 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Connections between Regularizations for Improving DNN Robustness
Jul 04, 2020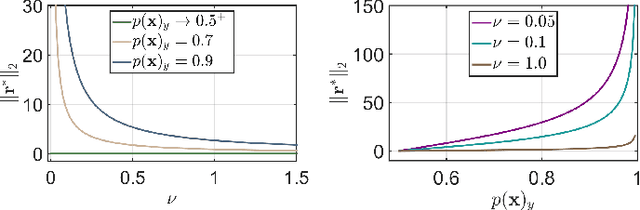
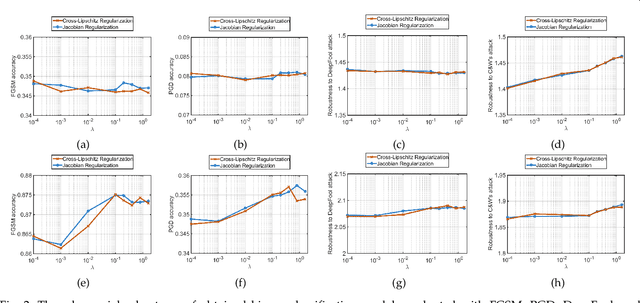
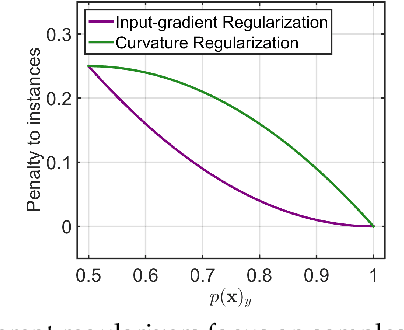
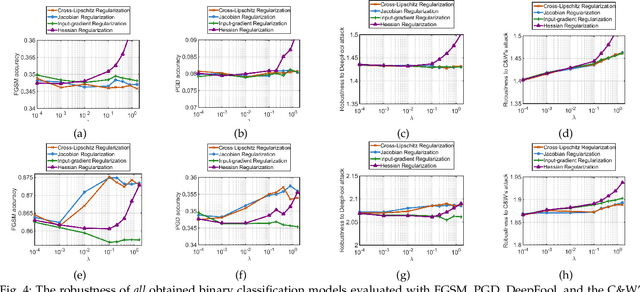
This paper analyzes regularization terms proposed recently for improving the adversarial robustness of deep neural networks (DNNs), from a theoretical point of view. Specifically, we study possible connections between several effective methods, including input-gradient regularization, Jacobian regularization, curvature regularization, and a cross-Lipschitz functional. We investigate them on DNNs with general rectified linear activations, which constitute one of the most prevalent families of models for image classification and a host of other machine learning applications. We shed light on essential ingredients of these regularizations and re-interpret their functionality. Through the lens of our study, more principled and efficient regularizations can possibly be invented in the near future.
