 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplete & Label: A Domain Adaptation Approach to Semantic Segmentation of LiDAR Point Clouds
Jul 16, 2020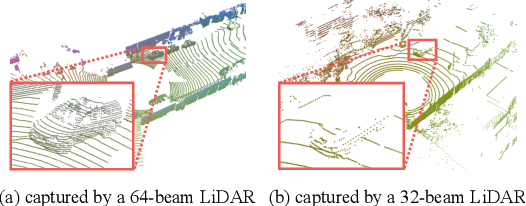
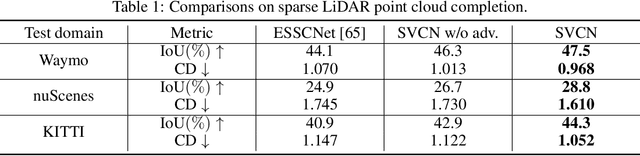
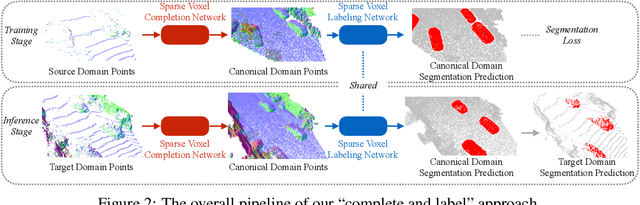
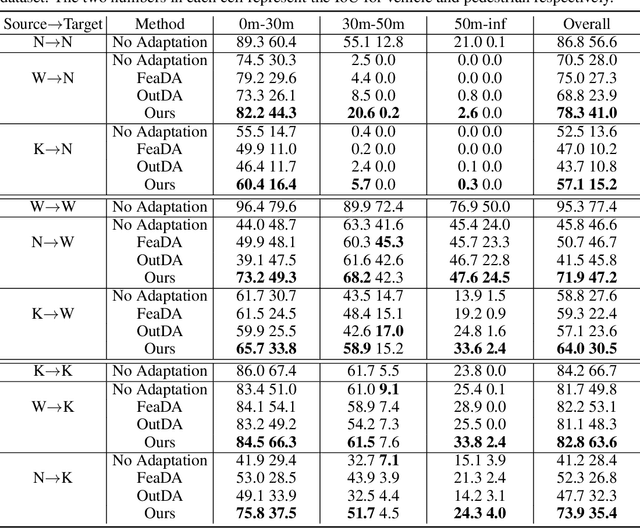
We study an unsupervised domain adaptation problem for the semantic labeling of 3D point clouds, with a particular focus on domain discrepancies induced by different LiDAR sensors. Based on the observation that sparse 3D point clouds are sampled from 3D surfaces, we take a Complete and Label approach to recover the underlying surfaces before passing them to a segmentation network. Specifically, we design a Sparse Voxel Completion Network (SVCN) to complete the 3D surfaces of a sparse point cloud. Unlike semantic labels, to obtain training pairs for SVCN requires no manual labeling. We also introduce local adversarial learning to model the surface prior. The recovered 3D surfaces serve as a canonical domain, from which semantic labels can transfer across different LiDAR sensors. Experiments and ablation studies with our new benchmark for cross-domain semantic labeling of LiDAR data show that the proposed approach provides 8.2-36.6% better performance than previous domain adaptation methods.
