 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the General Value of Evidence, and Bilingual Scene-Text Visual Question Answering
Feb 26, 2020
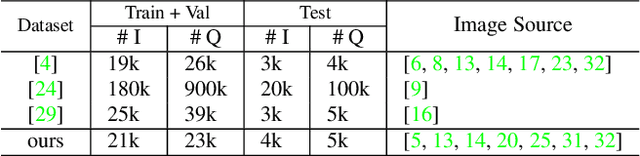

Visual Question Answering (VQA) methods have made incredible progress, but suffer from a failure to generalize. This is visible in the fact that they are vulnerable to learning coincidental correlations in the data rather than deeper relations between image content and ideas expressed in language. We present a dataset that takes a step towards addressing this problem in that it contains questions expressed in two languages, and an evaluation process that co-opts a well understood image-based metric to reflect the method's ability to reason. Measuring reasoning directly encourages generalization by penalizing answers that are coincidentally correct. The dataset reflects the scene-text version of the VQA problem, and the reasoning evaluation can be seen as a text-based version of a referring expression challenge. Experiments and analysis are provided that show the value of the dataset.
Separating Content from Style Using Adversarial Learning for Recognizing Text in the Wild
Jan 13, 2020

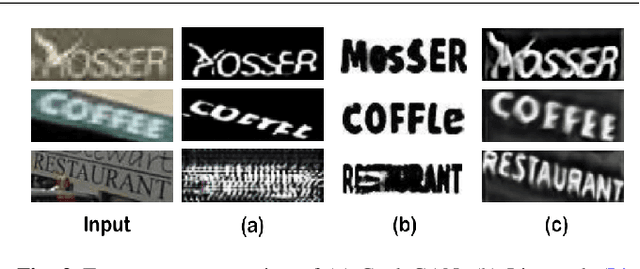

In this work we propose to improve text recognition from a new perspective by separating text content from complex backgrounds. We exploit the generative adversarial networks (GANs) for removing backgrounds while retaining the text content. As vanilla GANs are not sufficiently robust to generate sequence-like characters in natural images, we propose an adversarial learning framework for the generation and recognition of multiple characters in an image. The proposed framework consists of an attention-based recognizer and a generative adversarial architecture. Furthermore, to tackle the lack of paired training samples, we design an interactive joint training scheme, which shares attention masks from the recognizer to the discriminator, and enables the discriminator to extract the features of every character for further adversarial training. Benefiting from the character-level adversarial training, our framework requires only unpaired simple data for style supervision. Every target style sample containing only one randomly chosen character can be simply synthesized online during the training. This is significant as the training does not require costly paired samples or character-level annotations. Thus, only the input images and corresponding text labels are needed. In addition to the style transfer of the backgrounds, we refine character patterns to ease the recognition task. A feedback mechanism is proposed to bridge the gap between the discriminator and the recognizer. Therefore, the discriminator can guide the generator according to the confusion of the recognizer. The generated patterns are thus clearer for recognition. Experiments on various benchmarks, including both regular and irregular text, demonstrate that our method significantly reduces the difficulty of recognition. Our framework can be integrated with recent recognition methods to achieve new state-of-the-art performance.