Road Network Metric Learning for Estimated Time of Arrival
Jun 24, 2020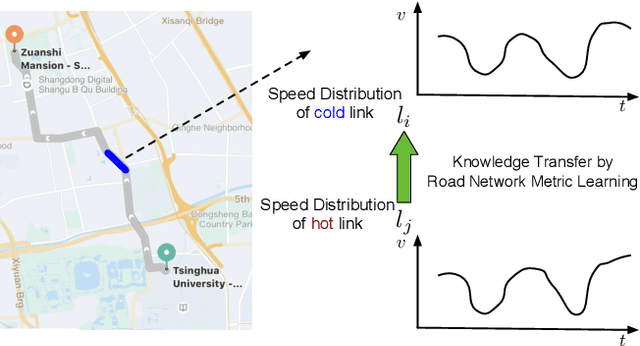
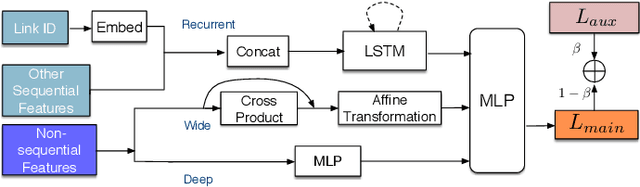
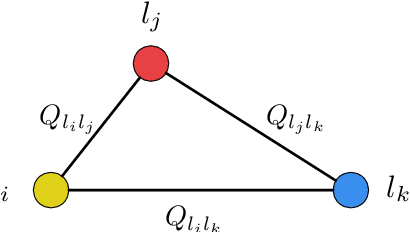
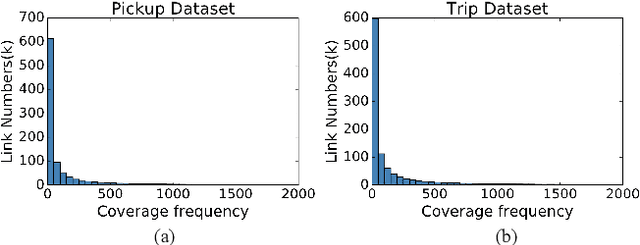
Recently, deep learning have achieved promising results in Estimated Time of Arrival (ETA), which is considered as predicting the travel time from the origin to the destination along a given path. One of the key techniques is to use embedding vectors to represent the elements of road network, such as the links (road segments). However, the embedding suffers from the data sparsity problem that many links in the road network are traversed by too few floating cars even in large ride-hailing platforms like Uber and DiDi. Insufficient data makes the embedding vectors in an under-fitting status, which undermines the accuracy of ETA prediction. To address the data sparsity problem, we propose the Road Network Metric Learning framework for ETA (RNML-ETA). It consists of two components: (1) a main regression task to predict the travel time, and (2) an auxiliary metric learning task to improve the quality of link embedding vectors. We further propose the triangle loss, a novel loss function to improve the efficiency of metric learning. We validated the effectiveness of RNML-ETA on large scale real-world datasets, by showing that our method outperforms the state-of-the-art model and the promotion concentrates on the cold links with few data.
xOrder: A Model Agnostic Post-Processing Framework for Achieving Ranking Fairness While Maintaining Algorithm Utility
Jun 16, 2020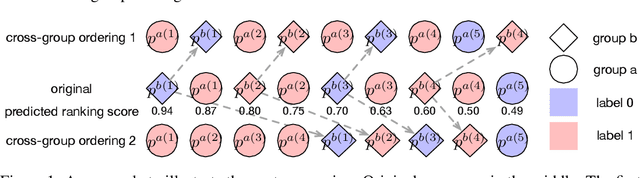

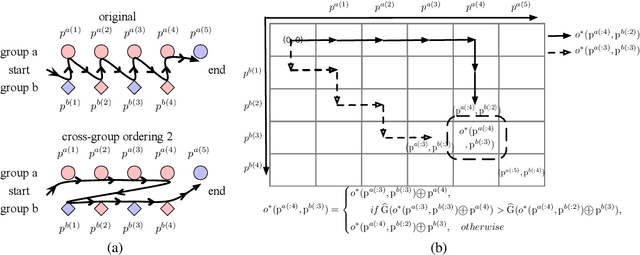
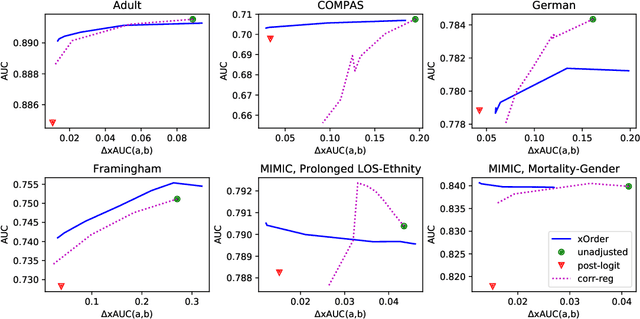
Algorithmic fairness has received lots of interests in machine learning recently. In this paper, we focus on the bipartite ranking scenario, where the instances come from either the positive or negative class and the goal is to learn a ranking function that ranks positive instances higher than negative ones. In an unfair setting, the probabilities of ranking the positives higher than negatives are different across different protected groups. We propose a general post-processing framework, xOrder, for achieving fairness in bipartite ranking while maintaining the algorithm classification performance. In particular, we optimize a weighted sum of the utility and fairness by directly adjusting the relative ordering across groups. We formulate this problem as identifying an optimal warping path across different protected groups and solve it through a dynamic programming process. xOrder is compatible with various classification models and applicable to a variety of ranking fairness metrics. We evaluate our proposed algorithm on four benchmark data sets and one real world patient electronic health record repository. The experimental results show that our approach can achieve great balance between the algorithm utility and ranking fairness. Our algorithm can also achieve robust performance when training and testing ranking score distributions are significantly different.