Smooth Adversarial Training
Jun 25, 2020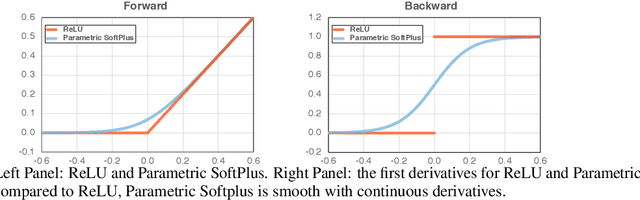

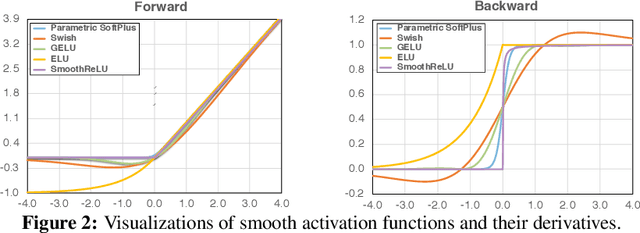
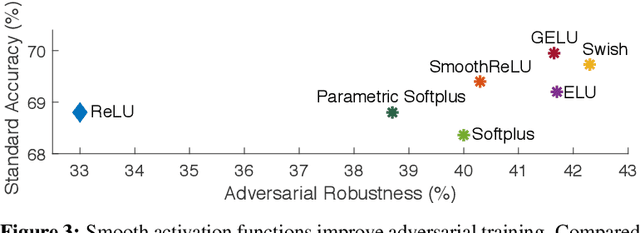
It is commonly believed that networks cannot be both accurate and robust, that gaining robustness means losing accuracy. It is also generally believed that, unless making networks larger, network architectural elements would otherwise matter little in improving adversarial robustness. Here we present evidence to challenge these common beliefs by a careful study about adversarial training. Our key observation is that the widely-used ReLU activation function significantly weakens adversarial training due to its non-smooth nature. Hence we propose smooth adversarial training (SAT), in which we replace ReLU with its smooth approximations to strengthen adversarial training. The purpose of smooth activation functions in SAT is to allow it to find harder adversarial examples and compute better gradient updates during adversarial training. Compared to standard adversarial training, SAT improves adversarial robustness for "free", i.e., no drop in accuracy and no increase in computational cost. For example, without introducing additional computations, SAT significantly enhances ResNet-50's robustness from 33.0% to 42.3%, while also improving accuracy by 0.9% on ImageNet. SAT also works well with larger networks: it helps EfficientNet-L1 to achieve 82.2% accuracy and 58.6% robustness on ImageNet, outperforming the previous state-of-the-art defense by 9.5% for accuracy and 11.6% for robustness.
When Ensembling Smaller Models is More Efficient than Single Large Models
May 01, 2020


Ensembling is a simple and popular technique for boosting evaluation performance by training multiple models (e.g., with different initializations) and aggregating their predictions. This approach is commonly reserved for the largest models, as it is commonly held that increasing the model size provides a more substantial reduction in error than ensembling smaller models. However, we show results from experiments on CIFAR-10 and ImageNet that ensembles can outperform single models with both higher accuracy and requiring fewer total FLOPs to compute, even when those individual models' weights and hyperparameters are highly optimized. Furthermore, this gap in improvement widens as models become large. This presents an interesting observation that output diversity in ensembling can often be more efficient than training larger models, especially when the models approach the size of what their dataset can foster. Instead of using the common practice of tuning a single large model, one can use ensembles as a more flexible trade-off between a model's inference speed and accuracy. This also potentially eases hardware design, e.g., an easier way to parallelize the model across multiple workers for real-time or distributed inference.
Neural Networks Are More Productive Teachers Than Human Raters: Active Mixup for Data-Efficient Knowledge Distillation from a Blackbox Model
Mar 31, 2020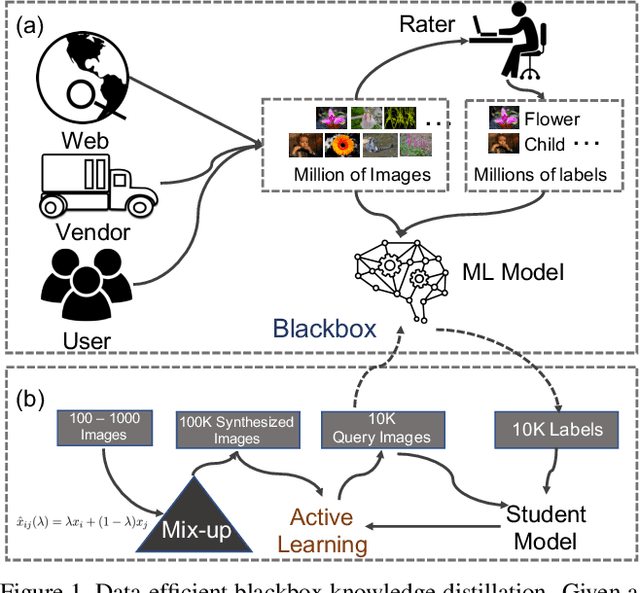



We study how to train a student deep neural network for visual recognition by distilling knowledge from a blackbox teacher model in a data-efficient manner. Progress on this problem can significantly reduce the dependence on large-scale datasets for learning high-performing visual recognition models. There are two major challenges. One is that the number of queries into the teacher model should be minimized to save computational and/or financial costs. The other is that the number of images used for the knowledge distillation should be small; otherwise, it violates our expectation of reducing the dependence on large-scale datasets. To tackle these challenges, we propose an approach that blends mixup and active learning. The former effectively augments the few unlabeled images by a big pool of synthetic images sampled from the convex hull of the original images, and the latter actively chooses from the pool hard examples for the student neural network and query their labels from the teacher model. We validate our approach with extensive experiments.
