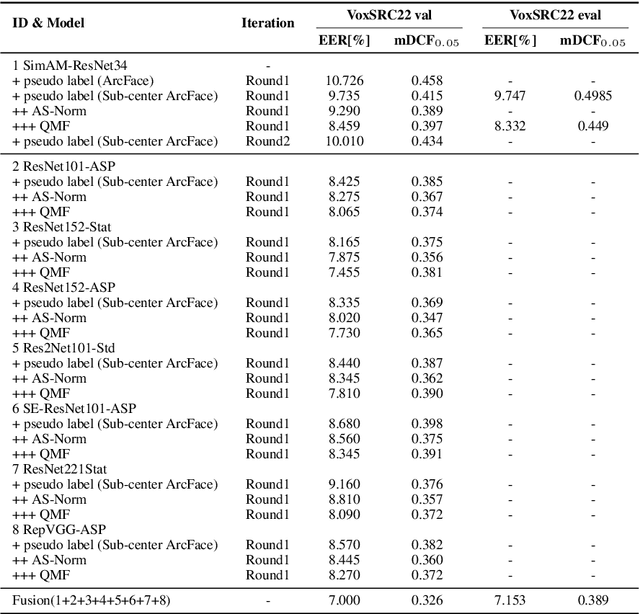
This paper is the system description of the DKU-Tencent System for the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC22). In this challenge, we focus on track1 and track3. For track1, multiple backbone networks are adopted to extract frame-level features. Since track1 focus on the cross-age scenarios, we adopt the cross-age trials and perform QMF to calibrate score. The magnitude-based quality measures achieve a large improvement. For track3, the semi-supervised domain adaptation task, the pseudo label method is adopted to make domain adaptation. Considering the noise labels in clustering, the ArcFace is replaced by Sub-center ArcFace. The final submission achieves 0.107 mDCF in task1 and 7.135% EER in task3.
Diffsound: Discrete Diffusion Model for Text-to-sound Generation
Jul 20, 2022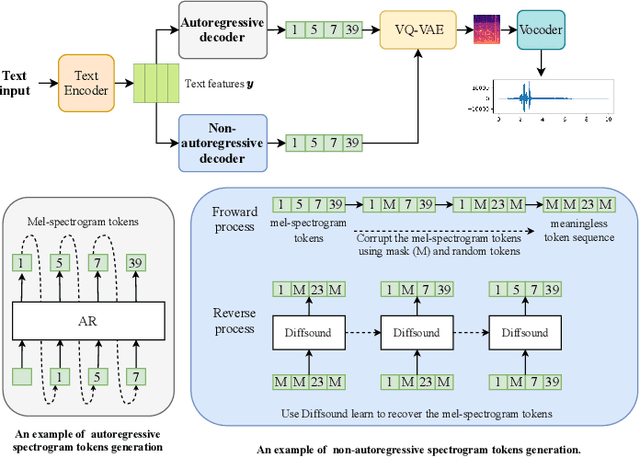
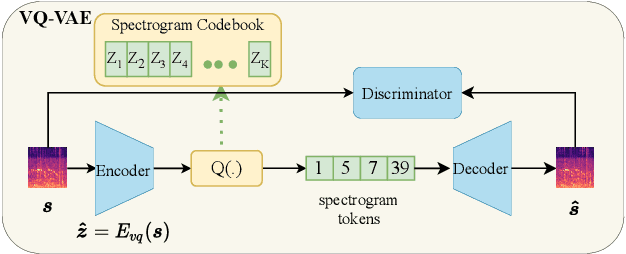
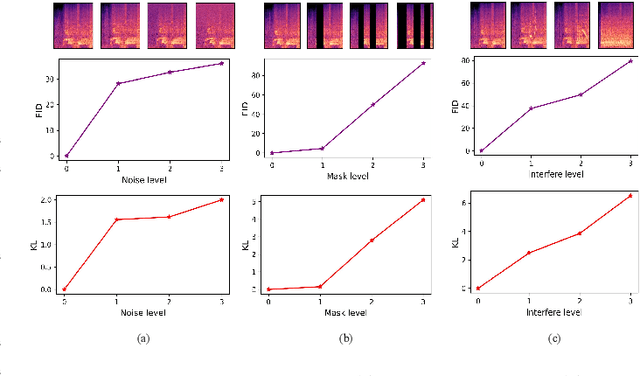

Generating sound effects that humans want is an important topic. However, there are few studies in this area for sound generation. In this study, we investigate generating sound conditioned on a text prompt and propose a novel text-to-sound generation framework that consists of a text encoder, a Vector Quantized Variational Autoencoder (VQ-VAE), a decoder, and a vocoder. The framework first uses the decoder to transfer the text features extracted from the text encoder to a mel-spectrogram with the help of VQ-VAE, and then the vocoder is used to transform the generated mel-spectrogram into a waveform. We found that the decoder significantly influences the generation performance. Thus, we focus on designing a good decoder in this study. We begin with the traditional autoregressive decoder, which has been proved as a state-of-the-art method in previous