FMA-ETA: Estimating Travel Time Entirely Based on FFN With Attention
Jun 07, 2020
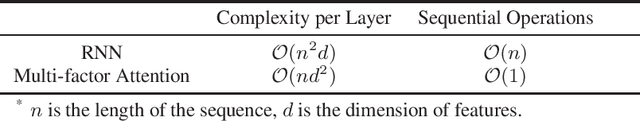
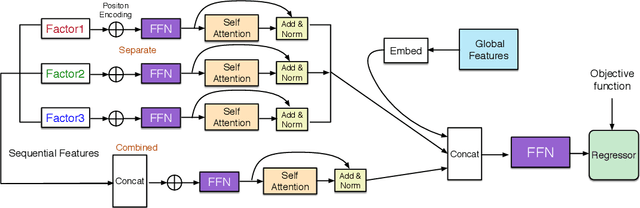
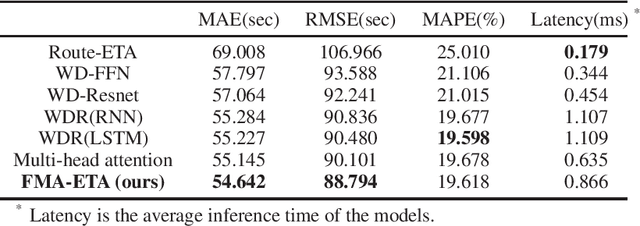
Estimated time of arrival (ETA) is one of the most important services in intelligent transportation systems and becomes a challenging spatial-temporal (ST) data mining task in recent years. Nowadays, deep learning based methods, specifically recurrent neural networks (RNN) based ones are adapted to model the ST patterns from massive data for ETA and become the state-of-the-art. However, RNN is suffering from slow training and inference speed, as its structure is unfriendly to parallel computing. To solve this problem, we propose a novel, brief and effective framework mainly based on feed-forward network (FFN) for ETA, FFN with Multi-factor self-Attention (FMA-ETA). The novel Multi-factor self-attention mechanism is proposed to deal with different category features and aggregate the information purposefully. Extensive experimental results on the real-world vehicle travel dataset show FMA-ETA is competitive with state-of-the-art methods in terms of the prediction accuracy with significantly better inference speed.