Rethinking Class-Balanced Methods for Long-Tailed Visual Recognition from a Domain Adaptation Perspective
Mar 24, 2020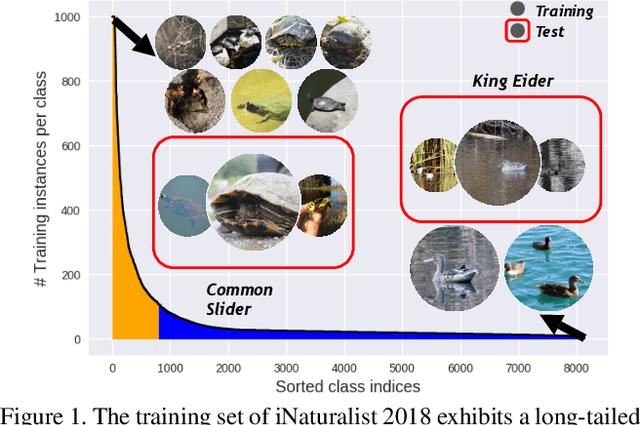


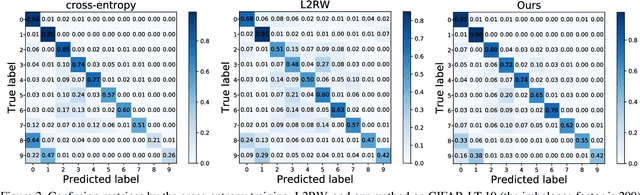
Object frequency in the real world often follows a power law, leading to a mismatch between datasets with long-tailed class distributions seen by a machine learning model and our expectation of the model to perform well on all classes. We analyze this mismatch from a domain adaptation point of view. First of all, we connect existing class-balanced methods for long-tailed classification to target shift, a well-studied scenario in domain adaptation. The connection reveals that these methods implicitly assume that the training data and test data share the same class-conditioned distribution, which does not hold in general and especially for the tail classes. While a head class could contain abundant and diverse training examples that well represent the expected data at inference time, the tail classes are often short of representative training data. To this end, we propose to augment the classic class-balanced learning by explicitly estimating the differences between the class-conditioned distributions with a meta-learning approach. We validate our approach with six benchmark datasets and three loss functions.
MACER: Attack-free and Scalable Robust Training via Maximizing Certified Radius
Feb 15, 2020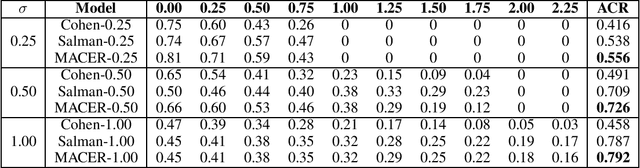
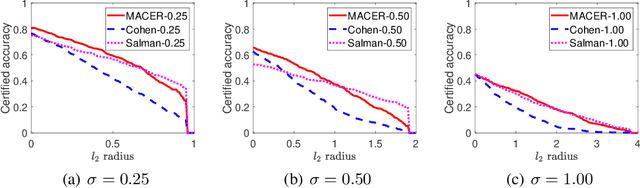
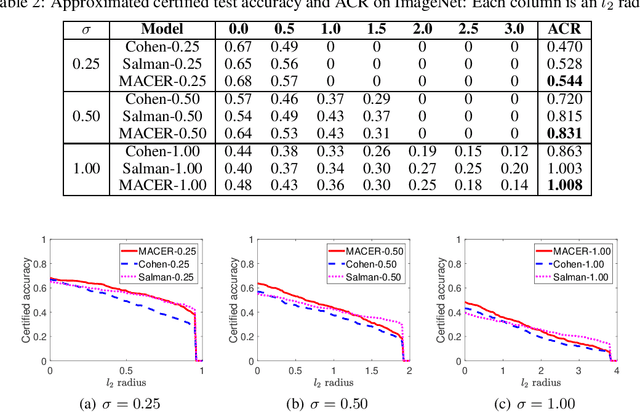
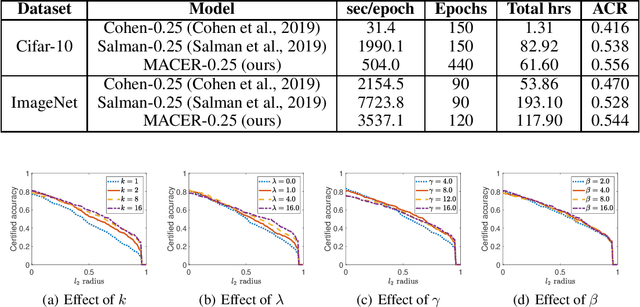
Adversarial training is one of the most popular ways to learn robust models but is usually attack-dependent and time costly. In this paper, we propose the MACER algorithm, which learns robust models without using adversarial training but performs better than all existing provable l2-defenses. Recent work shows that randomized smoothing can be used to provide a certified l2 radius to smoothed classifiers, and our algorithm trains provably