 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeePhys Pro: Diagnosing Modality Transfer and Blind-Training Effects in Multimodal RLVR for Physics Reasoning
May 10, 2026We introduce SeePhys Pro, a fine-grained modality transfer benchmark that studies whether models preserve the same reasoning capability when critical information is progressively transferred from text to image. Unlike standard vision-essential benchmarks that evaluate a single input form, SeePhys Pro features four semantically aligned variants for each problem with progressively increasing visual elements. Our evaluation shows that current frontier models are far from representation-invariant reasoners: performance degrades on average as information moves from language to diagrams, with visual variable grounding as the most critical bottleneck. Motivated by this inference-time fragility, we further develop large training corpora for multimodal RLVR and use blind training as a diagnostic control, finding that RL with all training images masked can still improve performance on unmasked validation sets. To analyze this effect, text-deletion, image-mask-rate, and format-saturation controls suggest that such gains can arise from residual textual and distributional cues rather than valid visual evidence. Our results highlight the need to evaluate multimodal reasoning not only by final-answer accuracy, but also by robustness under modality transfer and by diagnostics that test whether improvements rely on task-critical visual evidence.
SLIM: Subtrajectory-Level Elimination for More Effective Reasoning
Aug 27, 2025



In recent months, substantial progress has been made in complex reasoning of Large Language Models, particularly through the application of test-time scaling. Notable examples include o1/o3/o4 series and DeepSeek-R1. When responding to a query, these models generate an extended reasoning trajectory, during which the model explores, reflects, backtracks, and self-verifies before arriving at a conclusion. However, fine-tuning models with such reasoning trajectories may not always be optimal. Our findings indicate that not all components within these reasoning trajectories contribute positively to the reasoning process; in fact, some components may affect the overall performance negatively. In this study, we divide a reasoning trajectory into individual subtrajectories and develop a "5+2" framework to: (1) systematically identify suboptimal subtrajectories within the reasoning trajectory based on five human-established criteria; (2) assess the independence of the suboptimal subtrajectories identified in (1) from the subsequent content, ensuring that their elimination does not compromise overall flow and coherence of the reasoning process. Additionally, a sampling algorithm, built upon the "5+2" framework, is employed to select data whose reasoning process is free from suboptimal subtrajectories to the highest degree. Experimental results demonstrate that our method can reduce the number of suboptimal subtrajectories by 25.9\% during the inference. Furthermore, our method achieves an average accuracy of 58.92\% on highly challenging math benchmarks with only two thirds of training data, surpassing the average accuracy of 58.06\% achieved with the entire data, and outperforming open-source datasets, when fine-tuning Qwen2.5-Math-7B. Finally, We validated our method under resource constraints and observed improved performance across various inference token limits.
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
Advancing COVID-19 Diagnosis with Privacy-Preserving Collaboration in Artificial Intelligence
Nov 18, 2021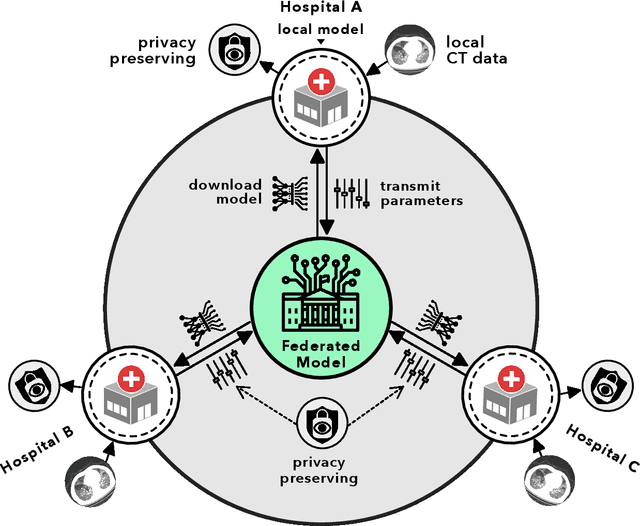
