 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposing Ensembles of Policies with Deep Reinforcement Learning
May 25, 2019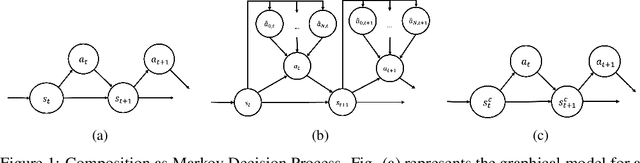

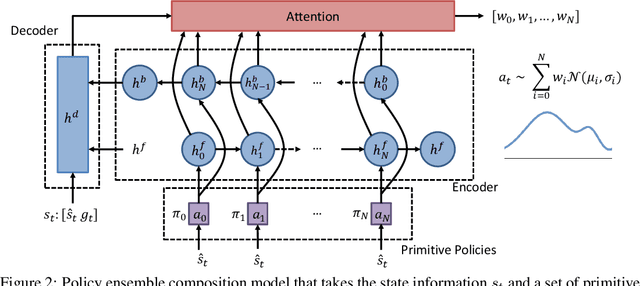
Composition of elementary skills into complex behaviors to solve challenging problems is one of the key elements toward building intelligent machines. To date, there has been plenty of work on learning new policies or skills but almost no focus on composing them to perform complex decision-making. In this paper, we propose a policy ensemble composition framework that takes the robot's primitive policies and learns to compose them concurrently or sequentially through reinforcement learning. We evaluate our method in problems where traditional approaches either fail or exhibit high sample complexity to find a solution. We show that our method not only solves the problems that require both task and motion planning but also exhibits high data efficiency, which is currently one of the main limitations of reinforcement learning.
Learning to Find Common Objects Across Image Collections
Apr 29, 2019
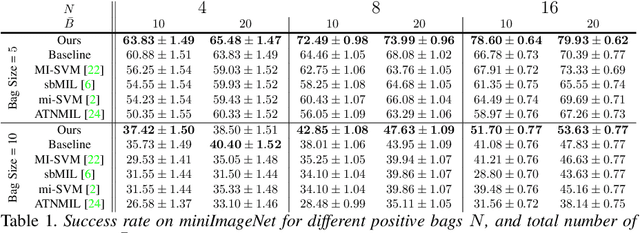
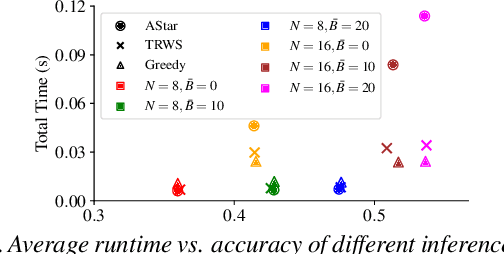
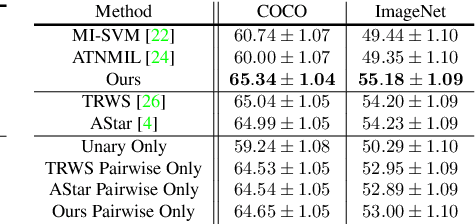
We address the problem of finding a set of images containing a common, but unknown, object category from a collection of image proposals. Our formulation assumes that we are given a collection of bags where each bag is a set of image proposals. Our goal is to select one image from each bag such that the selected images are of the same object category. We model the selection as an energy minimization problem with unary and pairwise potential functions. Inspired by recent few-shot learning algorithms, we propose an approach to learn the potential functions directly from the data. Furthermore, we propose a fast and simple greedy inference algorithm for energy minimization. We evaluate our approach on few-shot common object recognition and object co-localization tasks. Our experiments show that learning the pairwise and unary terms greatly improves the performance of the model over several well-known methods for these tasks. The proposed greedy optimization algorithm achieves performance comparable to state-of-the-art structured inference algorithms while being ~10 times faster. The code is publicly available on https://github.com/haamoon/finding_common_object.