Decoupled Attention Network for Text Recognition
Dec 21, 2019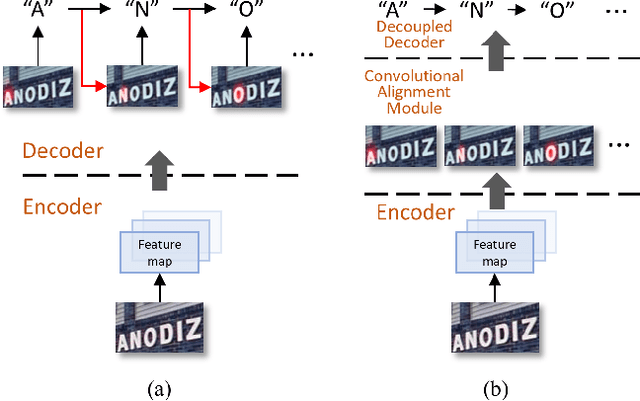
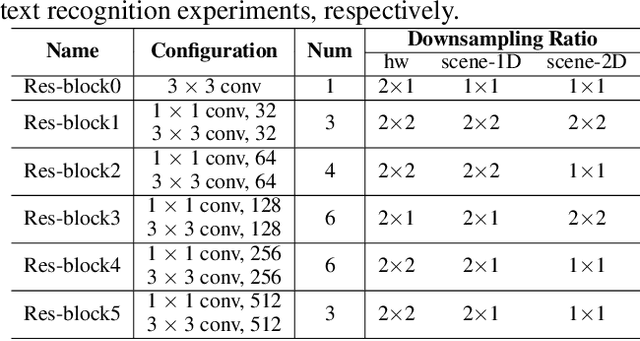
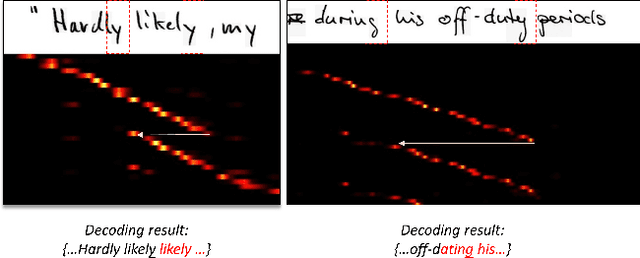
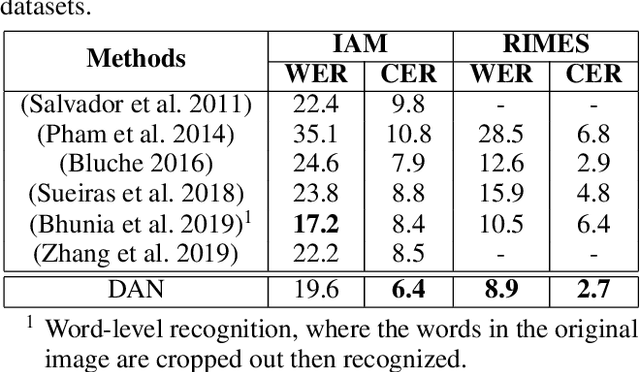
Text recognition has attracted considerable research interests because of its various applications. The cutting-edge text recognition methods are based on attention mechanisms. However, most of attention methods usually suffer from serious alignment problem due to its recurrency alignment operation, where the alignment relies on historical decoding results. To remedy this issue, we propose a decoupled attention network (DAN), which decouples the alignment operation from using historical decoding results. DAN is an effective, flexible and robust end-to-end text recognizer, which consists of three components: 1) a feature encoder that extracts visual features from the input image; 2) a convolutional alignment module that performs the alignment operation based on visual features from the encoder; and 3) a decoupled text decoder that makes final prediction by jointly using the feature map and attention maps. Experimental results show that DAN achieves state-of-the-art performance on multiple text recognition tasks, including offline handwritten text recognition and regular/irregular scene text recognition.
Exploring the Capacity of Sequential-free Box Discretization Network for Omnidirectional Scene Text Detection
Dec 20, 2019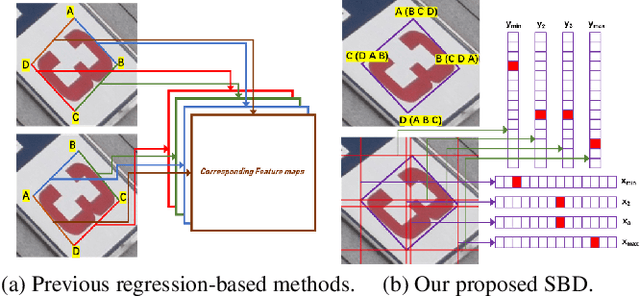

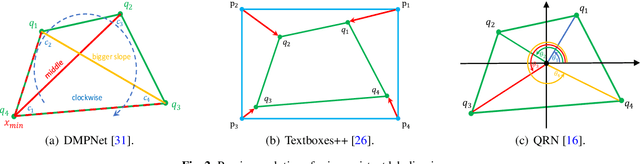

Omnidirectional scene text detection has received increasing research attention. Previous methods directly predict words or text lines of quadrilateral shapes. However, most methods neglect the significance of consistent labeling, which is important to maintain a stable training process, especially when a large amount of data are included. For the first time, we solve the problem in this paper by proposing a novel method termed Sequential-free Box Discretization (SBD). The proposed SBD first discretizes the quadrilateral box into several key edges, which contains all potential horizontal and vertical positions. In order to decode accurate vertex positions, a simple yet effective matching procedure is proposed to reconstruct the quadrilateral bounding boxes. It departs from the learning ambiguity which has a significant influence during the learning process. Exhaustive ablation studies have been conducted to quantitatively validate the effectiveness of our proposed method. More importantly, built upon SBD, we provide a detailed analysis of the impact of a collection of refinements, in the hope to inspire others to build state-of-the-art networks. Combining both SBD and these useful refinements, we achieve state-of-the-art performance on various benchmarks, including ICDAR 2015, and MLT. Our method also wins the first place in text detection task of the recent ICDAR2019 Robust Reading Challenge on Reading Chinese Text on Signboard, further demonstrating its powerful generalization ability. Code is available at https://tinyurl.com/sbdnet.