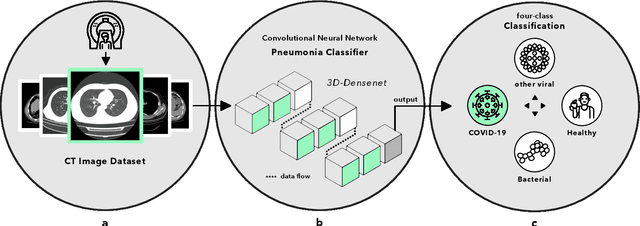
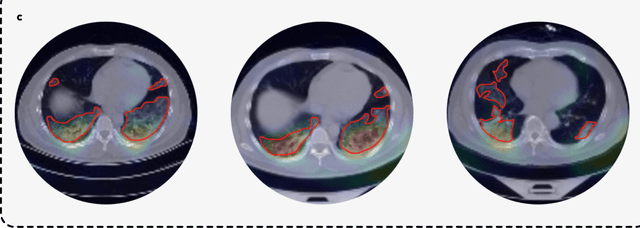
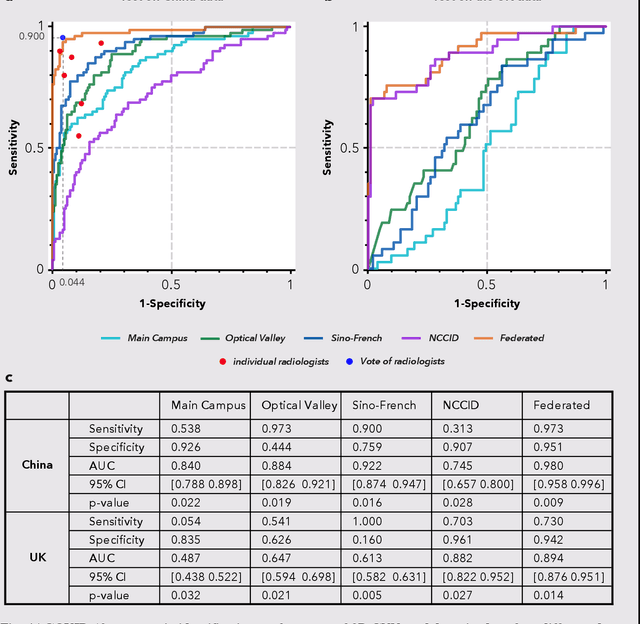
Artificial intelligence (AI) provides a promising substitution for streamlining COVID-19 diagnoses. However, concerns surrounding security and trustworthiness impede the collection of large-scale representative medical data, posing a considerable challenge for training a well-generalised model in clinical practices. To address this, we launch the Unified CT-COVID AI Diagnostic Initiative (UCADI), where the AI model can be distributedly trained and independently executed at each host institution under a federated learning framework (FL) without data sharing. Here we show that our FL model outperformed all the local models by a large yield (test sensitivity /specificity in China: 0.973/0.951, in the UK: 0.730/0.942), achieving comparable performance with a panel of professional radiologists. We further evaluated the model on the hold-out (collected from another two hospitals leaving out the FL) and heterogeneous (acquired with contrast materials) data, provided visual explanations for decisions made by the model, and analysed the trade-offs between the model performance and the communication costs in the federated training process. Our study is based on 9,573 chest computed tomography scans (CTs) from 3,336 patients collected from 23 hospitals located in China and the UK. Collectively, our work advanced the prospects of utilising federated learning for privacy-preserving AI in digital health.
Learning Directional Feature Maps for Cardiac MRI Segmentation
Jul 22, 2020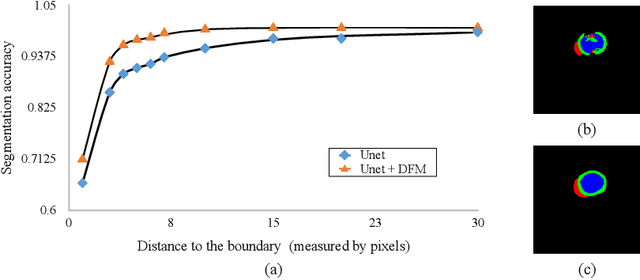
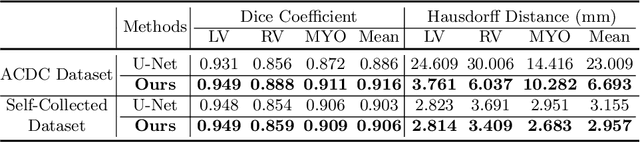
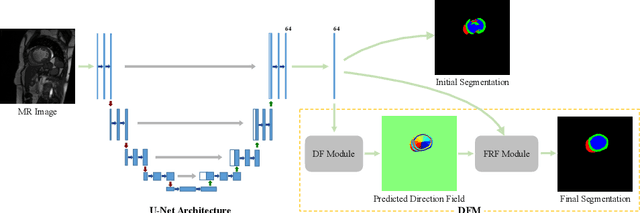
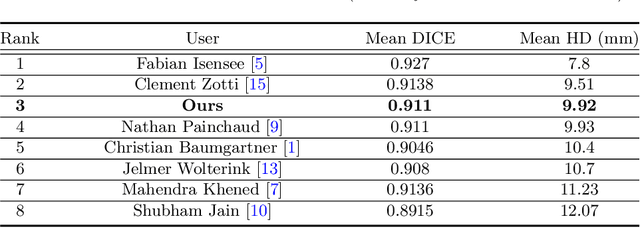
Cardiac MRI segmentation plays a crucial role in clinical diagnosis for evaluating personalized cardiac performance parameters. Due to the indistinct boundaries and heterogeneous intensity distributions in the cardiac MRI, most existing methods still suffer from two aspects of challenges: inter-class indistinction and intra-class inconsistency. To tackle these two problems, we propose a novel method to exploit the directional feature maps, which can simultaneously strengthen the differences between classes and the similarities within classes. Specifically, we perform cardiac segmentation and learn a direction field pointing away from the nearest cardiac tissue boundary to each pixel via a direction field (DF) module. Based on the learned direction field, we then propose a feature rectification and fusion (FRF) module to improve the original segmentation features, and obtain the final segmentation. The proposed modules are simple yet effective and can be flexibly added to any existing segmentation network without excessively increasing time and space complexity. We evaluate the proposed method on the 2017 MICCAI Automated Cardiac Diagnosis Challenge (ACDC) dataset and a large-scale self-collected dataset, showing good segmentation performance and robust generalization ability of the proposed method.
Face Detection Using Improved Faster RCNN
Feb 06, 2018Faster RCNN has achieved great success for generic object detection including PASCAL object detection and MS COCO object detection. In this report, we propose a detailed designed Faster RCNN method named FDNet1.0 for face detection. Several techniques were employed including multi-scale training, multi-scale testing, light-designed RCNN, some tricks for inference and a vote-based ensemble method. Our method achieves two 1th places and one 2nd place in three tasks over WIDER FACE validation dataset (easy set, medium set, hard set).