RMPflow: A Computational Graph for Automatic Motion Policy Generation
Apr 05, 2019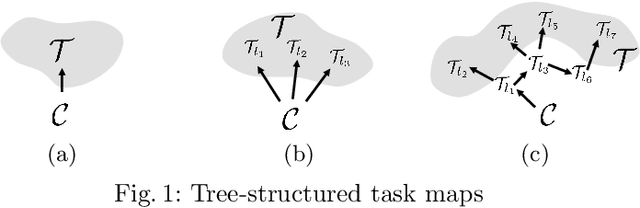
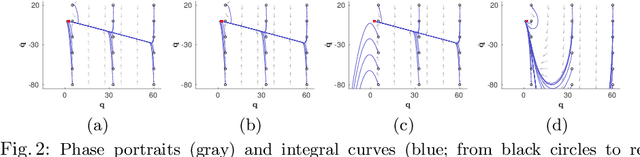
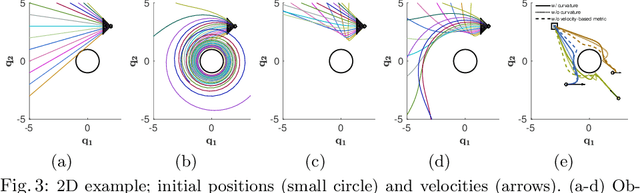
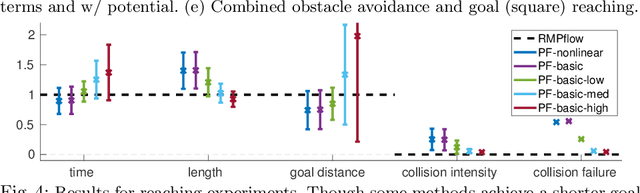
We develop a novel policy synthesis algorithm, RMPflow, based on geometrically consistent transformations of Riemannian Motion Policies (RMPs). RMPs are a class of reactive motion policies designed to parameterize non-Euclidean behaviors as dynamical systems in intrinsically nonlinear task spaces. Given a set of RMPs designed for individual tasks, RMPflow can consistently combine these local policies to generate an expressive global policy, while simultaneously exploiting sparse structure for computational efficiency. We study the geometric properties of RMPflow and provide sufficient conditions for stability. Finally, we experimentally demonstrate that accounting for the geometry of task policies can simplify classically difficult problems, such as planning through clutter on high-DOF manipulation systems.
Stable, Concurrent Controller Composition for Multi-Objective Robotic Tasks
Mar 29, 2019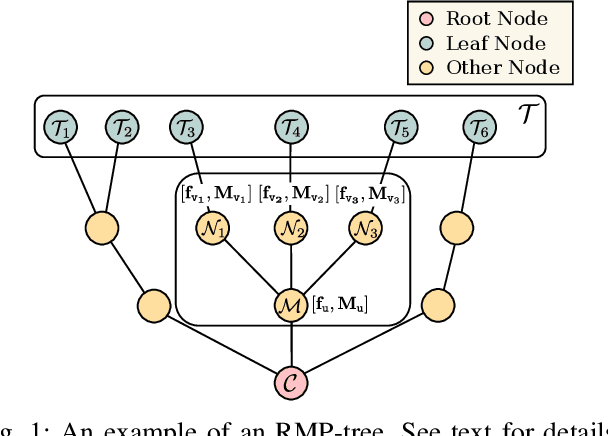
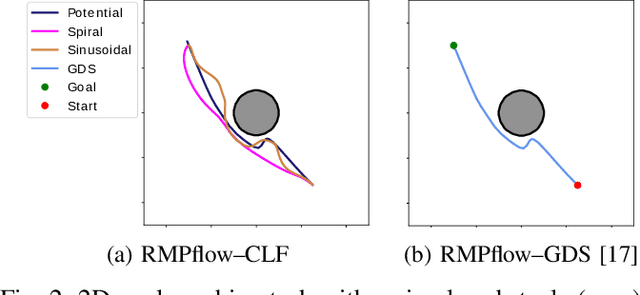
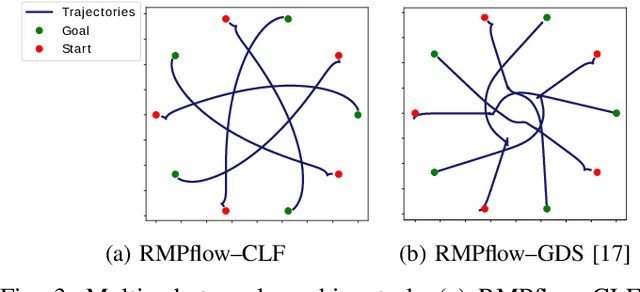

Robotic systems often need to consider multiple tasks concurrently. This challenge calls for control synthesis algorithms that are capable of fulfilling multiple control specifications simultaneously while maintaining the stability of the overall system. In this paper, we decompose complex, multi-objective tasks into subtasks, where individual subtask controllers are designed independently and then combined to generate the overall control policy. In particular, we adopt Riemannian Motion Policies (RMPs), a recently proposed controller structure in robotics, and, RMPflow, its associated computational framework for combining RMP controllers. We re-establish and extend the stability results of RMPflow through a rigorous Control Lyapunov Function (CLF) treatment. We then show that RMPflow can stably combine individually designed subtask controllers that satisfy certain CLF constraints. This new insight leads to an efficient CLF-based computational framework to generate stable controllers that consider all the subtasks simultaneously. Compared with the original usage of RMPflow, our framework provides users the flexibility to incorporate design heuristics through nominal controllers for the subtasks. We validate the proposed computational framework through numerical simulation and robotic implementation.