sound generation works. However, the AR decoder always predicts the mel-spectrogram tokens one by one in order, which introduces the unidirectional bias and accumulation of errors problems. Moreover, with the AR decoder, the sound generation time increases linearly with the sound duration. To overcome the shortcomings introduced by AR decoders, we propose a non-autoregressive decoder based on the discrete diffusion model, named Diffsound. Specifically, the Diffsound predicts all of the mel-spectrogram tokens in one step and then refines the predicted tokens in the next step, so the best-predicted results can be obtained after several steps. Our experiments show that our proposed Diffsound not only produces better text-to-sound generation results when compared with the AR decoder but also has a faster generation speed, e.g., MOS: 3.56 \textit{v.s} 2.786, and the generation speed is five times faster than the AR decoder.
Cross-Age Speaker Verification: Learning Age-Invariant Speaker Embeddings
Jul 13, 2022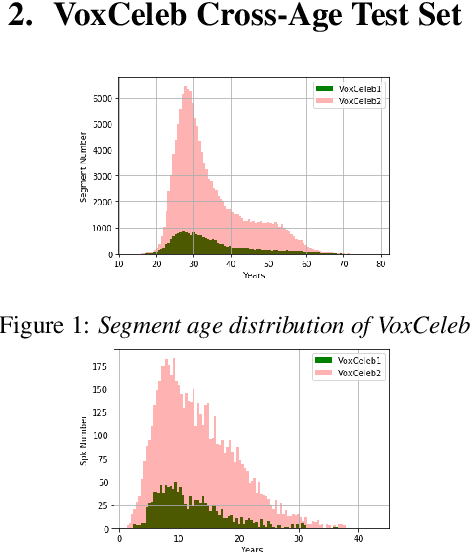
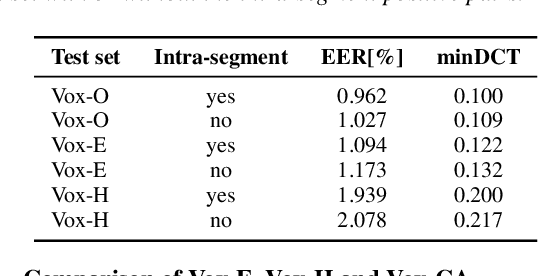
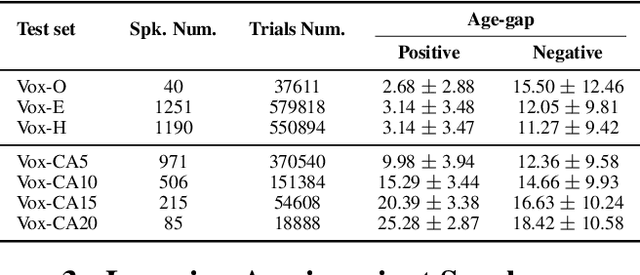
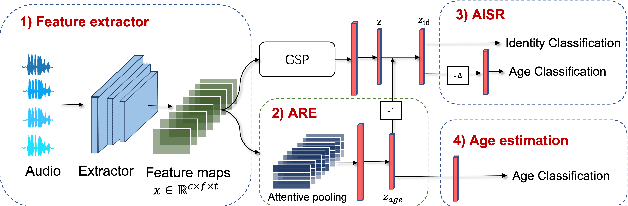
Automatic speaker verification has achieved remarkable progress in recent years. However, there is little research on cross-age speaker verification (CASV) due to insufficient relevant data. In this paper, we mine cross-age test sets based on the VoxCeleb dataset and propose our age-invariant speaker representation(AISR) learning method. Since the VoxCeleb is collected from the YouTube platform, the dataset consists of cross-age data inherently. However, the meta-data does not contain the speaker age label. Therefore, we adopt the face age estimation method to predict the speaker age value from the associated visual data, then label the