robust smoothed classifiers via MAximizing the CErtified Radius (MACER). The attack-free characteristic makes MACER faster to train and easier to optimize. In our experiments, we show that our method can be applied to modern deep neural networks on a wide range of datasets, including Cifar-10, ImageNet, MNIST, and SVHN. For all tasks, MACER spends less training time than state-of-the-art adversarial training algorithms, and the learned models achieve larger average certified radius.
Look, Listen, and Act: Towards Audio-Visual Embodied Navigation
Dec 25, 2019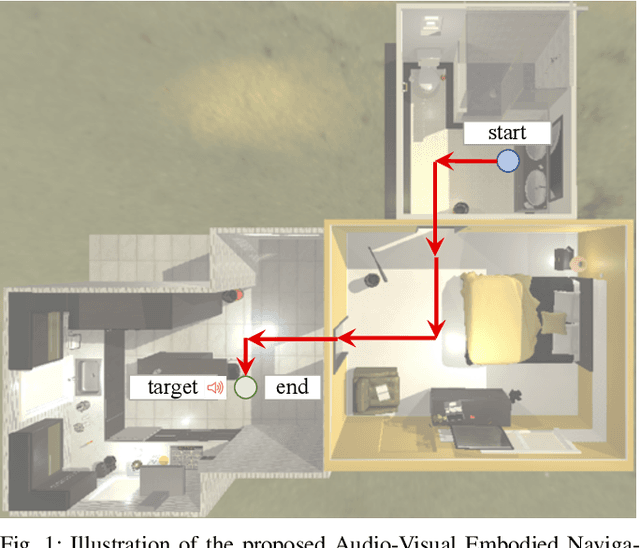

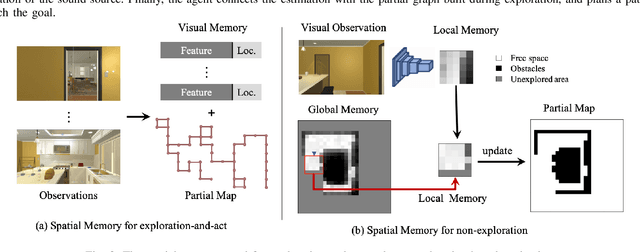
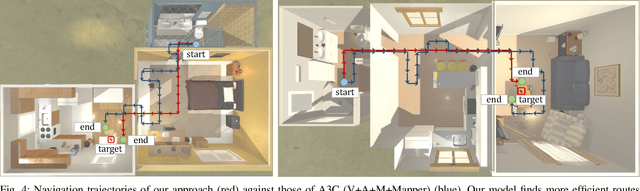
A crucial aspect of mobile intelligent agents is their ability to integrate the evidence from multiple sensory inputs in an environment and plan a sequence of actions to achieve their goals. In this paper, we attempt to address the problem of Audio-Visual Embodied Navigation, the task of planning the shortest path from a random starting location in a scene to the sound source in an indoor environment, given only raw egocentric visual and audio sensory data. To accomplish this task, the agent is required to learn from various modalities, i.e. relating the audio signal to the visual environment. Here we describe an approach to the audio-visual embodied navigation that can take advantage of both visual and audio pieces of evidence. Our solution is based on three key ideas: a visual perception mapper module that can construct its spatial memory of the environment, a sound perception module that infers the relative location of the sound source from the agent, and a dynamic path planner that plans a sequence of actions based on the visual-audio observations and the spatial memory of the environment, and then navigates towards the goal. Experimental results on a newly collected Visual-Audio-Room dataset using the simulated multi-modal environment demonstrate the effectiveness of our approach over several competitive baselines.