Learning Quantum Graphical Models using Constrained Gradient Descent on the Stiefel Manifold
Mar 09, 2019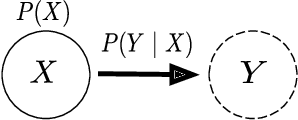
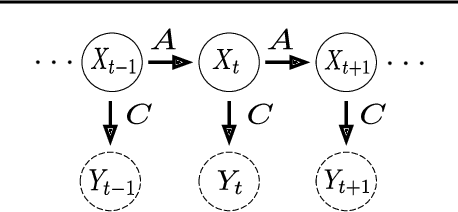
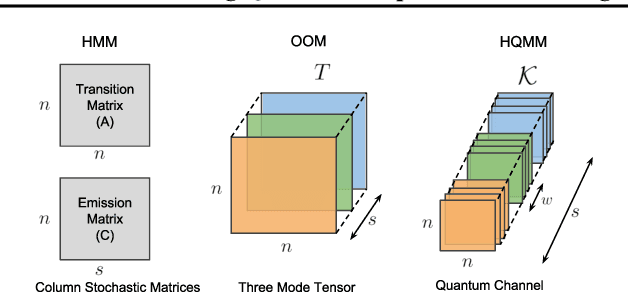
Quantum graphical models (QGMs) extend the classical framework for reasoning about uncertainty by incorporating the quantum mechanical view of probability. Prior work on QGMs has focused on hidden quantum Markov models (HQMMs), which can be formulated using quantum analogues of the sum rule and Bayes rule used in classical graphical models. Despite the focus on developing the QGM framework, there has been little progress in learning these models from data. The existing state-of-the-art approach randomly initializes parameters and iteratively finds unitary transformations that increase the likelihood of the data. While this algorithm demonstrated theoretical strengths of HQMMs over HMMs, it is slow and can only handle a small number of hidden states. In this paper, we tackle the learning problem by solving a constrained optimization problem on the Stiefel manifold using a well-known retraction-based algorithm. We demonstrate that this approach is not only faster and yields better solutions on several datasets, but also scales to larger models that were prohibitively slow to train via the earlier method.