audio recording with the estimated age. We construct multiple Cross-Age test sets on VoxCeleb (Vox-CA), which deliberately select the positive trials with large age-gap. Also, the effect of nationality and gender is considered in selecting negative pairs to align with Vox-H cases. The baseline system performance drops from 1.939\% EER on the Vox-H test set to 10.419\% on the Vox-CA20 test set, which indicates how difficult the cross-age scenario is. Consequently, we propose an age-decoupling adversarial learning (ADAL) method to alleviate the negative effect of the age gap and reduce intra-class variance. Our method outperforms the baseline system by over 10\% related EER reduction on the Vox-CA20 test set. The source code and trial resources are available on https://github.com/qinxiaoyi/Cross-Age_Speaker_Verification
LAE: Language-Aware Encoder for Monolingual and Multilingual ASR
Jun 05, 2022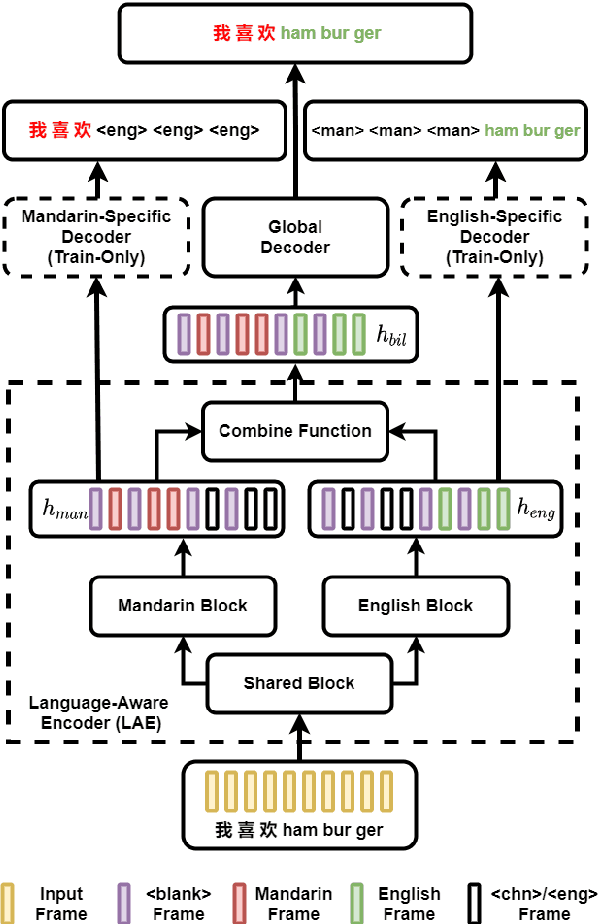
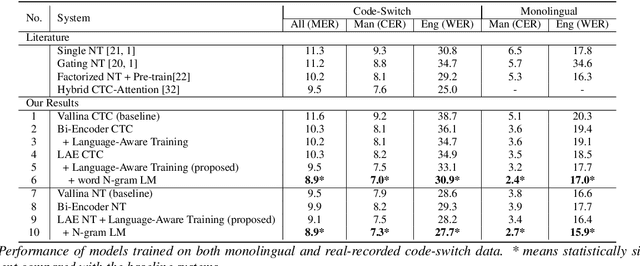
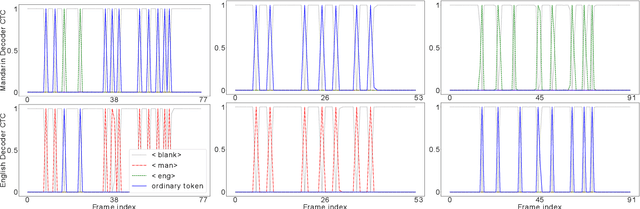
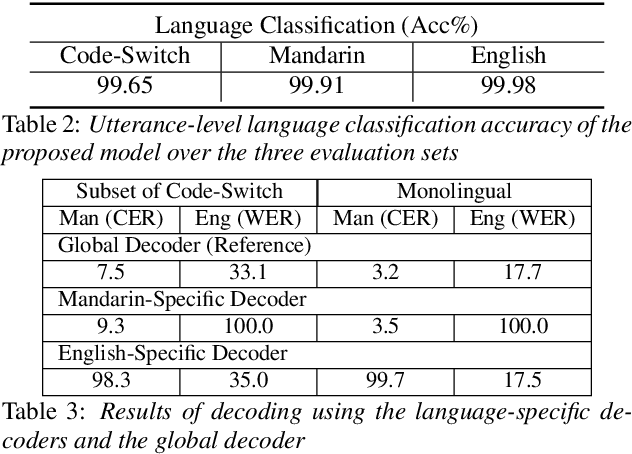
Despite the rapid progress in automatic speech recognition (ASR) research, recognizing multilingual speech using a unified ASR system remains highly challenging. Previous works on multilingual speech recognition mainly focus on two directions: recognizing multiple monolingual speech or recognizing code-switched speech that uses different languages interchangeably within a single utterance. However, a pragmatic multilingual recognizer is expected to be compatible with both directions. In this work, a novel language-aware encoder (LAE) architecture is proposed to handle both situations by disentangling language-specific information and generating frame-level language-aware representations during encoding. In the LAE, the primary encoding is implemented