Fusion Recurrent Neural Network
Jun 07, 2020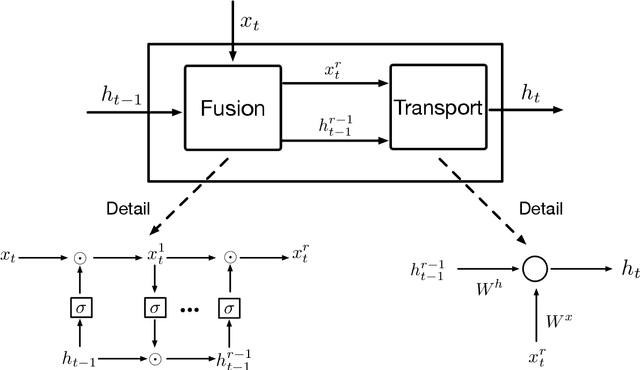


Considering deep sequence learning for practical application, two representative RNNs - LSTM and GRU may come to mind first. Nevertheless, is there no chance for other RNNs? Will there be a better RNN in the future? In this work, we propose a novel, succinct and promising RNN - Fusion Recurrent Neural Network (Fusion RNN). Fusion RNN is composed of Fusion module and Transport module every time step. Fusion module realizes the multi-round fusion of the input and hidden state vector. Transport module which mainly refers to simple recurrent network calculate the hidden state and prepare to pass it to the next time step. Furthermore, in order to evaluate Fusion RNN's sequence feature extraction capability, we choose a representative data mining task for sequence data, estimated time of arrival (ETA) and present a novel model based on Fusion RNN. We contrast our method and other variants of RNN for ETA under massive vehicle travel data from DiDi Chuxing. The results demonstrate that for ETA, Fusion RNN is comparable to state-of-the-art LSTM and GRU which are more complicated than Fusion RNN.
Constructing Geographic and Long-term Temporal Graph for Traffic Forecasting
Apr 23, 2020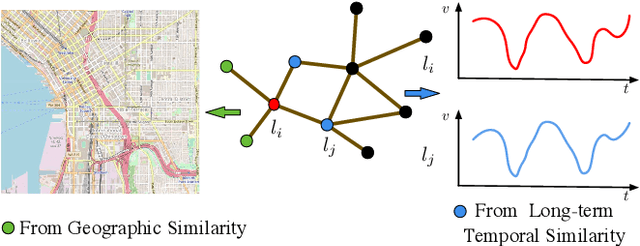
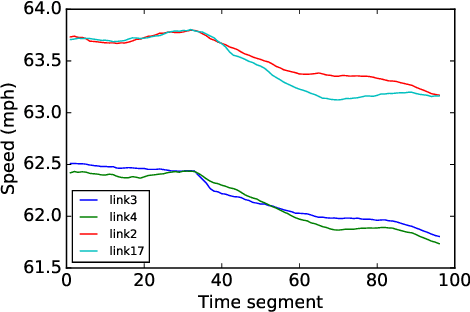
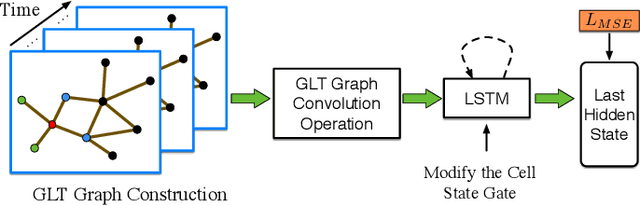
Traffic forecasting influences various intelligent transportation system (ITS) services and is of great significance for user experience as well as urban traffic control. It is challenging due to the fact that the road network contains complex and time-varying spatial-temporal dependencies. Recently, deep learning based methods have achieved promising results by adopting graph convolutional network (GCN) to extract the spatial correlations and recurrent neural network (RNN) to capture the temporal dependencies. However, the existing methods often construct the graph only based on road network connectivity, which limits the interaction between roads. In this work, we propose Geographic and Long term Temporal Graph Convolutional Recurrent Neural Network (GLT-GCRNN), a novel framework for traffic forecasting that learns the rich interactions between roads sharing similar geographic or longterm temporal patterns. Extensive experiments on a real-world traffic state dataset validate the effectiveness of our method by showing that GLT-GCRNN outperforms the state-of-the-art methods in terms of different metrics.