Joint Inference of Kinematic and Force Trajectories with Visuo-Tactile Sensing
Mar 08, 2019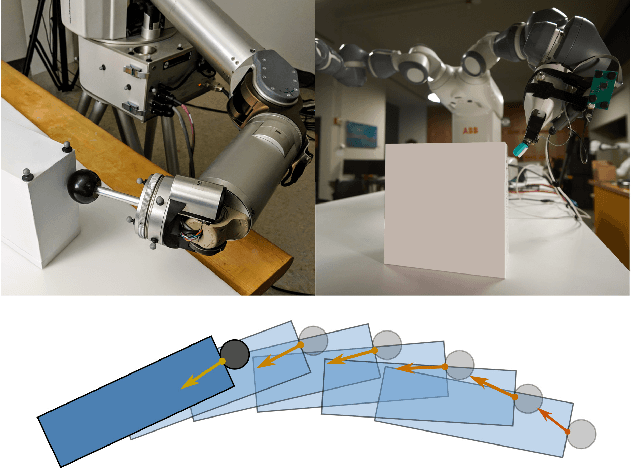
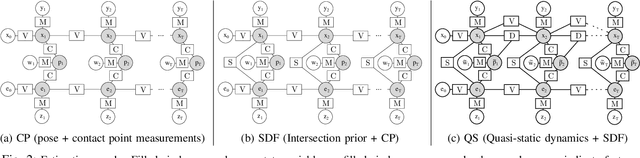
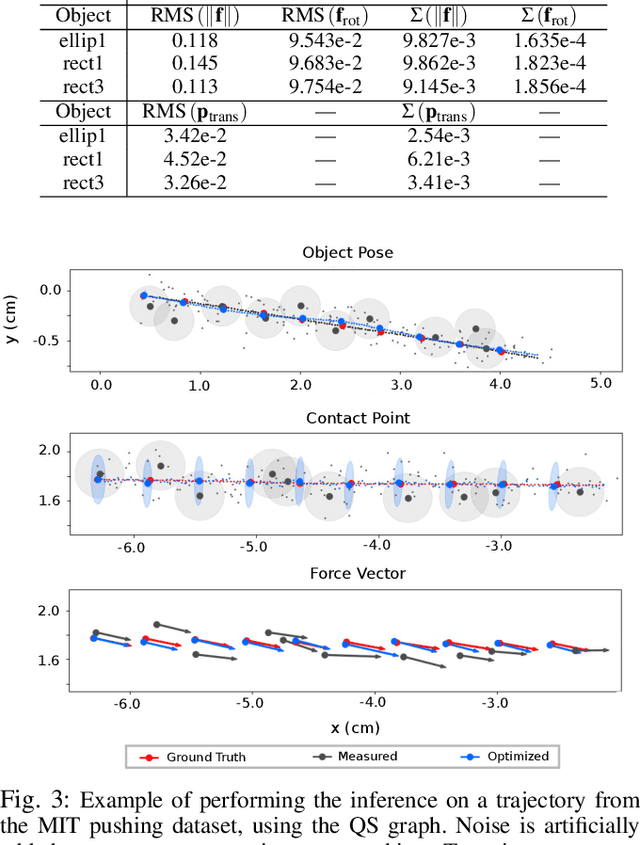

To perform complex tasks, robots must be able to interact with and manipulate their surroundings. One of the key challenges in accomplishing this is robust state estimation during physical interactions, where the state involves not only the robot and the object being manipulated, but also the state of the contact itself. In this work, within the context of planar pushing, we extend previous inference-based approaches to state estimation in several ways. We estimate the robot, object, and the contact state on multiple manipulation platforms configured with a vision-based articulated model tracker, and either a biomimetic tactile sensor or a force-torque sensor. We show how to fuse raw measurements from the tracker and tactile sensors to jointly estimate the trajectory of the kinematic states and the forces in the system via probabilistic inference on factor graphs, in both batch and incremental settings. We perform several benchmarks with our framework and show how performance is affected by incorporating various geometric and physics based constraints, occluding vision sensors, or injecting noise in tactile sensors. We also compare with prior work on multiple datasets and demonstrate that our approach can effectively optimize over multi-modal sensor data and reduce uncertainty to find better state estimates.