by the shared block while the language-specific blocks are used to extract specific representations for each language. To learn language-specific information discriminatively, a language-aware training method is proposed to optimize the language-specific blocks in LAE. Experiments conducted on Mandarin-English code-switched speech suggest that the proposed LAE is capable of discriminating different languages in frame-level and shows superior performance on both monolingual and multilingual ASR tasks. With either a real-recorded or simulated code-switched dataset, the proposed LAE achieves statistically significant improvements on both CTC and neural transducer systems. Code is released
Improving Target Sound Extraction with Timestamp Information
Apr 02, 2022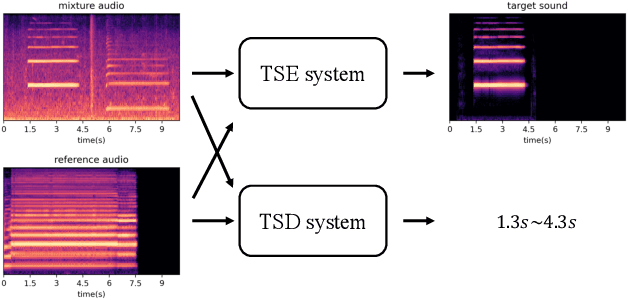
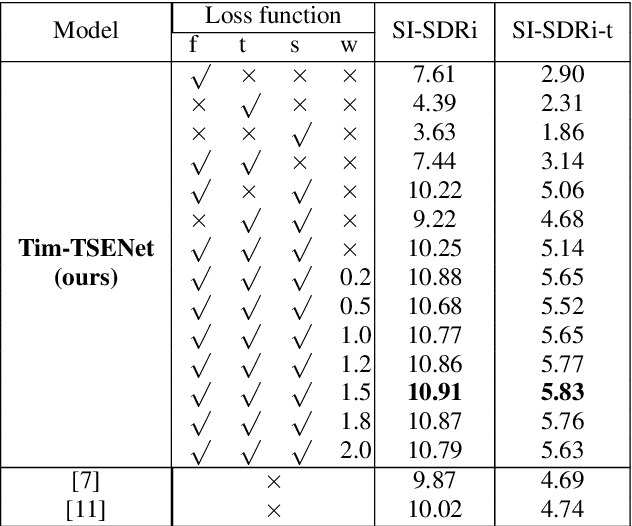
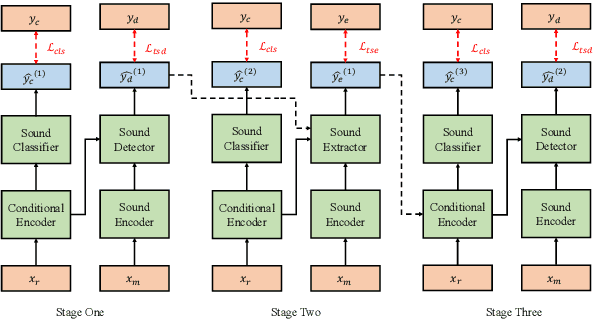
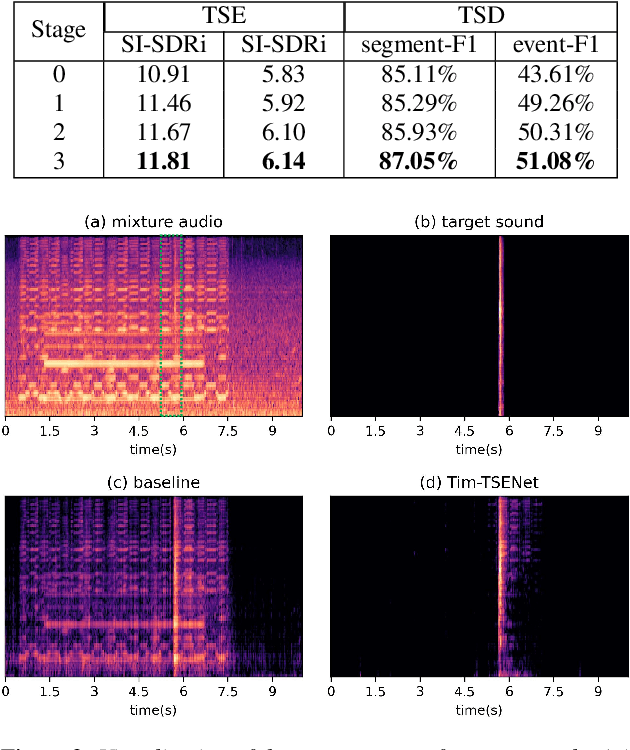
Target sound extraction (TSE) aims to extract the sound part of a target sound event class from a mixture audio with multiple sound events. The previous works mainly focus on the problems of weakly-labelled data, jointly learning and new classes, however, no one cares about the onset and offset times of the target sound event, which has been emphasized in the auditory scene analysis. In this paper, we study to utilize such timestamp information to help extract the target sound via a target sound detection network and a target-weighted time-frequency loss function. More specifically, we use the detection result of a target sound detection (TSD) network as the additional information to guide the learning of target sound extraction network. We also find that the result of TSE can further improve the performance of the TSD network, so that a mutual learning framework of the target sound