Boosting Semantic Human Matting with Coarse Annotations
Apr 10, 2020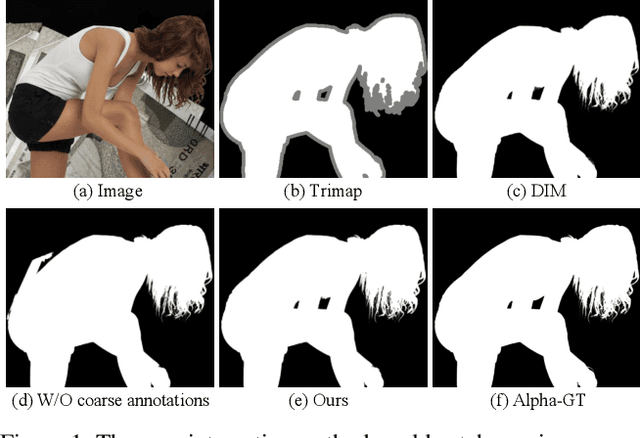
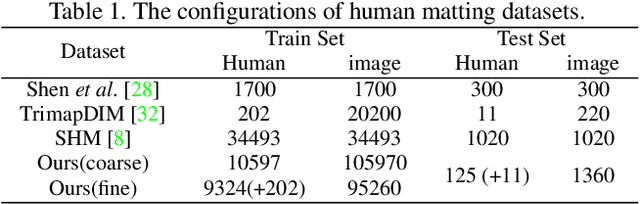
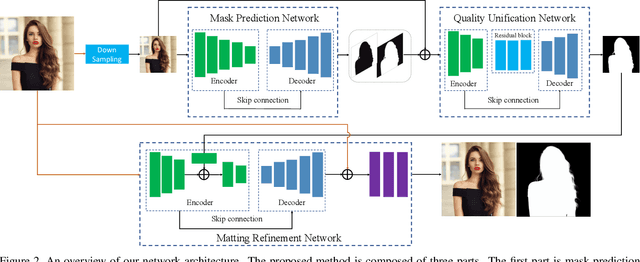
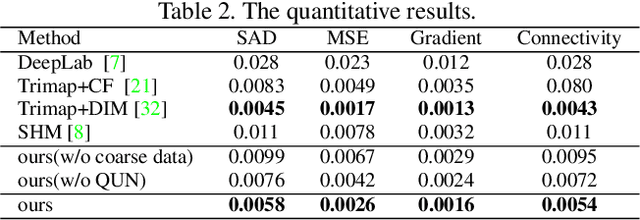
Semantic human matting aims to estimate the per-pixel opacity of the foreground human regions. It is quite challenging and usually requires user interactive trimaps and plenty of high quality annotated data. Annotating such kind of data is labor intensive and requires great skills beyond normal users, especially considering the very detailed hair part of humans. In contrast, coarse annotated human dataset is much easier to acquire and collect from the public dataset. In this paper, we propose to use coarse annotated data coupled with fine annotated data to boost end-to-end semantic human matting without trimaps as extra input. Specifically, we train a mask prediction network to estimate the coarse semantic mask using the hybrid data, and then propose a quality unification network to unify the quality of the previous coarse mask outputs. A matting refinement network takes in the unified mask and the input image to predict the final alpha matte. The collected coarse annotated dataset enriches our dataset significantly, allows generating high quality alpha matte for real images. Experimental results show that the proposed method performs comparably against state-of-the-art methods. Moreover, the proposed method can be used for refining coarse annotated public dataset, as well as semantic segmentation methods, which reduces the cost of annotating high quality human data to a great extent.