ICDAR 2019 Competition on Large-scale Street View Text with Partial Labeling -- RRC-LSVT
Sep 17, 2019


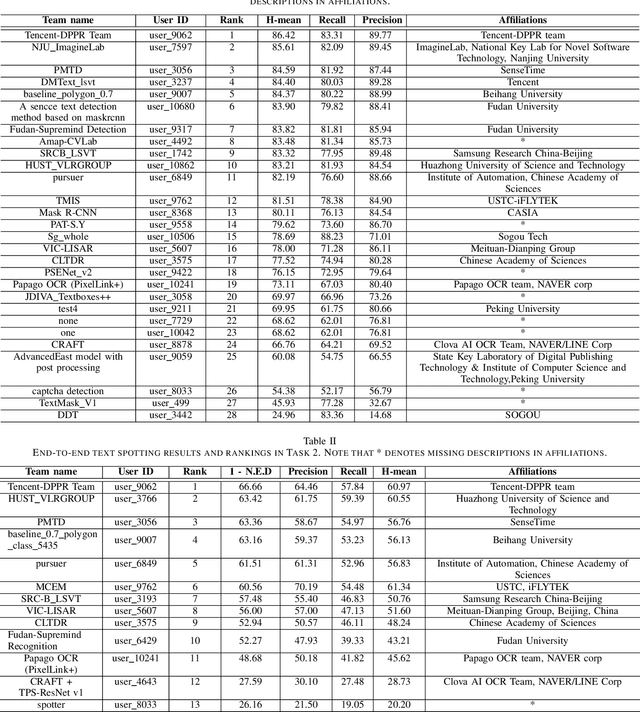
Robust text reading from street view images provides valuable information for various applications. Performance improvement of existing methods in such a challenging scenario heavily relies on the amount of fully annotated training data, which is costly and in-efficient to obtain. To scale up the amount of training data while keeping the labeling procedure cost-effective, this competition introduces a new challenge on Large-scale Street View Text with Partial Labeling (LSVT), providing 50, 000 and 400, 000 images in full and weak annotations, respectively. This competition aims to explore the abilities of state-of-the-art methods to detect and recognize text instances from large-scale street view images, closing the gap between research benchmarks and real applications. During the competition period, a total of 41 teams participated in the two proposed tasks with 132 valid submissions, i.e., text detection and end-to-end text spotting. This paper includes dataset descriptions, task definitions, evaluation protocols and results summaries of the ICDAR 2019-LSVT challenge.
ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT)
Sep 16, 2019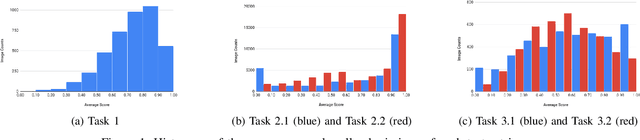



This paper reports the ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT) that consists of three major challenges: i) scene text detection, ii) scene text recognition, and iii) scene text spotting. A total of 78 submissions from 46 unique teams/individuals were received for this competition. The top performing score of each challenge is as follows: i) T1 - 82.65%, ii) T2.1 - 74.3%, iii) T2.2 - 85.32%, iv) T3.1 - 53.86%, and v) T3.2 - 54.91%. Apart from the results, this paper also details the ArT dataset, tasks description, evaluation metrics and participants methods. The dataset, the evaluation kit as well as the results are publicly available at https://rrc.cvc.uab.es/?ch=14
Adaptive Embedding Gate for Attention-Based Scene Text Recognition
Aug 26, 2019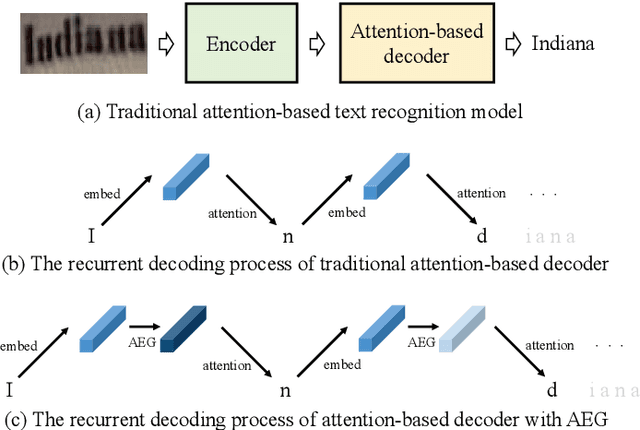
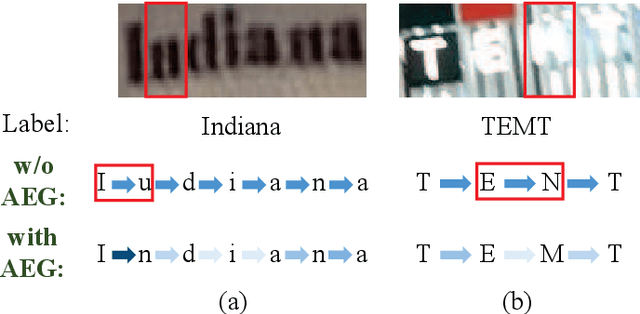
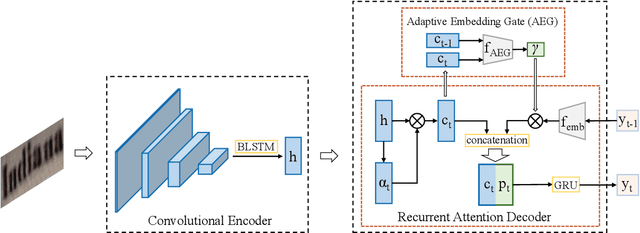

Scene text recognition has attracted particular research interest because it is a very challenging problem and has various applications. The most cutting-edge methods are attentional encoder-decoder frameworks that learn the alignment between the input image and output sequences. In particular, the decoder recurrently outputs predictions, using the prediction of the previous step as a guidance for every time step. In this study, we point out that the inappropriate use of previous predictions in existing attention mechanisms restricts the recognition performance and brings instability. To handle this problem, we propose a novel module, namely adaptive embedding gate(AEG). The proposed AEG focuses on introducing high-order character language models to attention mechanism by controlling the information transmission between adjacent characters. AEG is a flexible module and can be easily integrated into the state-of-the-art attentional methods. We evaluate its effectiveness as well as robustness on a number of standard benchmarks, including the IIIT$5$K, SVT, SVT-P, CUTE$80$, and ICDAR datasets. Experimental results demonstrate that AEG can significantly boost recognition performance and bring better robustness.