detection and extraction is proposed. In addition, a target-weighted time-frequency loss function is designed to pay more attention to the temporal regions of the target sound during training. Experimental results on the synthesized data generated from the Freesound Datasets show that our proposed method can significantly improve the performance of TSE.
Integrate Lattice-Free MMI into End-to-End Speech Recognition
Apr 02, 2022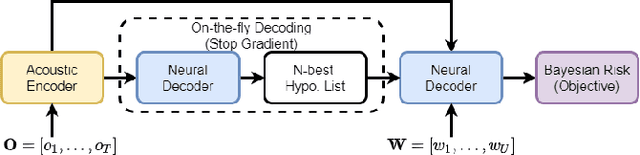
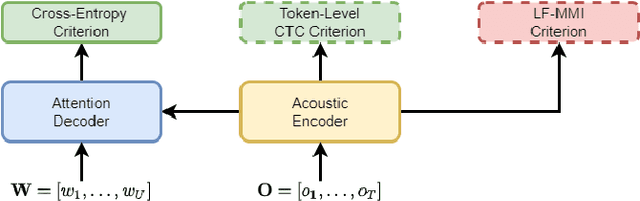
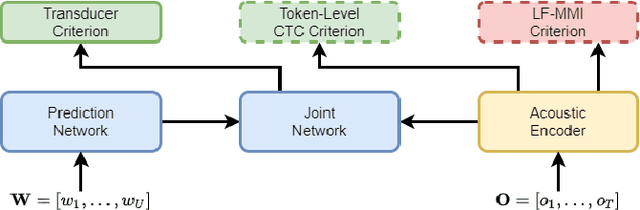
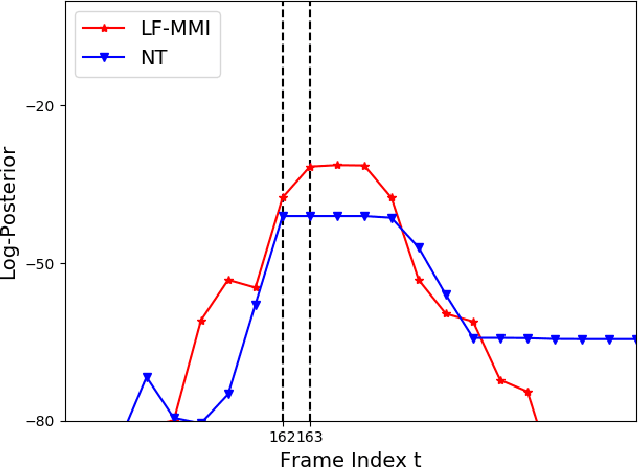
In automatic speech recognition (ASR) research, discriminative criteria have achieved superior performance in DNN-HMM systems. Given this success, the adoption of discriminative criteria is promising to boost the performance of end-to-end (E2E) ASR systems. With this motivation, previous works have introduced the minimum Bayesian risk (MBR, one of the discriminative criteria) into E2E ASR systems. However, the effectiveness and efficiency of the MBR-based methods are compromised: the MBR criterion is only used in system training, which creates a mismatch between training and decoding; the on-the-fly decoding process in MBR-based methods results in the need for pre-trained models and slow training speeds. To this end, novel algorithms are proposed in this work to integrate another widely used discriminative criterion, lattice-free maximum mutual information (LF-MMI), into E2E ASR systems not only in the training stage but also in the decoding process. The proposed LF-MMI training and decoding methods show their effectiveness on two widely used E2E frameworks: Attention-Based Encoder-Decoders (AEDs) and Neural Transducers (NTs). Compared with MBR-based methods, the proposed LF-MMI method: maintains the consistency between