Robust Learning of Tactile Force Estimation through Robot Interaction
Mar 05, 2019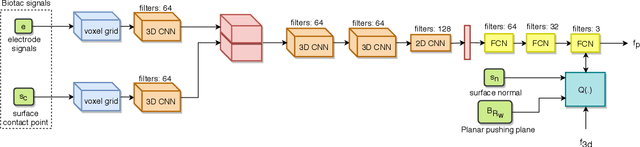
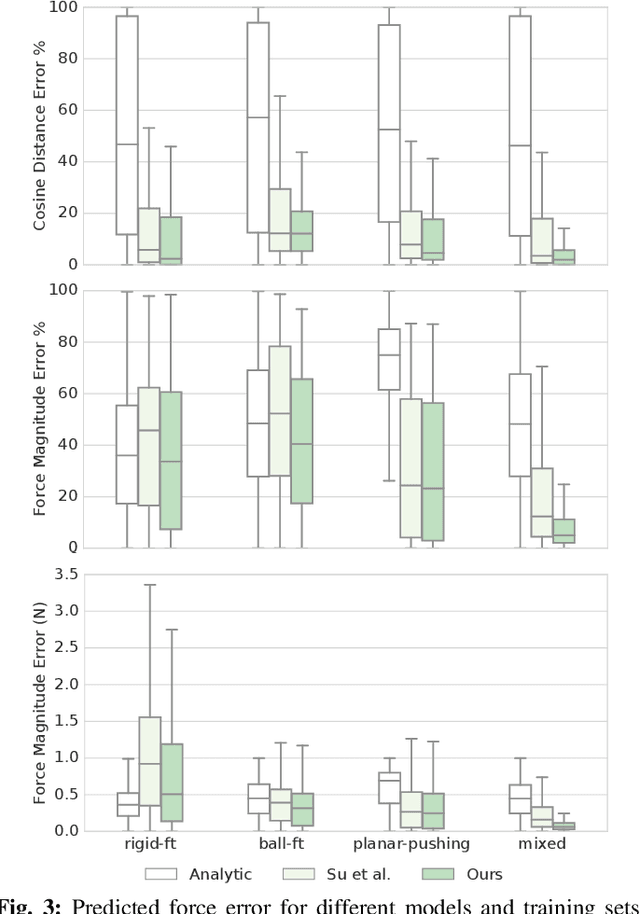
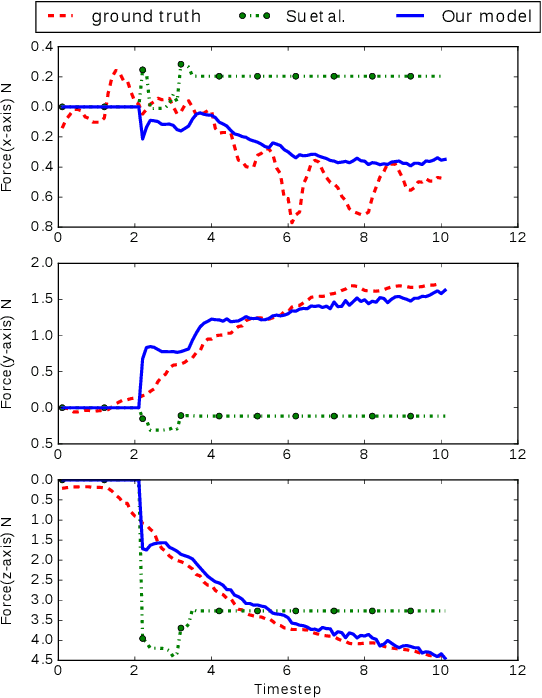
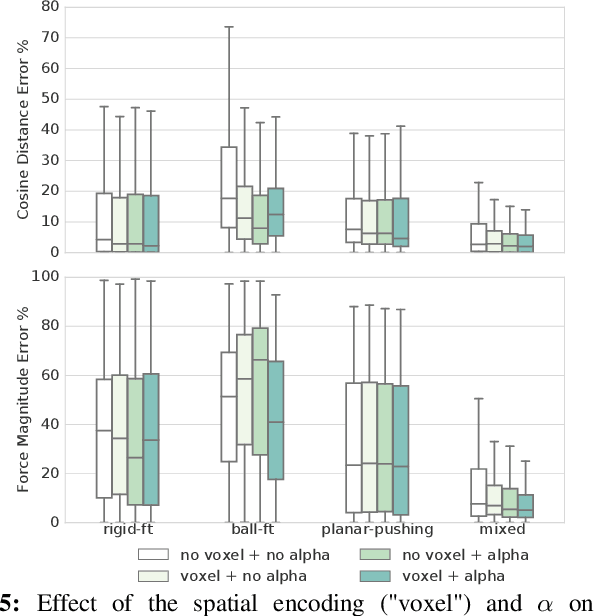
Current methods for estimating force from tactile sensor signals are either inaccurate analytic models or task-specific learned models. In this paper, we explore learning a robust model that maps tactile sensor signals to force. We specifically explore learning a mapping for the SynTouch BioTac sensor via neural networks. We propose a voxelized input feature layer for spatial signals and leverage information about the sensor surface to regularize the loss function. To learn a robust tactile force model that transfers across tasks, we generate ground truth data from three different sources: (1) the BioTac rigidly mounted to a force torque~(FT) sensor, (2) a robot interacting with a ball rigidly attached to the same FT sensor, and (3) through force inference on a planar pushing task by formalizing the mechanics as a system of particles and optimizing over the object motion. A total of 140k samples were collected from the three sources. We achieve a median angular accuracy of 3.5 degrees in predicting force direction (66% improvement over the current state of the art) and a median magnitude accuracy of 0.06 N (93% improvement) on a test dataset. Additionally, we evaluate the learned force model in a force feedback grasp controller performing object lifting and gentle placement. Our results can be found on https://sites.google.com/view/tactile-force.