Tightness-aware Evaluation Protocol for Scene Text Detection
Mar 27, 2019
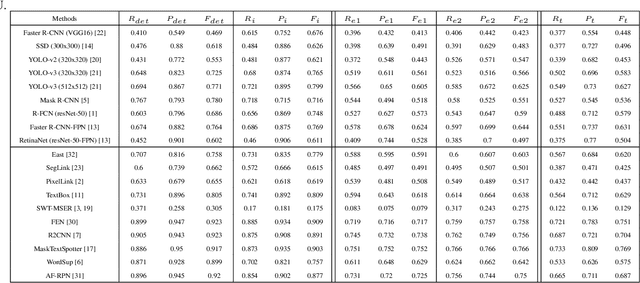

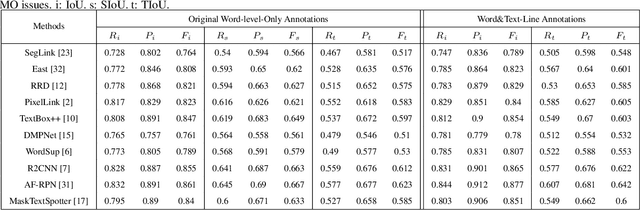
Evaluation protocols play key role in the developmental progress of text detection methods. There are strict requirements to ensure that the evaluation methods are fair, objective and reasonable. However, existing metrics exhibit some obvious drawbacks: 1) They are not goal-oriented; 2) they cannot recognize the tightness of detection methods; 3) existing one-to-many and many-to-one solutions involve inherent loopholes and deficiencies. Therefore, this paper proposes a novel evaluation protocol called Tightness-aware Intersect-over-Union (TIoU) metric that could quantify completeness of ground truth, compactness of detection, and tightness of matching degree. Specifically, instead of merely using the IoU value, two common detection behaviors are properly considered; meanwhile, directly using the score of TIoU to recognize the tightness. In addition, we further propose a straightforward method to address the annotation granularity issue, which can fairly evaluate word and text-line detections simultaneously. By adopting the detection results from published methods and general object detection frameworks, comprehensive experiments on ICDAR 2013 and ICDAR 2015 datasets are conducted to compare recent metrics and the proposed TIoU metric. The comparison demonstrated some promising new prospects, e.g., determining the methods and frameworks for which the detection is tighter and more beneficial to recognize. Our method is extremely simple; however, the novelty is none other than the proposed metric can utilize simplest but reasonable improvements to lead to many interesting and insightful prospects and solving most the issues of the previous metrics. The code is publicly available at https://github.com/Yuliang-Liu/TIoU-metric .
A Multi-Object Rectified Attention Network for Scene Text Recognition
Jan 10, 2019
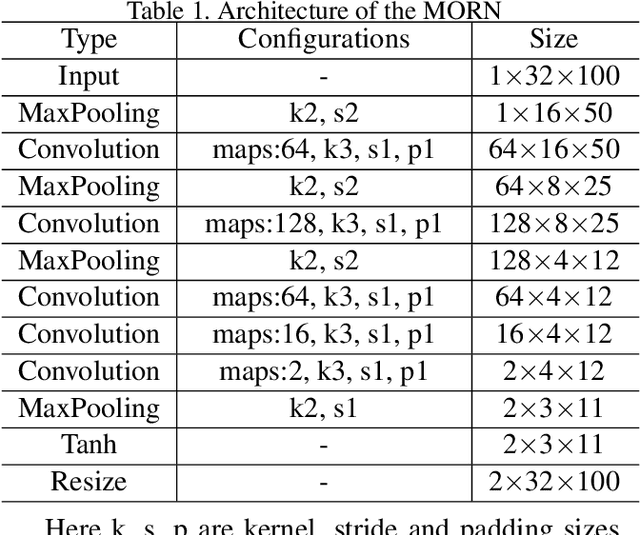
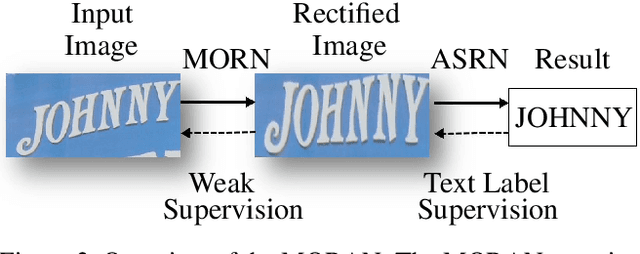
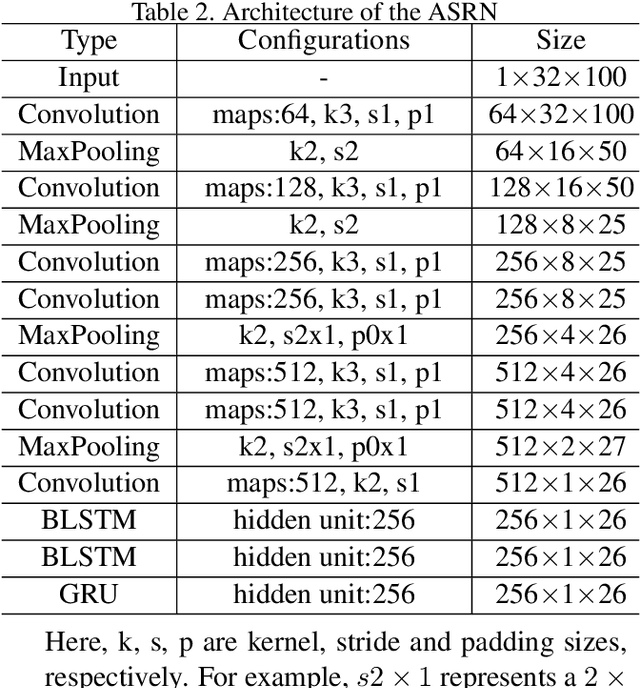