Adversarial Examples Improve Image Recognition
Nov 21, 2019
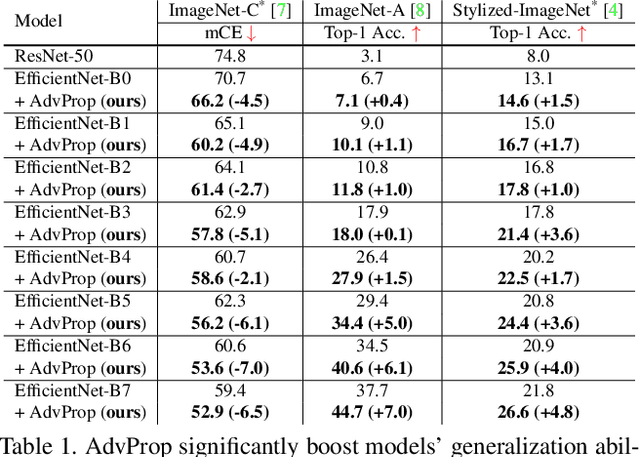
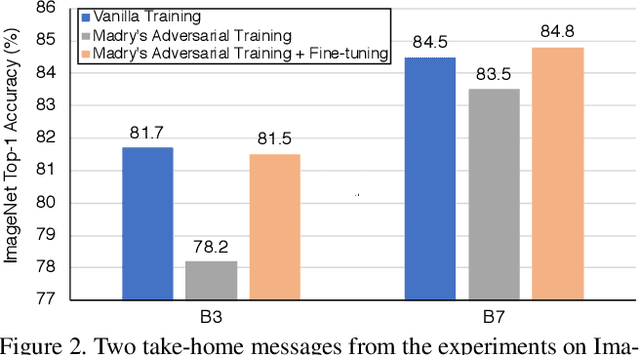
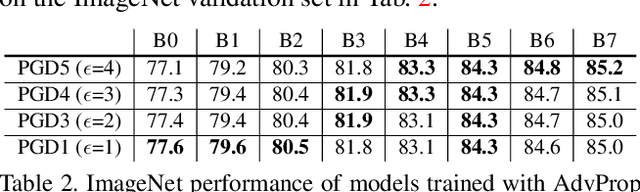
Adversarial examples are commonly viewed as a threat to ConvNets. Here we present an opposite perspective: adversarial examples can be used to improve image recognition models if harnessed in the right manner. We propose AdvProp, an enhanced adversarial training scheme which treats adversarial examples as additional examples, to prevent overfitting. Key to our method is the usage of a separate auxiliary batch norm for adversarial examples, as they have different underlying distributions to normal examples. We show that AdvProp improves a wide range of models on various image recognition tasks and performs better when the models are bigger. For instance, by applying AdvProp to the latest EfficientNet-B7 [28] on ImageNet, we achieve significant improvements on ImageNet (+0.7%), ImageNet-C (+6.5%), ImageNet-A (+7.0%), Stylized-ImageNet (+4.8%). With an enhanced EfficientNet-B8, our method achieves the state-of-the-art 85.5% ImageNet top-1 accuracy without extra data. This result even surpasses the best model in [20] which is trained with 3.5B Instagram images (~3000X more than ImageNet) and ~9.4X more parameters. Models are available at https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet.