training and decoding; eschews the on-the-fly decoding process; trains from randomly initialized models with superior training efficiency. Experiments suggest that the LF-MMI method outperforms its MBR counterparts and consistently leads to statistically significant performance improvements on various frameworks and datasets from 30 hours to 14.3k hours. The proposed method achieves state-of-the-art (SOTA) results on Aishell-1 (CER 4.10%) and Aishell-2 (CER 5.02%) datasets. Code is released.
The CUHK-TENCENT speaker diarization system for the ICASSP 2022 multi-channel multi-party meeting transcription challenge
Feb 04, 2022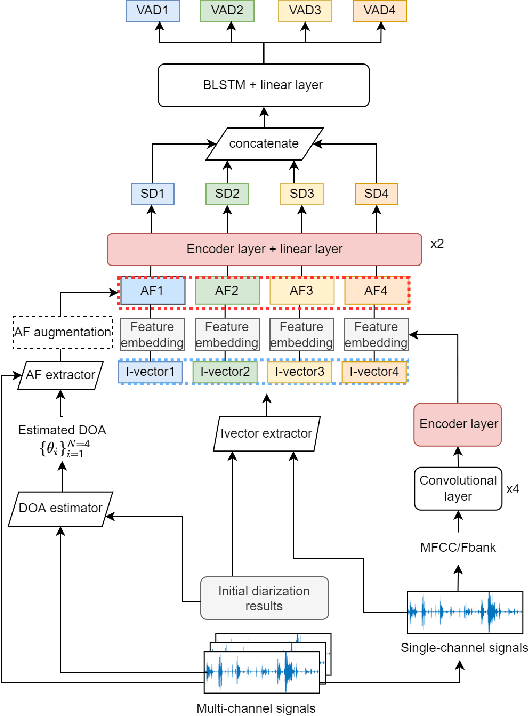
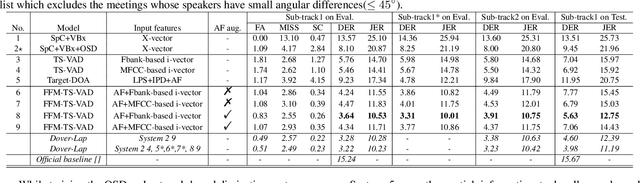
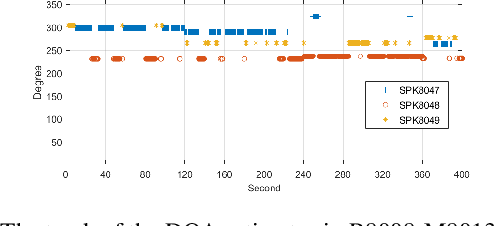
This paper describes our speaker diarization system submitted to the Multi-channel Multi-party Meeting Transcription (M2MeT) challenge, where Mandarin meeting data were recorded in multi-channel format for diarization and automatic speech recognition (ASR) tasks. In these meeting scenarios, the uncertainty of the speaker number and the high ratio of overlapped speech present great challenges for diarization. Based on the assumption that there is valuable complementary information between acoustic features, spatial-related and speaker-related features, we propose a multi-level feature fusion mechanism based target-speaker voice activity detection (FFM-TS-VAD) system to improve the performance of the conventional TS-VAD system. Furthermore, we propose a data augmentation method during training to improve the system robustness when the angular difference between two speakers is relatively small. We provide comparisons for different sub-systems we used in M2MeT challenge. Our submission is a fusion of several sub-systems and ranks second in the diarization task.