Irregular text is widely used. However, it is considerably difficult to recognize because of its various shapes and distorted patterns. In this paper, we thus propose a multi-object rectified attention network (MORAN) for general scene text recognition. The MORAN consists of a multi-object rectification network and an attention-based sequence recognition network. The multi-object rectification network is designed for rectifying images that contain irregular text. It decreases the difficulty of recognition and enables the attention-based sequence recognition network to more easily read irregular text. It is trained in a weak supervision way, thus requiring only images and corresponding text labels. The attention-based sequence recognition network focuses on target characters and sequentially outputs the predictions. Moreover, to improve the sensitivity of the attention-based sequence recognition network, a fractional pickup method is proposed for an attention-based decoder in the training phase. With the rectification mechanism, the MORAN can read both regular and irregular scene text. Extensive experiments on various benchmarks are conducted, which show that the MORAN achieves state-of-the-art performance. The source code is available.
Feature Enhancement Network: A Refined Scene Text Detector
Nov 12, 2017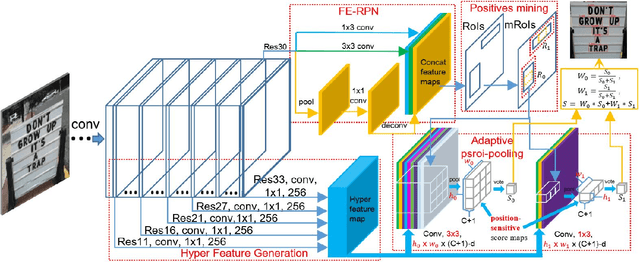
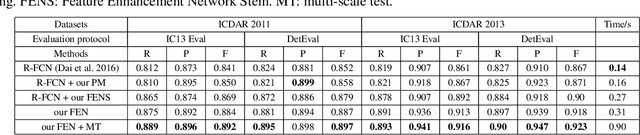

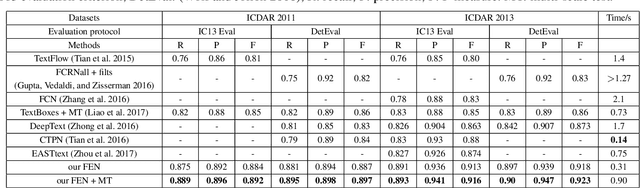
In this paper, we propose a refined scene text detector with a \textit{novel} Feature Enhancement Network (FEN) for Region Proposal and Text Detection Refinement. Retrospectively, both region proposal with \textit{only} $3\times 3$ sliding-window feature and text detection refinement with \textit{single scale} high level feature are insufficient, especially for smaller scene text. Therefore, we design a new FEN network with \textit{task-specific}, \textit{low} and \textit{high} level semantic features fusion to improve the performance of text detection. Besides, since \textit{unitary} position-sensitive RoI pooling in general object detection is unreasonable for variable text regions, an \textit{adaptively weighted} position-sensitive RoI pooling layer is devised for further enhancing the detecting accuracy. To tackle the \textit{sample-imbalance} problem during the refinement stage, we also propose an effective \textit{positives mining} strategy for efficiently training our network. Experiments on ICDAR 2011 and 2013 robust text detection benchmarks demonstrate that our method can achieve state-of-the-art results, outperforming all reported methods in terms of F-measure.