Compound Domain Adaptation in an Open World
Sep 08, 2019
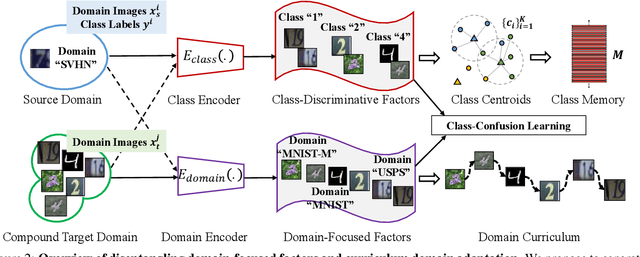

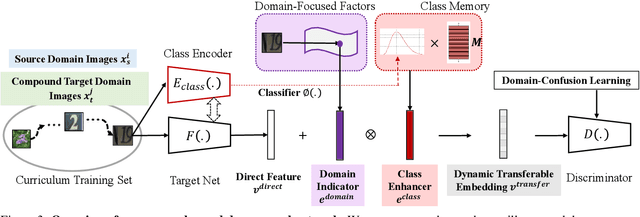
Existing works on domain adaptation often assume clear boundaries between source and target domains. Despite giving rise to a clean problem formalization, such form falls short of simulating the real world where domains are compounded of interleaving and confounding factors, blurring the domain boundaries. In this work, we opt for a different problem, dubbed open compound domain adaptation (OCDA), for studying the techniques of training domain-robust models in a more realistic setting. OCDA considers a compound (unlabeled) target domain which mixes several major factors (e.g., backgrounds, lighting conditions, etc.), along with a labeled training set, in the training stage and new open domains during inference. The compound target domain can be seen as a combination of multiple traditional target domains each with its own idiosyncrasy. To tackle OCDA, we propose a class-confusion loss to disentangle the domain-dominant factors out of the data and then use them to schedule a curriculum domain adaptation strategy. Moreover, we use a memory-augmented neural network architecture to increase the network's capacity for handling previously unseen domains. Extensive experiments on digit classification, facial expression recognition, semantic segmentation, and reinforcement learning verify the effectiveness of our approach.
Domain Randomization and Pyramid Consistency: Simulation-to-Real Generalization without Accessing Target Domain Data
Sep 02, 2019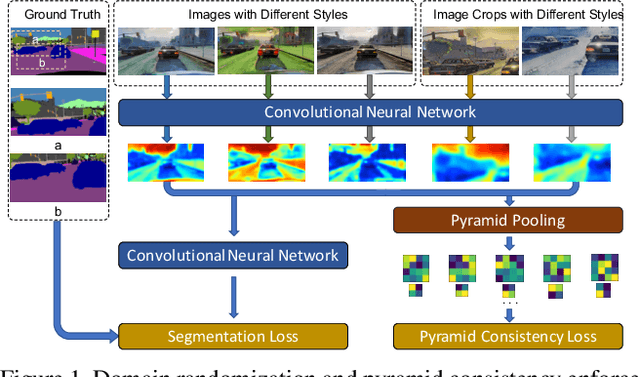
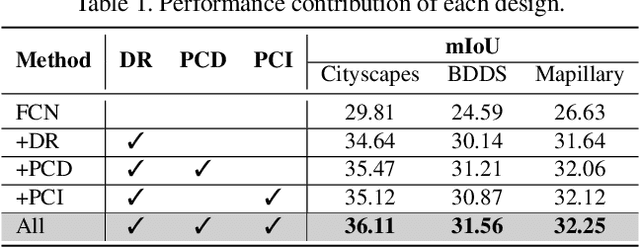

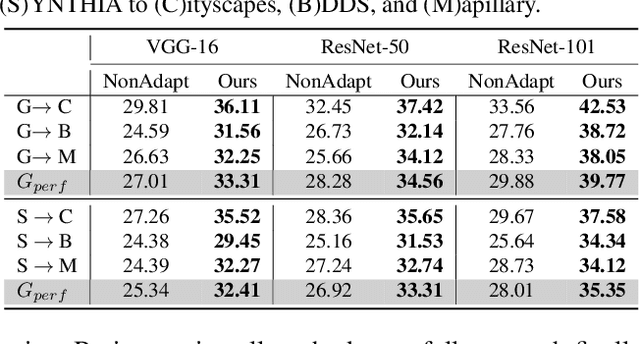
We propose to harness the potential of simulation for the semantic segmentation of real-world self-driving scenes in a domain generalization fashion. The segmentation network is trained without any data of target domains and tested on the unseen target domains. To this end, we propose a new approach of domain randomization and pyramid consistency to learn a model with high generalizability. First, we propose to randomize the synthetic images with the styles of real images in terms of visual appearances using auxiliary datasets, in order to effectively learn domain-invariant representations. Second, we further enforce pyramid consistency across different "stylized" images and within an image, in order to learn domain-invariant and scale-invariant features, respectively. Extensive experiments are conducted on the generalization from GTA and SYNTHIA to Cityscapes, BDDS and Mapillary; and our method achieves superior results over the state-of-the-art techniques. Remarkably, our generalization results are on par with or even better than those obtained by state-of-the-art simulation-to-real domain adaptation methods, which access the target domain data at training time.