GreedyNAS: Towards Fast One-Shot NAS with Greedy Supernet
Mar 25, 2020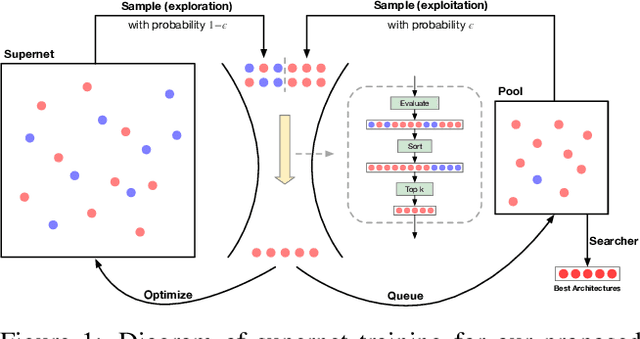
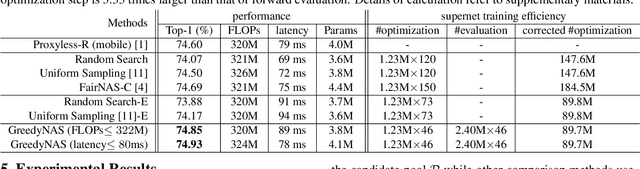
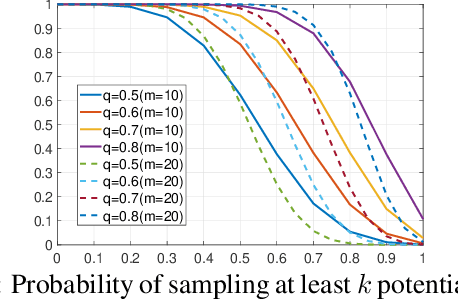
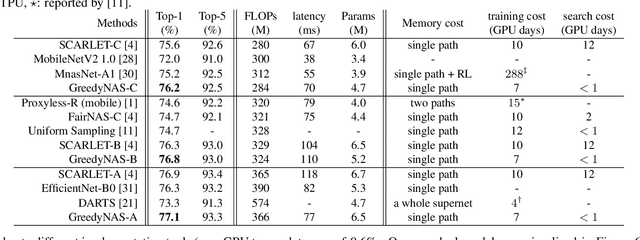
Training a supernet matters for one-shot neural architecture search (NAS) methods since it serves as a basic performance estimator for different architectures (paths). Current methods mainly hold the assumption that a supernet should give a reasonable ranking over all paths. They thus treat all paths equally, and spare much effort to train paths. However, it is harsh for a single supernet to evaluate accurately on such a huge-scale search space (e.g., $7^{21}$). In this paper, instead of covering all paths, we ease the burden of supernet by encouraging it to focus more on evaluation of those potentially-good ones, which are identified using a surrogate portion of validation data. Concretely, during training, we propose a multi-path sampling strategy with rejection, and greedily filter the weak paths. The training efficiency is thus boosted since the training space has been greedily shrunk from all paths to those potentially-good ones. Moreover, we further adopt an exploration and exploitation policy by introducing an empirical candidate path pool. Our proposed method GreedyNAS is easy-to-follow, and experimental results on ImageNet dataset indicate that it can achieve better Top-1 accuracy under same search space and FLOPs or latency level, but with only $\sim$60\% of supernet training cost. By searching on a larger space, our GreedyNAS can also obtain new state-of-the-art architectures.
RL-Duet: Online Music Accompaniment Generation Using Deep Reinforcement Learning
Feb 08, 2020
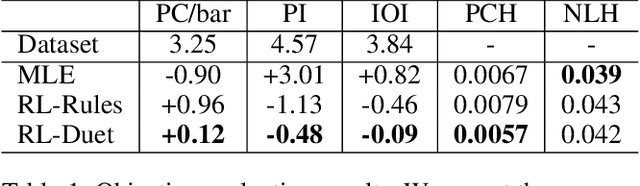

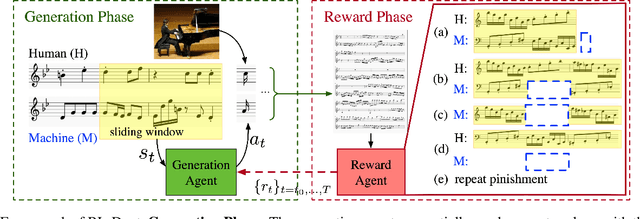
This paper presents a deep reinforcement learning algorithm for online accompaniment generation, with potential for real-time interactive human-machine duet improvisation. Different from offline music generation and harmonization, online music accompaniment requires the algorithm to respond to human input and generate the machine counterpart in a sequential order. We cast this as a reinforcement learning problem, where the generation agent learns a policy to generate a musical note (action) based on previously generated context (state). The key of this algorithm is the well-functioning reward model. Instead of defining it using music composition rules, we learn this model from monophonic and polyphonic training data. This model considers the compatibility of the machine-generated note with both the machine-generated context and the human-generated context. Experiments show that this algorithm is able to respond to the human part and generate a melodic, harmonic and diverse machine part. Subjective evaluations on preferences show that the proposed algorithm generates music pieces of higher quality than the baseline method.