An Online Learning Approach to Model Predictive Control
Feb 24, 2019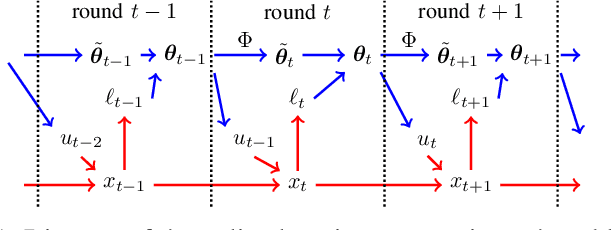
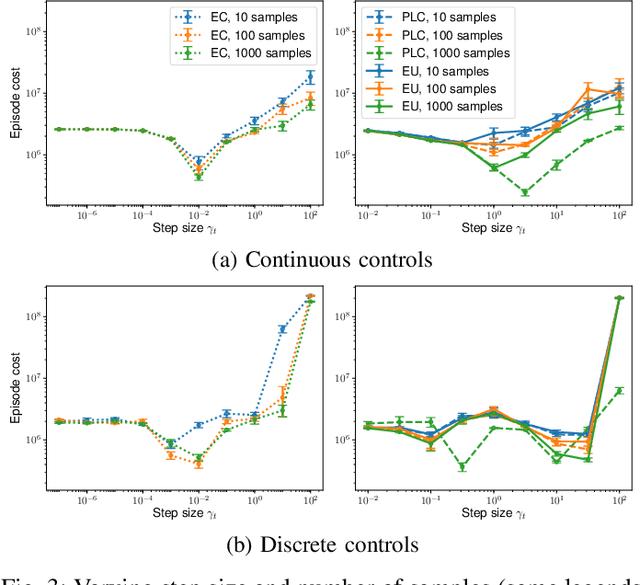
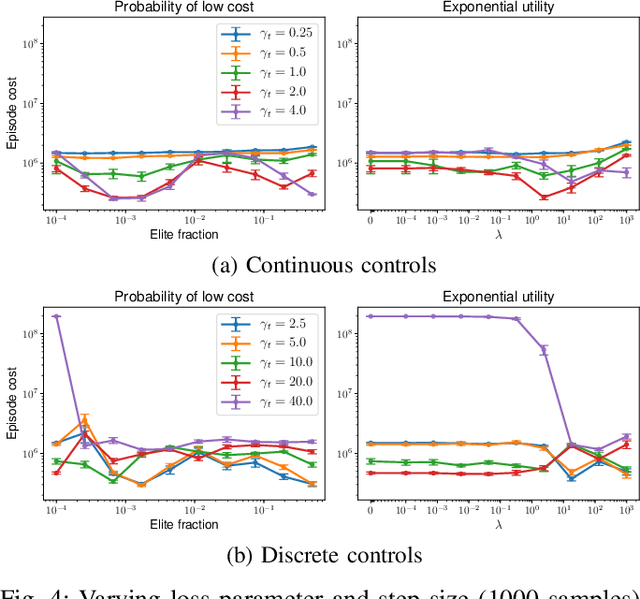
Model predictive control (MPC) is a powerful technique for solving dynamic control tasks. In this paper, we show that there exists a close connection between MPC and online learning, an abstract theoretical framework for analyzing online decision making in the optimization literature. This new perspective provides a foundation for leveraging powerful online learning algorithms to design MPC algorithms. Specifically, we propose a new algorithm based on dynamic mirror descent (DMD), an online learning algorithm that is designed for non-stationary setups. Our algorithm, Dynamic Mirror Decent Model Predictive Control (DMD-MPC), represents a general family of MPC algorithms that includes many existing techniques as special instances. DMD-MPC also provides a fresh perspective on previous heuristics used in MPC and suggests a principled way to design new MPC algorithms. In the experimental section of this paper, we demonstrate the flexibility of DMD-MPC, presenting a set of new MPC algorithms on a simple simulated cartpole and a simulated and real-world aggressive driving task.