Improving Mandarin End-to-End Speech Recognition with Word N-gram Language Model
Jan 06, 2022
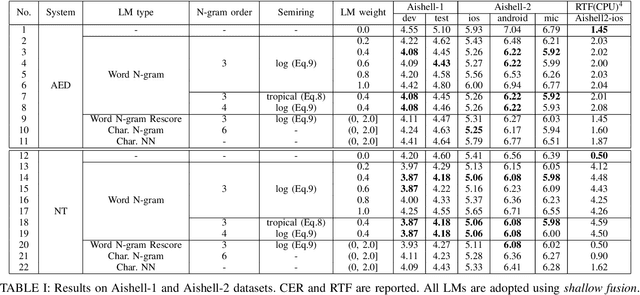
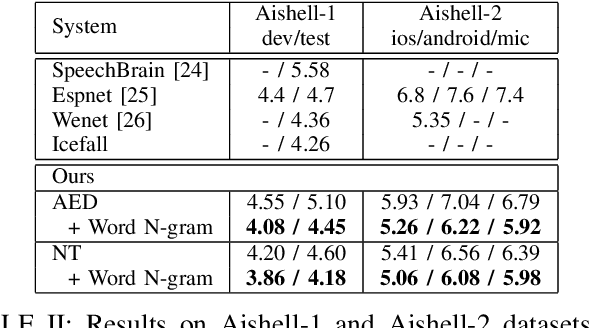
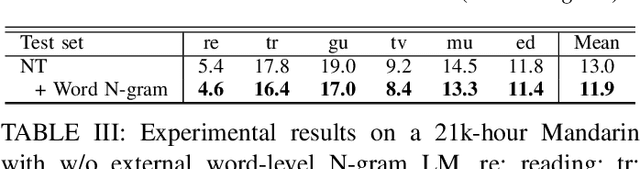
Despite the rapid progress of end-to-end (E2E) automatic speech recognition (ASR), it has been shown that incorporating external language models (LMs) into the decoding can further improve the recognition performance of E2E ASR systems. To align with the modeling units adopted in E2E ASR systems, subword-level (e.g., characters, BPE) LMs are usually used to cooperate with current E2E ASR systems. However, the use of subword-level LMs will ignore the word-level information, which may limit the strength of the external LMs in E2E ASR. Although several methods have been proposed to incorporate word-level external LMs in E2E ASR, these methods are mainly designed for languages with clear word boundaries such as English and cannot be directly applied to languages like Mandarin, in which each character sequence can have multiple corresponding word sequences. To this end, we propose a novel decoding algorithm where a word-level lattice is constructed on-the-fly to consider all possible word sequences for each partial hypothesis. Then, the LM score of the hypothesis is obtained by intersecting the generated lattice with an external word N-gram LM. The proposed method is examined on both Attention-based Encoder-Decoder (AED) and Neural Transducer (NT) frameworks. Experiments suggest that our method consistently outperforms subword-level LMs, including N-gram LM and neural network LM. We achieve state-of-the-art results on both Aishell-1 (CER 4.18%) and Aishell-2 (CER 5.06%) datasets and reduce CER by 14.8% relatively on a 21K-hour Mandarin dataset.