Adversarial Margin Maximization Networks
Nov 14, 2019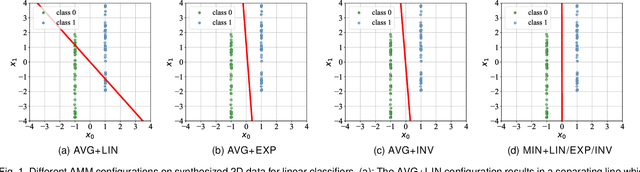
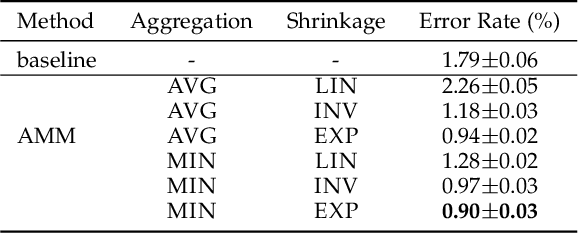
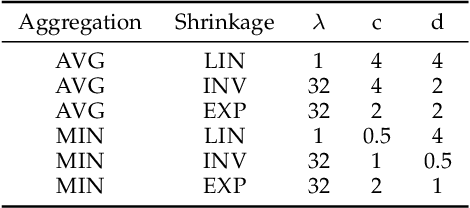
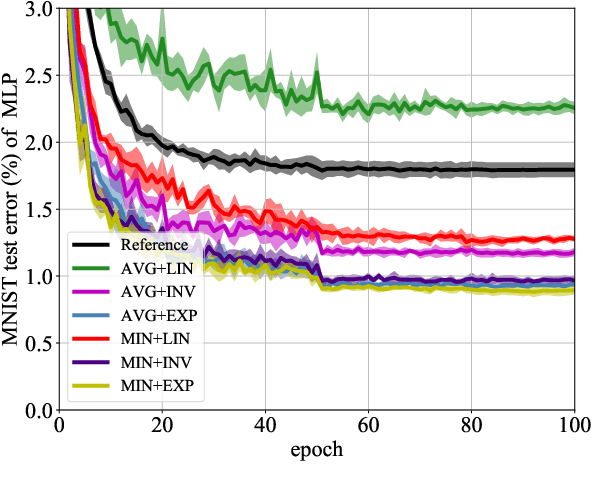
The tremendous recent success of deep neural networks (DNNs) has sparked a surge of interest in understanding their predictive ability. Unlike the human visual system which is able to generalize robustly and learn with little supervision, DNNs normally require a massive amount of data to learn new concepts. In addition, research works also show that DNNs are vulnerable to adversarial examples-maliciously generated images which seem perceptually similar to the natural ones but are actually formed to fool learning models, which means the models have problem generalizing to unseen data with certain type of distortions. In this paper, we analyze the generalization ability of DNNs comprehensively and attempt to improve it from a geometric point of view. We propose adversarial margin maximization (AMM), a learning-based regularization which exploits an adversarial perturbation as a proxy. It encourages a large margin in the input space, just like the support vector machines. With a differentiable formulation of the perturbation, we train the regularized DNNs simply through back-propagation in an end-to-end manner. Experimental results on various datasets (including MNIST, CIFAR-10/100, SVHN and ImageNet) and different DNN architectures demonstrate the superiority of our method over previous state-of-the-arts. Code and models for reproducing our results will be made publicly available.