Adversarial Imitation via Variational Inverse Reinforcement Learning
Feb 22, 2019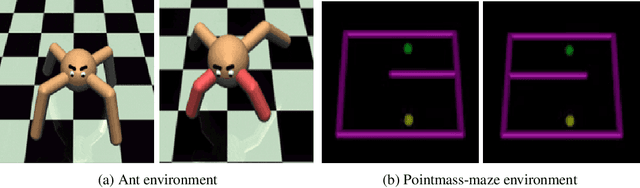
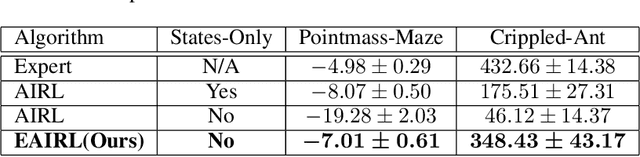
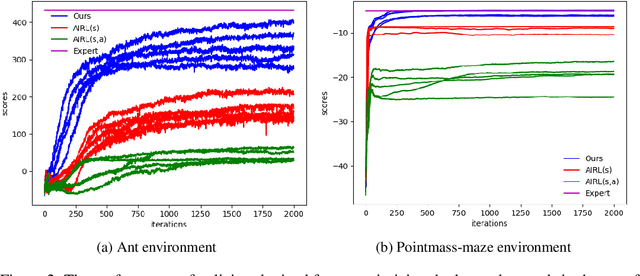
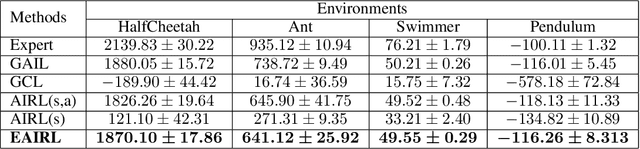
We consider a problem of learning the reward and policy from expert examples under unknown dynamics. Our proposed method builds on the framework of generative adversarial networks and introduces the empowerment-regularized maximum-entropy inverse reinforcement learning to learn near-optimal rewards and policies. Empowerment-based regularization prevents the policy from overfitting to expert demonstrations, which advantageously leads to more generalized behaviors that result in learning near-optimal rewards. Our method simultaneously learns empowerment through variational information maximization along with the reward and policy under the adversarial learning formulation. We evaluate our approach on various high-dimensional complex control tasks. We also test our learned rewards in challenging transfer learning problems where training and testing environments are made to be different from each other in terms of dynamics or structure. The results show that our proposed method not only learns near-optimal rewards and policies that are matching expert behavior but also performs significantly better than state-of-the-art inverse reinforcement learning algorithms.
Online Learning with Continuous Variations: Dynamic Regret and Reductions
Feb 19, 2019We study the dynamic regret of a new class of online learning problems, in which the gradient of the loss function changes continuously across rounds with respect to the learner's decisions. This setup is motivated by the use of online learning as a tool to analyze the performance of iterative algorithms. Our goal is to identify interpretable dynamic regret rates that explicitly consider the loss variations as consequences of the learner's decisions as opposed to external constraints. We show that achieving sublinear dynamic regret in general is equivalent to solving certain variational inequalities, equilibrium problems, and fixed-point problems. Leveraging this identification, we present necessary and sufficient conditions for the existence of efficient algorithms that achieve sublinear dynamic regret. Furthermore, we show a reduction from dynamic regret to both static regret and convergence rate to equilibriums in the aforementioned problems, which allows us to analyze the dynamic regret of many existing learning algorithms in few steps.